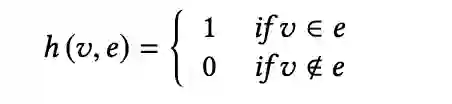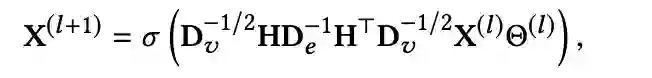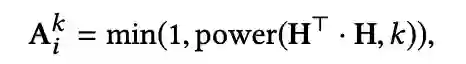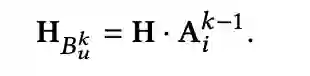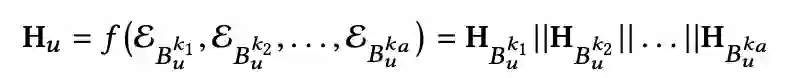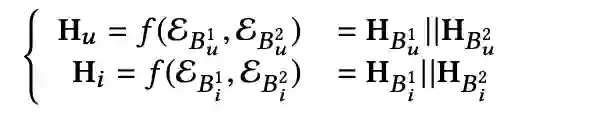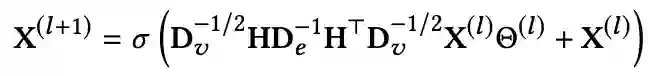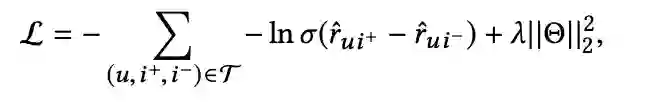论文:Dual Channel Hypergraph Collaborative Filtering
下载地址:https://dl.acm.org/doi/pdf/10.1145/3394486.3403253
“互联网推荐一点通” 是
火山引擎的
智能推荐团队运营的公众号,定期从各大顶会精选推荐/搜索相关论文,并从背景、方法、实验、创新点以及点评等五个方面对论文进行解读。
1. 背景介绍
协同过滤是在推荐领域非常普及的一种基础建模方式,传统协同过滤存在两个主要问题:
1.
user 和 item 之间的高阶相关性建模不充分;
2
. User-Item 建模不灵活,没有刻意对 user 节点和 item 节点进行语义区分,而是直接将 user 和 item 进行同质计算。
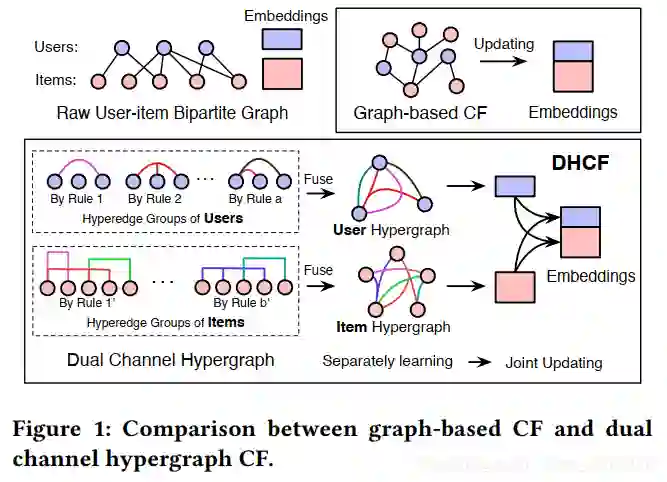
针对以上两个问题,论文提出了双通道超图卷积网络协同过滤的框架DHCF(Dual Channel Hypergraph Collaborative Filtering):
1. 为了学习到高阶相关性,在 channel 内部学习时,DHCF 使用超图来显式地建模 user、item 中的高阶相关性。
同时论文还提出了一种新的跳跃超图卷积(JHConv)方法,通过引入先验信息来有效地基于信息传播机制学习embedding;
2. 为了学习到 user 和 item 各自不同 embedding 表示方式,在协同过滤的框架中引入了divide-and-conquer 分治策略,双方先划分为 user channel 和
item channel ,channel内部各自自主学习,最后再统一集成输出。
这样在保持它们的特定属性的情况下,形成一个双通道协同过滤框架。
![]()
2. 方法介绍
2.1 基本定义
Hypergraph主要特点是一条边可以连接任意数量的顶点,即一个点集。给定一个超图
,其中
即一个普通顶点集(不是点集的集合),
是超边组成的集合(一条边可能对应多个点)。可以用关联矩阵
来表示超图中的连接。其中
是关联矩阵中的元素,其表示如下
![]()
其中有
和
,对超图定义点度
和边度
。最后可以定义点度对角矩阵
,和边度对角矩阵
。
有了超图之后可以定义超图卷积,给定超图关联矩阵
和第
层节点特征向量矩阵
。则定义超图卷积如下
![]()
其中
是可学习参数,它将第
层经过卷积操作后的特征向量映射成第
层激活函数
的输入。整个式子可以理解为两阶段消息传递机制,传播路径为vertex-hyperedge-vertex。
首先关联转置矩阵
把点信息传递到超边。
将超边信息传递到点。注意式子中间的对角度矩阵
和
起了正则化的作用,不影响消息传递可以被忽略。超图(HyperGraph)自然具有建模高阶连接的能力。此外,超图卷积可以处理高阶相关结构,作为一种有效而深入的操作。
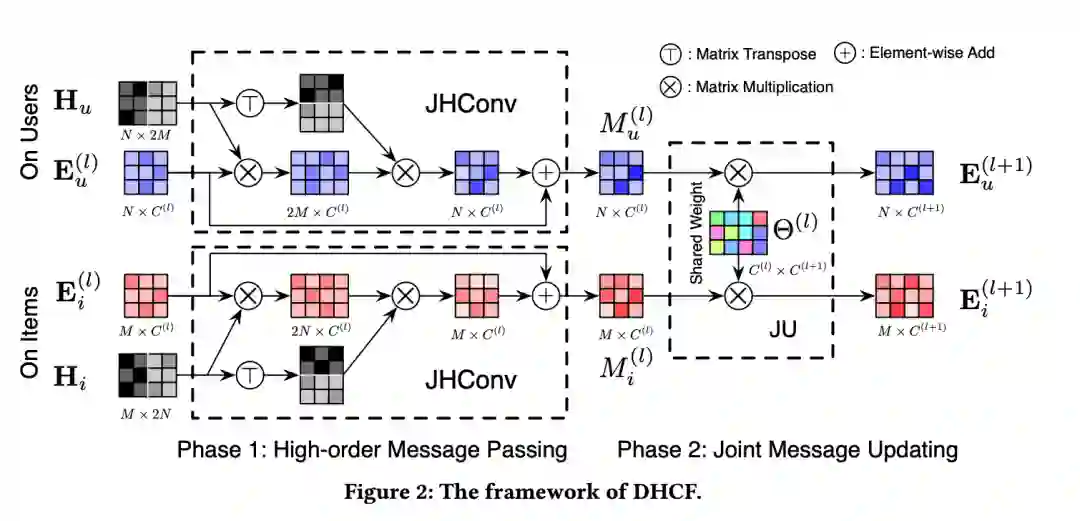
DHCF首先对于user和item各自学习了两组embedding。在学习到了embedding的基础上,再进一步通过user-item的embdding点积来拟合user-item的交互偏好矩阵。通过拟合拟合user-item的交互偏好矩阵,DHCF能学习到user 对 item 的偏好。
给定
个user和
个item的交互数据,首先构造超图关联矩阵
,并初始化user embedding向量
和item embedding向量
,DHCF框架大体分为两个阶段:
阶段1 - High-order Message Passing,高阶信息传递。此处对特征向量进行卷积);
阶段2 - Joint Message Updating,联合信息更新。
此处对卷积后的特征向量通过参数
进行全连接操作,再通过激活函数
,此处参数
在双通道之间是共享的。
![]()
下面定义高阶连通 High-Order Connectivity。给定user-item的二部图交互关联矩阵
,基于这个关联矩阵我们能够构造出用于模型训练的超图关联矩阵。
定义1:item 的 k 阶可达 item,在 user-item 交互矩阵中,如果存在一系列相邻节点在item_i 和 item_j 中,并且路径上的 item 数量小于k,item_i 是 item_j的 k 阶可达 item。
定义2:item 的 k 阶可达 user,在 user-item 交互矩阵中,如果存在一系列相邻节点在 item_i 和 user_j 中,并且路径上有 item_i 的 k 阶可达 item,user_j是 item_i 的,k 阶可达 user。
![]()
![]()
定义 || 为连接操作,user超图关联矩阵
,可通过如下数学公式表示
![]()
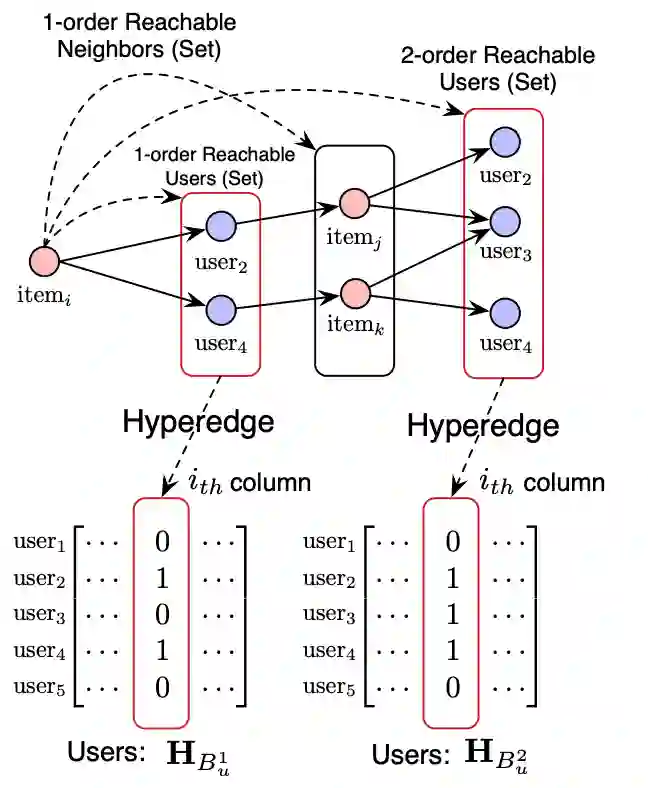
论文里只考虑了1阶、2阶连接,下图给出了如何构造user超图关联矩阵。
![]()
通过对称定义的方式,可以得到item超图关联矩阵
。总结数学表达式如下
![]()
本文使用的一个关键结构 Jump Hypergraph Convolution,在最初的超图卷积的基础上添加一个skip connect的连接,起到类似于ResNet中防止过深网络不可训练的效果,其数学表达式如下所示(本论文中最终采用的卷积方式还有略微不一样):
![]()
模型最终的数学结构可以如下表示,phase 1 对应 High-order Message Passing,phase2 对应 Joint Message Updating。
![]()
采用 pairwise Bayesian Personalized Ranking (BPR)loss来优化模型,如下所示
![]()
3. 实验
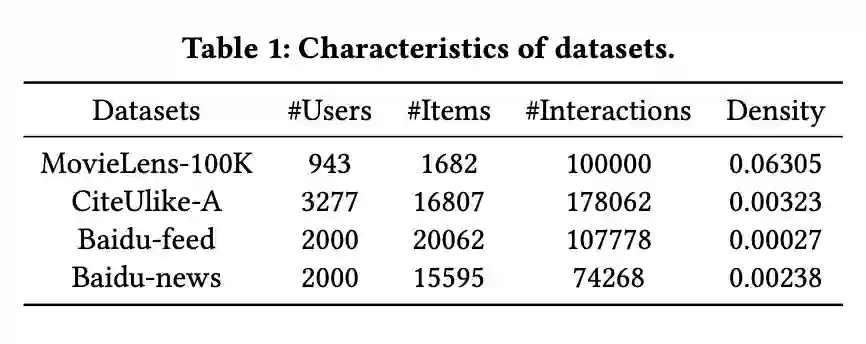
3.1 数据集设置
使用数据集如下,其中Baidu-feed和Baidu-news都是从真实数据集上随机抽取的,MovieLens 和 CiteUlike-A 则为公开数据集。
![]()
3.2 基线
选取的对比算法基线为 BPR-MF,GC-MC,PinSage,NGCF 等比较有代表性的建模方法,细节见下列各算法原文的引用。
![]()
3.3 实验结果
论文的实验,首先在四个数据集上,对比了准确率,召回率,ndcg,hit 等四个指标下和基线的差别,然后设计了消融实验
验证几个
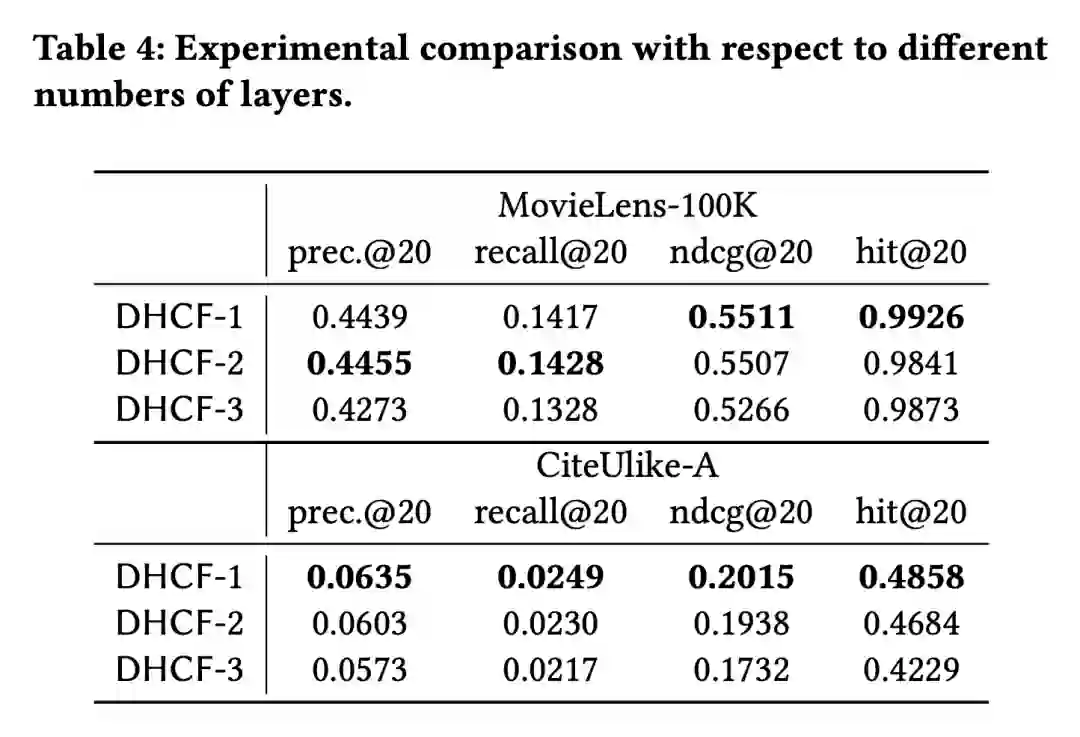
主
要设计对效果的影响,主要消融的部分为:skip-connection、网络层数、高阶连接。
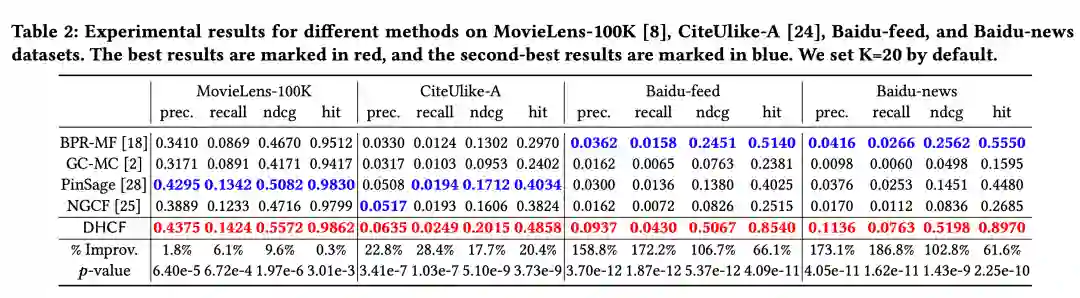
1. 下表为 DHCF 对比基线的实验结果,在4个数据集的4个指标上都有最好的表现;
![]()
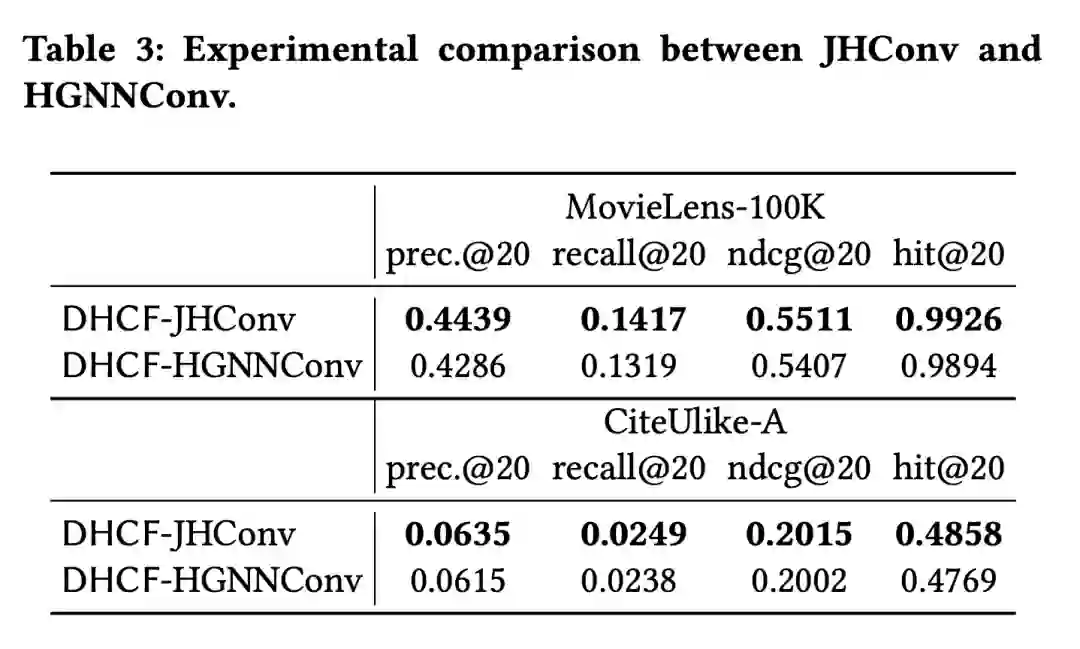
2. 下表为是否添加 skip-connection 对实验结果的影响;
![]()
![]()
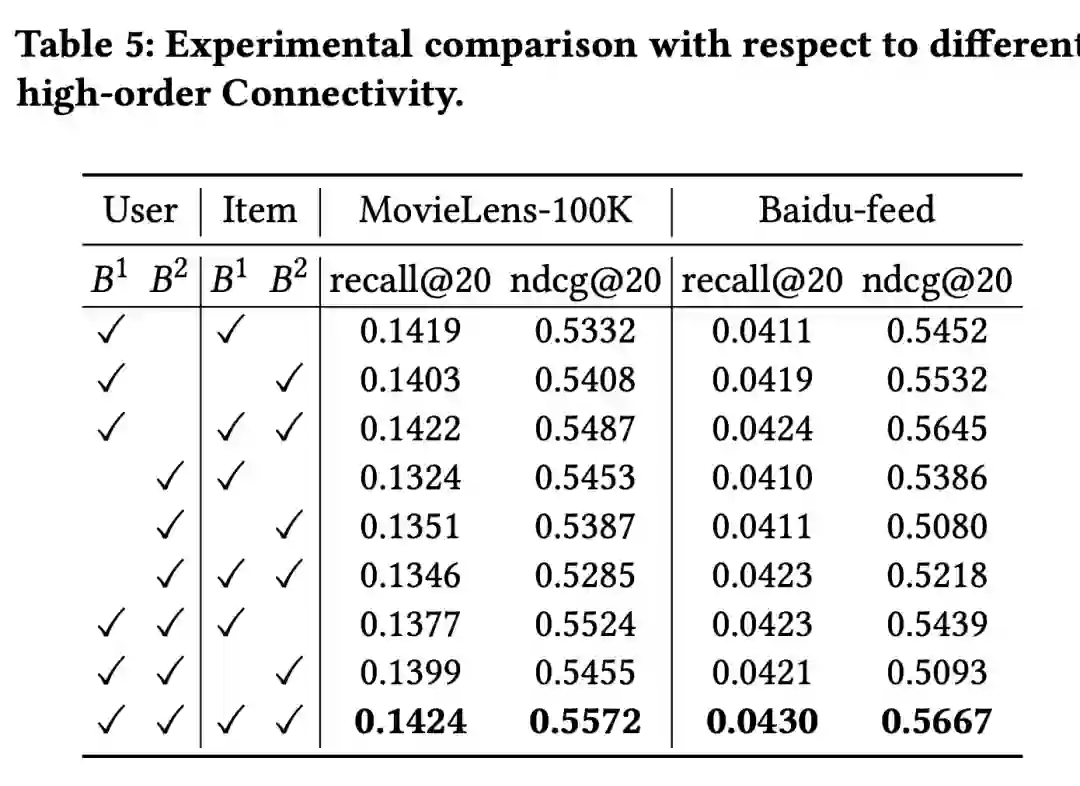
4. 下表为是否添加高阶连接建模对实验效果的影响,在 User 侧和 Item 侧都添加的效果最佳;
![]()
4. 创新点
分 User 和 Item Channel 进行学习,
形成一个双通道协同过滤框架,同时
使用超图
来显式地建
模 user、item
中
的高阶相关性,以更合理的方式对图所包含的信息进行提取。
扩展阅读:
https://blog.csdn.net/qq_44015059/article/details/108910037