【独家】百度朱凯华:智能搜索和对话式OS最新技术全面解读(65PPT)
新智元专栏
作者:朱凯华
【新智元导读】百度度秘事业部首席技术官朱凯华日前在上海计算机学会做了题为《AI赋能的搜索和对话交互》的报告,主要介绍了现在的百度搜索及度秘“DuerOS”系统。由陆奇领衔、百度全新组建的度秘事业部有什么技术干货?本文为你带来最详尽的解读。

很荣幸能够被上海计算机学会邀请来给大家做一个汇报,今天我讲的是AI赋能的搜索和对话交互。

简单介绍一下自己,我之前负责百度的搜索算法,现在技术负责百度的对话式操作系统DuerOS,所以今天分享下在工作过程中遇到的技术挑战,以及学习到的收获。

今天的演讲主要集中在以下两个部分:
AI赋能的现代搜索引擎——现在的百度搜索;
AI赋能的对话式交互计算机——我们现在正在做的DuerOS系统。
现代搜索引擎进展:两大挑战
首先看一下现代搜索引擎遇到的挑战。

现代搜索引擎面临两个重要挑战:1. 更好的建模搜索结果的语义相关性;2. 更直接地给用户答案。

第一部分讨论现代搜索引擎的进展时,我们主要分成:1. 通过语义匹配来提升语义相关性;2. 通过知识的帮助来给用户直接答案。

首先讨论语义匹配的部分。

更好的建模语义表达能力(representation capability)是不断改进语义匹配能力的基础。

我们通过经典的BM25匹配算法(信息检索的一个经典算法)来分析一下语义表达能力的基本组成部分。
关键词命中(Keyword hits):如果Document中的一个词(Term)是Query中有的,那么算法会认为这个Document和Query更相关,BM25匹配的得分更高。可以认为这个命中词对整体语义相关性有正向贡献。
关键词权重(Term weighting):通过TFIDF来决定每个命中词正向贡献的大小。
页面长度归一化(Document length normalization):如果Document的长度越长,这个Document和Query就更不相关(典型例子是:如果这个Document是一个词典,任何一个Query中的词在它中都出现),BM25匹配得分越低。可以认为Document中所有未被Query命中的词都会对整体语义相关性有负向贡献。
上面讨论的命中词对整体语义相关性的正/负向贡献,是语义表达能力的基础。

那么,我们就通过一个running example来讨论一下整个信息检索方向的发展史,它本身就随着语义表达能力的提升而不断前进的。
Running example的设定如下:
Query当中有A B C D E五个Term;
Document当中有X Ā B Y C D' Z七个Term。
我们要计算该Query和Document的相关性。
大家会注意到,Document中B和C都属于精确命中Query的Term,他们的对整体语义相关性的贡献可以认为已经被BM25讨论了,我们就不赘述。但是Document中没有命中Query的Term: X Ā Y D' Z,这些『未命中的词』对整体语义相关性的贡献的建模方式的改进,贯穿了信息检索理论的进化。
所以我们分成以下四个层次来讨论这些『未命中』的词对相关性的建模方式:
归一化命中
同义词命中
建模词与词之间“爱” 的关系
建模短语与词之间的“爱 / 恨”的关系

归一化命中主要表明两个词基本上是完全等价的,我们记作 A和Ā是1.0的关系。像这样基本等价的关系,会有一些词干提取(Stemming),拼写纠错,繁简体转换和数字格式归一化,上面在每种情况给了例子。

从归一化命中向前进一步,我们不要求两个词完全等价,放松要求他们只要有有类似的概念,基本可以互换,这就是同义词(Synonym)命中。在例子中记作 D和D'是0.8的关系(弱一点)。同义词有很多种,上面列举了一些例子。这都是百度系统中实际考虑的一些情况。

从同义词命中再前进一步,我们不要求两个词概念类似,而是有一种弱的『爱』的关系就行了。比如X虽然没有出现在Query中,但是因为Query中出现了E,我们认为两者的相关性有一个小提升(0.2),Y的贡献是0.05,Z的贡献更小是0.03。
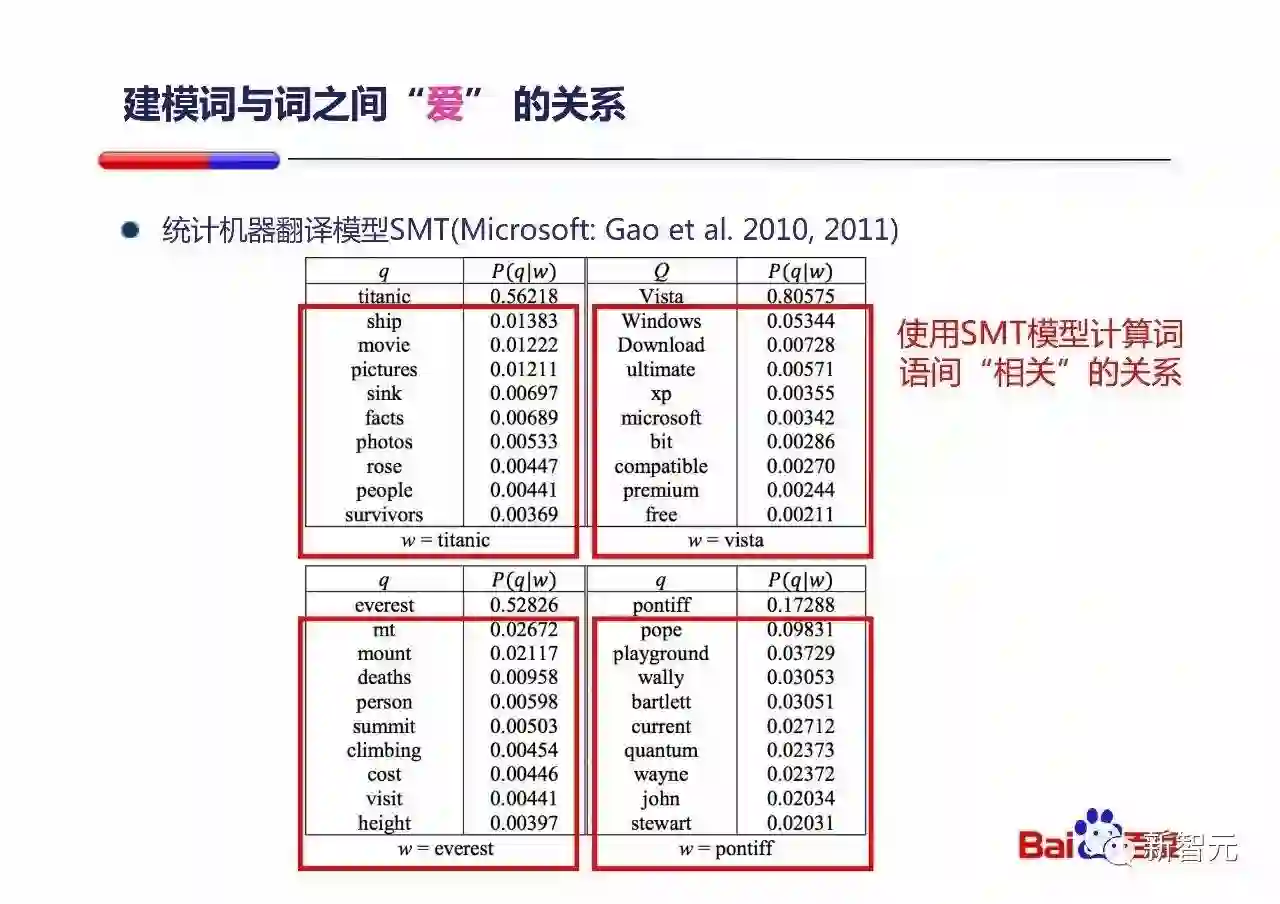
建模词与词之间『爱』的关系的一个有价值的工作是Gao Jianfeng在微软做的一个基于统计机器翻译(SMT)的一个模型,它通过SMT来计算词语之间『爱』的关系。
看一下表中的例子:
如果用户Query中有vista,那么如果一个Document中,出现了Windows, download,甚至是free,都会让系统认为这个Document更相关。
如果用户Query中有titanic,那么如果一个Document中,出现了ship, pictures,甚至是rose,都会让系统认为这个Document更相关。

上面这三种建模方式其实本质都是相同的:都是对任何一个query中的词,建立一个相关词的列表,每个相关词配上一个权重,如果Document中出现了任一个相关词,都会得到大小不等的正向贡献。(例子中,归一化是1.0;同义词是0.8;SMT是更小的权重)
但是,这样的建模方式有一个根本性的限制,就是相关词列表不能太大,否则模型大小会爆炸,无法实用。

在这三种建模方式更前进一步,我们希望能够建模词与词之间,短语与词之间『爱/恨』关系。比如Query中出现短语[C D E],那么Document中出现X的时候,系统能够认为这个Document更不相关。
通过语义匹配提高语义相关性:百度的例子

我们来讨论下百度如何通过DNN模型来建模短语与词之间的『爱/恨』关系。
首先Word embedding非常重要,它能够把词映射到一个低维(128维或256维)的稠密向量上。任意两个向量都能计算距离(cosine),而且距离有正有负(对应词之间的『爱/恨』关系)。
百度通过100亿的用户点击数据来训练一个DNN模型,该模型有超过1亿个参数。该模型2013年12月第一次上线,之后持续给百度的相关性带来非常大的提高。(2014年之后数据由于保密原因,不方便透露。)
据目前所知,百度是全球第一个将深度学习模型应用到实际网页搜索系统中的公司。(Google在2015年7月上线RankBrain,将深度学习模型应用到搜索系统中。)
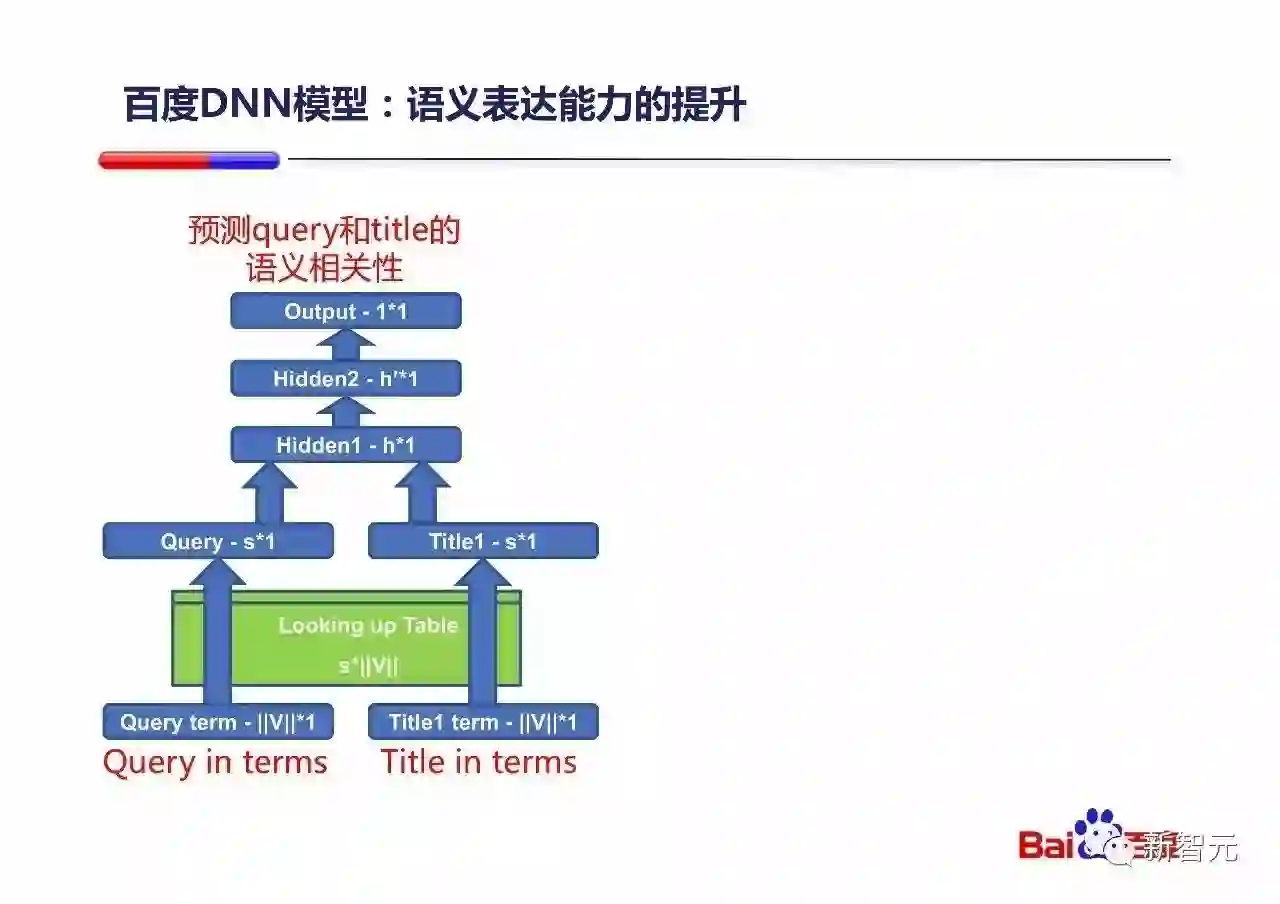
该DNN模型初版结构如上图所示,输入是Query中的Term和Document的Title中的Term,最终输出是对这个Query和Title对的语义相关性预测值。其中 S*|V|的Looking up Table是word embedding层。
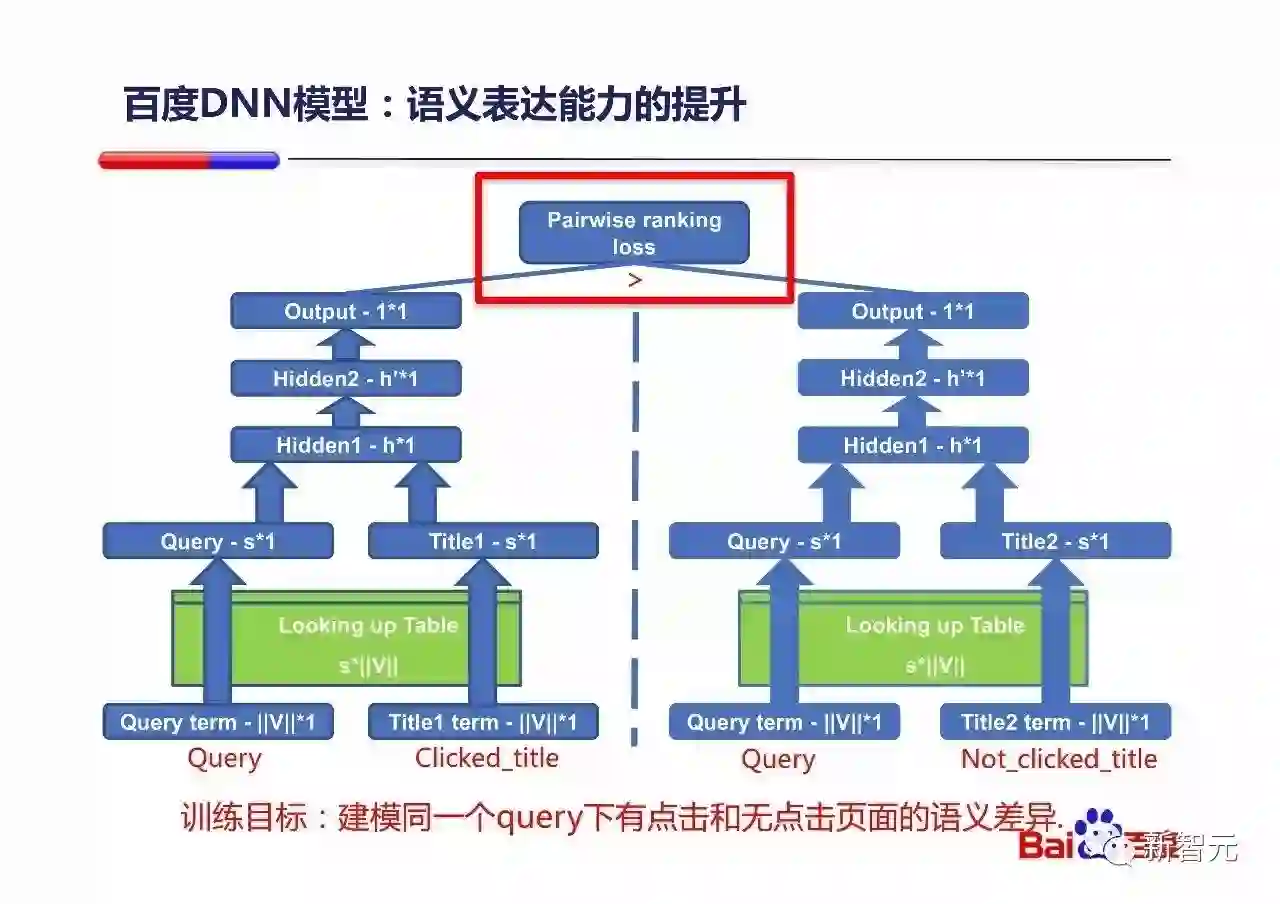
该DNN模型的训练是通过同一个Query下有点击和无点击的title构成Pair来进行Pairwise loss的训练的。这样构建训练样本的好处(比如相对DSSM来说),它能够在原有百度很好的页面相关性的基础上进一步捕获微妙的语义差别,让模型来专注于语义的差别。

举一个例子,在2013年上线DNN模型之前,如果用户查询百度『ghibli车头如何放置车牌』,由于这款玛莎拉蒂旗下的豪车可能在中国卖的不多,所以相关内容非常少。
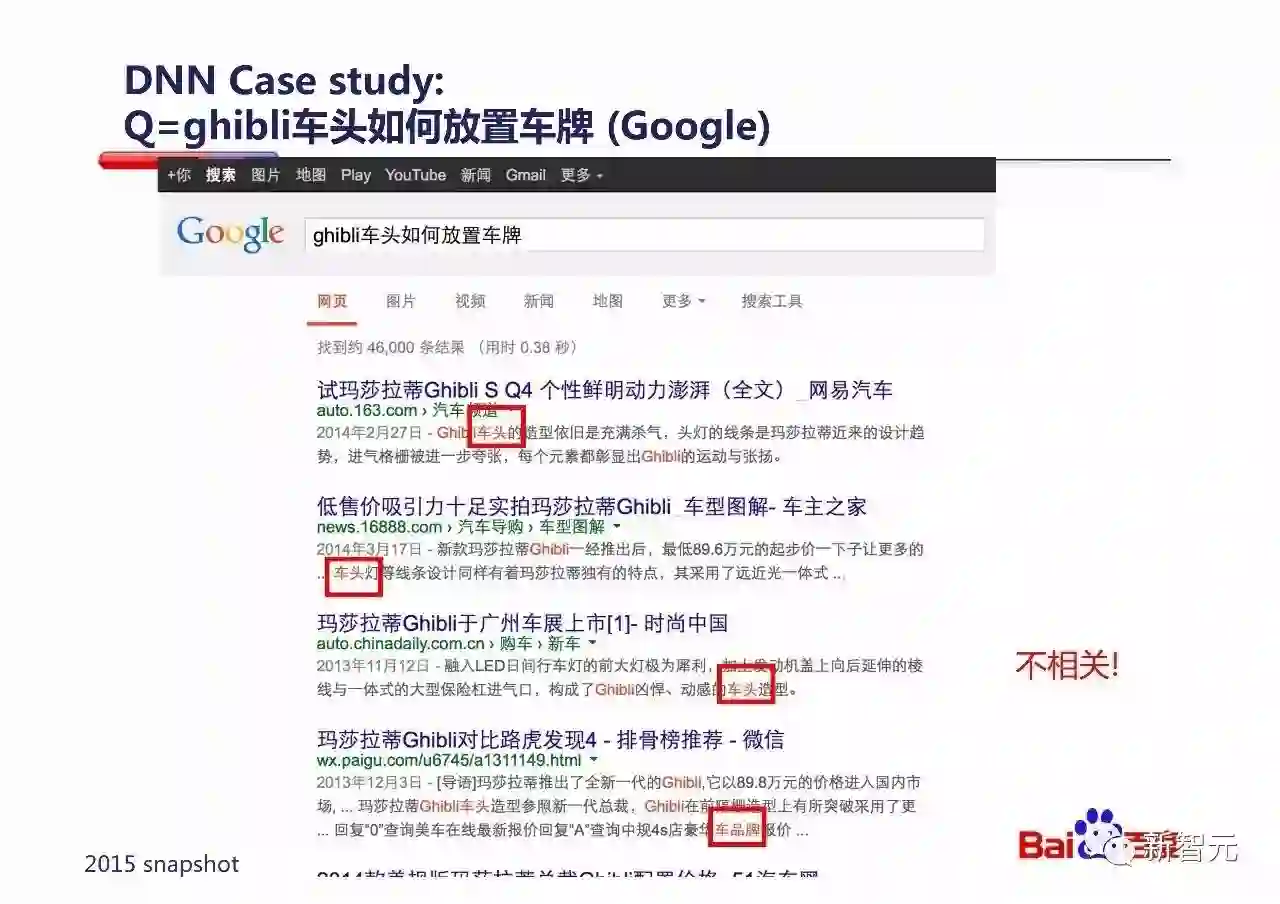
就算查询2015年的Google(2015年snapshot),结果和百度2013年之前的那个一样不好,都是在做字面匹配。

但当百度上线了DNN模型之后,大家可以看一下,搜索结果立刻明显改善了。排上来的结果虽然字面不是精确重现Query的问法,但是语义角度都是能够回答这个Query的。

仔细分析可以看到,DNN模型成功捕获了Query中『车头』和Document中『前』、『前面』的语义关系;捕获了Query中『如何放置』和Document中『放哪里』、『怎么装』、『咋挂』的语义关系。
其实这是在训练的100亿样本中,有一些样本体现了这样的语义关系,被DNN模型学习到了。两个例子如上图,那是两个用户点击过的Query/Document对。

再看一下进一步分析的例子:
如果Query和Document1都完全相同是『三岁小孩感冒怎么办』的时候,DNN的预测分数是-15;如果我们在Document1后面加『宝宝树』,预测得分立刻大幅提高了(升到-13),虽然『宝宝树』这个词没有出现在Query中,但是DNN模型认为这个词和query其他部分是有语义相关关系的,所以给出了正向的贡献(『爱』)。如果我们在Document1后面加了『搜房网』,预测得分立刻下降了(降到-15.8),因为DNN模型认为这个『搜房网』的出现和query其他部分语义更不相关,所以给出了负向的贡献(『恨』)。这个例子中,其实D2、D3和D1的区别都是增加了一个和Query没关系的Term,在传统的Information Retrieval中是一定会给D2,D3一样的相关性得分,而区别不出两者的差异。
后面两个例子类似,DNN能够区分『宝宝』和『小宝宝』类似,而和『狗宝宝』语义不相关。『励志格言』与『格言』类似,而『幼儿教师』和『幼儿』语义不相关。

所以DNN模型与现代搜索引擎的结合是必然,其发展方向大概是以下几个:
用更多数据和更好的体现搜索特性的标注:权威性、时效性、多样性……
更好的理解和调试DNN模型,只用SNE这类工具简单看一下是远远不够的。上面的一些例子分析就是一些如何更好调试DNN模型是否符合预期工作的一些示例。
通过CNN来更好的建模短距离的依赖关系,百度第一个CNN模型2015年1月上线。
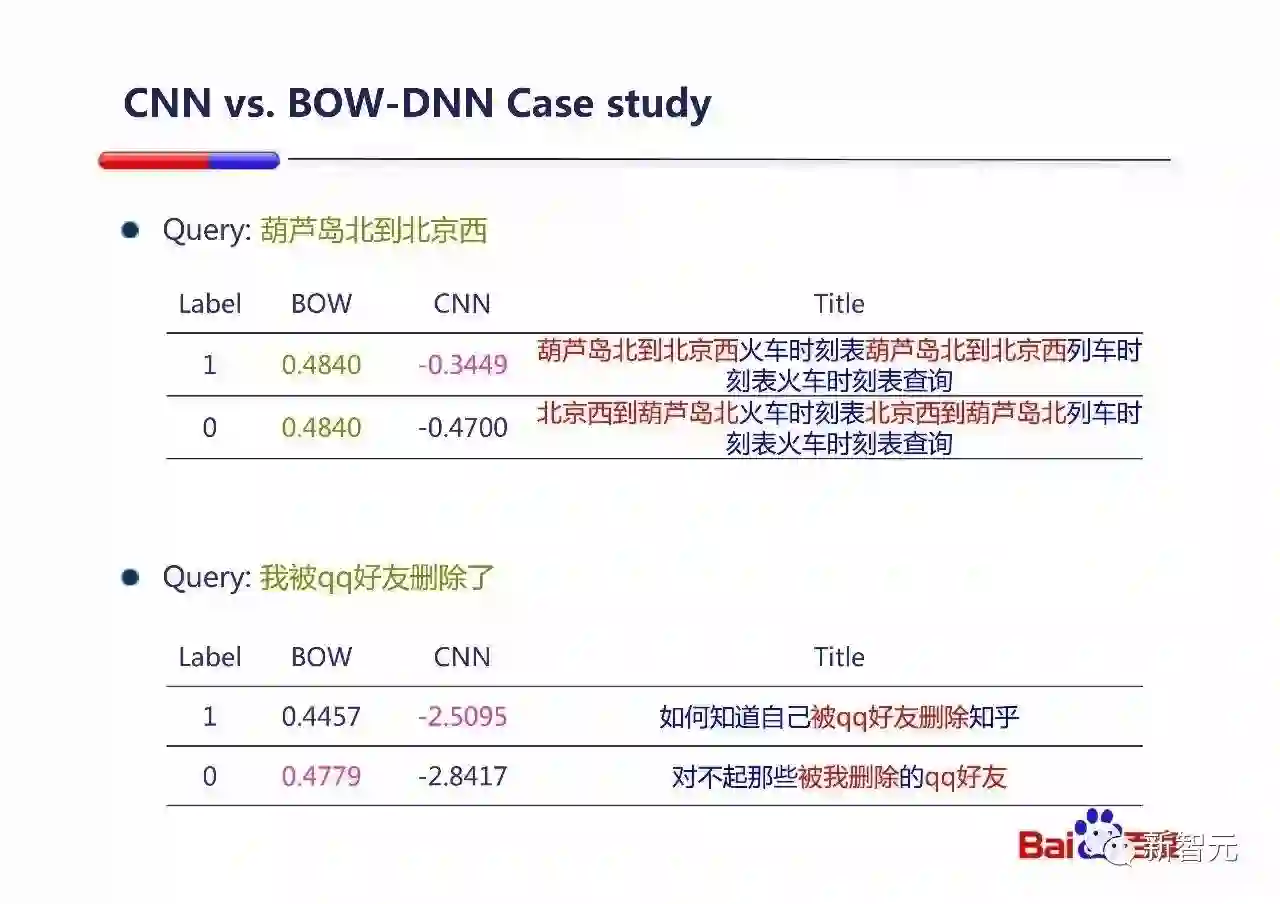
这个是CNN和Bag-of-word(BOW)的DNN对比的例子。
在第一个例子中BOW模型因为不考虑顺序,所以无法区分是从『葫芦岛北到北京西』还是『北京西到葫芦岛北』,给出一样的得分。而CNN模型能够知道哪个才是更加语义相关的。
第二个例子中CNN模型也能更好的区分『被我删除的QQ好友』和『被QQ好友删除』。

更进一步的改进方向是通过RNN赖建模长距离的依赖关系。百度在2015年7月时第一次上线RNN模型,对整体效果带来了很大提升。

这个例子可以看出,RNN对建模有跳跃的概念是非常有效的,如例子Document中:『宽屏X电脑XXX玩魔兽XXXXXX』;『沙田XXX到迪斯尼XXXXX地铁XXXX路线XXXXX』。

总结一下第一部分:我们可以通过使用DNN/CNN/RNN来更好的建模语义匹配程度,进一步提升语义相关性。(出于保密考虑,演讲提到的都是百度2~3年以前的工作。)

引入“知识”直接给出用户想要的答案:百度 PK 谷歌
接下来我们来讨论如何更好地通过引入『知识』来直接给出用户想要的答案。

随着设备越来越多样化,屏幕越来越小,现代搜索引擎都想给用户更少的links,更多的直接答案。

第一个很直白的方式就是通过在知识图谱上的推理,给出答案。
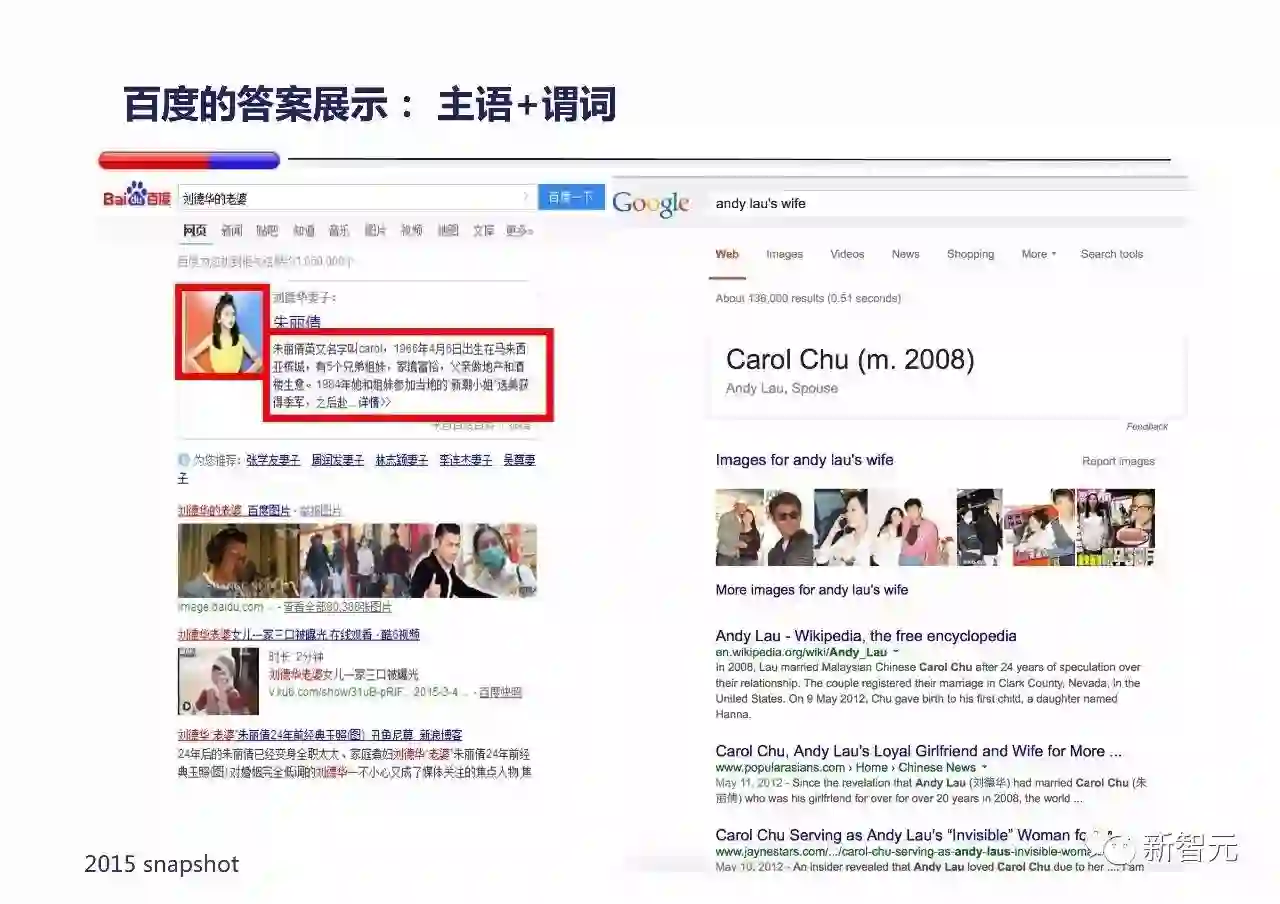
这边对比一下百度在知识图谱上的推理能力。
百度支持『主语+谓词』方式的推理,例子是『刘德华的老婆』,百度和Google都能给出答案。但从产品上百度更丰富的给出答案的详细信息。
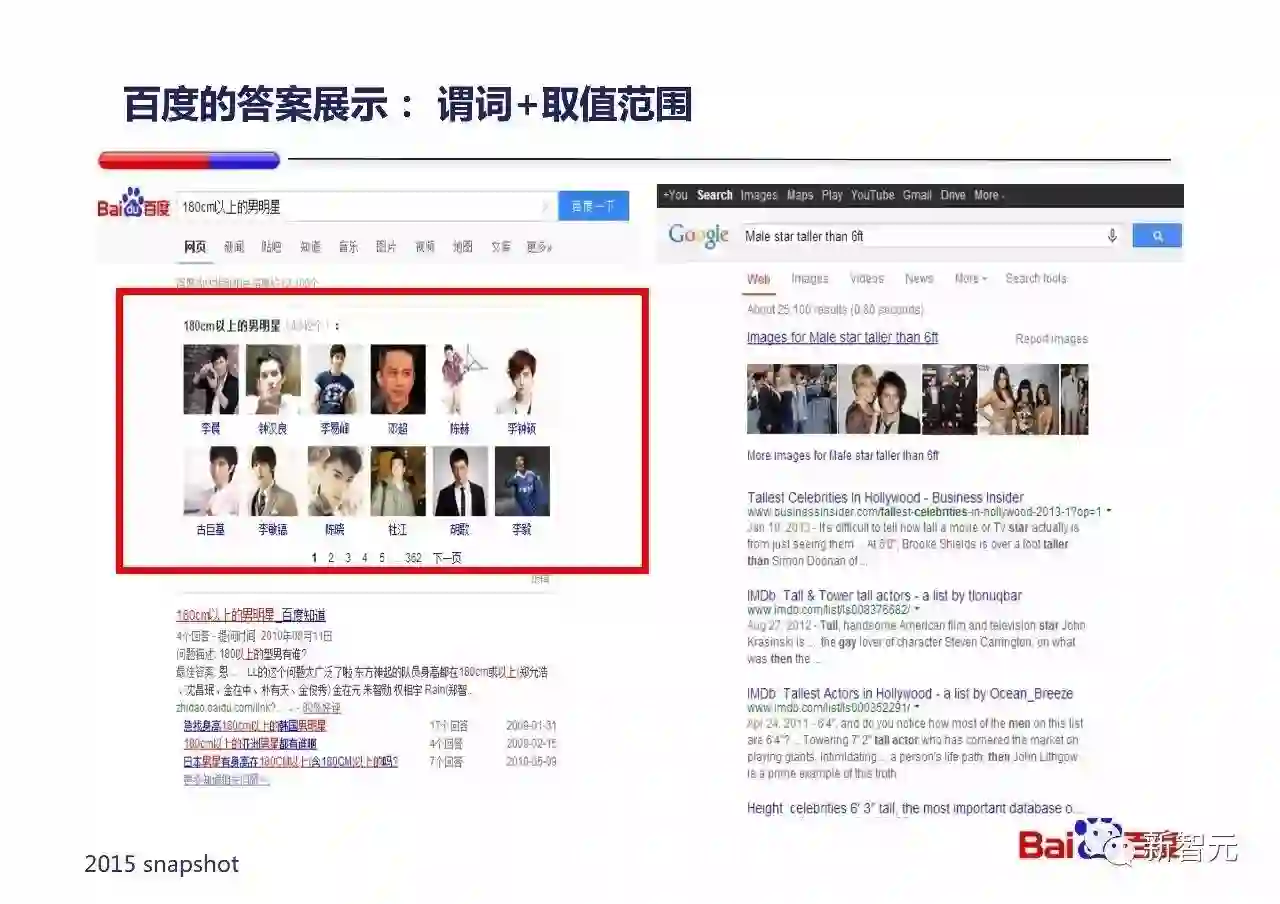
百度支持『谓词+取值范围』方式的推理,例子是『180cm以上的男明星』,百度能够给出符合要求的明星列表,Google不能给出答案。
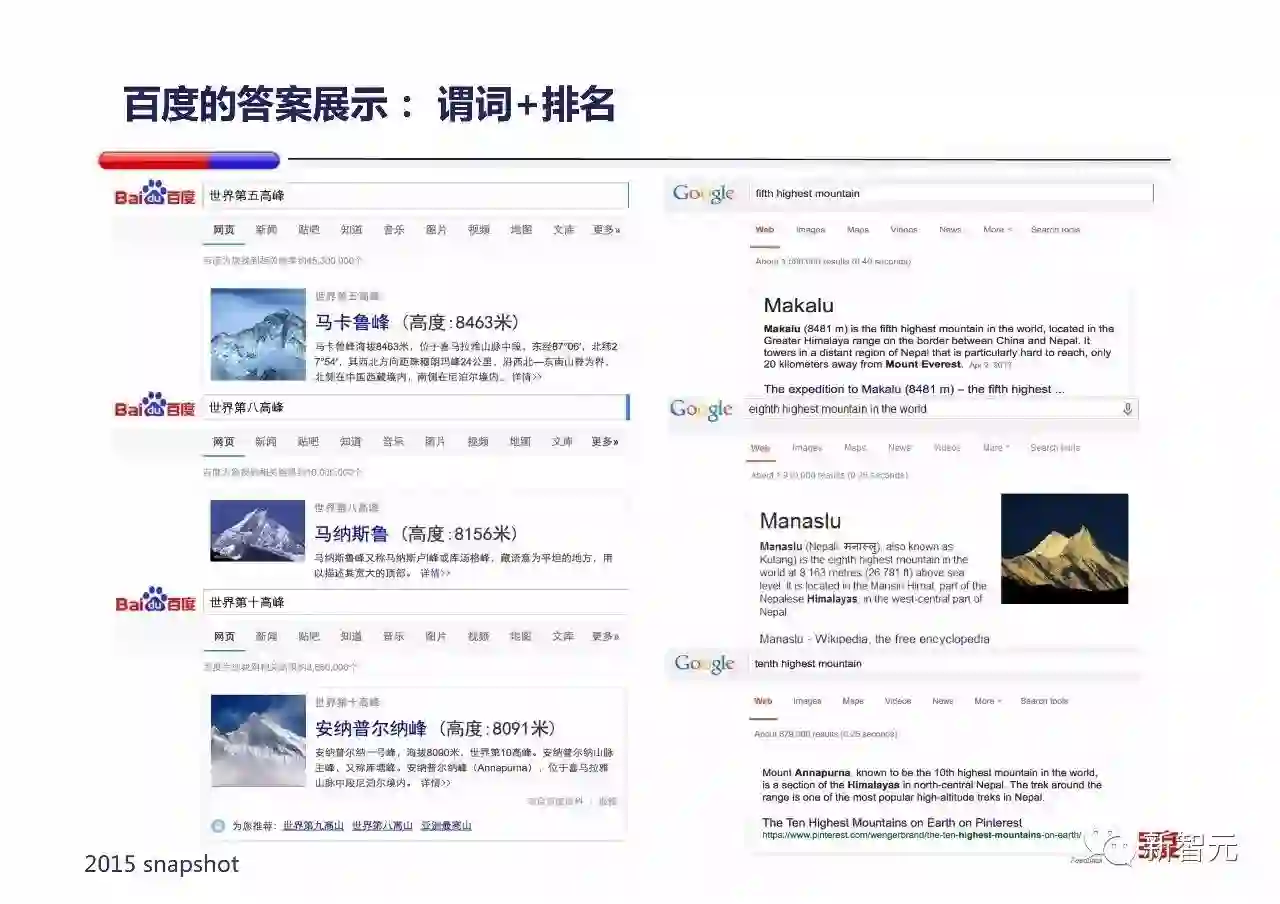
百度支持『谓词+排名』方式的推理,例子是『世界第五/第八/第十高峰』,百度能够给出符合要求的知识图谱卡片,Google给出的答案结构不一(有些是知识图谱卡片,有些是web answer卡片)。

百度支持多步推理,例子是『谢霆锋的爸爸的儿子的前妻的年龄』,百度能够通过多步推理给出答案,而Google不能给出答案(虽然真实用户不太会真的这样搜索百度,但是这个例子体现的是能力的差异)。

如何进行基于知识图谱的推理,这方面讨论很多,不多赘述。简言之就是按照知识先分析关系,然后在知识图谱上解释执行获取答案。上面的例子是『谢霆锋是谁的儿子』和『谢霆锋的儿子是谁』,虽然这两句话用词差不多,但是依存分析(Dependency Parsing)的解释完全不同,依据依存分析的解释,百度能够执行知识图谱查询并且获得正确的答案。
基于知识图谱推理的两大限制及三种解决方案
但是,基于知识图谱推理有一些关键的限制,限制之一是知识图谱有盲区(Blindness)。
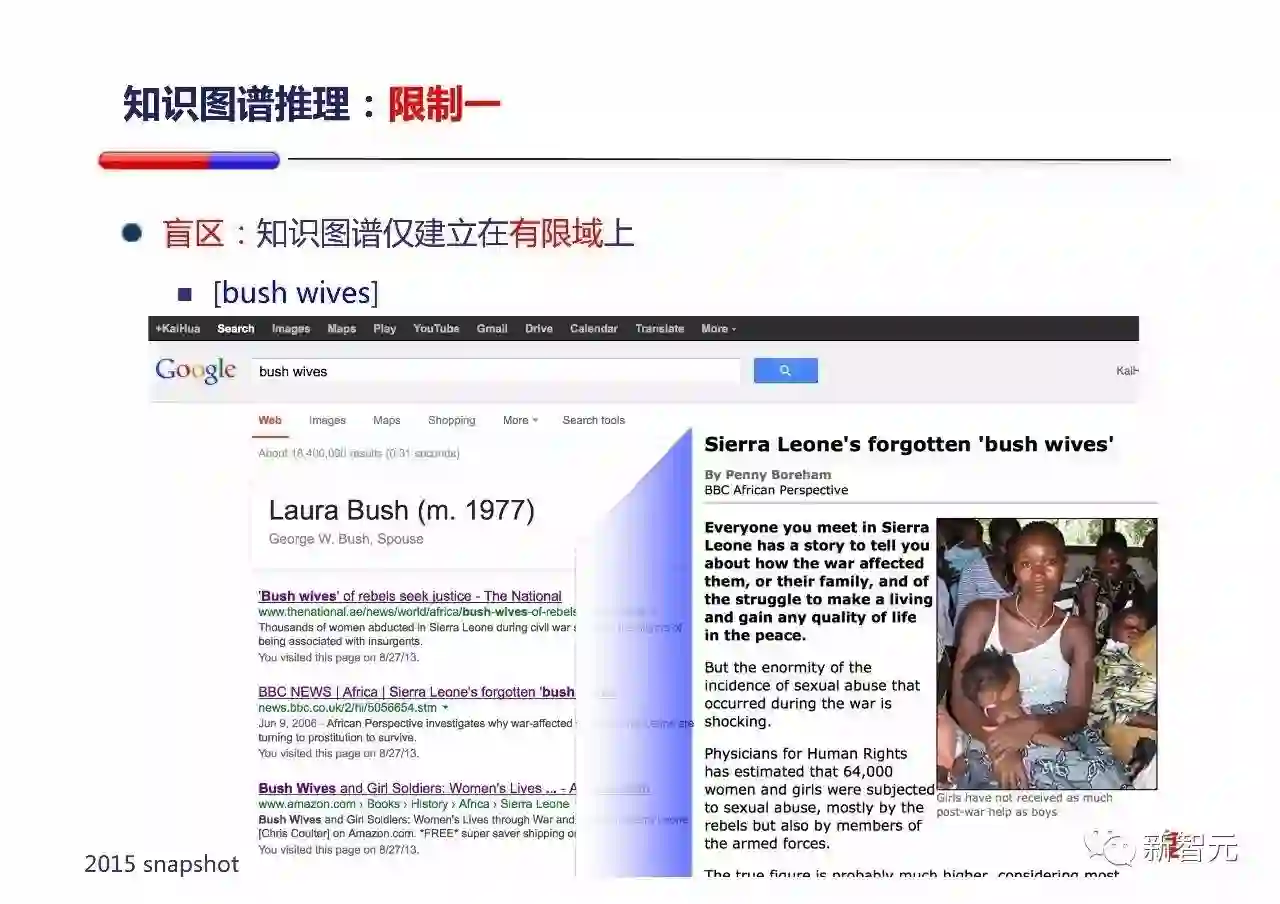
举个例子,看到『Bush wives』大家会猜到什么?一般都会理解为『小布什/老布什的老婆』(虽然wives复数有点奇怪)。包括Google在2015年的时候也是这么理解的(2015年WSDM演讲时的截图,后来Google修复了这个例子),但是如果仔细看一下头几条搜索结果,大家就会发现,bush wives讲的是非洲内战时,被掳获到丛林中充当慰安妇的妇女。
这就是典型的知识图谱的盲区问题,一旦某概念不在知识图谱其中,知识图谱会做一个它自己尽可能好的解释,但他可能和真正的解释相差很多。(一个类似的中文例子是『从百草园到三味书屋』,中国地大物博,确实有地名叫百草园,也有三味书屋,一个只关注地理位置POI的知识图谱就会觉得他是一个完美匹配导航需求的Query。但放大来看,大家都知道他是鲁迅的一篇散文。)

基于知识图谱推理的第二个限制是静态的图谱很难描述用户意图的分布以及变化。
举例来说,『天龙八部』这四个字,可以是小说,游戏,电视剧,电影。。。那么用户在一个上下文中说这四个字的时候,他到底要的是什么?如果世界上正好一部新的天龙八部的电影上映了,用户说这四个字的时候,他的需求分布是不是也应该相应改变?

由于以上限制,只通过只是图谱推理向用户直接提供答案是不够的,我们要其他方向的解法。

其他方向是『和搜索结合』。搜索能够帮助知识图谱解决盲区和意图分布的问题:
搜索能够看到全景:百度搜索索引了几百亿的页面,基本上涵盖用户各种需求的方方面面。
搜索能够提供用户真实意图的分布:有非常多的排序特征和用户反馈特征能告诉我们用户在各种上下文下真实的意图分布,并且会随着时间推移更新。
所以,搜索和知识图谱可以完美结合:
搜索可以为知识图谱提供上下文
知识图谱帮助理解搜索的Query和结果
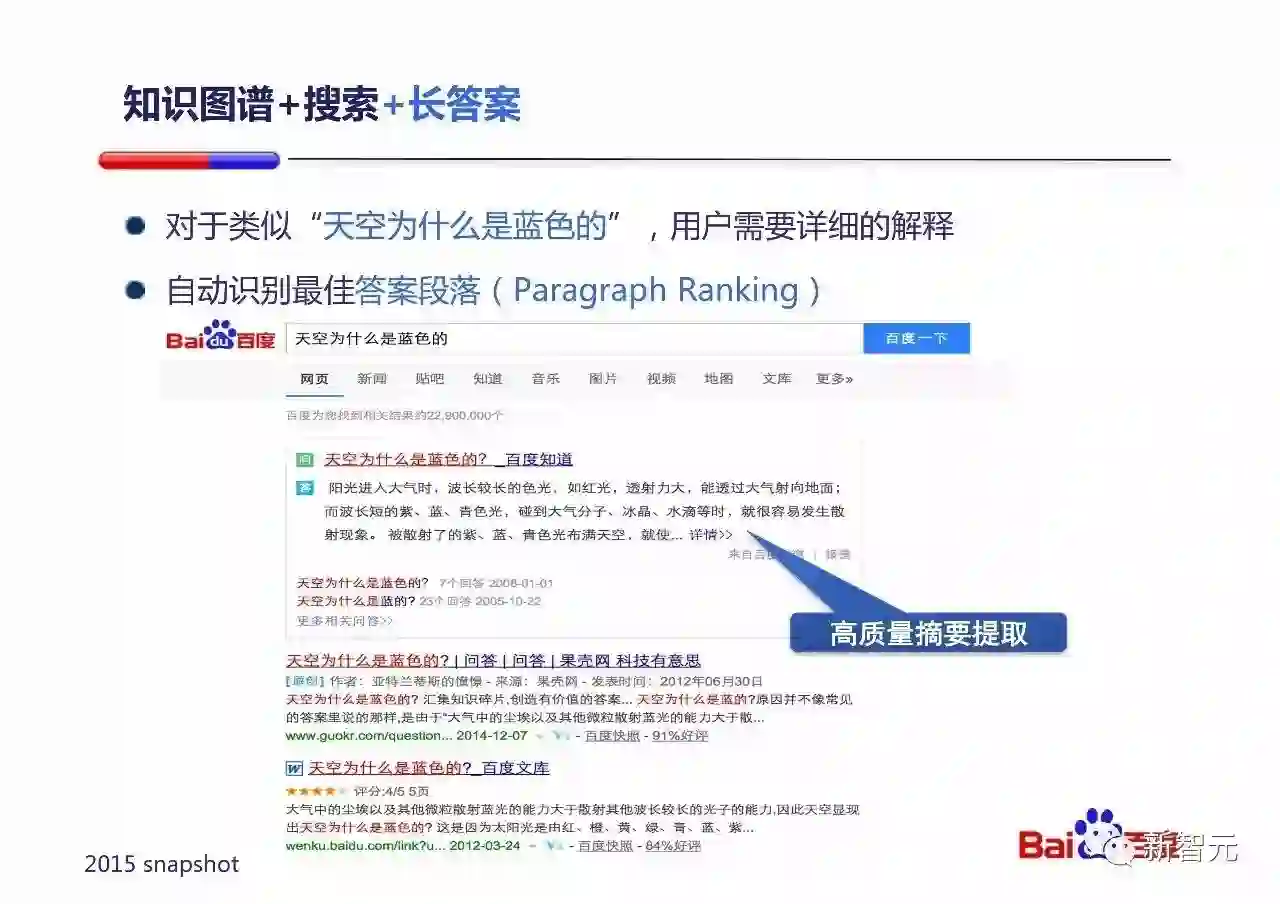
其中一种是两者结合来给用户『长答案』。
类似“天空为什么是蓝色的”这样的Query,用户需要详细的解释,我们可以把这个问题转化为在知识图谱的帮助下,自动识别最佳答案段落(Paragraph Ranking)的问题。这就会是一个百度很擅长的排序问题,我们能找出最精简描述『瑞利散射』的段落。
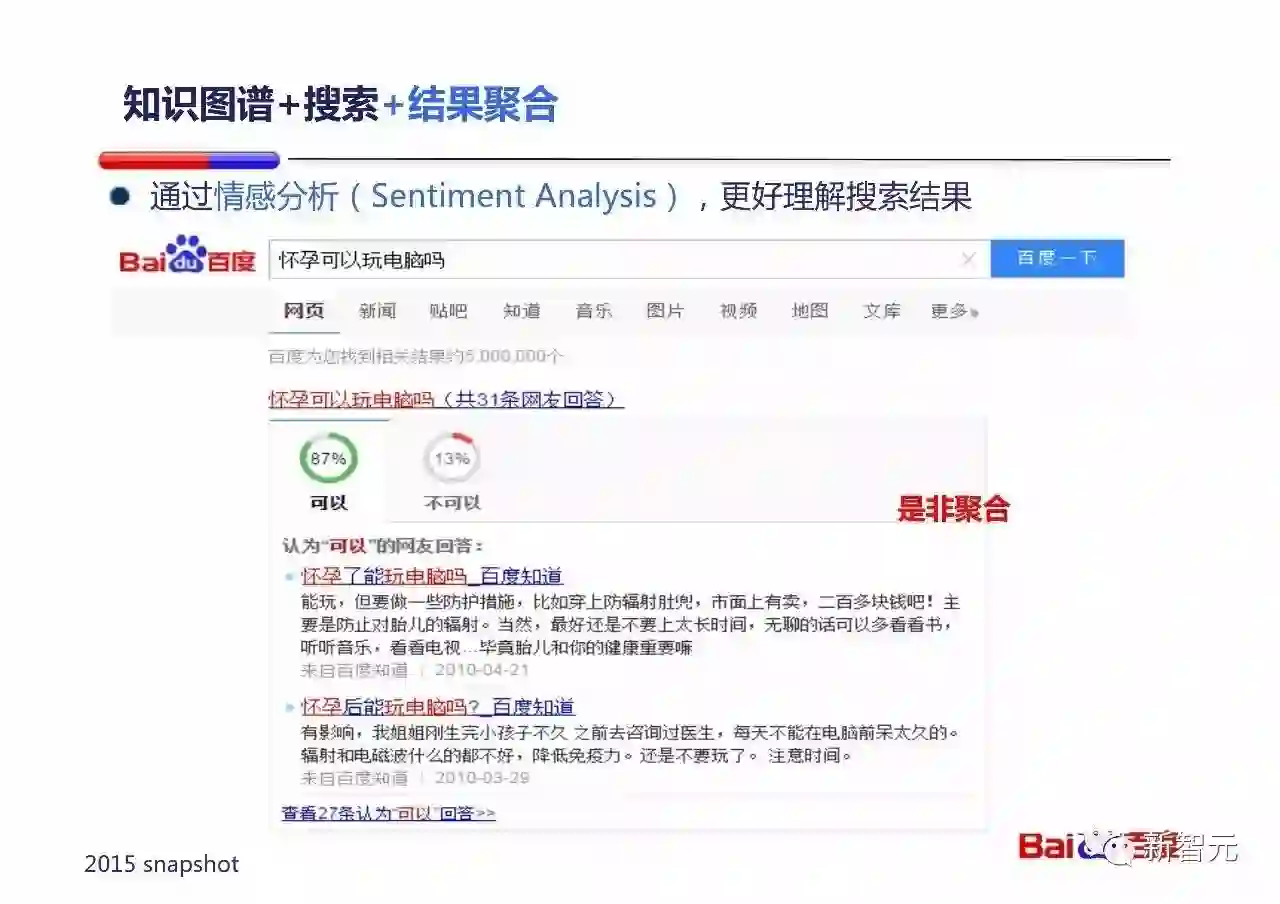
当知识图谱和搜索结合,我们通过情感分析(Sentiment Analysis),可以更好的理解搜索结果。
比如非常多人在百度上搜索『孕妇可以』打电话么?吃柿子么?玩电脑么?……或者『蚕丝被能够放在太阳下晒么』这样的问题,往往没有绝对的答案,这时候通过情感分析和知识图谱,百度能够告诉用户说有80%的人说可以,20%的人说不可以。您需要自己判断一下。 :)
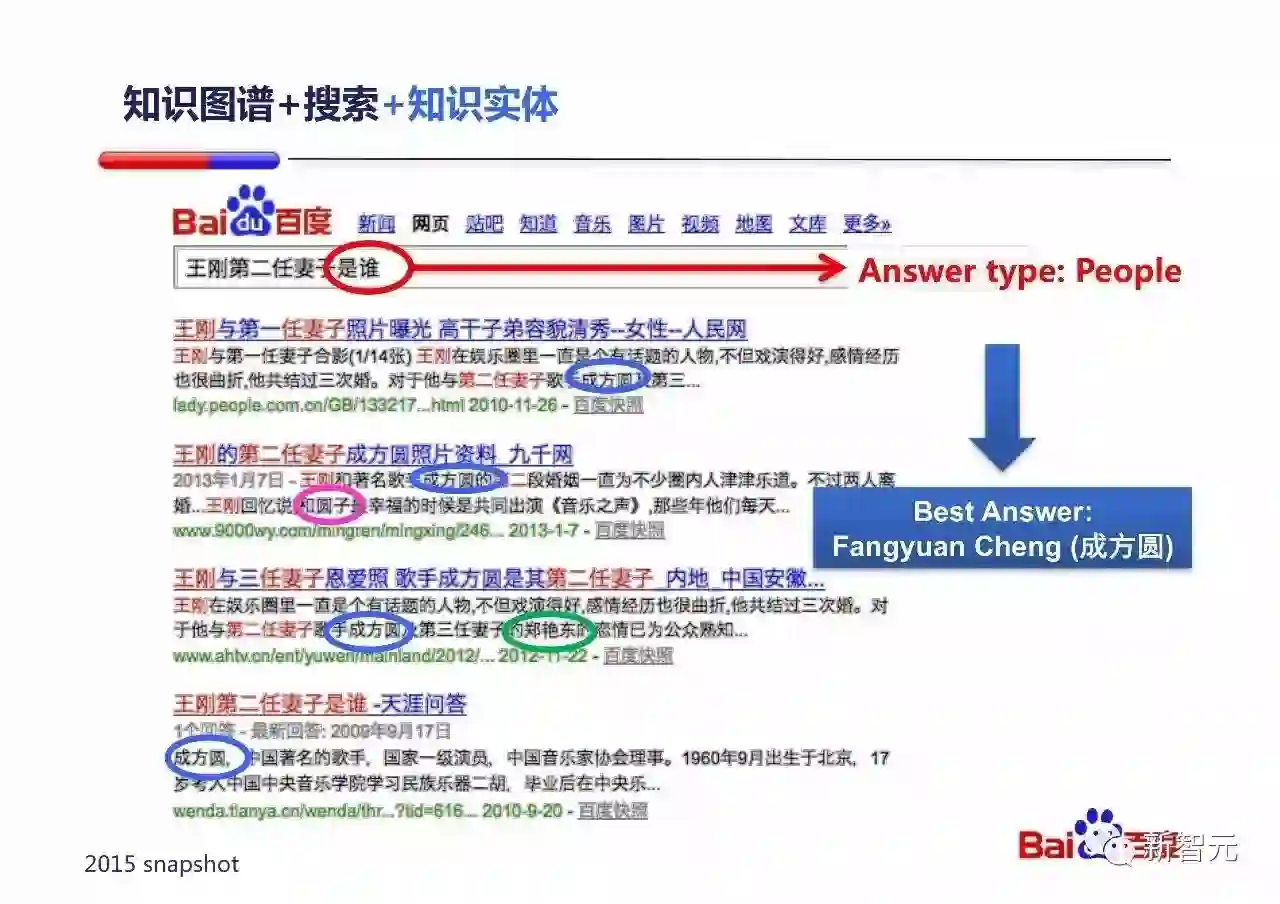
同样,基于实体和搜索结合可以把难度很高的问题难度减低到容易通用的实现。
举个例子:『王刚第二任妻子是谁』这个Query其实对知识图谱理解的要求很高:要理解这个第二,不是年龄第二,不是身高第二,而是结婚时间排序第二。但是一旦结合搜索,知识图谱的理解难度就下降了:
通过Query中的『是谁』,系统可以知道用户想要的答案很可能是一个人。
知识图谱可以标出搜索结果中所有是人的实体。
通过一些排序信号,包括实体出现在所有结果中的比例,我们较容易就能猜出答案很可能是『成方圆』——这是个正确答案。

总结一下第二部分,要给用户更多的直接答案,我们要充分利用知识图谱以及要和网页搜索来结合。(出于保密考虑,所有列出的数据都是百度2015年初的情况。)
AI 赋能的对话式计算机:百度 DuerOS

接下来讨论一下AI赋能的对话式计算机(Conversational Computer),也就是百度现在在做的DuerOS系统。

首先,我们有一个观点:从用户和计算机的交互方式来看,以DuerOS为代表的对话式计算机将会是第三代的操作系统。
第一代操作系统的主要交互方式是鼠标和键盘,代表的操作系统是Windows/Mac。
第二代操作系统的主要交互方式是触摸,代表的操作系统是iOS/Android。
第三代操作系统的主要交互方式是语音对话,代表的操作系统是DuerOS。
这三代操作系统一路走来,他们的交互方式越来越自然,使用门槛越来越低,用户受众越来越多。

在2017年1月的CES上,百度联合小鱼在家发布了第一款搭载DuerOS操作系统的智能家用机器人。

小鱼在家是我们合作的第一个设备,DuerOS还在和非常多的硬件合作伙伴合作,将DuerOS的对话交互的能力嵌入到各个地方。
我们对DuerOS的愿景是这样的:『我们希望DuerOS是无处不在的,我们希望未来DuerOS的标志可以贴在任何地方。无论它贴在哪里,小朋友就知道这个设备可以对话。它贴在桌子上就可以跟桌子对话,它贴在椅子上就可以跟椅子对话。』

延时DuerOS语音对话,多轮交互的能力。

DuerOS的场景如上图所示,它会深入我们生活的场景中(音响、电视、冰箱、手机、家用机器人、车、手表……)并且依托百度整个搜索来给用户提供各种各样的能力。
DuerOS在CES和极客公园上也引起了很大的反响和认可。
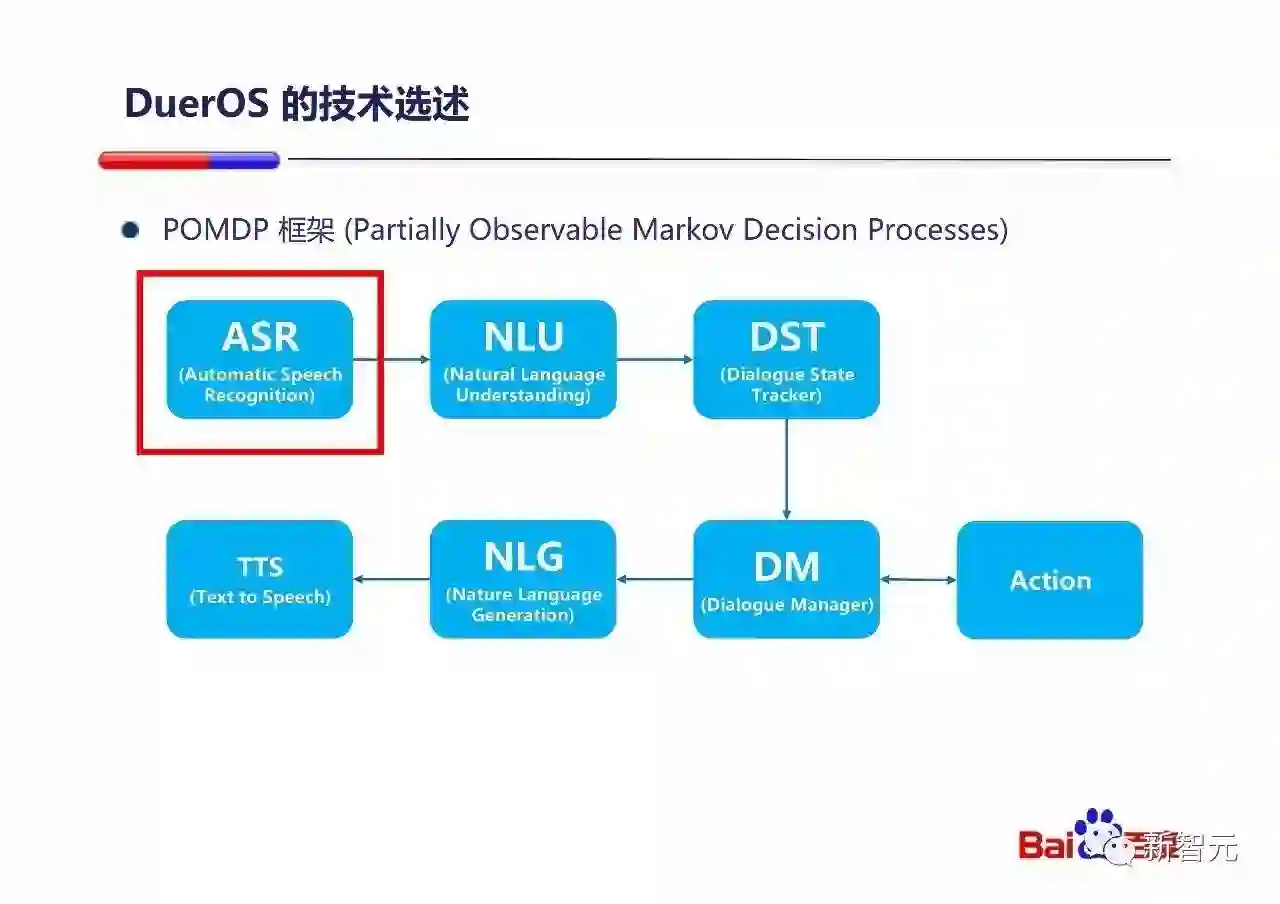
从整个对话系统来说,DuerOS的整体是符合POMDP的框架的。采用POMDP的框架有很大的好处:
整个系统可以整体建模每个环节的出错可能性。
整个系统可以整体建模几轮对话后用户最终给予的反馈。
DuerOS系统正在不断完善过程中,出于保密考虑,没办法分享全部的技术细节,所以只能选择一些小点来和大家粗略分享一下。
首先我们看一下和ASR相关的纠错部分。

普通的语音识别和纠错就不多说了。说一个主动纠正的例子。
用于语音搜索『chen’yu’juan』;百度给出结果是『陈玉娟』,用户纠正『下面是月的雨(育)』,最后一个字还是别错了,但是百度可以给出正确的『陈育娟』的结果。
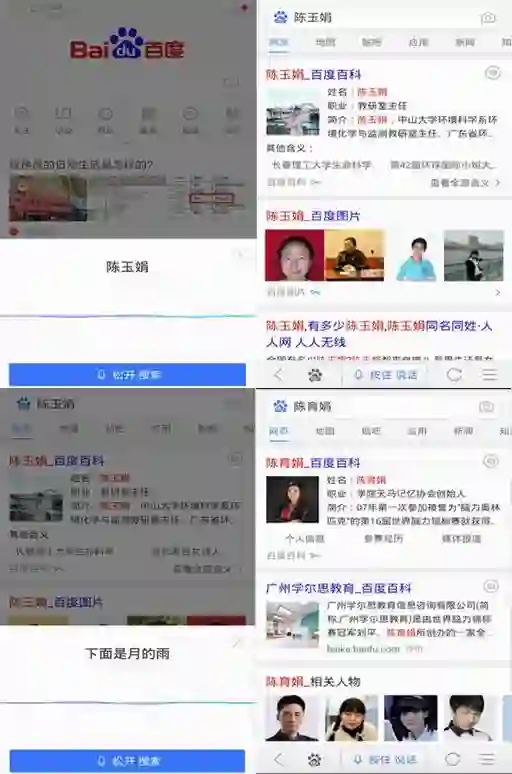
这个例子里面,我们就充分利用了RNN的序列标注能力,来找到语义上可能的替换点,然后通过Skip-gram的检索最终产生正确的替换。
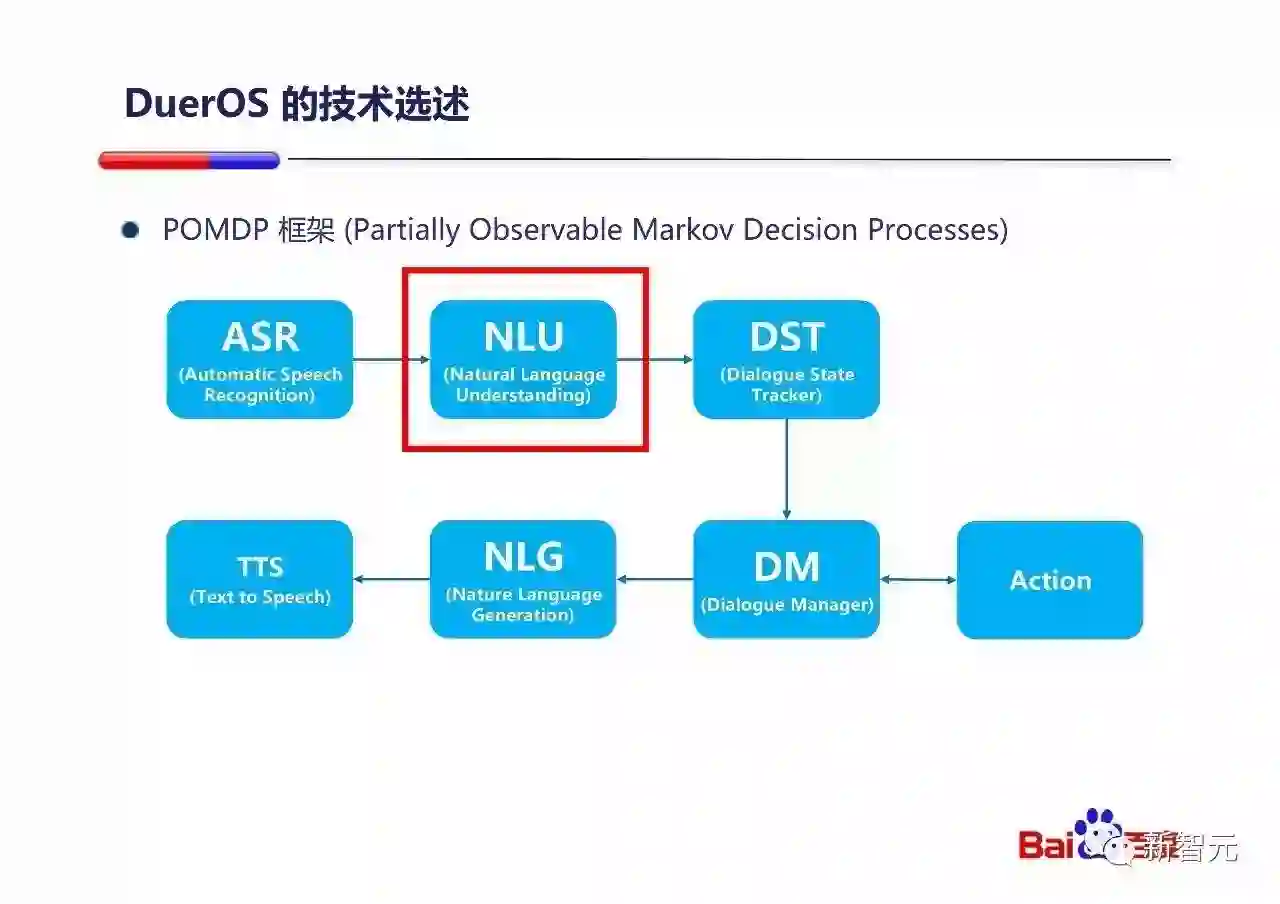
我们接下来看一下自然语言理解(NLU)的部分。自然语言理解中的意图分类(Intent classification)和槽位填写(Slot filling)是其中两个重要的问题。
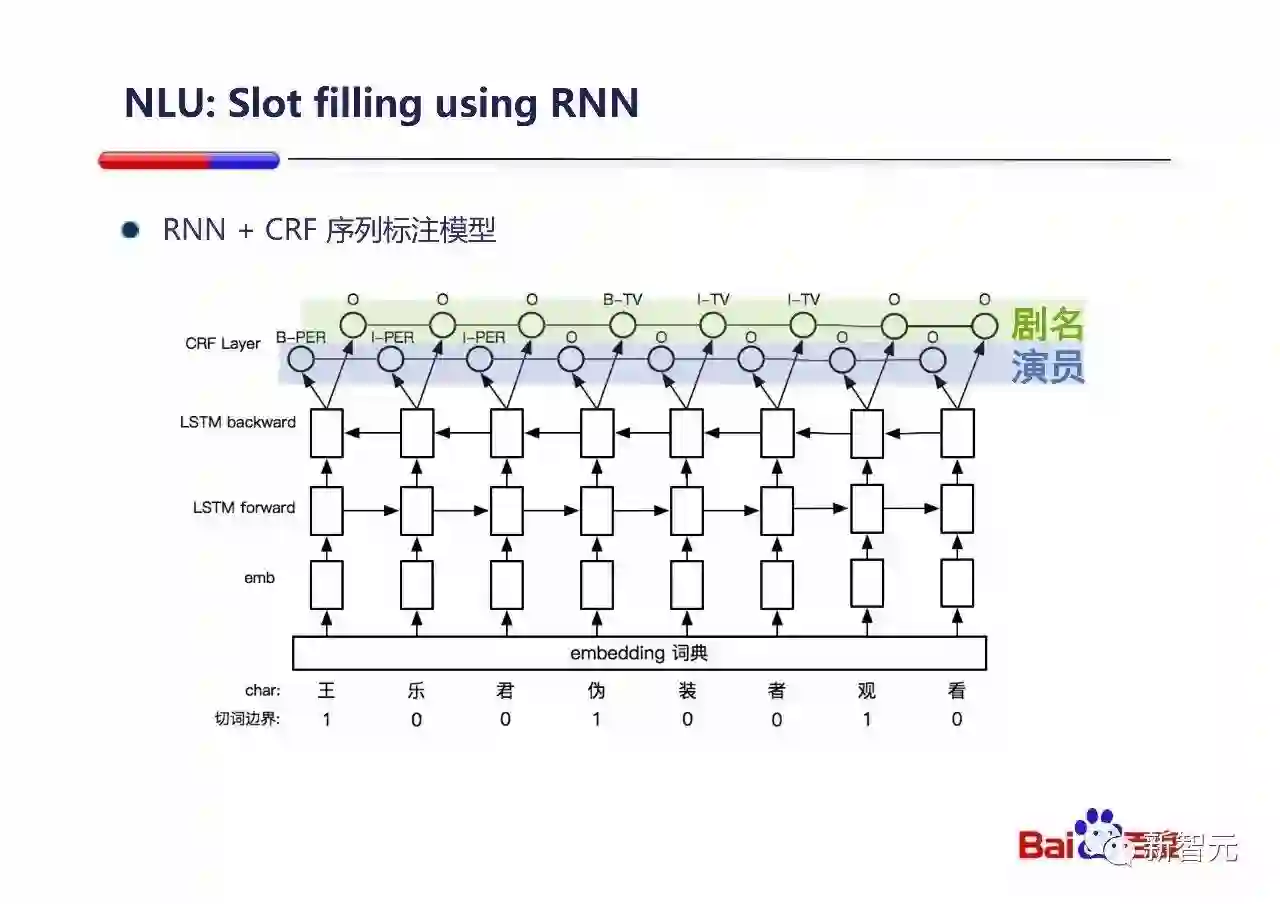
简单讨论下槽位填写的例子,百度采用一个字符级的双向LSTM和CRF层来做槽位填写的标注。如上图,在蓝色的演员这个序列上,『王乐君』就是一个比较可能的候选。『伪装者』就是剧名这个绿色的序列上可能的候选。
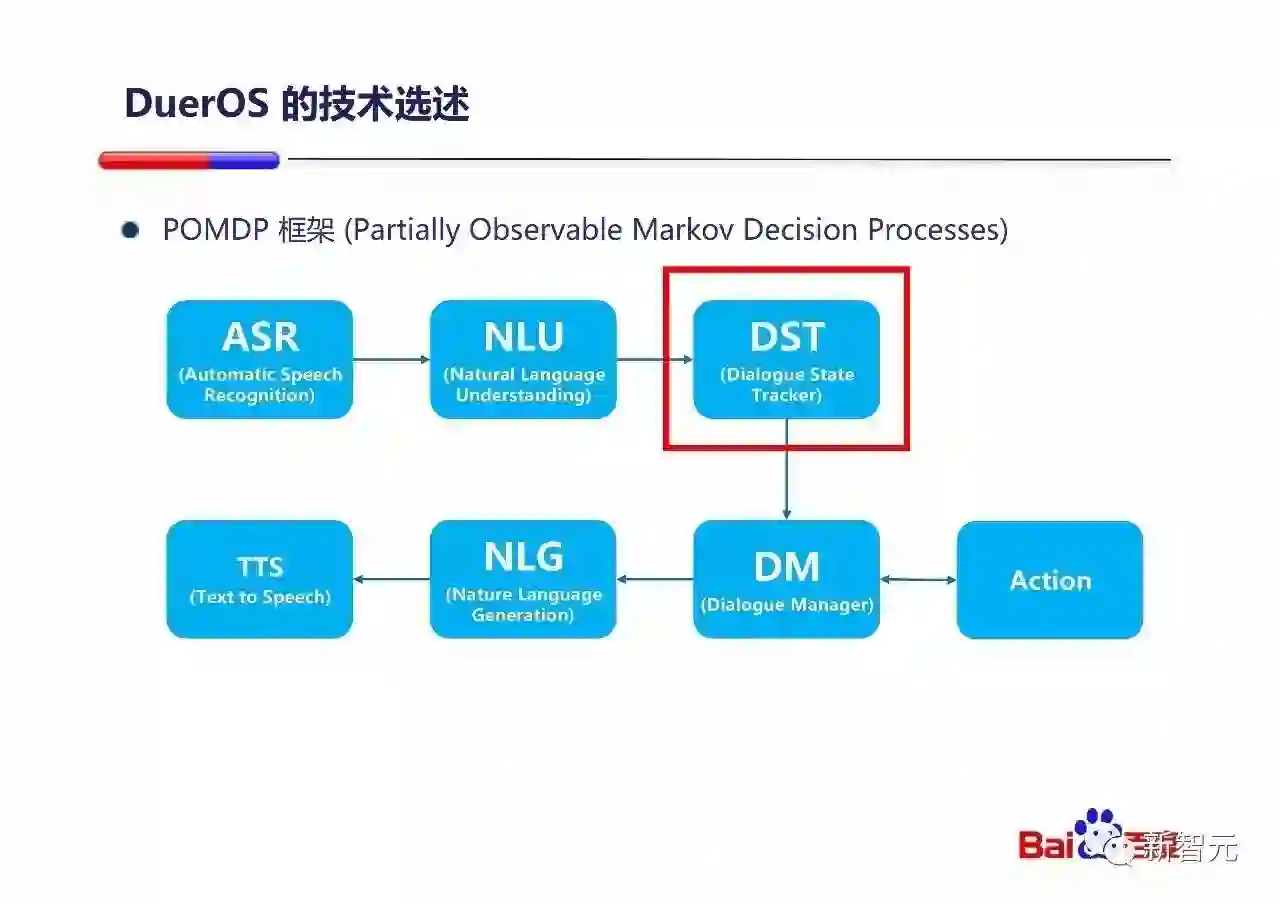
接下来我们讨论下对话状态跟踪。

在封闭领域(买飞机票,问汽车班次等)中的状态跟踪各处有过非常多的讨论,这里就不赘述。我们来看一个在比较开放的领域做状态跟踪并且更新的例子。
在这里,我们主要把Query间的上下文状态更新分为两种:上下文替换和主体补全。
上面两个是在百度系统中的真实Case,通过RNN + CRF来做到的状态更新:用户顺序说Q1,Q2,百度看到Q2会直接更新理解为Q3。
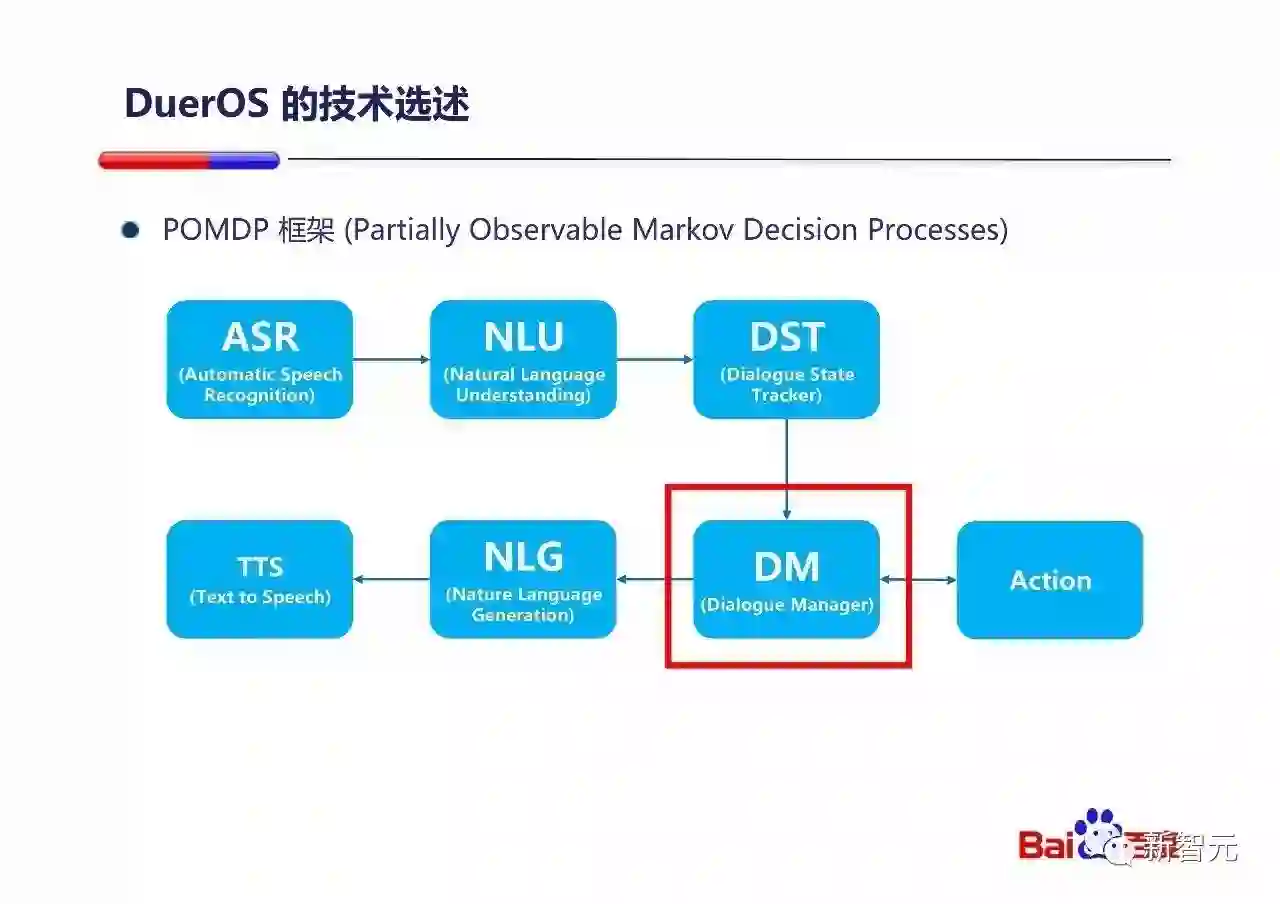
接下来我们讨论下对话状态管理,这个阶段主要是系统要选择合适的Action来动作。
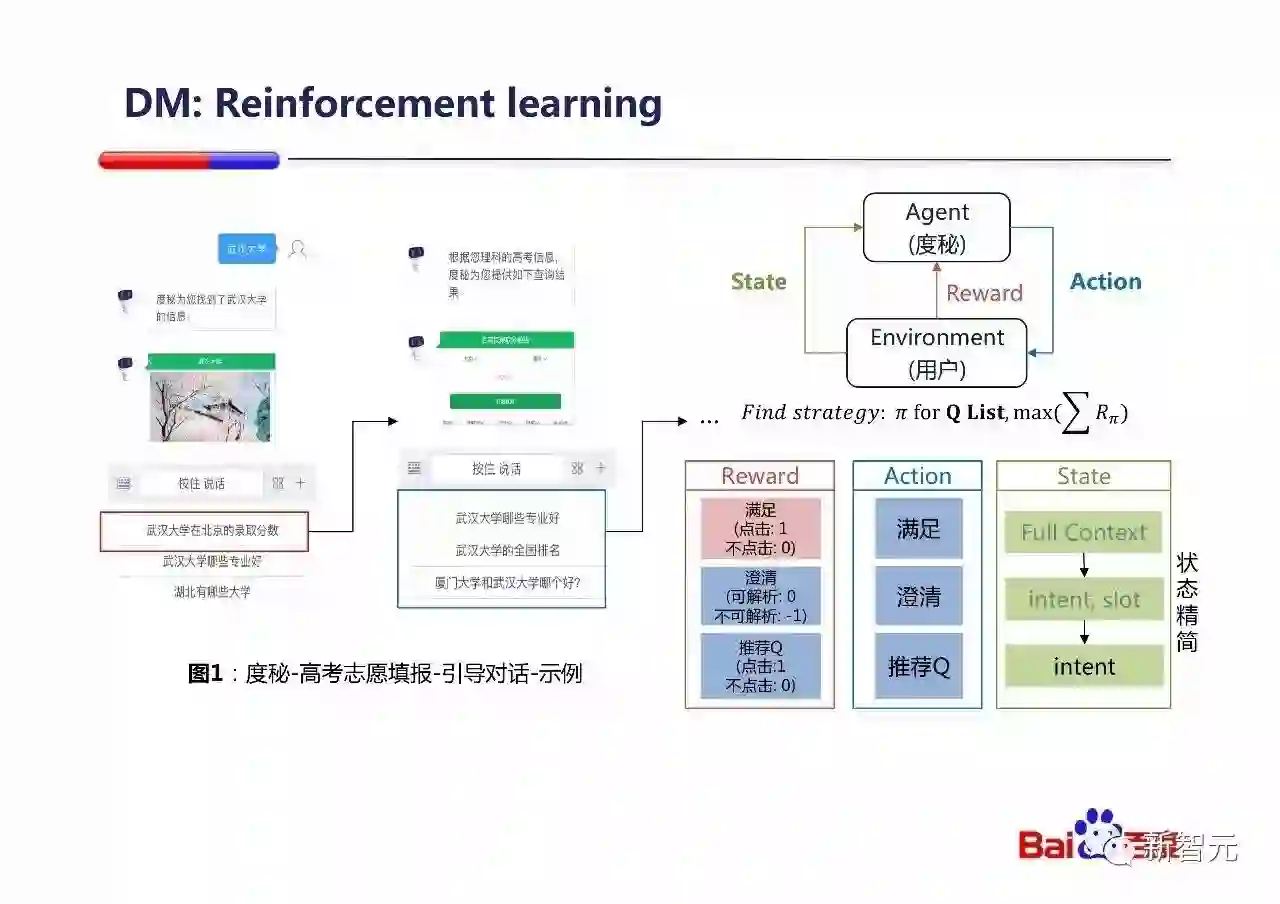
我在这里举一个度秘高考的例子,度秘在高考期间服务了非常多的填报志愿的考生,通过对话回答高考相关的问题,并且引导考生进一步了解他关心的学校的信息,帮助考生结合充分信息,来最终做出人生中这个非常重要的决定。
在这里我们会把这个Dialogue management的问题构建成一个MDP问题(由于在实际产品中,我们并不知道考生最终填报了哪个志愿,所以我们把Reward设计成每次交互都会给出显示的奖惩),放在经典的Reinforcement learning的框架中来求解。上线之后,用户的交互体验大幅提升。

总结一下这一部分,自然的语音交互是未来,未来的DuerOS会是无处不在的。在这样的对话系统中,技术挑战有很多:更好建模上下文,更好的处理异构下游服务……在百度,我们充分利用在深度学习上的积累,相信能够在对话系统中提供让用户感到惊艳的交互体验。

总结一下今天的演讲,AI现在逐步深入人们生活的方方面面,赋能各种产品。我们今天讨论的是AI赋能的现代搜索引擎(百度搜索)和AI赋能的对话式计算机(DuerOS)。
今天讲的所有工作都是归功于整个百度技术团队所有人的努力工作!并且今天讲的所有内容,都是我们上线给亿万用户每天在使用的!

谢谢大家!
最后做个广告:)
我们在百度有非常多的实际有意思的问题,有非常自由的空间来尝试想法,有实际的系统每天被亿万用户使用,我们有非常多的很棒的工程师和研究员。如果你感兴趣,我们提供各种各样的机会,请发信来:duer-recruit@baidu.com。 :)


3月27日,新智元开源·生态AI技术峰会暨新智元2017创业大赛颁奖盛典隆重召开,包括“BAT”在内的中国主流 AI 公司、600多名行业精英齐聚,共同为2017中国人工智能的发展画上了浓墨重彩的一笔。
点击阅读原文,查阅文字版大会实录
访问以下链接,回顾大会盛况:



