【工大SCIR】AAAI20 基于反向翻译和元学习的低资源神经语义解析
论文名称:Neural Semantic Parsing in Low-Resource Settings with Back-Translation and Meta-Learning
论文作者:孙一博,唐都钰,段楠,宫叶云,冯骁骋,秦兵,Daxin Jiang
原创作者:孙一博
论文链接:https://arxiv.org/abs/1909.05438
转载须标注出处:哈工大SCIR
1. 引言
本文研究的是在低资源环境下的神经语义解析,在本章的设置中,只知道有限数量的简单映射规则可用,包括少量与领域无关的词汇级匹配表(如果需要的话),但不能访问问题对应的标注好的逻辑表达式或其执行结果。这个工作的关键思想在于用上述规则为出发点收集适度的<问题,逻辑表达式>对,然后利用自动生成的数据来提高模型的准确性和通用性。这种方式带来了三个挑战,包括如何以有效的方式生成数据,如何度量生成数据的质量(自动生成的数据可能包含错误和噪声),以及如何训练一个可以对规则覆盖的示例进行稳健地预测并很好地推广到未覆盖的示例的神经语义解析器。
本文提出了一个由三个关键部分组成的框架来应对上述挑战。第一个组件是一个数据生成器。它包括一个神经语义解析模型,用于将自然语言问题映射到逻辑表达式,和一个神经问题生成模型,用于将逻辑表达式映射到自然语言问题。本文使用伪并行示例在反向翻译范式中学习这两个模型,其灵感来自于在无监督神经机器翻译方面的巨大成功。第二个组件是一个质量控制器,用于过滤生成的伪训练数据中包含的噪声和错误。本文构造了一个具有频繁映射模式的短语表,这个短语表可以后续被用来滤除低频噪声数据和错误数据。类似的想法也被应用于神经机器翻译中的后验正则相关的方法之中。第三个组件是元学习训练器。为了确保模型在保留人工先验知识的情况下增强对位置领域数据的泛化性,本文没有将用规则涵盖的数据预先训练好的模型在后续新生成的数据上进行微调,而是利用模型不可知元学习(MAML)方法来训练模型。模型不可知元学习是一种优雅的元学习算法,它已经被成功应用于包括小样本学习(few-shot learning)和自适应控制在内的广泛任务之中。在使用模型不可知元学习时,本文将不同的数据源视为不同的任务,并且将不同数据源使用质量控制器进行过滤后再交送模型进行元学习的训练过程,已达到稳定模型训练的目的。
本文在面向表格数据的单轮问答任务和面向表格数据的多轮问答任务上对本文提出的方法进行了测试。此外,为了验证本文提出的方法的泛化性,本文也在大规模知识图谱问答的任务上测试了本文提出的的方法。其中面向表格数据的单轮和多轮问答任务中的目标逻辑形式是类SQL数据库查询语言,知识图谱问答任务中的逻辑形式是简单的<主语,谓语>对。在这些目标逻辑形式中,用于面向表格数据的单轮问答任务和知识图谱问答任务的目标逻辑形式比较简单,而针对多面向表格数据的多轮问答任务中的类SQL查询语言则有相当程度的复杂性。实验结果表明,与基于规则的系统相比,本文提出的模型有了很大的改进,采用不同的策略后,本文提出的模型的整体性能逐步得到了提高。在WikiSQL数据集上,本文提出的性能最好的系统达到了72.7%的执行准确率,这个结果可以与使用问题答案作为监督信号的而训练的最好系统(此系统的执行准确率达到了74.8%)相媲美。
2. 算法

图1 学习算法
本文提出利用反向翻译和元学习来训练神经语义解析器。学习过程的具体算法在算法上图中展现。
下面将依次描述算法中的三个重要组成部分,即反向翻译、质量控制和元学习。
2.1 反向翻译
在使用反向翻译的过程中,本文构建了一个语义解析器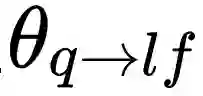
2.2 质量控制
直接使用生成的数据作为监督模型的训练数据是不可取的,因为生成的数据中包含噪声或误差。为了解决这个问题,本文借鉴了后验正则化方法在神经机器翻译任务中的应用,并实现了一个基于字典的判别器,用于衡量伪数据的质量。其基本思想是,虽然这些生成的数据并不完美,但是自然语言查询 q 中的短语与逻辑表达式 lf 中的符号之间的频繁映射模式有助于过滤生成的数据中的低频率噪声。有多种方法可以收集短语表信息,例如使用Giza++之类的基于统计的短语级对齐算法,或者用启发式的方法直接统计任何出现在自然语言查询中的单词和逻辑表达式中的符号的共现次数。基于简单高效的考虑,本文在这项工作中使用后者。本文构造了一个具有频繁映射模式的短语表,因此可以滤除低频噪声和错误。
2.3 元学习
元学习包括两个优化目标:学习模型对新任务进行更好地学习,以及元学习模型对学习模型有着更好地训练。在这项工作中,元学习模型是通过找到一个良好的高度适应性的的初始化而被进行优化的。具体来说,本文使用了模型不可知元学习(MAML)算法。这是一种功能强大的元学习算法,它具有适合本文所涉及的任务的非常理想的特性,包括不引入额外的参数,也不假设模型的结构等。在模型不可知元学习中,任务特定的参数![]() 由
由![]() 初始化,并基于任务
初始化,并基于任务![]() 的损失函数
的损失函数![]() 使用梯度下降进行更新。在这项工作中,两个任务的损失函数是相同的。更新后的参数
使用梯度下降进行更新。在这项工作中,两个任务的损失函数是相同的。更新后的参数![]() 用于计算模型在任务间的性能,以更新参数
用于计算模型在任务间的性能,以更新参数![]() 。
。
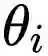 由
由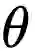 初始化,并基于任务
初始化,并基于任务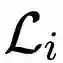 的损失函数
的损失函数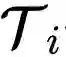 使用梯度下降进行更新。在这项工作中,两个任务的损失函数是相同的。更新后的参数
使用梯度下降进行更新。在这项工作中,两个任务的损失函数是相同的。更新后的参数如果只有规则所涵盖的样例,例如在初始化阶段使用的样例,元学习将学习一个良好的初始参数,该参数通过对来自同一分布的样例的有用性进行评估。在训练阶段,本文的语义解析器可以生成两个任务的所需的训练数据,元学习模型学习到如何学习一个初始化参数的能力,该参数可以快速有效地适应两个任务中样例的需求。在测试阶段,可以使用规则来检测输入样例是否被其覆盖,以决定输入样例所属于哪个任务,并使用相应的针对于特定任务的模型来对输入样例进行预测。在处理规则覆盖的示例时,可以直接使用规则进行预测,也可以使用通过元学习训练得到的模型,这取决于所学习的模型对开发集规则覆盖的样例的准确性。
3. 实验
本文在三个不同面向不同领域的目标逻辑形式的基准数据集上进行了充分的实验。这些任务包括了为单轮和多轮的面向表格数据自动问答任务生成SQL或者类SQL数据库查询语言,和为知识库问答任务生成主语-谓语实体对。在这篇文章中我们只介绍面向表格数据的单轮自动问答任务,剩余的实验结果可以移步论文进行查看。
3.1 任务和数据集
给出一种自然语言查询 q 和一个以 n 列和 m 行组成的表格作 t 为输入,任务是输出一个SQL查询 y ,该查询可以在表格 t 上执行,以得到自然语言查询 q 的正确答案。本文在WikiSQL数据集上进行了实验,该数据集在26375个网络表格上提供了87726个标注好的的<自然语言查询,SQL查询>对。本文在训练模型的过程中既不使用WikiSQL数据集中提供的SQL查询语句也不使用SQL被执行后获得的问题答案。本文使用了执行准确率作为评估指标,它测量生成的SQL查询中产生正确答案的百分比。
3.2 人工规则
表1 人工规则
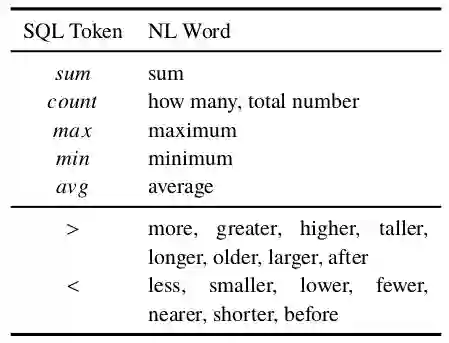
本文首先检测WHERE表达式中的属性值,在WikiSQL数据集中,这些出现在表格单元格中的属性值一般与自然语言查询中的描述一致,可以较为容易的被匹配得到。得到WHERE表达式中的属性值后,即可选择该属性值所在的一列的列标题作为WHERE表达式中该条件的列标题。如果一个单元格出现在多个列中,本文选择与自然语言查询重叠的单词较多的列标题,并限制共出现的单词数大于1。随后本文只需确定WHERE表达式中这个条件的运算符。在默认情况下,这个运算符为=。但在值的周围单词包含表中列出的>和<等关键字的情况下,则将其设置为对应的运算符,例如自然语言查询中若出现了单词"more"和"greater",则倾向于映射到WHERE运算符">"。WHERE表达式生成完毕后,本文开始生成SELECT表达式。本文设定SELECT表达式中的列标题必须是与自然语言查询具有最多的共现单词的列标题,且该列标题不能与任何出现在WHERE表达式中的列标题相同。如果有多个候选列标题符合上述为SELECT表达式制定的规则,则丢弃此条数据。最后本文确定SELECT表达式中的聚合器。默认情况下,聚合器为NONE。若自然语言查询中的单词匹配上了表中的任何关键字,本文将聚合器设置为对应的符号。例如,自然语言查询中若出现了单词"average",则倾向于映射到聚合器"avg"。本文的规则在WikiSQL数据集的训练集上的覆盖率为78.4%,其执行准确率为77.9%。
3.3 对比模型设置
根据训练数据能否被规则处理,本文将其分为规则覆盖部分和非规则覆盖部分。对于规则覆盖部分,可以使用本文定义好的规则从中获取被规则覆盖的训练数据。对于非规则覆盖部分,也可以使用由规则覆盖数据训练好的基线模型来在其上推理从而得到新的训练数据,本文将这些数据称为自我推理(SF)训练数据。此外,可以通过反向翻译得到更多的训练数据,本文将这些数据称为问题生成(QG)的训练数据。对于所有设置,基本模型都是用规则覆盖的训练数据初始化的。在Base+Self-Training方法中,利用自我推理训练数据对基本模型进行微调。在Base+QG方法中,本文使用问题生成训练的数据对基本模型进行优化。在Base+BT方法中,本文同时使用自我推理和问题生成的数据来优化基本模型。在Base+BT+QC中,本文添加了质量控制器,来对自我推理和问题生成的数据进行过滤。在Base+BT+QC+MAML中,本文在上个模型的基础上进一步增加了模型不可知元学习。
3.4 实验结果与分析
表2 实验结果
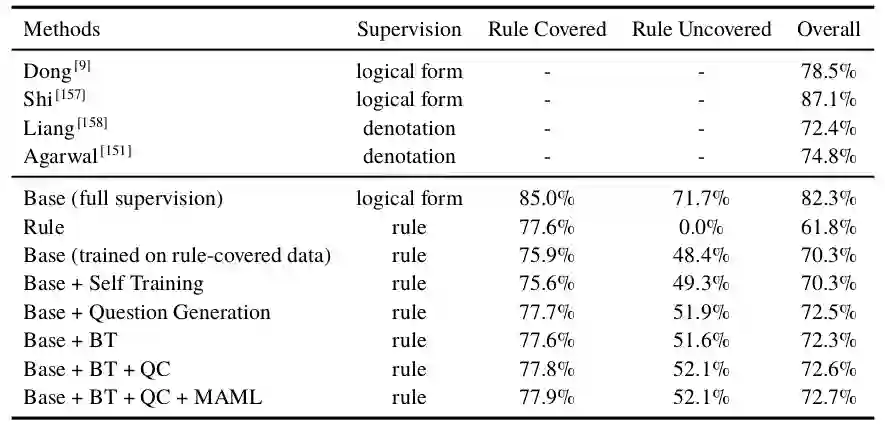
实验结果在表格中给出。可以看出,反向翻译、质量控制和模型不可知元学习等方法的引入会逐步提高准确性。这里的Base+QG比Base+Self-Training设置的结果要好,即问题生成的数据质量要优于自我推理生成的数据质量。这是因为WikiSQL中的逻辑形式相对简单,所以抽样逻辑形式的分布与原始逻辑形式相似。在Base+BT的设置中,生成的例子来自于自我训练和问题生成模型。该模型对规则覆盖实例的性能优于规则覆盖实例,提高了对未覆盖实例的准确性。
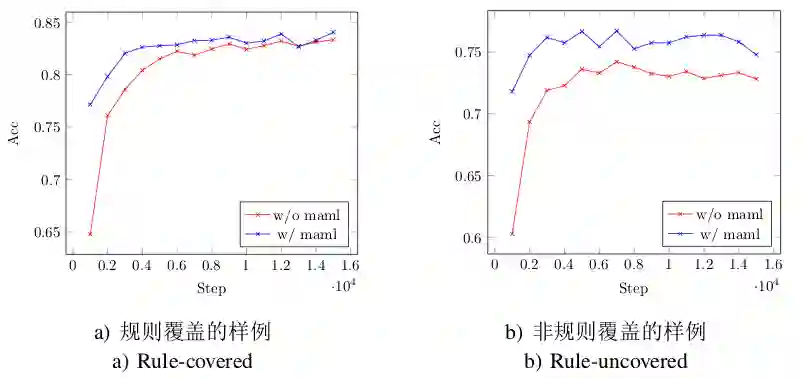
图2 列标题模型预测的学习曲线
上图显示了使用或不使用模型不可知元学习方法后的列标题预测模型的学习曲线。使用了模型不可知元学习训练的模型在训练过程中有较好的起点,这反映了训练参数的有效性。
4. 结论
本文提出了一种在没有标注好的自然语言查询对应的逻辑表达式或其执行答案的条件下,只从简单的与领域无关的规则中学习神经语义解析器的方法。本文提出的方法从规则所涵盖的示例开始,规则用于在反向翻译范式中初始化语义解析器和问题生成器。本文在统计分析的基础上对生成的样例进行测量和过滤,并使用了模型不可知元学习,这保证了模型在对规则覆盖的样例确保准确性和稳定性的同时也获得了很好的对非规则覆盖实例的泛化性和通用性。本文对三个数据集进行了面向表格和面向知识库的自动问答任务的实验。结果表明,采用不同的策略可以逐步提高系统的性能。本文在WikiSQL数据集上的最佳模型达到了当前最佳的从答案中学习的系统的精度。在未来,本文计划关注更复杂的逻辑形式。
延伸阅读
赛尔原创 | AAAI20 基于多任务自监督学习的文本顺滑研究
赛尔原创 | AAAI20 基于选择两方面信息的文档级文本内容改写
赛尔原创 | AAAI20 基于关键词注意力机制和回复弱监督的医疗对话槽填充研究
赛尔原创 | AAAI 2020 故事结局预测任务上的区分性句子建模
本期编辑:冯梓娴