中科院自动化所兴军亮研究员领导的博弈学习研究组提出了一种高水平轻量化的两人无限注德州扑克 AI 程序——AlphaHoldem。其决策速度较 DeepStack 速度提升超 1000 倍,与高水平德州扑克选手对抗的结果表明其已经达到了人类专业玩家水平,相关工作已被 AAAI 2022 接收。
从人工智能学科诞生伊始,智能博弈研究就是人工智能技术发展创新的沃土,并且一直都是衡量人工智能发展水平的重要评价准则 [1][2][3][4]。2016 年,AlphaGo[2] 以 4:1 的成绩战胜围棋世界冠军李世石,这一事件被认为是智能博弈技术发展的一个重要里程碑。不同于完美信息的围棋博弈,现实世界博弈的一个显著特点是由于信息不完备性造成的对手不确定。以德州扑克为代表的大规模不完美信息博弈问题很好地集中了这一难题,是进一步深入研究智能博弈理论与技术的极佳平台。近年来,国际上围绕德州扑克这一大规模不完美信息博弈问题的优化求解取得了长足进步,来自加拿大阿尔伯特大学和美国卡内基梅隆大学的研究者设计的 AI 程序 DeepStack[3]和 Libratus[4]先后在两人无限注德州扑克中均战胜了人类专业选手,随后卡内基梅隆大学设计的 AI 程序 Pluribus[5]又在六人无限注德州扑克中战胜了人类专业选手。
上述具有里程碑意义的德州扑克 AI 都依赖一种迭代式的反事实遗憾最小化(Counterfactual Regret Minimization,CFR)[6]算法。该算法在训练过程中不仅需要耗费大量的计算资源,同时需要很多德州扑克游戏的领域知识。近日,中国科学院自动化研究所兴军亮研究员领导的博弈学习研究组在德州扑克 AI 方面取得了重要进展,提出了一种高水平轻量化的两人无限注德州扑克 AI 程序 AlphaHoldem。AlphaHoldem 整体上采用一种精心设计的伪孪生网络架构,并将一种改进的深度强化学习算法与一种新型的自博弈学习算法相结合,在不借助任何领域知识的情况下,直接从牌面信息端到端地学习候选动作进行决策。AlphaHoldem 使用了 1 台包含 8 块 GPU 卡的服务器,经过三天的自博弈学习后,战胜了 Slumbot[7]和 DeepStack[3]。在每次决策时,AlphaHoldem 仅需不到 3 毫秒,比 DeepStack 速度提升超过了 1000 倍。同时,AlphaHoldem 与四位高水平德州扑克选手对抗 1 万局的结果表明其已经达到了人类专业玩家水平。
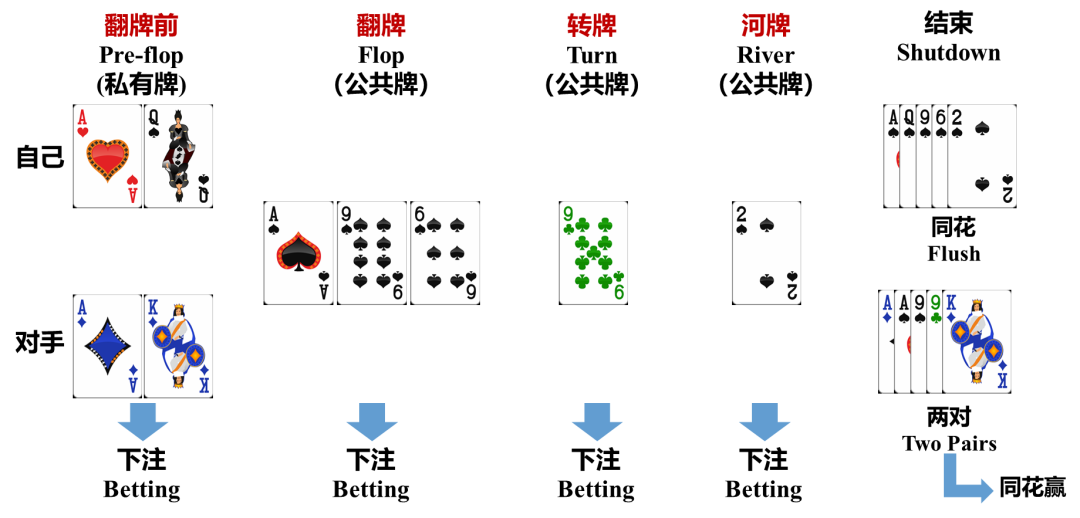
德州扑克是国际上最为流行的扑克游戏,由于最早起源于 20 世纪初美国德克萨斯州而得名。德州扑克的规则是使用去掉王牌的一副扑克牌,共 52 张牌,至少 2 人参与,至多 22 人,一般参与人数为两人和十人之间。游戏开始时,首先为每个玩家发两张私有牌作为各自的 “底牌”,随后将五张公共牌依次按三张、一张、一张朝上发出。在发完两张私有牌、三张共有牌、第四张公共牌、第五张公共牌后玩家都可以多次无限制押注,这四轮押注分别称为“翻牌前”、“翻牌”、“转牌”、“河牌”。图 1 展示了一场德州扑克游戏的完整流程示意。经过四轮押注之后,若仍不能分出胜负,游戏进入“摊牌” 阶段,所有玩家亮出各自底牌并与公共牌组合成五张牌,成牌最大者获胜。图 2 给出了德州扑克不同组合的牌型解释和大小。
德州扑克不仅是最流行的扑克类游戏,而且也为研究智能博弈基础理论和方法提供了一个绝佳试验和测试平台。首先,德州扑克博弈的问题复杂度很大,两人无限注德州扑克的决策空间复杂度超过 10 的 161 次方[3];其次,德州扑克博弈过程属于典型的回合制动态博弈过程,游戏参与者每一步决策都依赖于上一步的决策结果,同时对后面的决策步骤产生影响;另外,德州扑克博弈属于典型的不完美信息博弈,博弈过程中玩家各自底牌信息不公开使得每个玩家信息都不完备,玩家在每一步决策时都要充分考虑对手的各种可能情况,这就涉及到对手行为与心理建模、欺诈与反欺诈等诸多问题。此外,由于德州扑克游戏规则又非常简单且边界确定,特别适合作为一个虚拟实验环境对博弈的相关基础理论方法和核心技术算法进行深入探究。
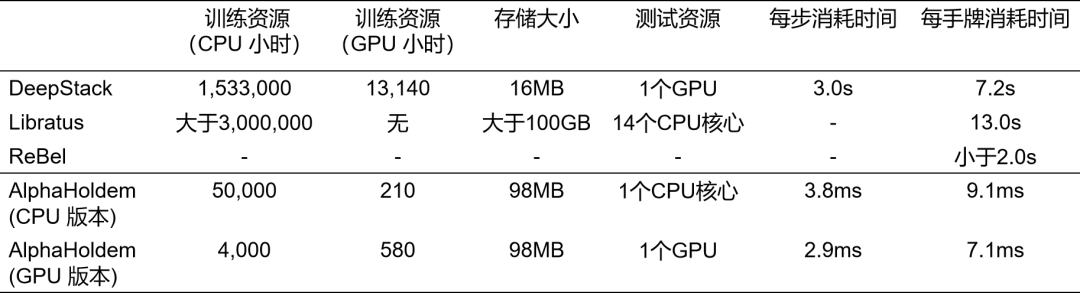
目前主流德州扑克 AI 背后的核心思想是利用反事实遗憾最小化(Counterfactual Regret Minimization, CFR)算法 [6] 逼近纳什均衡策略。具体来说,首先利用抽象(Abstraction)技术 [3][7] 压缩德扑的状态和动作空间,从而减小博弈树的规模,然后在缩减过的博弈树上进行 CFR 算法迭代。这些方法严重依赖于人类专家知识进行博弈树抽象,并且 CFR 算法需要对博弈树的状态结点进行不断地采样遍历和迭代优化,即使经过模型缩减后仍需要耗费大量的计算和存储资源。例如,DeepStack 使用了 153 万的 CPU 时以及 1.3 万的 GPU 时训练最终 AI,在对局阶段需要一个 GPU 进行 1000 次 CFR 的迭代过程,平均每个动作的计算需耗时 3 秒。Libratus 消耗了大于 300 万的 CPU 时生成初始策略,每次决策需要搜索 4 秒以上。这样大量的计算和存储资源的消耗严重阻碍了德扑 AI 的进一步研究和发展;同时,CFR 框架很难直接拓展到多人德扑环境中,增加玩家数量将导致博弈树规模呈指数增长。另外,博弈树抽象不仅需要大量的领域知识而且会不可避免地丢失一些对决策起到至关作用的信息。
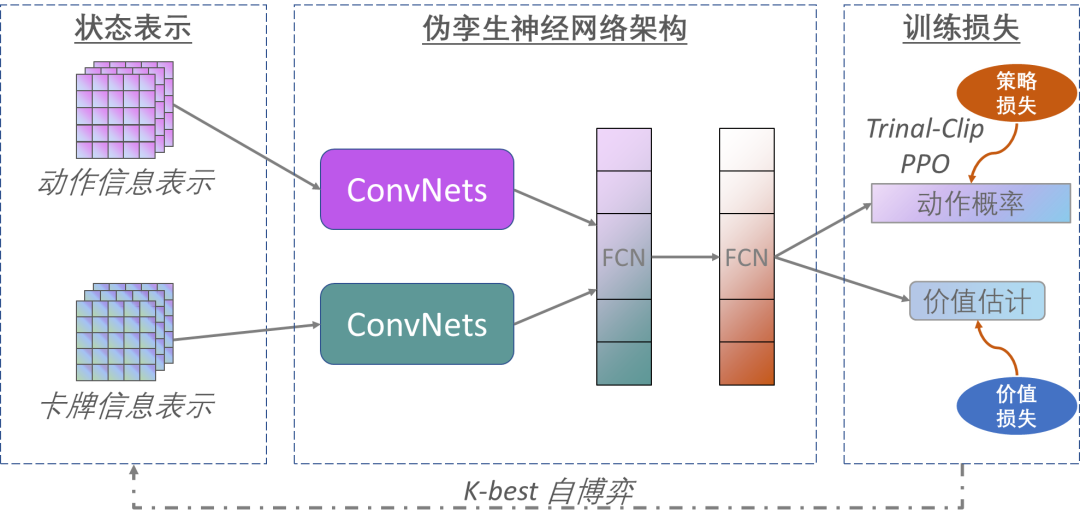
不同于已有的基于 CFR 算法的德州扑克 AI,中国科学院自动化研究所博弈学习研究组基于端到端的深度强化学习算法研发了一款高水平轻量型的德州扑克 AI 程序 AlphaHoldem,其整体架构如图 4 所示。AlphaHoldem 采用 Actor-Critic 学习框架[8],其输入是卡牌和动作的编码,然后通过伪孪生卷积网络(结构相同参数不共享)提取特征,接下来通过两个全连接层得到状态的高层特征,最终输出动作概率和价值估计。
AlphaHoldem 的成功得益于其采用了一种高效的状态编码来完整地描述当前及历史状态信息、一种基于 Trinal-Clip PPO 损失的深度强化学习算法来大幅提高训练过程的稳定性和收敛速度、以及一种新型的 Best-K 自博弈方式来有效地缓解德扑博弈中存在的策略克制问题。
高效的全状态空间编码
:已有德州扑克 AI 受限于 CFR 算法的处理能力,均需要对牌面状态和动作信息进行压缩,压缩的好坏完全取决于对德扑领域知识的掌握程度,而且不可避免地造成信息的损失。AlphaHoldem 对整个状态空间进行高效编码,不利用德扑领域知识进行信息压缩。对于卡牌信息,将其编码成包含多个通道的张量,用来表示私有牌、公共牌等信息。对于动作信息,AlphaHoldem 同样将其编码为多通道张量,用来表示各玩家当前及历史的动作信息。AlphaHoldem 的多维张量状态表示方法不仅完整地编码了当前及历史的状态信息,而且非常适合作为卷积神经网络的输入进行特征的学习。
Trinal-Clip PPO 强化学习
:由于信息不完美及不同对手的各种 “诈唬” 欺骗行为,使得德州扑克成为一种结果具有很强随机性的游戏,这导致常见的强化学习算法(如 PPO[9]等)训练过程很不稳定且难以收敛。AlphaHoldem 提出了一种新型的 Trinal-Clip PPO 损失用于改进深度强化学习过程的稳定性,通过引入 3 个截断参数解决了 PPO 算法在优势函数小于零时损失值方差过大的问题以及 “全压” 等动作造成的价值函数难估计的问题。整体上来说,Trinal-clip PPO 损失有效缓解了德扑博弈的强随机性造成的策略训练不稳定问题,使 AlphaHoldem 训练得又快又好。
Best-K 自博弈训练方法
:德扑游戏不同策略之间存在复杂的克制关系,这使得 Naive 自博弈方法 [10] 或是 AlphaGo 采用的 Best-Win 自博弈方法 [3] 很难在德扑游戏中收敛。然而使用 AlphaStar 的群体博弈 PBT[11],神经虚拟自博弈 NFSP[12]等方法来训练德扑 AI 会消耗比传统 CFR 算法更多的计算资源。为了有效地平衡训练效率和模型性能,AlphaHoldem 采用了一种新型的 Best-K 自博弈方法。该方法通过在训练过程中测试历史模型的性能,挑选出 K 个最好的模型与现在最新的模型对打,不断通过强化学习提升自身性能。
我们将 AlphaHoldem 与当前的高水平德扑 AI 进行了比较,发现 AlphaHoldem 都有明显优势。经过 10 万局的对抗,AlphaHoldem 平均赢 Slumbot[7](2018 年世界计算机扑克大赛 ACPC 冠军,现在还在进化)111.56 mbb / 局(每 1000 手牌赢多少个大盲注),赢 DeepStack(课题组使用 120 GPU 卡训练 3 周复现的版本)16.91 mbb / 局。同时,它可以达到人类专业玩家水平,通过和 4 位专业玩家对抗 1 万局,AlphaHoldem 平均赢专业玩家 10.27 mbb / 局。另外,AlphaHoldem 在一台包含 1 个 AMD 2.00GHz CPU(64 个核心)、8 个 NVIDIA TITAN V GPU 的服务器上仅训练三天,在一个 CPU 核心下每次决策仅需 4 毫秒,做到了真正的又快又好。
AlphaHoldem 接下来会接入到课题组自研的人机对抗平台 OpenHoldem[13](http://holdem.ia.ac.cn/)中供研究者开放测试(图 5)。OpenHoldem 是学术界第一个开放的大规模不完美信息博弈研究平台,包含了多维度评测指标、高性能基准 AI 以及公开的在线测试环境。平台支持人人对抗、机机对抗以及人机对抗等多种模式、支持 AI 分布式并行对抗、支持动态测试请求响应及资源分配、支持多用户并发访问和跨终端统一登录。平台目前已经吸引了来自高校、研究所、互联网企业等 200 余家单位的近 500 名注册用户,并受到了国内多家权威机构和主流媒体的转发报道。
图 5:OpenHoldem 在线不完美信息博弈对抗平台首页
AlphaHoldem 采用了端到端强化学习的框架,大大降低了现有德扑 AI 所需的领域知识以及计算存储资源消耗,并达到了人类专业选手的水平。该框架是一个通用的端到端学习框架,我们已经在多人无限注德扑上验证了该框架的适用性,目前正在提升多人模型训练过程的学习性能。我们还准备将 AlphaHoldem 背后的技术应用到更多不完美信息博弈问题中,比如麻将、斗地主、桥牌等,同时也计划进行多人博弈策略空间的均衡结构分析等研究内容。
博弈学习研究组是中科院自动化所下属科研团队,是中科院人工智能创新研究院的骨干研究力量。课题组负责人为兴军亮研究员。课题组现有正式员工 9 人,博士研究生 7 人,硕士研究生 9 人,形成了一支以青年科研骨干为主体的高水平、高素质的科研队伍。
研究组以计算机博弈为研究切入点,通过将最新的机器学习技术引入到经典博弈理论和模型之中,同时借鉴运筹学、最优化、算法设计等学科的研究方法和算法,形成具有鲜明交叉特点的技术研究体系;通过使用经典博弈理论对博弈过程进行建模,然后利用最新机器学习技术对模型的参数进行学习更新,从而实现对复杂人机博弈问题的可建模性、可计算性和可解释性的结合。
课题组从 2018 年底开始研究以德州扑克为代表的大规模不完美信息博弈问题,在 2020 年公开了学界首个大规模不完美信息博弈对抗平台 OpenHoldem,集成了高性能基准 AI、多维度评测协议、在线对抗评估等完整功能,支持人机、机机、人人、人机混合等对抗模式。相关研发工作的主要完成人员包括兴军亮研究员,李凯副研究员,博士生赵恩民、徐航、李金秋,硕士生闫仁业、吴哲等。
Enmin Zhao#, Renye Yan#, Jinqiu Li, Kai Li, Junliang Xing*.
High-Performance Artificial Intelligence for Heads-Up No-Limit Poker via End-to-End Reinforcement Learning. In AAAI 2022.
Kai Li, Hang Xu, Enmin Zhao, Zhe Wu, Junliang Xing*.
OpenHoldem: An Open Toolkit for Large-Scale Imperfect-Information Game Research. ArXiv preprint arXiv:2012.06168, 2020.
[1] Murray C, Joseph H, and Feng-hsiung H. Deep Blue. Artificial Intelligence, 2002, 134(1):57-83.
[2] Silver D, Huang A, Maddison C J, et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016, 529(7587): 484-489.
[3] Moravčík M, Schmid M, Burch N, et al. Deepstack: Expert-level artificial intelligence in heads-up no-limit poker[J]. Science, 2017, 356(6337): 508-513.
[4] Brown N, Sandholm T. Superhuman AI for heads-up no-limit poker: Libratus beats top professionals[J]. Science, 2018, 359(6374): 418-424.
[5] Brown N, Sandholm T. Superhuman AI for multiplayer poker[J]. Science, 2019, 365(6456): 885-890.
[6] Zinkevich M, Johanson M, Bowling M, et al. Regret minimization in games with incomplete information[J]. Advances in neural information processing systems, 2007, 20: 1729-1736.
[7] Jackson E G. Slumbot NL: Solving large games with counterfactual regret minimization using sampling and distributed processing[C]. Workshops at the Twenty-Seventh AAAI Conference on Artificial Intelligence. 2013.
[8] Konda V R, Tsitsiklis J N. Actor-critic algorithms[C]. Advances in neural information processing systems. 2000: 1008-1014.
[9] Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[J]. ArXiv preprint arXiv:1707.06347, 2017.
[10] Silver D, Hubert T, Schrittwieser J, et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play[J]. Science, 2018, 362(6419): 1140-1144.
[11] Vinyals O, Babuschkin I, Czarnecki W M, et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019, 575(7782): 350-354.
[12] Heinrich J, Lanctot M, Silver D. Fictitious self-play in extensive-form games[C]. International conference on machine learning. PMLR, 2015: 805-813.
[13] Li K, Xu H, Zhang M, et al. OpenHoldem: An Open Toolkit for Large-Scale Imperfect-Information Game Research[J]. ArXiv preprint arXiv:2012.06168, 2020.
苏黎世联邦理工DS3Lab:构建以数据为中心的机器学习系统
苏黎世联邦理工学院(ETH Zurich) DS3Lab实验室由助理教授张策以及16名博士生和博士后组成,主要致力于两大研究方向,Ease.ML项目:研究如何设计、管理、加速以数据为中心的机器学习开发、运行和运维流程,ZipML项目:面向新的软硬件环境设计实现高效可扩展的机器学习系统。
12月15日-12月22日
,来自苏黎世联邦理工学院DS3Lab实验室的11位嘉宾将带来6期分享:构建以数据为中心的机器学习系统,详情如下:
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com