三分钟带你读懂 BERT

本文为 AI 研习社编译的技术博客,原标题 :
BERT Technology introduced in 3-minutes
作者 | Suleiman Khan, Ph.D.
翻译 | 胡瑛皓、stone豪
校对 | 酱番梨 审核 | 约翰逊·李加薪 整理 | 立鱼王
原文链接:
https://towardsdatascience.com/bert-technology-introduced-in-3-minutes-2c2f9968268c
注:本文的相关链接请访问文末二维码
由谷歌公司出品的用于自然语言理解的预训练BERT算法,在许自然语言处理的任务表现上远远胜过了其他模型。
BERT算法的原理由两部分组成,第一步,通过对大量未标注的语料进行非监督的预训练,来学习其中的表达法。其次,使用少量标记的训练数据以监督方式微调预训练模型以进行各种监督任务。预训练机器学习模型已经在各种领域取得了成功,包括图像处理和自然语言处理(NLP)。
BERT的含义是Transformer的双向编码器表示。 它基于Transformer架构(由Google于2017年发布,《Attention Is All You Need》)。 Transformer算法使用编码-解码器网络,但是,由于BERT是预训练模型,它仅使用编码来学习输入文本中的潜在表达。

Photo by Franki Chamaki on Unsplash
技术
BERT将多个transformer编码器堆叠在一起。tranformer基于著名的多头注意模块(multi-head attention)。 它在视觉和语言任务方面都取得了巨大成功。关于attention的回顾,请参考此处:
http://mlexplained.com/2017/12/29/attention-is-all-you-need-explained/
BERT卓越的性能基于两点。 首先创新预训练任务Masked Language Model (MLM)以及Next Sentence Prediction (NSP). 其次训练BERT使用了大量数据和算力。
MLM使得BERT能够从文本中进行双向学习,也就是说这种方式允许模型从单词的前后单词中学习其上下文关系。此前的模型这是做不到的。此前最优的算法称为Generative Pre-training (GPT) 该方法采用了从左到右的训练方式,另外ELMo 采用浅双向学习(shallow bidirectionality)。
MLM预训练任务将文本转换为tokens,把token表示作为训练的输入和输出。随机取其中15%的token进行mask,具体来说就是在训练输入时隐藏,然后用目标函数预测出正确的token内容。这种方式对比以往的训练方式,以往方式采用单方向预测作为目标或采用从左到右及从右到左两组(单方向)去近似双向。NSP任务通过预测后一个句子是否应该接在前一句之后,从而使得BERT可以学习句子间的关系。训练数据采用50%顺序正确的句子对加上另外50%随机选取的句子对。BERT同时训练MLM和NSP这两个目标。
数据及TPU/GPU运行时
BERT训练使用了33亿单词以及25亿维基百科和8亿文本语料。训练采用TPU, GPU,大致情况如下.

BERT训练设备和时间 for BERT; 使用TPU数量和GPU估算.
Fine-tuning训练采用了2.5K~392K 标注样本。重要的是当训练数据集超过100K,在多种超参数设置下模型显示了其稳健的性能。每个fine-tuning实验采用单个TPU均在1小时内完成,GPU上需要几小时。
结果
BERT在11项NLP任务中超越了最优的算法。主要是3类任务,文本分类、文字蕴涵和问答。BERT在SQUAD和SWAG任务中,是第一个超过人类水平的算法!
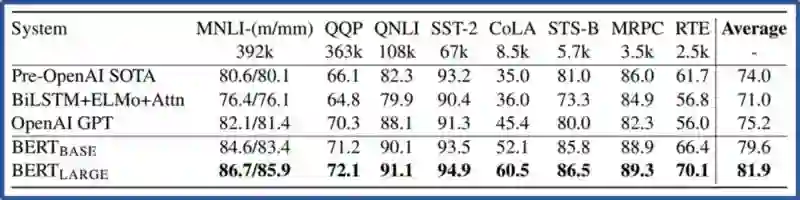
BERT 论文中结果 https://arxiv.org/abs/1810.04805
在分享中使用 BERT
BERT目前已开源: https://github.com/google-research/bert 分别用TensorFlow和Pytorch预训练了104种语言。
模型可进行fine-tuned,然后用于多项NLP任务,诸如文本分类、文本相似度、问答系统、文本标记如词性POS命名和实体识别NER等。当然预训练BERT计算上相当昂贵,除非你采用TPU或类似Nvidia V100这样的GPU。
BERT技术人员同时也放出了多语言模型,模型采用Wikipedia里的100多种语言。不过多语言BERT模型比单语言模型的性能要略低几个百分点。
批判
BERT在MLM任务中的mask策略对真实的单词产生偏见。目前还未显示这种偏见对训练的影响。
参考文献
[1] https://cloud.google.com/tpu/docs/deciding-pod-versus-tpu
[2] Assuming second generation TPU, 3rd generation is 8 times faster. https://en.wikipedia.org/wiki/Tensor_processing_unit
[3] http://timdettmers.com/2018/10/17/tpus-vs-gpus-for-transformers-bert/
想要继续查看该篇文章相关链接和参考文献?
点击底部【阅读原文】或长按下方地址/二维码访问:
https://ai.yanxishe.com/page/TextTranslation/1509

AI求职百题斩 · 每日一题
每天进步一点点,扫码参与每日一题!


点击阅读原文,查看更多内容↙




