12 月 8 日至 12 月 12 日,人工智能顶级会议 NeurIPS2019 在加拿大温哥华召开。据机器之心了解,阿里巴巴共有 11 篇论文被此届大会收录,其中多篇论文展示了阿里在认知智能领域的研究成果,本文对论文《Learning Disentangled Representations for Recommendation》进行了深度解读。
![]()
论文链接:
https://arxiv.org/pdf/1910.14238.pdf
在做人和商品匹配的过程中,相比于黑盒模型,阿里更想关注匹配过程中人的认知因素。人为什么喜欢一件商品,他是对哪些概念动了心,种了草,他是因为什么原因点了击、收了藏、下了单,他当下关注点在哪个认知层面的东西,推荐系统能显式的知道、消化并且准确响应吗?这些所谓的认知因素,并不是商品固有的细粒度的属性、品类,而是一种从人的角度理解商品的可传播可解释的概念。其更像是广告商会选择去打动人心的记忆点。而推荐系统区别于搜索场景的一个点恰好在于是否能主动激发用户潜在的兴趣,帮助用户找到并接受意料之外的商品。因此,如何挖掘潜在的认知概念,并以合理的方式将潜在可接受的认知概念传递给用户可能是未来一段时间推荐系统需要有所突破的事情。
当然,关注这样的认知过程并不是为了端到端的做「下一个商品」的预测或者点击率预估亦或者是评分预估。至少前人在大规模数据的线上经验能表明,产品形态不变的可解释推荐,相比于黑盒模型并不能真正提高最终的点击和转化效果。因此相比于可解释推荐,认知推荐更强调人的因素,其归宿必然是技术驱动产品形态上的创新。而新的产品形态则可以创造新的需求、用户习惯和新的商业场景。
a)商品在人的认知空间中,他们是如何表征的,这样的表征是否具有可解释性,例如是否能找到的对应的某一维就能够代表一个独立的「语义」。这里的语义,其所具有的可解释性其实是本质是一个与认知和传播相关的概念,即是能被人们理解和传播的。类似的,人在这个空间下的表征,是否也具有这样的语义。联系解离化表征(Disentangled Representation Learning)在连续型数据上的发展,我们探索其是否能从离散数据,特别是用户行为数据上学习到类似的结果。
b)基于这样的表征,我们能否提出新型的推荐应用,并至少给出一种原型方案。
![]()
目前来说,其实解离化向量并没有一个标准的定义。如上图所示,假设一副图片的向量表示中,不同的维度含义不同并且这个含义还能被人类所能识别,就称这样的向量是一个解离化的向量表示。例如第一维是方位,第二维是大小,第三位是椅子腿的风格。得到这样的向量有几个好处。1)鲁棒性,可迁移性。2)解释性。3)可控制的生成。前两点其实和因果推断的优势类似,第三点主要是应用方面有较大的潜力。与后文提到的 binding problem 对比,1、2 更像是分解,3 更像是组合。
这其中探索的一个问题就是,根据用户的行为,能否得到一些认知相关的决策因素并以可解离的方式对商品和用户进行表示。
设平台上有 M 个商品,记用户 u 与商品 i 的交互记录为![]() ,
取值为 1 表示用户点击了该商品,取值为 0 表示没有相关记录。那么用户 u 的行为可以记作
,
取值为 1 表示用户点击了该商品,取值为 0 表示没有相关记录。那么用户 u 的行为可以记作![]() 。我们的目标是获得用户 u 的向量化表征
。我们的目标是获得用户 u 的向量化表征![]() ,同时模型也会产出商品的表征
,同时模型也会产出商品的表征![]() ,以供推荐系统根据用户的表征召回一批商品。
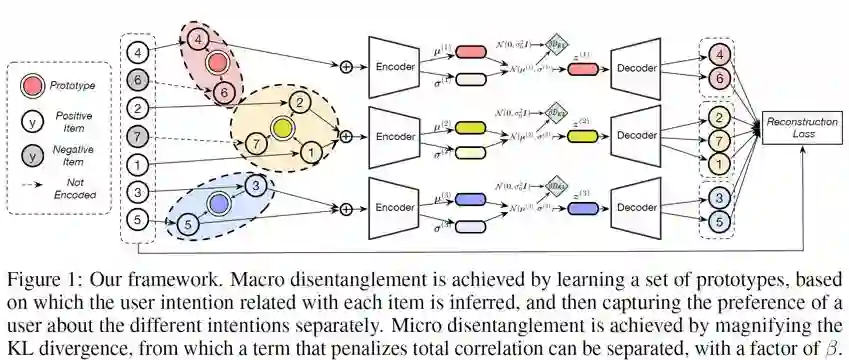
针对电商平台上用户行为的特点,我们的模型采用了层次化的设计:它在推理一个用户的表征时将依次进行宏观解离化(macro disentanglement)和微观解离化(micro disentanglement)。
,以供推荐系统根据用户的表征召回一批商品。
针对电商平台上用户行为的特点,我们的模型采用了层次化的设计:它在推理一个用户的表征时将依次进行宏观解离化(macro disentanglement)和微观解离化(micro disentanglement)。
宏观解离化:
宏观解离化的启发一方面来自于用户在综合类电商场景下的兴趣确实较为分散,另一方面也来自于人类的传统认知难题 Binding Problem。首先,用户兴趣通常是非常广泛的,一个用户的点击记录往往会涉及到多个独立的消费意图(比如点击不同大类下的商品)。而用户在执行不同意图时的偏好往往也是独立,比如喜欢深色的衣服并不意味着用户也喜欢深色的电器。哪怕是价格偏好也常存在不可迁移的情况,比如买高档口红、和买便宜好用的笔记本电脑这两者并不互斥。另外,宏观解离化也是微观解离化的必要前提(见下)。因此,我们的将用户的表征拆分成 K 个 d 维分量![]() ,
用来表示用户执行 K 种不同的意图时的偏好(比如这 K 个分量可以对应 K 个商品大类)。同时,每个商品都有对应的 one-hot 向量
,
用来表示用户执行 K 种不同的意图时的偏好(比如这 K 个分量可以对应 K 个商品大类)。同时,每个商品都有对应的 one-hot 向量![]() ,其中
,其中![]() 表示商品 i 通常与第 k 种宏观的消费意图相关(或属于第 k 个商品大类)。另一方面,给定一个数据整体(一副图像、一组用户行为),binding problem 在讲人是如何将整体分割成部分(图像中不同的物体,行为中不同的兴趣),并且从部分组合出新的数据。这方面的研究本身有难度,也比较有意思。
表示商品 i 通常与第 k 种宏观的消费意图相关(或属于第 k 个商品大类)。另一方面,给定一个数据整体(一副图像、一组用户行为),binding problem 在讲人是如何将整体分割成部分(图像中不同的物体,行为中不同的兴趣),并且从部分组合出新的数据。这方面的研究本身有难度,也比较有意思。
微观解离化:
我们希望能把用户在执行某个意图时的偏好进一步地分解到更细的粒度。比如,设第 k 个意图对应服饰,我们希望用户在这个意图下的偏好向量![]() 的
各个维度能够对应不同的商品属性,比如某一维和颜色相关,另一维和尺寸相关,等等。这里可以看到,宏观解离是微观解离的前提:不同大类的商品属性集合是很不同的,用户表征向量的某一个维度如果已经被用于刻画用户对手机电量的偏好了,那么这一维对服饰等商品就是没有任何意义的——在预测用户是否会点击某个服饰时、在通过用户行为学习某个服饰的表征时,我们都应当忽略这些只和手机相关的维度。
的
各个维度能够对应不同的商品属性,比如某一维和颜色相关,另一维和尺寸相关,等等。这里可以看到,宏观解离是微观解离的前提:不同大类的商品属性集合是很不同的,用户表征向量的某一个维度如果已经被用于刻画用户对手机电量的偏好了,那么这一维对服饰等商品就是没有任何意义的——在预测用户是否会点击某个服饰时、在通过用户行为学习某个服饰的表征时,我们都应当忽略这些只和手机相关的维度。
![]()
这个模型是一个深度生成模型,它假设数据的生成过程是这样的:
![]()
这里的![]() 是
用户 u 的点击历史,
是
用户 u 的点击历史,![]() 是用户 u 的表征,
是用户 u 的表征,![]() 指示了这些商品通常都对应哪些宏观的消费意图。
指示了这些商品通常都对应哪些宏观的消费意图。![]() 是模型的参数,它包括模型涉及到的深度神经网络的参数,也包括了商品的表征
是模型的参数,它包括模型涉及到的深度神经网络的参数,也包括了商品的表征![]() 等等。
等等。![]() 是一个离散概率分布,用于对用户 u 接下来会点击哪个商品进行建模。这里为了实现宏观解离化,在预测用户对商品 i 的态度时,我们限制了商品 i 只能和用户表征 K 个分量的其中一个进行比对(注意:
是一个离散概率分布,用于对用户 u 接下来会点击哪个商品进行建模。这里为了实现宏观解离化,在预测用户对商品 i 的态度时,我们限制了商品 i 只能和用户表征 K 个分量的其中一个进行比对(注意:![]() 是 one-hot 的)。这里的
是 one-hot 的)。这里的![]() 起到归一化的作用,而
起到归一化的作用,而![]() 是一个简单的网络,使用
是一个简单的网络,使用![]() 。计算
。计算![]() 需要枚举全部 M 个商品,非常耗时,我们尝试了各种近似方法(包括 negative sampling、noise contrastive estimation 等),最终最新版采用的是 sampled softmax【4】,因其表现相对比较稳定。
需要枚举全部 M 个商品,非常耗时,我们尝试了各种近似方法(包括 negative sampling、noise contrastive estimation 等),最终最新版采用的是 sampled softmax【4】,因其表现相对比较稳定。
为了优化这个深度概率模型,采纳了 VAE 的框架。为此,引入了一个编码器![]() (
具体实现见伪代码,类似一个 K 通道的单层图卷积神经网络)。整个模型的优化目标是:
(
具体实现见伪代码,类似一个 K 通道的单层图卷积神经网络)。整个模型的优化目标是:
![]()
这里为了实现微观解离化,借鉴了 beta-VAE【1】的方法,对 KL 惩罚项进行了加强(令 beta 远大于 1)。这种做法将迫使表征的各个维度去捕捉比较独立的信息,比如各种各样的不太相关的商品属性(颜色和大小就不太相关)——当然,某些商品属性之间可能存在较强的相关,这就有待未来工作去解决了。
商品对应的宏观意图![]() 若是
已知的,可以直接使用。若是未知的,我们的实现里提供了一种基于原型向量的平摊化推理方法(prototype-based amortized infernece)来估计各个商品对应的宏观意图,并使用了 Gumbel-Softmax【5】技巧来估计离散变量的梯度。值得一提的是,我们的实现里广泛使用了余弦相似度,而不是更常用的点积相似度,这是为了避免发生模态崩塌(mode collapse)(全部原型退化成同一个点,或是全部商品都被分配到同一个原型),详见论文的分析。
若是
已知的,可以直接使用。若是未知的,我们的实现里提供了一种基于原型向量的平摊化推理方法(prototype-based amortized infernece)来估计各个商品对应的宏观意图,并使用了 Gumbel-Softmax【5】技巧来估计离散变量的梯度。值得一提的是,我们的实现里广泛使用了余弦相似度,而不是更常用的点积相似度,这是为了避免发生模态崩塌(mode collapse)(全部原型退化成同一个点,或是全部商品都被分配到同一个原型),详见论文的分析。
以下的伪代码是 Macro-Micro Disentangled VAE 框架的一个参考实现:
![]()
解离化表征在带来一定的可解释性的同时,也带来了一定的可控制性。这种可控制性有望给推荐系统引入一种全新的用户体验。比如说,既然表征的各个维度关联的是不同的商品属性,那么完全可以把用户的表征向量提供给用户,允许用户自行固定绝大部分维度(比如对应的是衣服的风格、价格、尺寸等)、然后单独调整某个维度的取值(比如颜色对应的维度),系统再根据这个反馈调整推荐结果。这将帮助用户更加精准地表达自己想要的、并检索得到自己想要的。
我们从某个商品或用户的表征出发,在固定住其它维度后,逐步地改变表征第 j 维的取值。然后利用论文中提供的一种类似 beam search 的小技巧,检索出了表征第 j 维大不一样、但其它维度都很一致的一批商品。
以下是我们在调控某个维度后检索得到的两批商品,可以看出这个被调控的维度和背包的颜色这一属性比较相关:
![]()
![]()
以下是在另一个维度上检索得到的两批商品,可以看出这个维度和背包的大小这一属性比较相关:
![]()
![]()
当然,并不是所有的维度都有人类可以理解的语义。而且,正如文献【2】所指出的,在无监督的情况下,训练出可解释的模型仍然是需要运气的——在加了 beta-VAE 的约束后,获得可解释模型的概率相比普通 VAE 大大提高,但仍然避免不了「反复训练多个模型,然后挑出最好的模型」这一陷阱。因此,我们和文献【2】一样,建议未来的研究者们多多关注(弱/半)监督方法,引入标签信息。
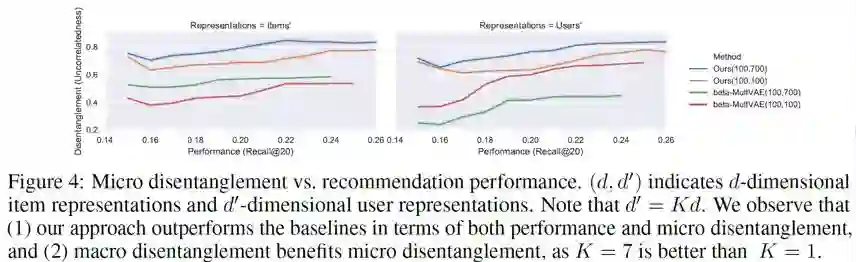
我们在某个小规模数据集上定量测量了解离化程度(及其与推荐性能之间的关系)。初步发现:(1)解离化程度较高与推荐性能好这两者之间有较强的相关性;(2)引入宏观解离化后,确实大大改善了微观解离化;(3)我们的方法无论是解离化程度还是推荐性能,都优于基线方法。
![]()
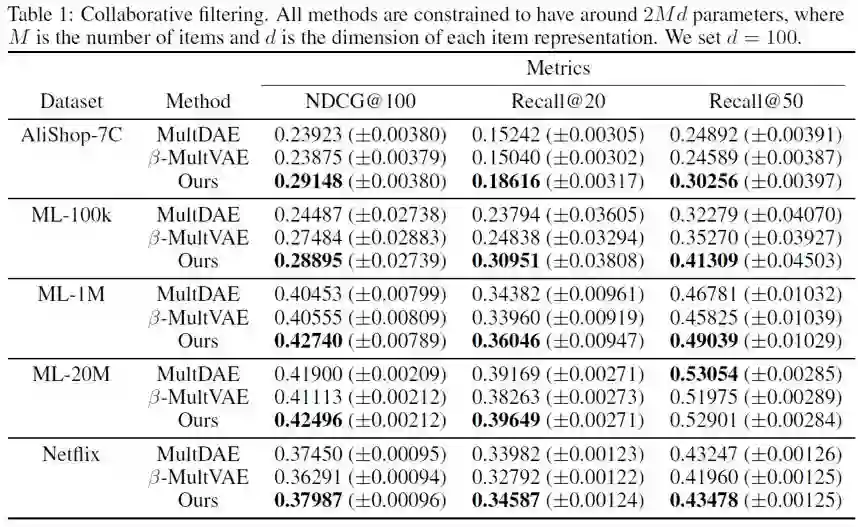
我们接着测量了我们的方法在几个离线数据集(包括一个淘宝的数据集 AliShop-7C)上的 Top-N 推荐表现。可以看出这个方法优于基线方法,尤其是在小规模或稀疏的数据集上。因为 top-n 推荐不是阿里做这个问题的初衷,所以能做出这样的效果我们认为已经是令人满意的了。
![]()
随着现代电商推荐系统的技术发展,学术界和工业界在预估点击率,预测下一个点击商品这些单任务上的提高越发困难,而这样的提高所带来的增量效益也难以很好的估计。更多用户体验方面的问题被摆在了决策者的眼前,比如为什么买了又推,为什么都是点过的商品,如何创造真正增量的价值。我们目前选择围绕人的认知行为和过程,来探索新的推荐形态的可能性。本文的工作仍然有很多需要进一步探索和需要优化的地方。
【1】Beta-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. Higgins et al., ICLR 2017.
【2】Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations. Locatello et al., ICML 2019.
【3】 Disentangled Graph Convolutional Networks. Ma et al., ICML 2019.
【4】 On using Very Large Target Vocabulary for Neural Machine Translation. Jean et al.., ACL 2015.
【5】 Categorical Reparameterization with Gumbel-Softmax. Jang et al., ICLR 2017.
【6】 The Binding Problem. https://en.wikipedia.org/wiki/Binding_problem
【本文】Learning Disentangled Representations for Recommendation. Ma & Zhou et al., NeurIPS 2019.
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content
@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


 ,
取值为 1 表示用户点击了该商品,取值为 0 表示没有相关记录。那么用户 u 的行为可以记作
,
取值为 1 表示用户点击了该商品,取值为 0 表示没有相关记录。那么用户 u 的行为可以记作 。我们的目标是获得用户 u 的向量化表征
。我们的目标是获得用户 u 的向量化表征 ,同时模型也会产出商品的表征
,同时模型也会产出商品的表征 ,以供推荐系统根据用户的表征召回一批商品。
,以供推荐系统根据用户的表征召回一批商品。
 ,
用来表示用户执行 K 种不同的意图时的偏好(比如这 K 个分量可以对应 K 个商品大类)。同时,每个商品都有对应的 one-hot 向量
,
用来表示用户执行 K 种不同的意图时的偏好(比如这 K 个分量可以对应 K 个商品大类)。同时,每个商品都有对应的 one-hot 向量 ,其中
,其中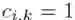 表示商品 i 通常与第 k 种宏观的消费意图相关(或属于第 k 个商品大类)。另一方面,给定一个数据整体(一副图像、一组用户行为),binding problem 在讲人是如何将整体分割成部分(图像中不同的物体,行为中不同的兴趣),并且从部分组合出新的数据。这方面的研究本身有难度,也比较有意思。
表示商品 i 通常与第 k 种宏观的消费意图相关(或属于第 k 个商品大类)。另一方面,给定一个数据整体(一副图像、一组用户行为),binding problem 在讲人是如何将整体分割成部分(图像中不同的物体,行为中不同的兴趣),并且从部分组合出新的数据。这方面的研究本身有难度,也比较有意思。
 的
各个维度能够对应不同的商品属性,比如某一维和颜色相关,另一维和尺寸相关,等等。这里可以看到,宏观解离是微观解离的前提:不同大类的商品属性集合是很不同的,用户表征向量的某一个维度如果已经被用于刻画用户对手机电量的偏好了,那么这一维对服饰等商品就是没有任何意义的——在预测用户是否会点击某个服饰时、在通过用户行为学习某个服饰的表征时,我们都应当忽略这些只和手机相关的维度。
的
各个维度能够对应不同的商品属性,比如某一维和颜色相关,另一维和尺寸相关,等等。这里可以看到,宏观解离是微观解离的前提:不同大类的商品属性集合是很不同的,用户表征向量的某一个维度如果已经被用于刻画用户对手机电量的偏好了,那么这一维对服饰等商品就是没有任何意义的——在预测用户是否会点击某个服饰时、在通过用户行为学习某个服饰的表征时,我们都应当忽略这些只和手机相关的维度。

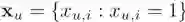 是
用户 u 的点击历史,
是
用户 u 的点击历史, 是用户 u 的表征,
是用户 u 的表征,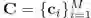 指示了这些商品通常都对应哪些宏观的消费意图。
指示了这些商品通常都对应哪些宏观的消费意图。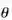 是模型的参数,它包括模型涉及到的深度神经网络的参数,也包括了商品的表征
是模型的参数,它包括模型涉及到的深度神经网络的参数,也包括了商品的表征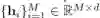 等等。
等等。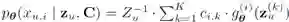 是一个离散概率分布,用于对用户 u 接下来会点击哪个商品进行建模。这里为了实现宏观解离化,在预测用户对商品 i 的态度时,我们限制了商品 i 只能和用户表征 K 个分量的其中一个进行比对(注意:
是一个离散概率分布,用于对用户 u 接下来会点击哪个商品进行建模。这里为了实现宏观解离化,在预测用户对商品 i 的态度时,我们限制了商品 i 只能和用户表征 K 个分量的其中一个进行比对(注意: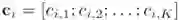 是 one-hot 的)。这里的
是 one-hot 的)。这里的 起到归一化的作用,而
起到归一化的作用,而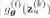 是一个简单的网络,使用
是一个简单的网络,使用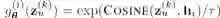 。计算
。计算 需要枚举全部 M 个商品,非常耗时,我们尝试了各种近似方法(包括 negative sampling、noise contrastive estimation 等),最终最新版采用的是 sampled softmax【4】,因其表现相对比较稳定。
需要枚举全部 M 个商品,非常耗时,我们尝试了各种近似方法(包括 negative sampling、noise contrastive estimation 等),最终最新版采用的是 sampled softmax【4】,因其表现相对比较稳定。
 (
具体实现见伪代码,类似一个 K 通道的单层图卷积神经网络)。整个模型的优化目标是:
(
具体实现见伪代码,类似一个 K 通道的单层图卷积神经网络)。整个模型的优化目标是:
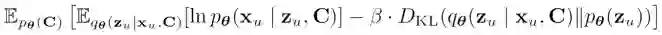
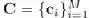 若是
已知的,可以直接使用。若是未知的,我们的实现里提供了一种基于原型向量的平摊化推理方法(prototype-based amortized infernece)来估计各个商品对应的宏观意图,并使用了 Gumbel-Softmax【5】技巧来估计离散变量的梯度。值得一提的是,我们的实现里广泛使用了余弦相似度,而不是更常用的点积相似度,这是为了避免发生模态崩塌(mode collapse)(全部原型退化成同一个点,或是全部商品都被分配到同一个原型),详见论文的分析。
若是
已知的,可以直接使用。若是未知的,我们的实现里提供了一种基于原型向量的平摊化推理方法(prototype-based amortized infernece)来估计各个商品对应的宏观意图,并使用了 Gumbel-Softmax【5】技巧来估计离散变量的梯度。值得一提的是,我们的实现里广泛使用了余弦相似度,而不是更常用的点积相似度,这是为了避免发生模态崩塌(mode collapse)(全部原型退化成同一个点,或是全部商品都被分配到同一个原型),详见论文的分析。