8.6M超轻量中英文OCR模型来了,还可自定义训练!

OCR技术有着丰富的应用场景,包括已经在日常生活中广泛应用的面向垂类的结构化文本识别,如车牌识别、银行卡信息识别、身份证信息识别、火车票信息识别等等,此外,通用OCR技术也有广泛的应用,如在视频场景中,经常使用OCR技术进行字幕自动翻译、内容安全监控等等,或者与视觉特征相结合,完成视频理解、视频搜索等任务。
OCR文字检测和识别目前的主流方法大多是采用深度学习技术,这从ICDAR2015自然场景排名前列的应用方法可以明显看出。深度学习技术在一些垂类场景,文本识别精准度已经可以达到99%以上,取得了非常好的效果。
但在实际应用中,尤其是在广泛的通用场景下,OCR技术也面临一些挑战,比如仿射变换、尺度问题、光照不足、拍摄模糊等技术难点;另外OCR应用常对接海量数据,但要求数据能够得到实时处理;并且OCR应用常部署在移动端或嵌入式硬件,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求。
在这样的背景下,飞桨首次开源文字识别模型套件PaddleOCR,目标是打造丰富、领先、实用的文本识别模型/工具库。首阶段的开源套件推出了重磅模型:8.6M超轻量中英文识别模型。用户既可以很便捷的直接使用该超轻量模型,也可以使用开源套件训练自己的超轻量模型。
项目地址:
https://github.com/PaddlePaddle/PaddleOCR
8.6M超轻量
中英文OCR模型开源
模型画像:
-
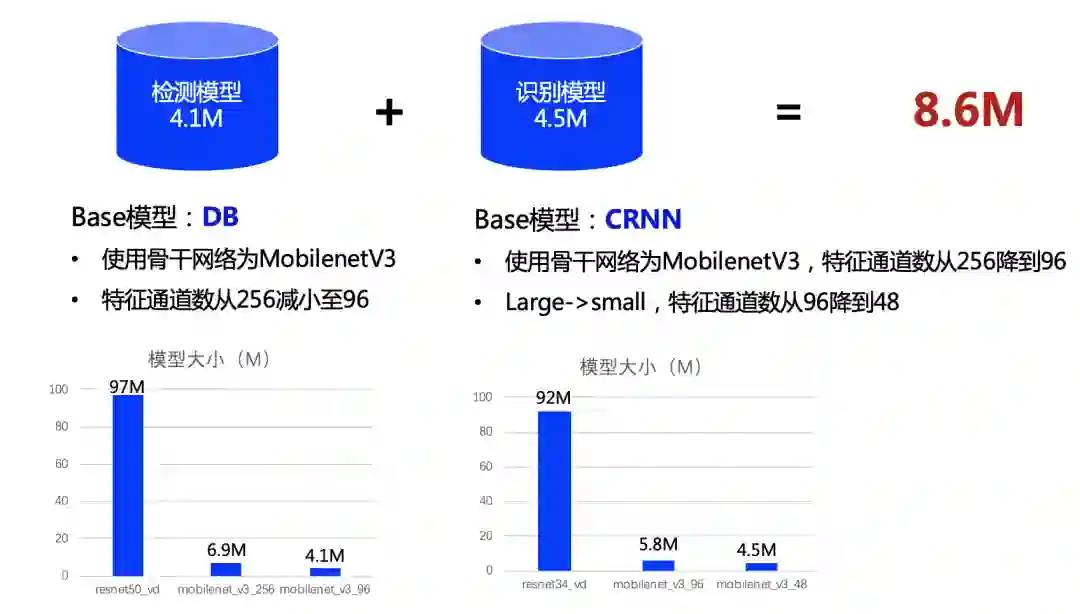
总模型大小仅8.6M -
仅1个检测模型(4.1M)+1个识别模型(4.5M)组成 -
同时支持中英文识别 -
支持倾斜、竖排等多种方向文字识别 -
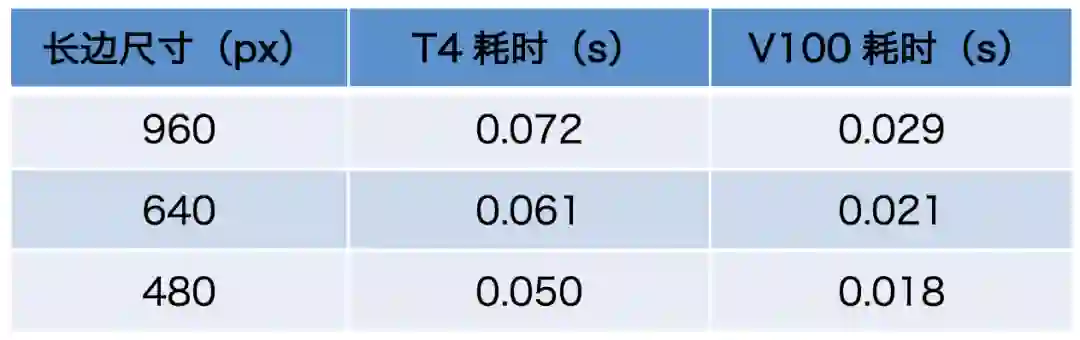
T4单次预测全程平均耗时仅60ms -
支持GPU、CPU预测 -
可运行于Linux、Windows、MacOS等多种系统






<< 滑动查看下一张图片 >>
快速体验超轻量
中英文OCR模型
PaddleOCR已将该超轻量模型开源,感兴趣的小伙伴赶紧动手操练一下吧:
mkdir inference && cd inference
# 下载超轻量级中文OCR模型的检测模型并解压
wget https://paddleocr.bj.bcebos.com/ch_models/ch_det_mv3_db_infer.tar && tar xf ch_det_mv3_db_infer.tar
# 下载超轻量级中文OCR模型的识别模型并解压
wget https://paddleocr.bj.bcebos.com/ch_models/ch_rec_mv3_crnn_infer.tar && tar xf ch_rec_mv3_crnn_infer.tar
cd ..
# 设置PYTHONPATH环境变量
export PYTHONPATH=.
# 预测image_dir指定的单张图像
python3 tools/infer/predict_system.py --image_dir=
"./doc/imgs/11.jpg" --det_model_dir=
"./inference/ch_det_mv3_db/" --rec_model_dir=
"./inference/ch_rec_mv3_crnn/"
更便捷的在线体验方案
该模型也已经内置在飞桨预训练模型应用工具PaddleHub中,供用户更便捷地体验,上传图片即可在线体验:
https://www.paddlepaddle.org.cn/hub/scene/ocr
pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
import paddlehub
as hub
ocr = hub.Module(name=
"chinese_ocr_db_crnn")
#加载预训练模型
results = ocr.recognize_text(paths=[
'/PATH/TO/IMAGE'], visualization=
True) #输入自定义待识别图片路径、并保存可视化图片结果
效果更好的大模型同步开源


<< 滑动查看下一张图片 >>
# 通用中文OCR模型的检测模型
https://paddleocr.bj.bcebos.com/ch_models/ch_det_r50_vd_db_infer.tar
# 通用中文OCR模型的识别模型
https://paddleocr.bj.bcebos.com/ch_models/ch_rec_r34_vd_crnn_infer.tar
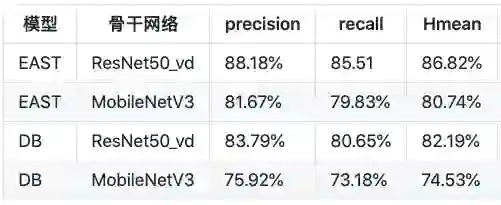
训练自己的超轻量模型
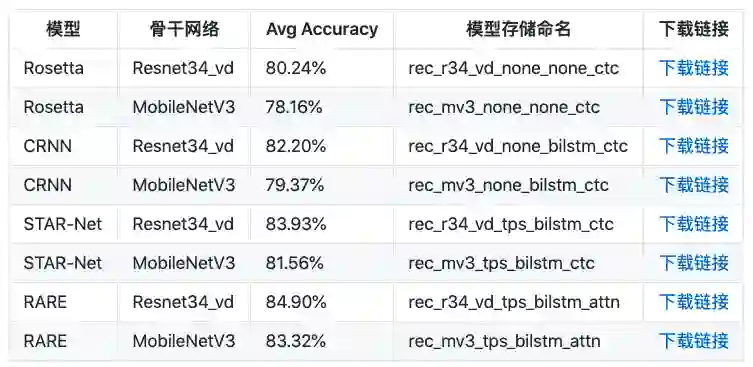

参考文献
END

登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文