我是最差的NLPer之Trie树

一 :今日吐槽
作为一个没有系统学过CS四大课程的NLPer,凭借一手百度+CTRL-C+CTRL-V的技能,混迹于技术中心,实属不易。
不要问我线程安全,问就是不会。
不要问我TCP三次握手,问就是不会。
不要问我二叉树的后序遍历,问就是不会。
知乎上有个问题:你见过最差的算法工程师能差到什么程度?
有个回答:
"我听过一个江湖潜规则,每一个大公司团队都会招一个特别不着调,水平也不行,智商也比较低的算法工程师,用来背低绩效。
当组里成员感到职业发展太难的时候,就会下意识看看那个人,这样,心里就会有莫大的安慰。
我当时下意识地看看周围的同事,发现他们都不符合这些描述。"
我也回头看了看钰轩君、费马君和其他同事,发现他们都不符合这些描述。
二:内容预告
自然语言处理还不是深度学习的天下。
传统机器学习算法如HMM、CRF、Kmeans,传统数据结构和算法如Trie树、AC自动机、动态规划,都还大有用武之地。
最近就遇到一个问题:如何做敏感词过滤。
网上查了一下资料,方案有两个:确定有限状态自动机(DFA)和AC自动机。
AC自动机又涉及Trie树和KMP算法。
这让我进一步想到NLP中常用的其他数据结构和算法:
query纠错中的编辑距离
ROUGE-L中的最长公共子序列
序列标注中的维特比算法
word2vec中的哈弗曼树
海量文本求topk相似的局部敏感哈希
看来,为了摆脱一年后失业的悲惨命运,传统的数据结构和算法是不得不学了。
本文整理Trie树的python代码实现。
本来还想基于Trie树,实现搜索引擎的自动联想功能,可是想想520还是一个人过,我还是放过自己吧。
本文关注以下三方面的内容:
什么是Trie树
Trie树的时间复杂度和空间复杂度
Trie树的python实现
三:什么是Trie树
大家好,我是Trie树,你们也可以叫我字典树或前缀树。
我擅长处理字符串匹配问题,即给定N条字符串的集合,我可以快速判断某条字符串是否在这个集合中。
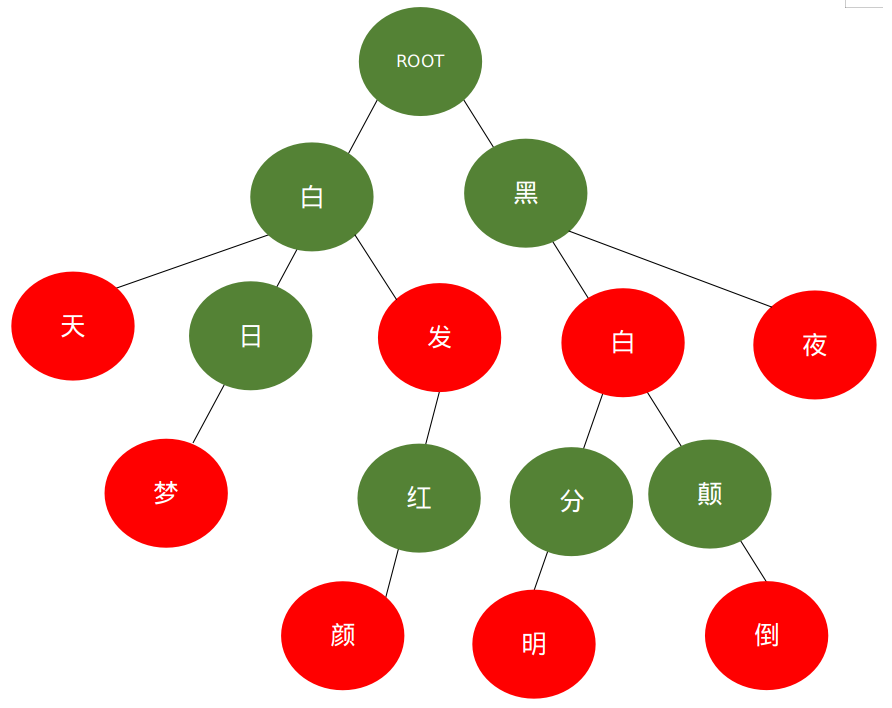
比如字符串集合中有8个词语:
["白天","白日梦","白发","白发红颜","黑夜","黑白", "黑白颠倒","黑白分明"]
我们需要判断 "黑白颠倒" 这个词语是否在这个集合中。
那么我是怎么处理这个问题的呢?
首先我会以树的格式存储这8个词语,如下图。
红色节点的意思是,从上往下到这个节点,是一个词语。
以字典的格式存储,如下:
{'白': {'发': {'Exist': True, '红': {'颜': {'Exist': True}}},
'天': {'Exist': True},
'日': {'梦': {'Exist': True}}},
'黑': {'夜': {'Exist': True},
'白': {'Exist': True,
'分': {'明': {'Exist': True}},
'颠': {'倒': {'Exist': True}}}}}查找时,我首先把 “黑白颠倒” 拆成【黑,白,颠,倒】三个字。
然后去字典中进行匹配,首先匹配中【黑】字,那么继续往下匹配,发现第一条路径的子节点为【白】,匹配中。
然后继续往下匹配,依次匹配中【颠】、【倒】,于是判断这个词语在字符串集合中。
可以看到,由于很多词有共同的前缀 【黑】,所以第一个字符匹配中【黑】之后,后面字符的匹配,我只在以【黑】开头的这棵右子树上去匹配就行,匹配的速度更快。
如果用纯粹遍历的方法,怎么查找呢?
那我还得拿 “黑白颠倒” 这个词,和以【白】字开头的四个词去比较,速度就慢了。
通过以上简单的例子,你大概也可以总结出我作为巨蟹座的三个特点:
根节点(ROOT)不包含字符,除根节点以外的每个节点只包含一个字符。
从根节点到特殊标记节点(红色节点),路径上经过的字符连接起来,为该特殊节点对应的完整字符串。
每个节点的所有子节点(字符)不相同。
我坚决贯彻以空间换时间的方针政策,利用字符串的公共前缀,减少无谓的字符串比较,从而降低查询的时间复杂度。
假设字符集的总数为m(比如英文中只有26个字母),如果需要存储的字符串的最大长度为n,那么树的每个节点出度为m(即每个节点可能的子节点数量为m),Trie树的高度为n。
我的空间复杂度为O(m^n),是不是很恐怖?
但是正由于每个节点的出度为m,所以我能够每次顺着分支(最多m个)往下查找,而不需要遍历所有的字符串。
我的时间复杂度为O(n)。
也就是说,如果要查询的字符串长度为n,那么查n次,就可以查到。
每个班都有一个灵活的胖子。
我通常出现在搜索引擎系统中,用于搜索提示和词频统计,也作为AC自动机的基本数据结构,用于敏感词过滤。

四:Trie树的实现
下面就用Python来写一棵Trie树,实现插入和查找字符串的功能。
#coding:utf-8
class Trie:
def __init__(self):
"""
Trie树。
如果到该节点为完整字符串,则标记为 Exist
"""
self.root = {}
self.word_end = "Exist"
def insert(self, word):
"""
插入单词。
如果某字符不是子节点,则作为子节点插入;
如果某字符已经是子节点,则共享该节点。
"""
curNode = self.root
for c in word:
if not c in curNode:
curNode[c] = {}
curNode = curNode[c]
curNode[self.word_end] = True
def search(self, word):
"""
查找存在字典树中的单词
如果查找到最后一个字符,没有标记为 Exist,则不存在
如果最后一个字符,被标记为 Exist,则查询成功。
"""
curNode = self.root
for c in word:
if not c in curNode:
return False
curNode = curNode[c]
if self.word_end not in curNode:
return False
return True
def startsWith(self, prefix):
"""
判断输入的词是否为字典树中的前缀
如果输入词的每个字符都是子节点,则为前缀
"""
curNode = self.root
for c in prefix:
if not c in curNode:
return False
curNode = curNode[c]
return True然后来测试一下:
if __name__ == "__main__":
trie = Trie()
words = ["白天","白日梦","白发","白发红颜","黑夜","黑白","黑白颠倒","黑白分明"]
for word in words:
trie.insert(word)
print(trie.search("白天"))字典树为:
{'白': {'发': {'Exist': True, '红': {'颜': {'Exist': True}}},
'天': {'Exist': True},
'日': {'梦': {'Exist': True}}},
'黑': {'夜': {'Exist': True},
'白': {'分': {'明': {'Exist': True}}, '颠': {'倒': {'Exist': True}}}}}返回:True。
五:Trie树的白板编程
拿出一张A4纸,来一个白板编程。

最近不知道自己在干什么,这篇写得很水,各位看官就当是在看笑话吧。
END
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。