高二学生:Kaggle Whale 鲸尾识别分类银牌解决方案
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:杨乐涵
https://zhuanlan.zhihu.com/p/58081812
笔者介绍
杨乐涵,成都实验外国语学校高二学生,华中科技大学机器学习实习研究生,师从何琨教授,主要研究兴趣为计算机视觉。创新工场DeeCamp2018成员,Kaggle Expert(top 1.21%),两枚银牌,目前计算机视觉方向论文一篇。欢迎各位国内外的导师帮助我保送国内本科。
Team leader Khoi已经在kaggle discussion上发表了部分的工作
https://www.kaggle.com/c/humpback-whale-identification/discussion/82393
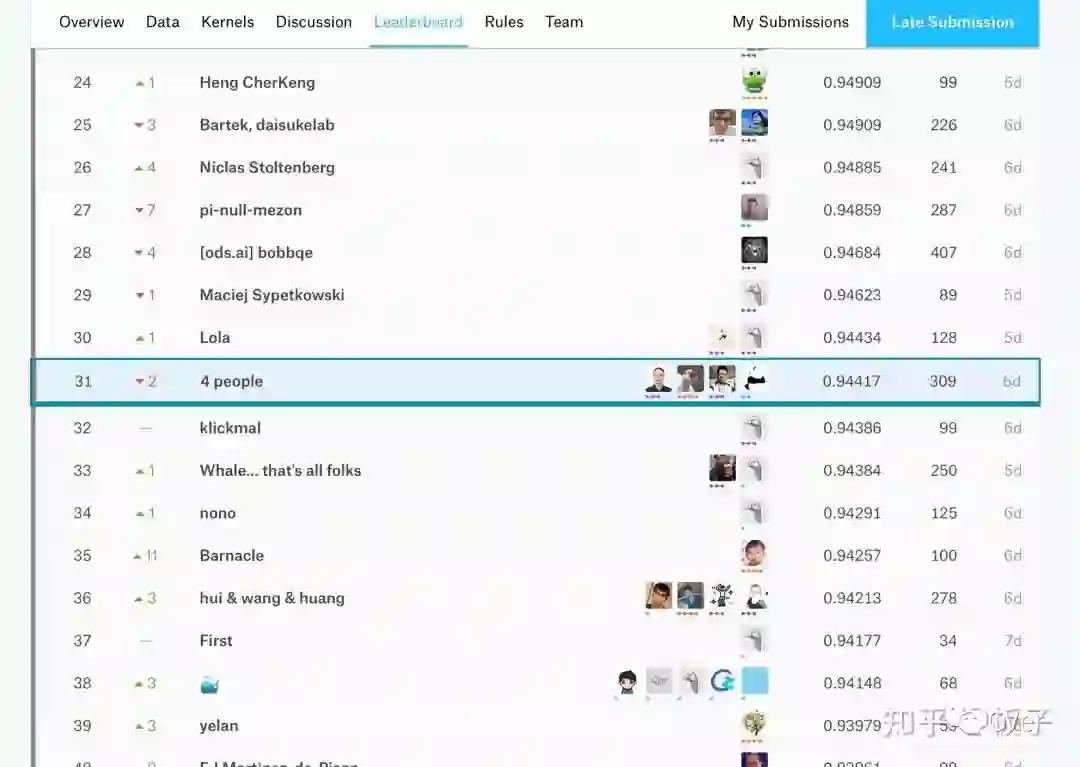
参赛人员:Khoi Nguyen、Iafoss、Hans Yang、Ocean
排名:31/2131(top 2% silver medal)
致谢
Martin,感谢martin在上一次kaggle whale playground比赛中的第一名代码和解决方案。
Alex Liao @AlexL,感谢Alex在比赛期间回答了我们很多问题,并且透露了一定的trick
Lu Yang,感谢西北工业大学的Lu Yang学长在比赛期间与我们分享他的test方法,是我们在public LB上能boost 0.02左右的分数
何琨,感谢何教授在比赛前期提供了一些关于one-shot的思路
interneuron,感谢interneuron在discussion提出的Images with text OCR方法,使我们在LB上得到了更优的方法
Guosheng Hu @Guosheng Hu,感谢胡博士在比赛前期给我们了专业的指导
代码&解决方案
代码:https://github.com/suicao/Siamese-Whale-Identification
模型结构:Siamese(cnn部分使用DenseNet121、DenseNet169、ResNet50、NasNetMobile)、ResNeXt50、SE-ResNeXt101、SE-ResNeXt152
1.使用ImageNet预训练模型,Iafoss的单模型分数最高的是DenseNet121(0.938LB)
2.我们尝试在前大约100个epochs使用384*384的小尺寸图像,再使用512*512尺寸的图像训练50 epochs,受限于计算资源,我们没有更大的显存或使用半精度来训练更大尺寸的图像,经过试验验证,使用大尺寸图像来训练会有更高的LB分数。
3.在使用TTA之后LB有所降低,所以我们最后没有使用TTA
4.我也曾经尝试过在siamese中使用nasnetmobile,不过nasnetmobile的训练速度实在太慢,以至于没能跑到100epoch以上
5.SE-ResNeXt101 152在训练过程中出现了一些小bug,在10 epoch左右的时候loss不再下降,尝试使用Adam和SGD都有同样的问题,最终因为时间问题并未解决该bug
6.ResNet50 正常分类训练,测试的时候不输出类的标签,直接提取特征向量(度量欧式距离最近的几个),new_whale不参与训练,仅参与测试。
7.最后通过多模型的融合达到了Private LB 0.94417
Additional:使用RGB而非Gray,我们最高的Gray单模型仅仅达到了0.89x
Happy Kaggle, Happy academic.
CVer竞赛交流群
扫码添加CVer助手,可申请加入CVer-竞赛交流群。一定要备注:竞赛交流+地点+学校/公司

▲长按加群
这么硬的竞赛分享,麻烦给我一个好看

▲长按关注我们
麻烦给我一个好看!



