谁说RL智能体只能在线训练?谷歌发布离线强化学习新范式,训练集相当于200多个ImageNet
选自谷歌博客
作者:Rishabh Agarwal、Mohammad Norouzi
机器之心编译
为了避免 distribution mismatch,强化学习的训练一定要在线与环境进行交互吗?谷歌的这项最新研究从优化角度,为我们提供了离线强化学习研究新思路,即鲁棒的 RL 算法在足够大且多样化的离线数据集中训练可产生高质量的行为。该论文的训练数据集与代码均已开源。机器之心友情提示,训练数据集共包含 60 个雅达利游戏环境,谷歌宣称其大小约为 ImageNet 的 60 x 3.5 倍。

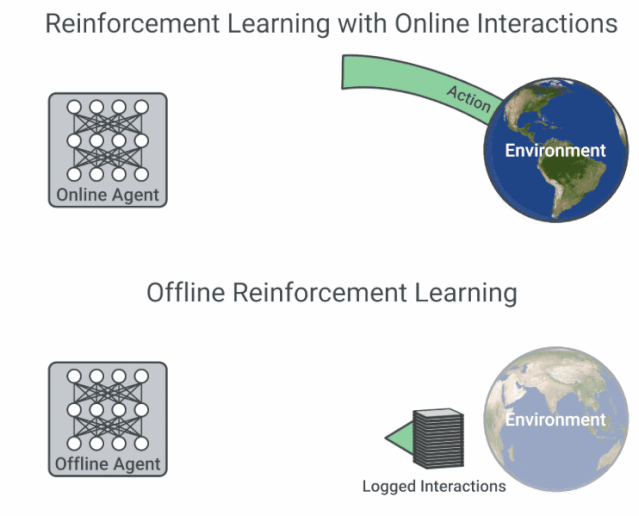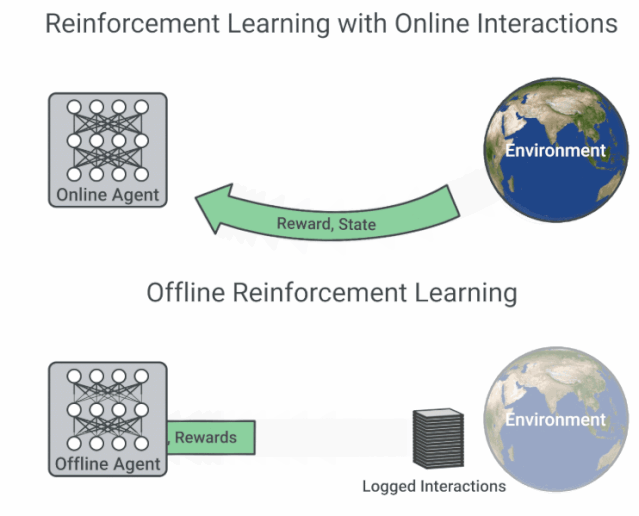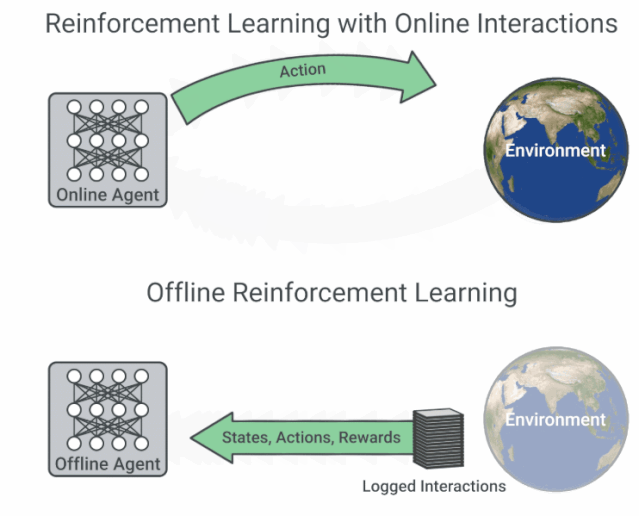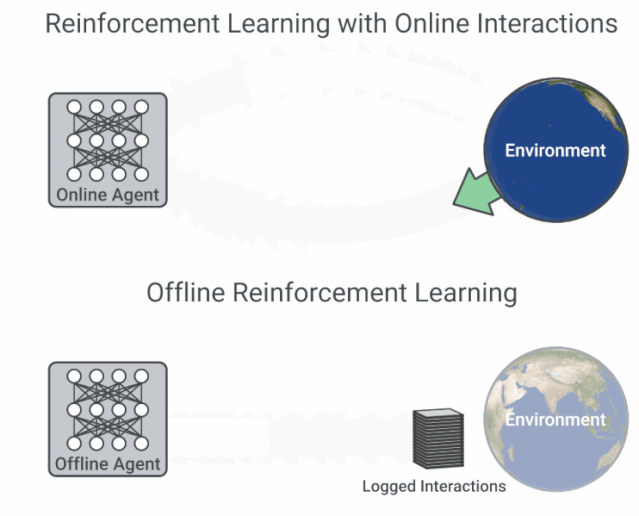
论文链接:https://arxiv.org/pdf/1907.04543.pdf
项目地址:https://github.com/google-research/batch_rl


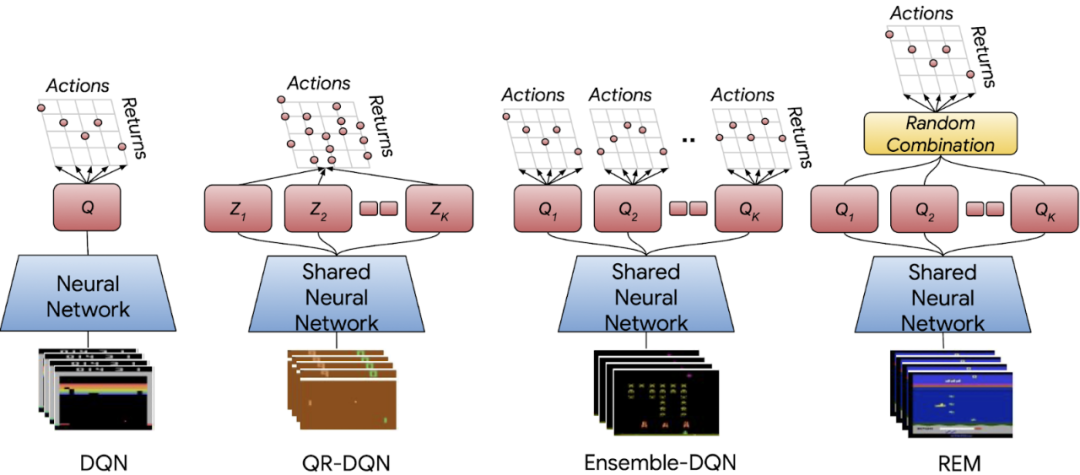
集成 DQN 是 DQN 的一个简单扩展,它训练多个 Q 值估计并取平均值来进行评估;
随机集成混合(Random Ensemble Mixture,REM)是一个易于实现的 DQN 扩展,它受到了 Dropout 的启发。REM 的核心理念是,如果可以得到 Q 值的多个估计,则 Q 值估计的加权组合(weighted combination)也成为 Q 值的一个估计。因此,REM 在每次迭代中随机组合多个 Q 值估计,并将这种随机组合用于鲁棒训练。
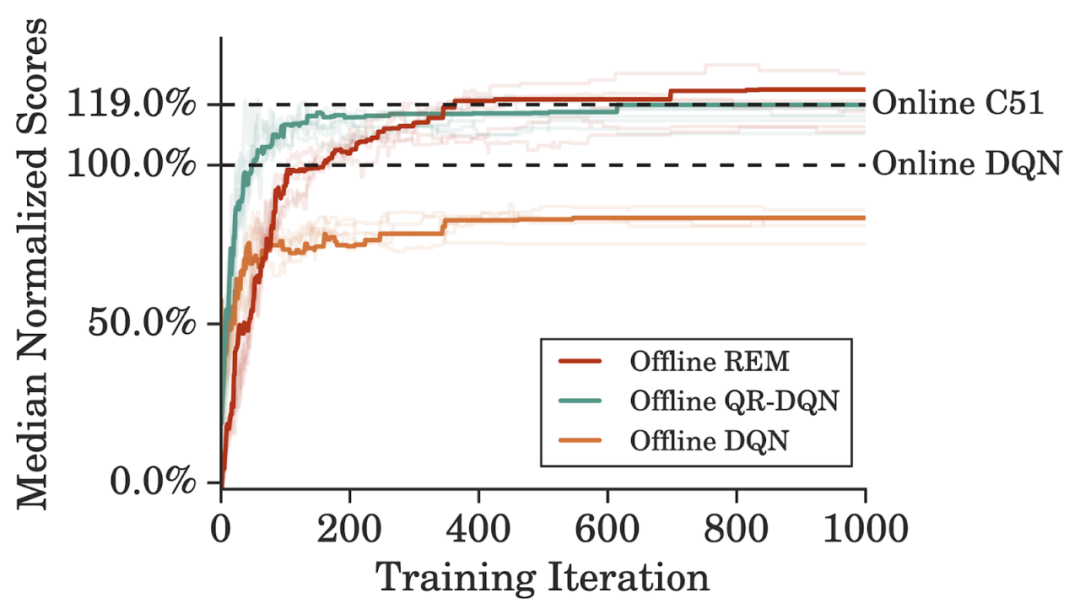
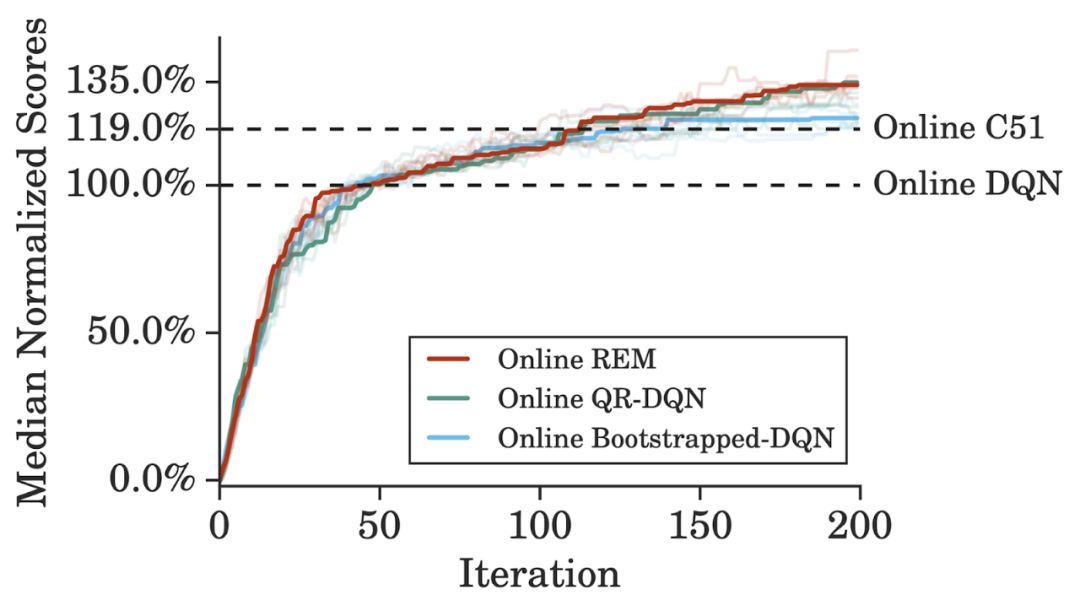
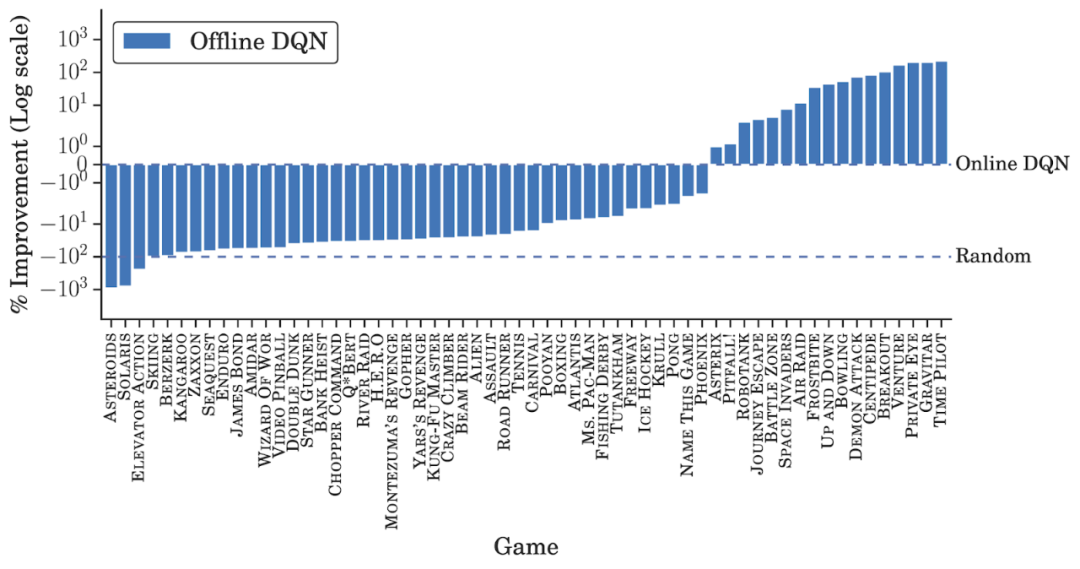
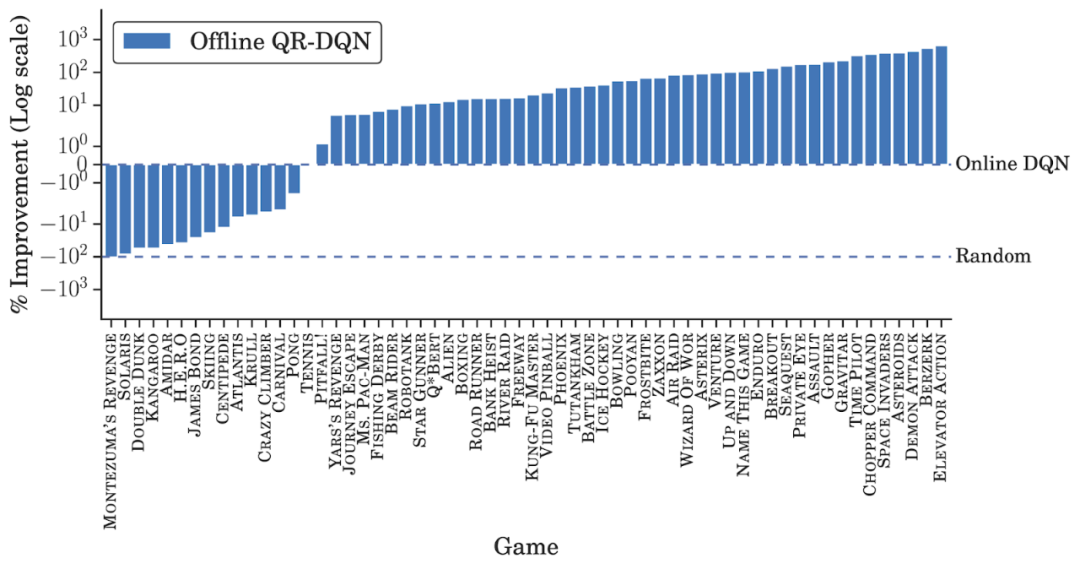
离线数据集大小。谷歌训练离线 QR-DQN 和 REM 所用的数据集是通过随机下采样整个 DQN 回溯数据集得到的简化数据,同时保持了相同的数据分布。与监督学习类似,模型性能随着数据集大小的增加而提升。REM 和 QR-DQN 只用整个数据集的 10% 就达到了与完全的 DQN 接近的性能;
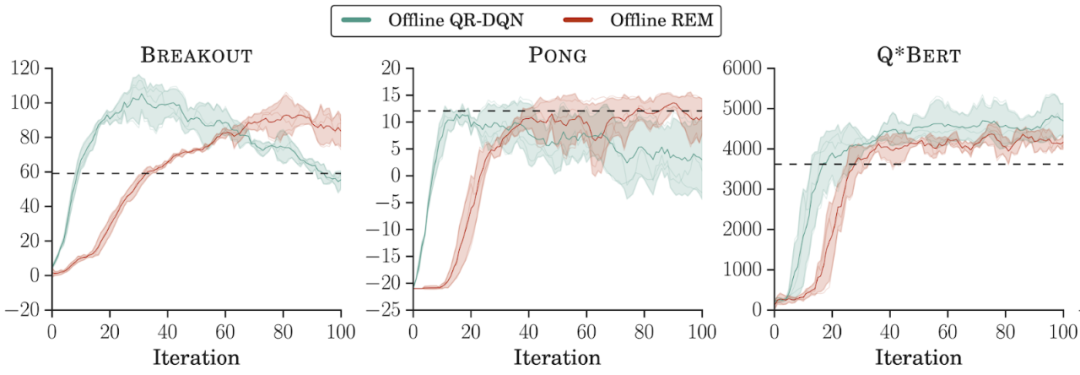
离线数据集的组成。研究者在 DQN 回溯数据集每个游戏的前 2000 万帧上训练了离线强化学习智能体。离线 REM 和 QR-DQN 在这个低质量数据集上的表现优于最佳策略(best policy),这表明如果数据集足够多样,标准强化学习智能体也能在离线设置下表现良好;
离线算法的选择。有人认为,在离线状态下训练时,标准异策略智能体在连续控制任务中会表现不佳。然而,谷歌研究者发现,最近的连续控制智能体(如 TD3)在大型、多样化离线数据集上训练时,其性能与复杂离线智能体相当。
登录查看更多
相关内容
专知会员服务
131+阅读 · 2020年4月19日
Arxiv
5+阅读 · 2018年4月3日




相关VIP内容
专知会员服务
131+阅读 · 2020年4月19日
相关资讯
相关论文
Arxiv
5+阅读 · 2018年4月3日