北大开源全新中文分词工具包:准确率远超THULAC、结巴分词
选自GitHub
作者:罗睿轩、许晶晶、孙栩
机器之心编辑
最近,北大开源了一个中文分词工具包,它在多个分词数据集上都有非常高的分词准确率。其中广泛使用的结巴分词误差率高达 18.55% 和 20.42,而北大的 pkuseg 只有 3.25% 与 4.32%。
pkuseg 是由北京大学语言计算与机器学习研究组研制推出的一套全新的中文分词工具包。它简单易用,支持多领域分词,在不同领域的数据上都大幅提高了分词的准确率。
项目地址:https://github.com/lancopku/PKUSeg-python
pkuseg 具有如下几个特点:
高分词准确率:相比于其他的分词工具包,该工具包在不同领域的数据上都大幅提高了分词的准确度。根据北大研究组的测试结果,pkuseg 分别在示例数据集(MSRA 和 CTB8)上降低了 79.33% 和 63.67% 的分词错误率。
多领域分词:研究组训练了多种不同领域的分词模型。根据待分词的领域特点,用户可以自由地选择不同的模型。
支持用户自训练模型:支持用户使用全新的标注数据进行训练。
此外,作者们还选择 THULAC、结巴分词等国内代表分词工具包与 pkuseg 做性能比较。他们选择 Linux 作为测试环境,在新闻数据(MSRA)和混合型文本(CTB8)数据上对不同工具包进行了准确率测试。此外,测试使用的是第二届国际汉语分词评测比赛提供的分词评价脚本。评测结果如下:
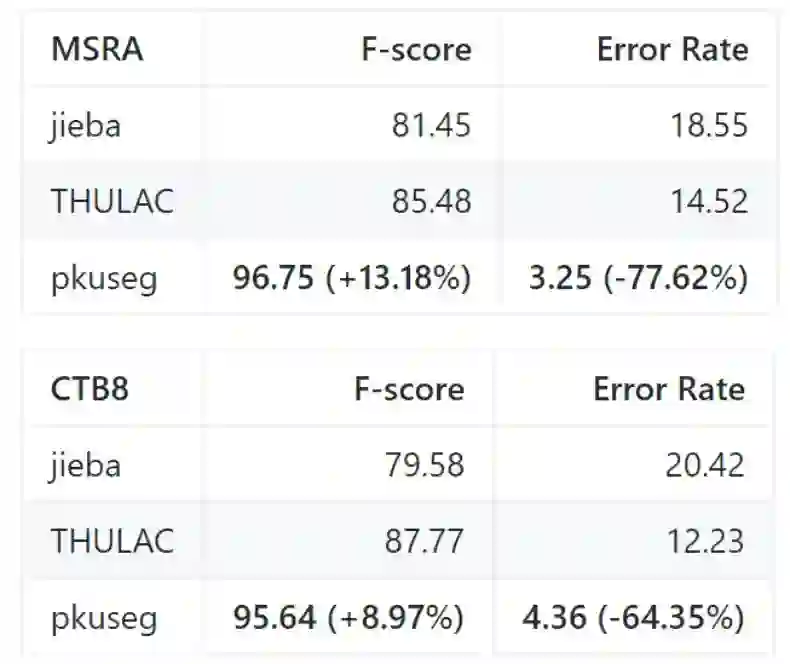
我们可以看到,最广泛使用的结巴分词准确率最低,清华构建的 THULAC 分词准确率也没有它高。当然,pkuseg 是在这些数据集上训练的,因此它在这些任务上的准确率也会更高一些。
预训练模型
分词模式下,用户需要加载预训练好的模型。研究组提供了三种在不同类型数据上训练得到的模型,根据具体需要,用户可以选择不同的预训练模型。以下是对预训练模型的说明:
MSRA:在 MSRA(新闻语料)上训练的模型。新版本代码采用的是此模型。
CTB8:在 CTB8(新闻文本及网络文本的混合型语料)上训练的模型。
WEIBO:在微博(网络文本语料)上训练的模型。
其中,MSRA 数据由第二届国际汉语分词评测比赛提供,CTB8 数据由 LDC 提供,WEIBO 数据由 NLPCC 分词比赛提供。在 GitHub 项目中,这三个预训练模型都提供了下载地址。
安装与使用
pkuseg 的安装非常简单,我们可以使用 pip 安装,也可以直接从 GitHub 下载:
pip install pkuseg
使用 pkuseg 实现分词也很简单,基本上和其它分词库的用法都差不多:
'''代码示例1: 使用默认模型及默认词典分词'''
import pkuseg
#以默认配置加载模型
seg = pkuseg.pkuseg()
#进行分词
text = seg.cut('我爱北京天安门')
print(text)
'''代码示例2: 设置用户自定义词典'''
import pkuseg
#希望分词时用户词典中的词固定不分开
lexicon = ['北京大学', '北京天安门']
#加载模型,给定用户词典
seg = pkuseg.pkuseg(user_dict=lexicon)
text = seg.cut('我爱北京天安门')
print(text)
'''代码示例3'''
import pkuseg
#假设用户已经下载好了ctb8的模型并放在了'./ctb8'目录下,通过设置model_name加载该模型
seg = pkuseg.pkuseg(model_name='./ctb8')
text = seg.cut('我爱北京天安门')
print(text)
对于大型文本数据集,如果需要快速分词的话,我们也可以采用多线程的方式:
'''代码示例4'''
import pkuseg
#对input.txt的文件分词输出到output.txt中,使用默认模型和词典,开20个进程
pkuseg.test('input.txt', 'output.txt', nthread=20)
最后,pkuseg 还能重新训练一个分词模型:
'''代码示例5'''
import pkuseg
#训练文件为'msr_training.utf8',测试文件为'msr_test_gold.utf8',模型存到'./models'目录下,开20个进程训练模型
pkuseg.train('msr_training.utf8', 'msr_test_gold.utf8', './models', nthread=20)
这些都是 GitHub 上的示例,详细的内容请参考 GitHub 项目,例如参数说明和参考论文等。

本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com