用OpenAI的“后经验重放”来解决算法环境适应问题 | 2分钟读论文

来源 / Two Minute Papers
翻译 / 廖颖
校对 / 凡江
整理 / 雷锋字幕组
AI 研习社出品系列短视频《 2 分钟论文 》,带大家用碎片时间阅览前沿技术,了解 AI 领域的最新研究成果。
本期论文:Hindsight Experience Replay 后经验重放
众所周知,增强学习是一种很棒的算法,可用于计算机游戏,直升机导航,击打棒球,甚至结合神经网络和蒙特卡洛树搜索策略来击败围棋冠军。不仅如此,增强学习也是非常通用的算法,可以处理各种涉及感知环境并得出一系列行为来使得分最大化。
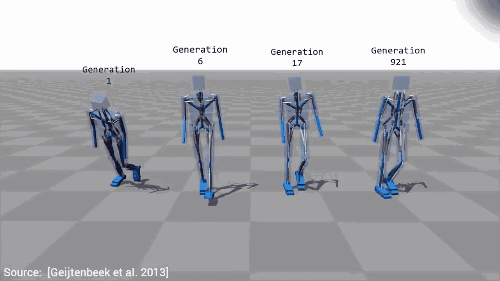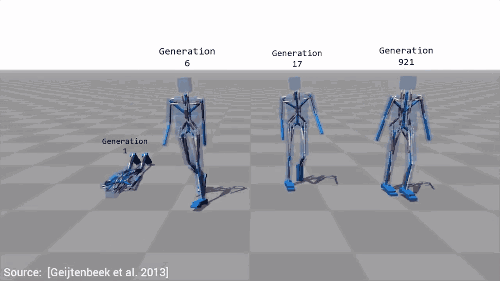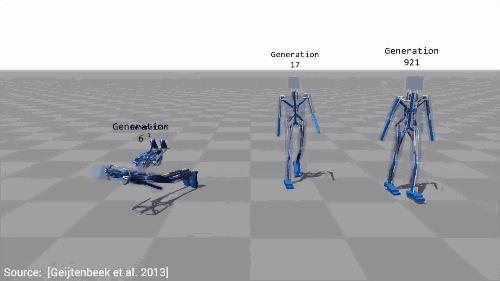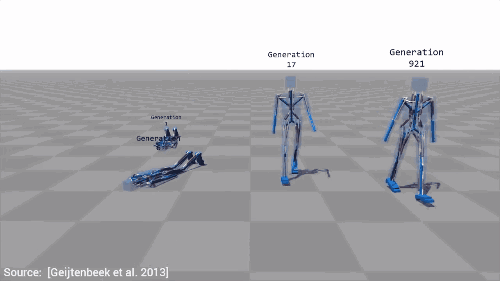
在之前的学习中,我们看见了谷歌DeepMind算法,能在复杂的三维环境中有效选择一系列动作实现导航。最大化的分数由起始点距离测量,我们的物体走得越远,它获得的分数就越高,因而就能成功地学习运动的概念。
要使增强学习得以正常工作,有一个条件是,给它富含信息的回报信号。举个例子,如果参加一个笔试,我们想要将每个问题得分的详细信息作为输出,这样就可以知道自己在哪些方面做得好,哪些地方要更加努力。然而想象一下,有个马虎的老师,从来都不会告诉我我们分数,仅仅告诉我们是否通过考试。
没有解释,没有单个题目的分数,也不告诉我们,是失败了一大截,还是失败了一点点。第一次尝试,我们失败了,第二次我们又失败了,如此往复,我们永远也得不到进步,完全不知道哪里需要改进。毫无疑问,这个老师并不称职。

然而,当计算一个增强学习问题时,相对于使用更多信息的分数,告知算法是否成功会容易得多呢?在直升机控制问题中,当我们几乎撞在树上时,怎么样的分数算有意义呢?这一部分被称为回报工程,核心思想是使问题适用于算法,而最好的是算法能是适应于问题。
这是增强学习研究中长期存在的一个问题,一个可能的解决方案是尽可能开发解决更难更有趣的问题的学习算法。而这正是OpenAI研究团队正在尝试的方法,引入“后验经验重放”(Hindsight Experience Replay),简称为Her或者her,以此来解决问题。可以说是非常恰当了。

该算法在处理问题时,分数均是二值的,也就意味着对规定任务而言,不是通过就是失败,真是一个典型的马虎老师。而这些回报不仅是二值的,同时非常稀疏,这使得问题的难度进一步增加。视频中,你可以看见之前的算法在两种不同的情况下:未结合Her扩展方法和结合Her扩展方法,表现有何差异。
▷ 观看论文解读大概需要 4 分钟
Epoch的数量越多,训练的时间越长。还有一点不可思议的是,它可以实现一个目标,即便它在训练中从未达到过这个目标。关键思想是我们可以从不理想的输出中学习,就像在理想的输出中学习一样。
想象一下你正在学习如何击打曲棍球,并尝试将球击入网中。你打中了球,但是它落在了网外右侧,这种情形况下,一个标准的增强学习算法会得出这样的结论:即执行这个动作序列不能成功进球,学习效果微乎其微。然而,也有可能得出另外一种结论,那就是:这样的行为序列可以成功,如果把球网放在更右的地方。通过储存跟重复之前不同潜在目标的经验,就可以实现这个目标。

现在,这个系统在软件上可以很好地完成测试,而将其配置在真实的机械臂上,也是有用的。你可以在视频中看见,目标就在结果旁边,这项工作很酷的一点是,它可能开发出新的方法来考虑增强学习,毕竟学习算法已经非常好,可以让我们用一种足以被辞退的偷懒方式来解决问题。
阅读论文:https://arxiv.org/pdf/1707.01495.pdf



新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
全文翻译Hinton那篇备受关注的Capsule论文
▼▼▼



