ICLR-17最佳论文作者Nicolas Papernot现场演讲:如何用PATE框架有效保护隐私训练数据?(附视频)
AI科技评论按:ICLR 2017 总共有三篇最佳论文,其中有一篇是关于如何有效保护机器学习训练中的隐私数据,名为「用半监督知识迁移解决深度学习中训练数据隐私问题」(Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data)。论文给出了一种通用性的解决方法,名为「教师模型全体的隐私聚合」(Private Aggregation of Teacher Ensembles/PATE)。该论文第一作者是 Nicolas Papernot。在近日举办的 ICLR 2017 大会上,Papernot 对论文和研究方法进行了口头演讲。
以下是 Papernot 现场演讲视频。下文为中文文字版, AI 科技评论听译。
我主要讲一讲,如何在机器学习当中保护数据的隐私性。这篇论文的贡献者还有:Martín Abadi、Úlfar Erlingsson、Kunal Talwar 和 Ian Goodfellow。
为了解决这个问题,我们展示了一种能为训练数据提供强健隐私保障的通用性方法:「教师模型全体的隐私聚合」(Private Aggregation of Teacher Ensembles/PATE)。
一些机器学习应用的训练涉及到敏感数据。这里是一个训练一般人脸识别模型的例子,2015 年一群研究员发现,通过机器学习模型的预测结果,可以反过来重建模型训练时使用的人脸数据。2016 年,另一拨研究人员发现,同样可以根据模型的预测结果,来推理出模型训练数据中是否包含了某个具体的训练点(training point),他们将这种攻击称之为「会员推理攻击」(membership inference attacks)。
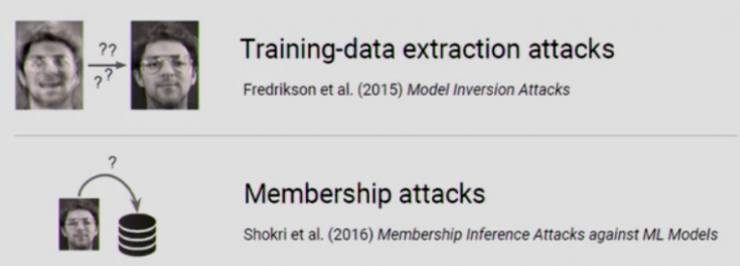
几种攻击类型和我们的威胁模型
以下有两种攻击类型。
模型查询(model querying)
攻击者通过查询来观察模型。对于攻击者来说,模型是一个黑盒,攻击者可以挑选输入值,来观察模型的预测结果。
模型检验(model inspection)
当我们进行防守设计的时候,我们会针对最强的攻击手法。有很多证据表明,机器学习模型能够记住一些训练数据,其中一个证据就是来自这篇论文:《理解深度学习,需要重新思考泛化问题》(Understanding Deep Learning Requires Rethinking Generalization)。所以我们也想防范白盒攻击者(white-box adversary)通过模型检验进行的攻击。

在我们的工作中,威胁模型有以下几个假定:
攻击者可以进行潜在的无限多的查询
攻击者能够进入模型内部组件

在以上假定下,我们设计保护数据隐私的通用性方法。「通用性」的意思是指「独立于学习算法或学习架构」,这是与此前该领域工作最大的一个不同点。我们不仅提供正式的差分隐私保障,也提供一定的直观隐私(intuitive privacy)保障,关于这一点,我后续会给出更多的解释。

我们的方法:PATE
我们给出的解决方法是「教师模型全体的隐私聚合」(Private Aggregation of Teacher Ensembles/PATE),PATE 的发音类似「法国肉酱」这种食物。

教师模型(Teacher Model)
起初,我们将敏感数据分割为 N 个互斥的不同数据集,然后由这些数据集分别独立训练不同的模型,得到 N 个「教师模型」。当我们部署训练好的「教师模型」时,我们记录每一个「教师模型」的预测结果,选取票数最高的那个,将预测结果聚合起来。
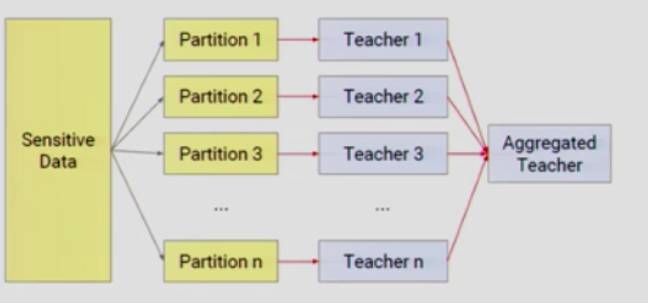
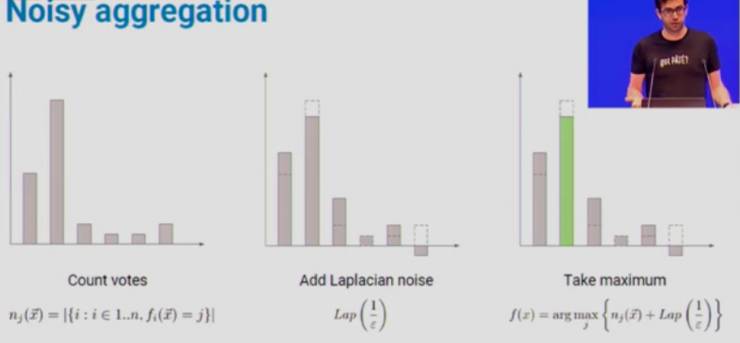
如果大部分「教师模型」都同意某一个预测结果,那么就意味着它不依赖于具体的分散数据集,所以隐私成本很小。但是,如果有两类预测结果有相近的票数,那么这种不一致,或许会泄露隐私信息。
因此,我们在中间「统计票数」和「取最大值」之间,添加了额外的一个步骤:引入拉普拉斯噪声,把票数的统计情况打乱,从而保护隐私。
学生模型(Student Model)
你可以把「聚合教师模型」(Aggregated Teacher)看做是一个差分隐私 API,你提交输入值,它会给你保护隐私的标签。但是,如果我们能训练一个机器学习模型,部署到用户设备上直接运行模型得出预测结果,这样会更好。所以,我们又训练了一个额外模型:「学生模型」。「学生模型」可以获得未标记的公共数据池。为了训练「学生模型」,我们需要「聚合教师模型」以隐私保护的方式,来给公共数据进行标注,传递知识。我们用于部署在设备上的,就是训练好的「学生模型」。
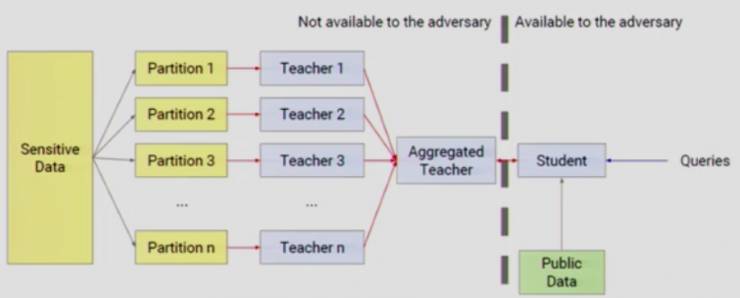
为什么要训练一个额外的「学生模型」?
如果你仔细看一下,就会发现「聚合教师模型」实际上破坏了我们的威胁模型。每次你在查询「聚合教师模型」时,都会增加隐私成本,因它每次给出的输出结果都会或多或少透露一些隐私信息。然而,当「学生模型」训练好之后,只能对「聚合教师模型」进行固定数量的查询,那么隐私成本就会被固定下来了。
另外,我们要防范攻击者探取模型底层函数库。「教师模型」是由隐私数据训练的,「学生模型」是由公共数据训练的,带有隐私保护的标注。所以最坏的情况是,攻击者通过查验「学生模型」的底层函数库而获得其训练数据,也只能得到带有隐私保护的标注信息,除此以外攻击者得不到再多的隐私信息了。

差分隐私分析
对于相近的数据集(d,d'),随机的算法 M 满足(ε,δ)差分隐私,那么两个查询数据库(d,d')的查询结果在概率上接近。写成公式就是:

也就是说,对于任意的查询结果集合 S,参数ε接近 0 时,隐私程度高。所以,ε值决定了噪声的干扰程度,也决定了隐私程度。另外,我们还有一个参数δ,代表失败率(failure rate),简化了差分隐私分析。
我们应用了 Moments Accountant 技巧,来自去年的一篇论文(Abadi et al,2016),可以对「教师模型」设置一个强固定数(strong quorum),从而带来小隐私成本。另外,差分隐私范围(bound)是依赖于数据的。

生成式变种:PATE-G
在展示实验结果之前,我想展示一下 PATE 的一种生成式变种:PATE-G,你可以把它当做是更华丽的一种 PATE 版本。PATE-G 的设计初衷很简单:我们希望产生「学生模型」训练时需要用的标签数目,数目越小,则隐私成本越小。
生成对抗网络(GANs)的一般架构是分为生成器和判别器。我们将原本二元分类的判别器(只判别数据是真实的 or 生成的)扩展至一个多类别的分类器,用来区分:已标注的真实样本,未标注真实样本,以及生成样本。

实验结果
实验设置
我们使用了四个数据库:MNIST、SVHN、UCI Adult 和 UCI Diabetes。在训练「教师模型」时,对于 MNIST 和 SVHN 两个图像数据库,我们使用了卷积架构;对于两个 UCI 数据库,我们使用了随机森林。在训练「学生模型」时,对于 MNIST 和 SVHN,我们使用了 PATE-G;对于两个 UCI 数据库,我们使用的是普通的 PATE 架构。顺便说一句,我们所有的实验设置都已经在 TensorFlow 模块上。
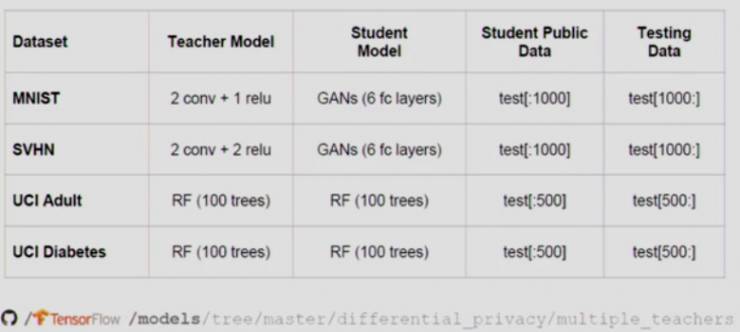
「聚合教师模型」的准确率
这幅图描绘了「聚合教师模型」的准确率。所以,在训练「学生模型」之前,我们考虑了每一个标签的隐私。横轴是每一个标签查询的ε值,纵轴是预测结果的平均准确率。
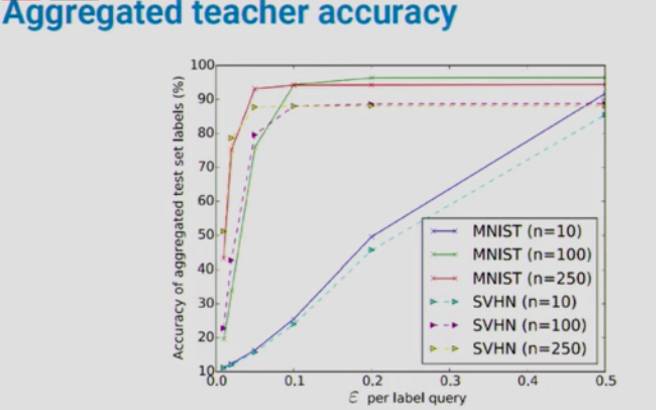
紫色这条线代表了一个包含 10 个「教师模型」的「聚合教师模型」(n=10)。当我们逐渐降低ε的值,意味着我们引入更多的随机噪声,加强隐私保障,那么这个「聚合教师模型」的准确率也很快下降。但是,图中绿线和红线的部分,分别是包含 100 个和 250 个「教师模型」的「聚合教师模型」(n=100,n=250),那么在较低ε值时,我们仍然可以保持较高的准确率。
「学生模型」准确率和隐私之间平衡
横轴是「学生模型」的ε值,代表我们方法的所有隐私成本(overall cost)。纵轴是进行了隐私保护的「学生模型」的错误率。
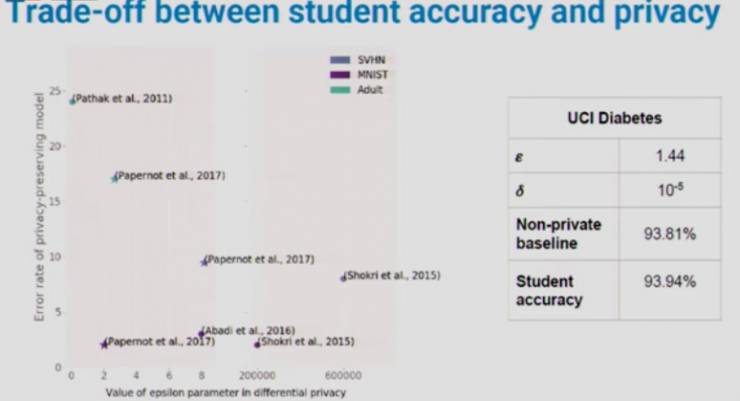
在紫色(MNIST)和蓝色(SVHN)部分,我们大幅度降低了ε值(60 万到 20 万以下),意味着大幅加强隐私保障,由此保持甚至提高了准确率,因为错误率都保持在较低水平。对于绿色(Adult)部分,我们把错误率降低到了最先进的水平,同时付出了适量的隐私成本。
最后,对于 UCI Diabetes 数据库,我们发现了一些非常有趣的东西。隐私保护模型(student accuracy)比未加隐私保护的模型(non-private baseline)的准确率还要高。
总结
最后,我想强调三点。第一点,就是这个方法是具有通用性的,这意味着你可以将它应用于各种分类器中(包括神经网络);另外,就算你不太懂隐私保护的知识,你可以通过 PATE 框架来保护机器学习里的训练数据。第二点,差分隐私范围(bound)不是给定的,对于达到准确度与隐私之间的良好的平衡,具有重要意义。第三点,我们观察到,隐私和通用性并不一定是互相矛盾的。
以上就是我的报告,谢谢大家。
报名 |【2017 AI 最佳雇主】榜单

在人工智能爆发初期的时代背景下,雷锋网联合旗下人工智能频道AI科技评论,携手《环球科学》和 BOSS 直聘,重磅推出【2017 AI 最佳雇主】榜单。
从“公司概况”、“创新能力”、“员工福利”三个维度切入,依据 20 多项评分标准,做到公平、公正、公开,全面评估和推动中国人工智能企业发展。
本次【2017 AI 最佳雇主】榜单活动主要经历三个重要时段:
2017.4.11-6.1 报名阶段
2017.6.1-7.1 评选阶段
2017.7.7 颁奖晚宴
最终榜单名单由雷锋网、AI科技评论、《环球科学》、BOSS 直聘以及 AI 学术大咖组成的评审团共同选出,并于7月份举行的 CCF-GAIR 2017大会期间公布。报名期间欢迎大家踊跃自荐或推荐心目中的最佳 AI 企业公司。
报名方式
如果您有意参加我们的评选活动,可以点击【阅读原文】,进入企业报名通道。提交相关审核材料之后,我们的工作人员会第一时间与您取得联系。
【2017 AI 最佳雇主】榜单与您一起,领跑人工智能时代。



