使用上下文信息优化CTR预估中的特征嵌入

1、背景
特征交互的学习对于CTR预估模型来说是至关重要的。在NLP领域中的ELMO和Bert模型,通过单词在句子中的上下文环境来动态调整单词的embedding表示,取得了多项任务的效果提升。受到此思路的启发,论文提出了名为ContextNet的CTR预估框架,该框架可以基于样本信息对embedding进行优化,同时能够有效的建模特征之间的高阶交互信息。接下来,在第二节中对ContextNet进行详细介绍。
2、ContextNet介绍
2.1 整体介绍
ContextNet的整体结构如下图所示:
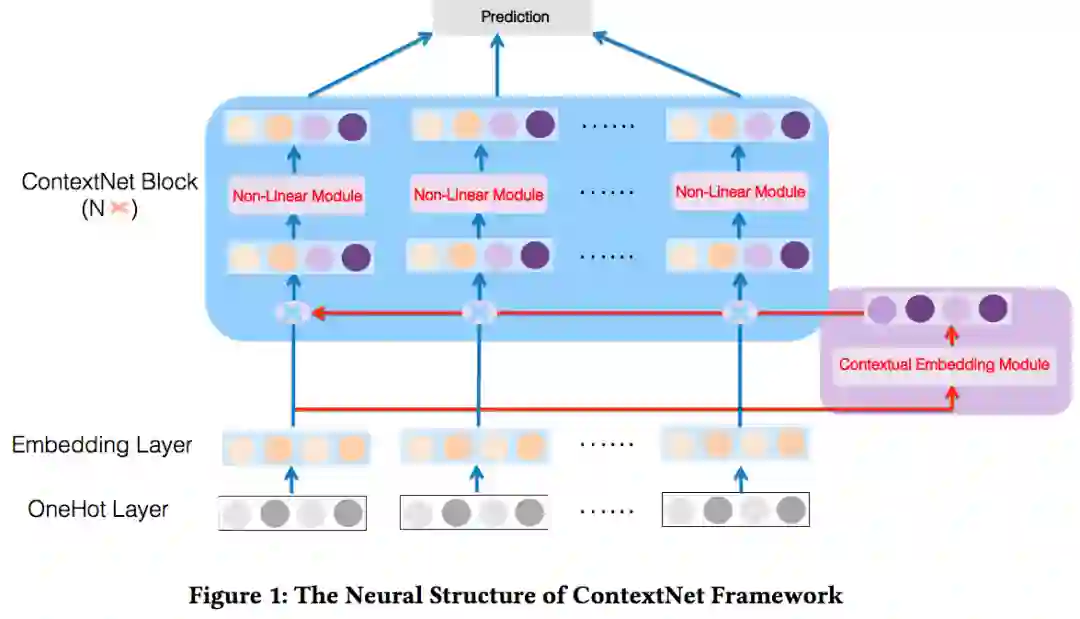
如上图所示,ContextNet包含两个主要的部分,分别为contextual embedding module 和 ContextNet block。contextual embedding module主要是对样本中的上下文信息(所有特征)进行聚合,并将这些上下文信息映射为与embedding同样长度的向量。ContextNet block则是进行embedding合并和非线性变换。接下来,分别对这两部分进行介绍。
2.2 Feature Embedding
在介绍主要的两部分之前,简单介绍下特征embedding的处理,对于离散特征,首先转换为对应的one-hot向量,随后转换为对应的embedding,对于连续特征,这里采用的处理方式为field embedding,即同field的连续特征共享同一个embedding,并使用特征值进行缩放(更多关于对连续特征embedding的处理方式,可以参考本系列的第118篇文章)。
最终,特征embedding层的输出计作E:
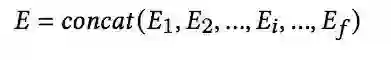
2.3 Contextual Embedding
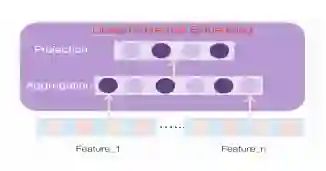
可以看到,主要包含了两层的网络,第一层可以看作是聚合层,第二层是映射层,用如下的数学公式进行表示:
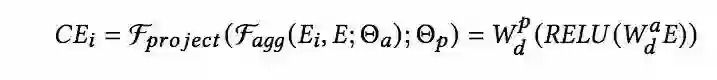
Contextual embedding module针对每一个特征,都会得到一个对应的Contextual embedding,那么为了平衡参数数量和模型表达能力,对于聚合层的参数,采用参数共享的方式,而对于映射层的参数,则是每个特征都有其对应的单独的参数,有点类似于多任务学习中的share-bottom结构。
2.4 ContextNet Block

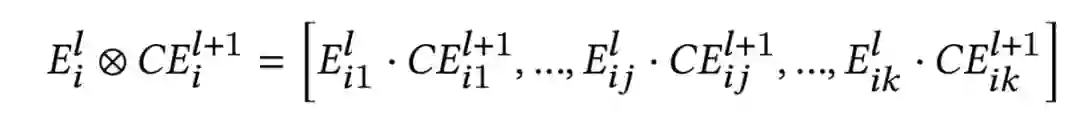
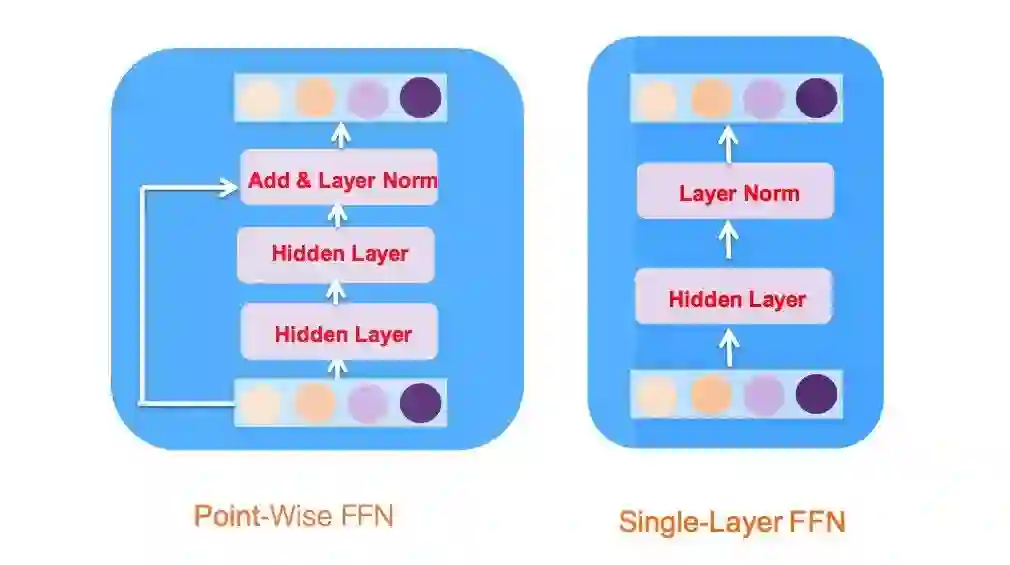
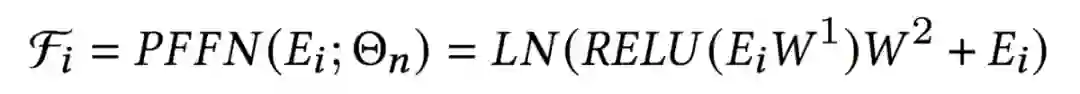
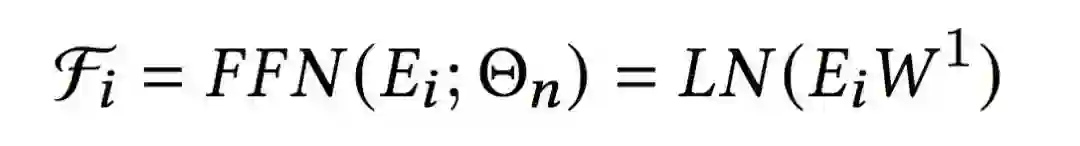
尽管SFFN从模型结构上来看比PFFN更加简单,但实际效果却比PFFN更好,在实验部分将给出具体数据。
3、实验结果
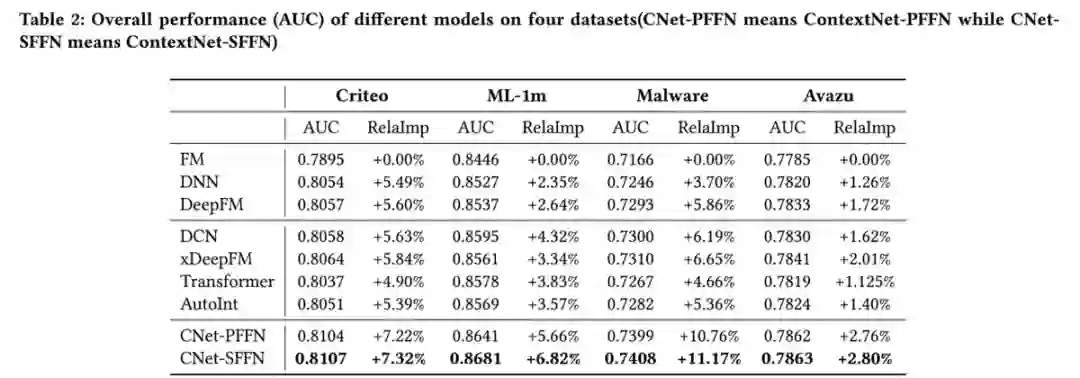
最后来看一下实验结果,与base模型相比,ContextNet在四个不同数据集上的AUC均取得了一定的提升,同时SFFN的效果要好于PFFN:
本文介绍就到这里,感兴趣的同学可以阅读原文~~