【人工智能】深入浅出遗传算法、快速交付机器学习项目
深入浅出遗传算法
来源:数学与人工智能
经典算法研究系列
深入浅出遗传算法
初探遗传算法
Ok,先看维基百科对遗传算法所给的解释:
遗传算法是计算数学中用于解决最优化的搜索算法,是进化算法的一种。进化算法最初是借鉴了进化生物学中的一些现象而发展起来的,这些现象包括遗传、突变、自然选择以及杂交等。
遗传算法通常实现方式为一种计算机模拟。对于一个最优化问题,一定数量的候选解(称为个体)的抽象表示(称为染色体)的种群向更好的解进化。传统上,解用二进制表示(即0和1的串),但也可以用其他表示方法。进化从完全随机个体的种群开始,之后一代一代发生。在每一代中,整个种群的适应度被评价,从当前种群中随机地选择多个个体(基于它们的适应度),通过自然选择和突变产生新的生命种群,该种群在算法的下一次迭代中成为当前种群。
光看定义,可能思路并不清晰,咱们来几个清晰的图解、步骤、公式:
基本遗传算法的框图:
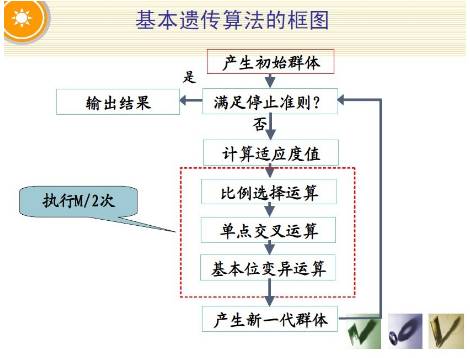
所以,遗传算法基本步骤是:
1) 初始化 t←0进化代数计数器;T是最大进化代数;随机生成M个个体作为初始群体 P(t);
2) 个体评价 计算P(t)中各个个体的适应度值;
3) 选择运算 将选择算子作用于群体;
4) 交叉运算 将交叉算子作用于群体;
5) 变异运算 将变异算子作用于群体,并通过以上运算得到下一代群体P(t + 1);
6) 终止条件判断 t≦T:t← t+1 转到步骤2;
t>T:终止 输出解。
好的,看下遗传算法的伪代码实现:
▲Procedures GA: 伪代码

深入遗传算法
1、智能优化算法概述
智能优化算法又称现代启发式算法,是一种具有全局优化性能、通用性强且适合于并行处理的算法。
这种算法一般具有严密的理论依据,而不是单纯凭借专家经验,理论上可以在一定的时间内找到最优解或近似最优解。
遗传算法属于智能优化算法之一。
常用的智能优化算法有:
遗传算法 、模拟退火算法、禁忌搜索算法、粒子群算法、蚁群算法。
(本经典算法研究系列,日后将陆续阐述模拟退火算法、粒子群算法、蚁群算法。)
2、遗传算法概述
遗传算法是由美国的J. Holland教授于1975年在他的专著《自然界和人工系统的适应性》中首先提出的。
借鉴生物界自然选择和自然遗传机制的随机化搜索算法。
模拟自然选择和自然遗传过程中发生的繁殖、交叉和基因突变现象。
在每次迭代中都保留一组候选解,并按某种指标从解群中选取较优的个体,利用遗传算子(选择、交叉和变异)对这些个
体进行组合,产生新一代的候选解群,重复此过程,直到满足某种收敛指标为止。
基本遗传算法(Simple Genetic Algorithms,GA)又称简单遗传算法或标准遗传算法),是由Goldberg总结出的一种最基本的遗传算法,其遗传进化操作过程简单,容易理解,是其它一些遗传算法的雏形和基础。
3、基本遗传算法的组成
(1)编码(产生初始种群)
(2)适应度函数
(3)遗传算子(选择、交叉、变异)
(4)运行参数
接下来,咱们分门别类,分别阐述着基本遗传算法的五个组成部分:
1)编码
遗传算法(GA)通过某种编码机制把对象抽象为由特定符号按一定顺序排成的串。
正如研究生物遗传是从染色体着手,而染色体则是由基因排成的串。
基本遗传算法(SGA)使用二进制串进行编码。
初始种群:基本遗传算法(SGA)采用随机方法生成若干个个体的集合,该集合称为初始种群。
初始种群中个体的数量称为种群规模。
2)适应度函数
遗传算法对一个个体(解)的好坏用适应度函数值来评价,适应度函数值越大,解的质量越好。
适应度函数是遗传算法进化过程的驱动力,也是进行自然选择的唯一标准,
它的设计应结合求解问题本身的要求而定。
3.1、选择算子
遗传算法使用选择运算对个体进行优胜劣汰操作。
适应度高的个体被遗传到下一代群体中的概率大;适应度低的个体,被遗传到下一代群体中的概率小。
选择操作的任务就是从父代群体中选取一些个体,遗传到下一代群体。
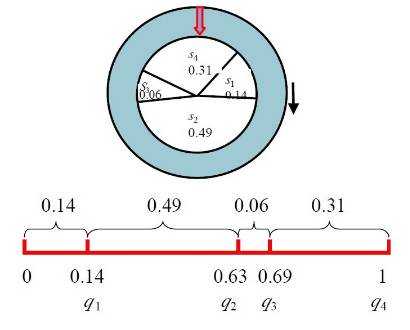
基本遗传算法(SGA)中选择算子采用轮盘赌选择方法。
Ok,下面就来看下这个轮盘赌的例子,这个例子通俗易懂,对理解选择算子帮助很大。
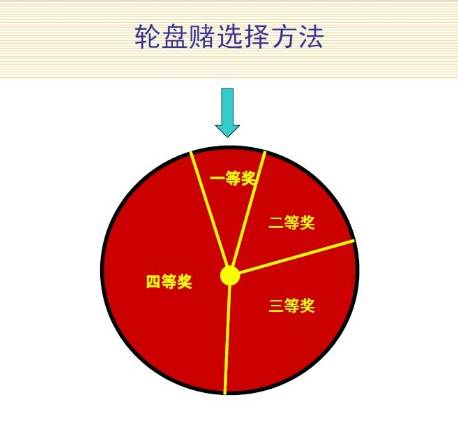
轮盘赌选择方法
轮盘赌选择又称比例选择算子,其基本思想是:
各个个体被选中的概率与其适应度函数值大小成正比。
设群体大小为N,个体xi 的适应度为 f(xi),则个体xi的选择概率为:
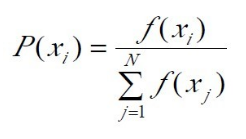
轮盘赌选择法可用如下过程模拟来实现:
(1)在[0, 1]内产生一个均匀分布的随机数r。
(2)若r≤q1,则染色体x1被选中。
(3)若qk-1<r≤qk(2≤k≤N), 则染色体xk被选中。
其中的qi称为染色体xi (i=1, 2, …, n)的积累概率, 其计算公式为:
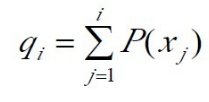
积累概率实例:
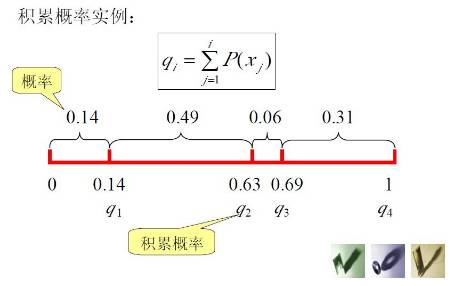
轮盘赌选择方法的实现步骤:
(1)计算群体中所有个体的适应度值;
(2)计算每个个体的选择概率;
(3)计算积累概率;
(4)采用模拟赌盘操作(即生成0到1之间的随机数与每个个体遗传到下一代群体的概率进行匹配)
来确定各个个体是否遗传到下一代群体中。
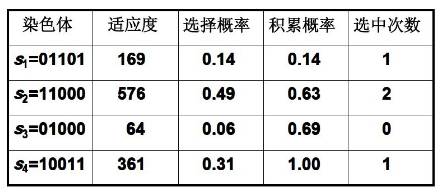
例如,有染色体
s1= 13 (01101)
s2= 24 (11000)
s3= 8 (01000)
s4= 19 (10011)
假定适应度为f(s)=s^2 ,则
f (s1) = f(13) = 13^2 = 169
f (s2) = f(24) = 24^2 = 576
f (s3) = f(8) = 8^2 = 64
f (s4) = f(19) = 19^2 = 361
染色体的选择概率为:

染色体的累计概率为:

根据上面的式子,可得到:
例如设从区间[0, 1]中产生4个随机数:
r1 = 0.450126, r2 = 0.110347
r3 = 0.572496, r4 = 0.98503
3.2、交叉算子
交叉运算,是指对两个相互配对的染色体依据交叉概率 Pc 按某种方式相互交换其部分基因,
从而形成两个新的个体。
交叉运算是遗传算法区别于其他进化算法的重要特征,它在遗传算法中起关键作用,
是产生新个体的主要方法。
基本遗传算法(SGA)中交叉算子采用单点交叉算子。
单点交叉运算

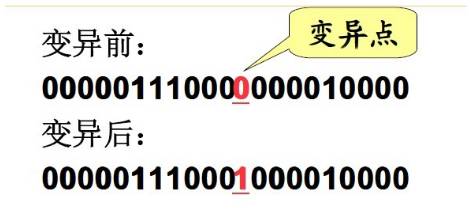
3.3、变异算子
变异运算,是指改变个体编码串中的某些基因值,从而形成新的个体。
变异运算是产生新个体的辅助方法,决定遗传算法的局部搜索能力,保持种群多样性。
交叉运算和变异运算的相互配合,共同完成对搜索空间的全局搜索和局部搜索。
基本遗传算法(SGA)中变异算子采用基本位变异算子。
基本位变异算子是指对个体编码串随机指定的某一位或某几位基因作变异运算。
对于二进制编码符号串所表示的个体,若需要进行变异操作的某一基因座上的原有基因值为0,
则将其变为1;反之,若原有基因值为1,则将其变为0 。
基本位变异算子的执行过程:
4)运行参数
(1)M :种群规模
(2)T : 遗传运算的终止进化代数
(3)Pc :交叉概率
(4)Pm :变异概率
浅出遗传算法
遗传算法的本质
遗传算法本质上是对染色体模式所进行的一系列运算,即通过选择算子将当前种群中的优良模式遗传
到下一代种群中,利用交叉算子进行模式重组,利用变异算子进行模式突变。
通过这些遗传操作,模式逐步向较好的方向进化,最终得到问题的最优解。
遗传算法的主要有以下八方面的应用:
(1)组合优化 (2)函数优化 (3)自动控制 (4)生产调度
(5)图像处理 (6)机器学习 (7)人工生命 (8)数据挖掘
遗传算法的应用
遗传算法的应用举例、透析本质(这个例子简明、但很重要)
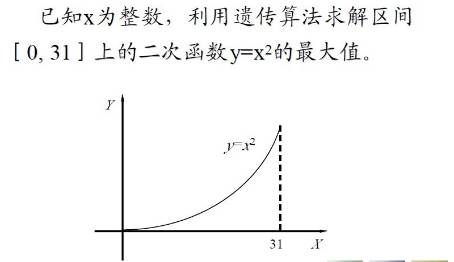
已知x为整数,利用遗传算法求解区间[0, 31]上的二次函数y=x2的最大值。
[分析]
原问题可转化为在区间[0, 31]中搜索能使 y 取最大值的点 a 的问题。
个体:[0, 31] 中的任意点x
适应度:函数值f(x)=x2
解空间:区间[0, 31]
这样, 只要能给出个体x的适当染色体编码, 该问题就可以用遗传算法来解决。
[解]
(1) 设定种群规模,编码染色体,产生初始种群。
将种群规模设定为4;用5位二进制数编码染色体;取下列个体组成初始种群S1
s1= 13 (01101), s2= 24 (11000)
s3= 8 (01000), s4= 19 (10011)
(2) 定义适应度函数, 取适应度函数
f (x)=x^2
(3) 计算各代种群中的各个体的适应度, 并对其染色体进行遗传操作,
直到适应度最高的个体,即31(11111)出现为止。
首先计算种群S1中各个体:
s1= 13(01101), s2= 24(11000)
s3= 8(01000), s4= 19(10011)
的适应度f (si), 容易求得:
f (s1) = f(13) = 13^2 = 169
f (s2) = f(24) = 24^2 = 576
f (s3) = f(8) = 8^2 = 64
f (s4) = f(19) = 19^2 = 361
再计算种群S1中各个体的选择概率:
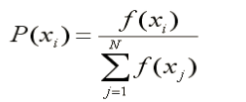
由此可求得
P(s1) = P(13) = 0.14
P(s2) = P(24) = 0.49
P(s3) = P(8) = 0.06
P(s4) = P(19) = 0.31
再计算种群S1中各个体的积累概率:
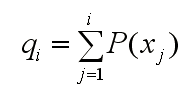
选择-复制
设从区间[0, 1]中产生4个随机数如下:
r1 = 0.450126, r2 = 0.110347
r3 = 0.572496, r4 = 0.98503
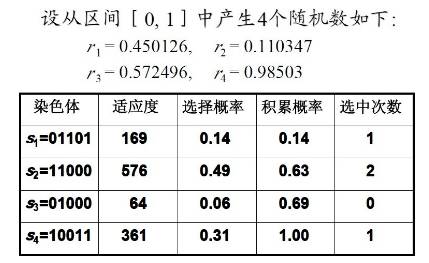
于是,经复制得群体:
s1’ =11000(24), s2’ =01101(13)
s3’ =11000(24)(24被选中俩次), s4’ =10011(19)
交叉
设交叉率pc=100%,即S1中的全体染色体都参加交叉运算。
设s1’与s2’配对,s3’与s4’配对。
s1’ =11000(24), s2’ =01101(13)
s3’ =11000(24), s4’ =10011(19)
分别交换后两位基因,得新染色体:
s1’’=11001(25), s2’’=01100(12)
s3’’=11011(27), s4’’=10000(16)
变异
设变异率pm=0.001。
这样,群体S1中共有
5×4×0.001=0.02
位基因可以变异。
0.02位显然不足1位,所以本轮遗传操作不做变异。
于是,得到第二代种群S2:
s1=11001(25), s2=01100(12)
s3=11011(27), s4=10000(16)
第二代种群S2中各染色体的情况:
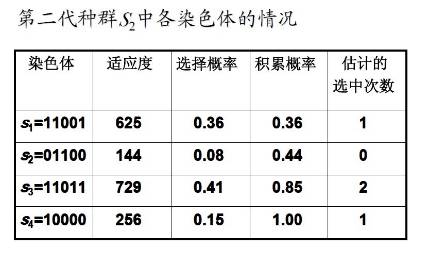
假设这一轮选择-复制操作中,种群S2中的4个染色体都被选中,则得到群体:
s1’=11001(25), s2’= 01100(12)
s3’=11011(27), s4’= 10000(16)
做交叉运算,让s1’与s2’,s3’与s4’ 分别交换后三位基因,得
s1’’=11100(28), s2’’ = 01001(9)
s3’’ =11000(24), s4’’ = 10011(19)
这一轮仍然不会发生变异。
于是,得第三代种群S3:
s1=11100(28), s2=01001(9)
s3=11000(24), s4=10011(19)
第三代种群S3中各染色体的情况:
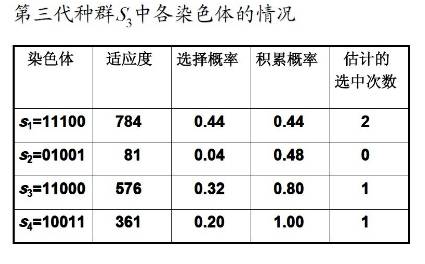
设这一轮的选择-复制结果为:
s1’=11100(28), s2’=11100(28)
s3’=11000(24), s4’=10011(19)
做交叉运算,让s1’与s4’,s2’与s3’ 分别交换后两位基因,得
s1’’=11111(31), s2’’=11100(28)
s3’’=11000(24), s4’’=10000(16)
这一轮仍然不会发生变异。
于是,得第四代种群S4:
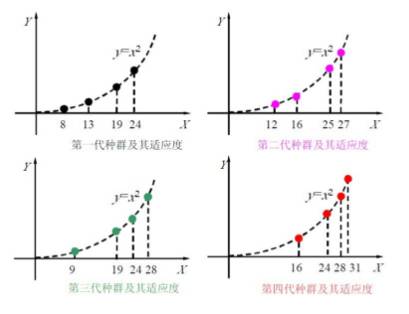
s1=11111(31)(出现最优解), s2=11100(28)
s3=11000(24), s4=10000(16)
显然,在这一代种群中已经出现了适应度最高的染色体s1=11111。
于是,遗传操作终止,将染色体(11111)作为最终结果输出。
然后,将染色体“11111”解码为表现型,即得所求的最优解:31。
将31代入函数y=x2中,即得原问题的解,即函数y=x2的最大值为961。
所以,综合以上各代群的情况,如下:
快速交付机器学习项目:ML工程循环指南
编者按:Insight Data Science AI负责人Emmanuel Ameisen和前百度硅谷人工智能实验室主管Adam Coates分享了快速交付机器学习项目的经验。

由于机器学习(ML)日益成为每个产业的重要组成部分,对机器学习工程师的需求增长迅猛。机器学习工程师结合机器学习技术与软件工程知识,为给定的应用寻求表现优异的模型,同时处理随之而来的实现的挑战——从创建训练基础设施到为部署模型做准备。虽然网上不断出现训练工程师创建ML模型并解决遇到的各种软件挑战的资源,而新ML团队最常遇到的一个障碍却是保持和传统软件工程同等水准的进度。
这一挑战最关键的原因是开发新ML模型的过程从一开始就是高度不确定的。毕竟,在最后的训练完成之前,很难知晓模型表现有多好,更别说大量的调参和采用不同的建模假定对模型表现有什么影响了。
多种职业人士面临类似的情况:软件和商业开发者,寻求产品-市场契合的初创企业,处于信息有限的演习之中的飞行员。每种职业人士采用一种常见框架以帮助团队在不确定的情况下高效作业:软件开发的敏捷原则,精益创业,美国空军的OODA循环。机器学习工程师可以遵循类似的框架,应对不确定性,迅速交付伟大的产品。
ML工程循环
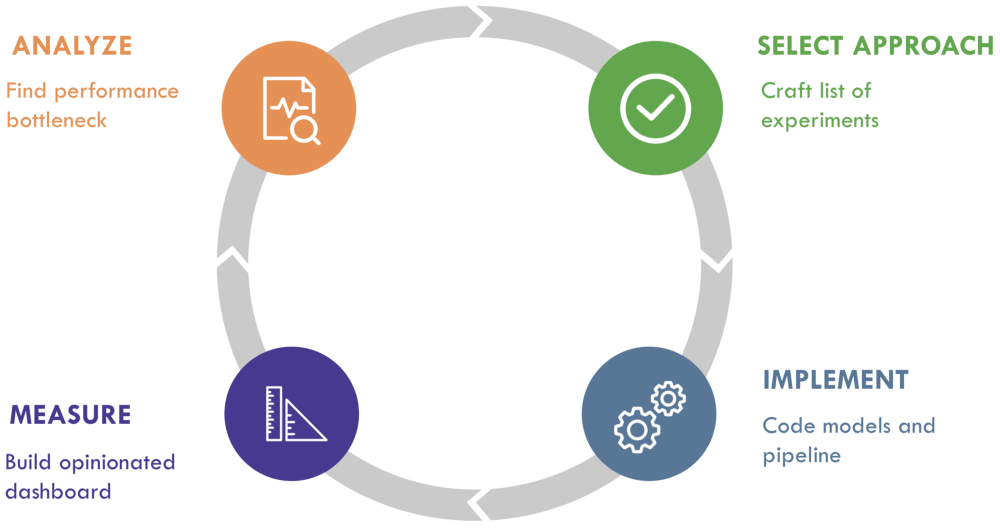
本文将介绍机器学习的OODA循环:ML工程循环,其中ML工程师不断进行以下四个步骤:
分析
选型
实现
测量
从而快速、高效地发现最佳模型,并适应未知数据。此外,我们也为每个阶段提供了具体的窍门,并将介绍如何优化整个过程。
ML团队的成功常常意味着交付满足给定限制的表现优异的模型——例如,在满足内存占用、推理时间、公平性等限制的前提下,达到较高的预测精确度。表现是由和最终产品最相关的测度定义的,不管它是精确度,速度,还是输出的多样性。出于简单性,下文的表现测度我们选择了最小化“误差率”。
刚开始着手一个新项目时,你应该精确地定义成功标准,之后将其转换为模型测度。用产品术语来说,服务需要具备什么级别的表现才有用?例如,如果新闻平台向用户分别推荐5篇文章,其中需要多少篇用户相关的文章,我们又如何定义相关性?给定表现标准和现有数据,你可以创建的最简单的模型是什么?
ML工程循环的目的是提供一个开发过程中牢记的心智模型,简化决策过程,以集中精力处理下一个重要步骤。随着从业者经验的积累,这一过程变为从业者的第二本能,可以快速果断地在分析和实现间切换。话是这么说,不过,当不确定性增加时,即使是最有经验的工程师也会发现这一框架价值非凡——例如,模型出乎意料地没能满足需求,团队目标突然调整(例如,为了体现产品需求的变动,测试集做了改动),团队进程因缺乏目标而停滞。
开始
为了启动这一循环,你应该先从一个基本不涉及不确定性的最小实现开始。通常我们想要尽可能快地“得到一个数字”——创建一个足以评估表现并开始迭代的系统。这通常意味着:
开始设置训练、验证、测试集。
实现一个可以工作的简单模型。
例如,如果我们需要创建一个树检测器以调查某一区域的树木,我们也许可以使用相关Kaggle竞赛中现成的数据作为训练集,并使用我们自行收集的一组目标区域的照片作为验证集和测试集。我们接着可以在原始像素上运行逻辑回归,或者在训练图像上运行预训练好的网络(比如ResNet)。这里的目标不是一下子完结这个项目,而是开启我们的迭代循环。下面是一些有助于你达成这一点的窍门:
窍门
关于良好的测试集:
由于团队的目标是在测试集上取得较优表现,测试集实质上描述了团队的目标。因此,测试集应当反映产品或业务的需求。例如,如果你正创建一个基于自拍检测皮肤状况的应用,你可以在任意图像上训练,但需确保测试集包含光照和画质不佳的图像,因为一些自拍很可能出现这类情况。
改变测试集意味着调整团队的目标,所以最好及早固定测试集,仅当项目、产品、业务目标发生变动时才改动测试集。
尽量使测试集和验证集足够大,这样才能得到足够精确的表现测度,从而很好地区分不同的模型。如果测试集太小,你最终将基于噪声数据得出结论。
类似地,你应该在实际情况允许的情况下,尽可能确保测试集和验证集的标签和标注足够精确。错误标注的测试集差不多等于没有正确说明的产品需求。
了解人类或现存/竞争系统在测试集上的表现很有帮助。这给出了最优误差率的界限,也就是你可能取得的最佳表现。
对许多任务而言,达到和人类相当的水平经常是一个很好的长期目标。在任何情况下,最终目标都是使测试表现尽可能接近我们猜测的最佳表现。
关于验证集和训练集:
验证集是测试表现的代理,可用于调整超参数。因此,验证集的分布应当和测试集一致。不过,理想情形下,验证集和测试集应该来自不同组别的用户/输入,这可以避免数据泄露。确保这一点的一个好办法是首先积累大量样本,然后打乱顺序,之后将其分割为验证集和测试集。
如果在你的设想中,产品数据会有很多噪声,确保训练集考虑到了噪声问题(比如使用数据增强或数据劣化)。你不能期望完全在锐利图像上训练的模型能很好地推广到模糊图像。
实现了初始原型之后,你应该在训练集、验证集、测试集上测试它的表现。这标志着你度过了循环的第一个(退化的)周期。评估测试表现和有用的产品所需表现之间的差距。现在到了开启迭代的时刻了!

分析
识别表现瓶颈
在实践中,可能有许多交叉的问题导致了当前的结果,但你的目标是首先找出最明显的问题,这样你就可以快速解决它。不要拘泥于试图完全理解所有缺陷——转而理解最关键的因素,因为在你改进模型之后,许多小问题会改变,甚至消失。
我们下面列出了一些常见的诊断。选择从哪方面开始多多少少是门手艺,但随着ML工程循环的进行,你将逐渐获得尝试哪个的直觉。
对所有分析而言,一个很好的起点是查看训练集、验证集、测试集上的表现。我们建议你写代码在每次试验后自动进行这一比较,养成习惯。平均来说,我们有:训练集误差 <= 验证集误差 <= 测试集误差 (如果三个数据集中的数据遵循同一分布)。基于上一次试验的训练、验证、测试误差率,你可以快速地获知哪个因素是当前最大的限制。例如,如果训练误差和验证误差存在一定差距,那么训练误差是提升表现的瓶颈。
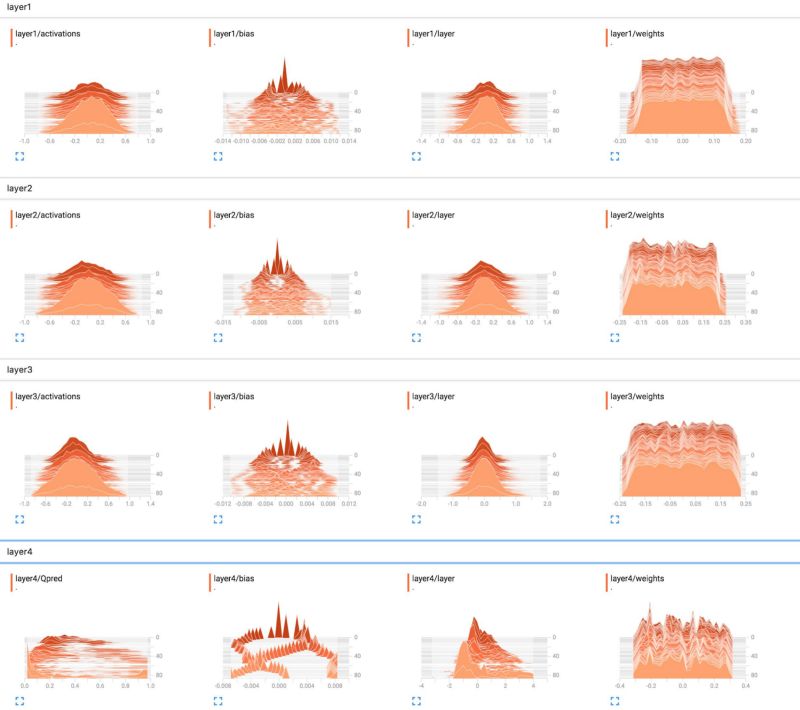
诊断
如果训练集误差是当前的限制因素,那么可能的问题有:
优化算法(例如,深度神经网络的梯度下降)没有调整准确。看看学习曲线,损失有没有下降。检查下是否能够过拟合一个小很多的数据集(例如,在单个minibatch甚至单个样本上训练)。你可以可视化神经元反应的直方图,看看它们有没有饱和(这可能会导致梯度消失)。
训练集可能有标注错误或毁坏的数据。在传给训练算法前,手工检查一些训练样本。
模型可能过小、过于简单。例如,如果你在高度非线性的问题上应用线性回归,你的模型无法很好地拟合数据。我们称为高偏差或欠拟合。
如果验证集误差是当前的限制因素,那么可能的问题有:
模型可能过大、过于复杂,或者正则化不够。我们称为高方差或过拟合。
训练数据不足。
训练数据的分布和验证集、测试集分布不同。
模型的超参数设得不好。如果你搜索最佳超参数(比如特征集、正则项),那可能是搜索方法难以找到较好的选择。
模型编码的“归纳先验”和模型匹配不好。例如,如果数据集用一个线性函数表示更自然,使用最近邻方法也许很难推广,除非你有海量训练数据。
如果测试集误差是当前的限制因素,这常常是因为验证集太小,或者团队在多次尝试的过程中过拟合验证集了。
不管是上面哪种情况,你都可以通过手工检查一组模型出错的随机样本,理解模型的缺陷(一般情况下你不应该在测试集上这么做,以避免在测试样本上“训练”系统)。
通过可视化数据尝试识别常见类型的误差。然后检查样本,记录每种类型的误差出现的频率。分类问题可以看下混淆矩阵,找出表现最差的分类。接着你就可以集中精力解决导致最多错误的那类误差。
有些样本可能错误标注了,或者有多种合理的标签。
有些样本可能比其他样本更难判断,或者缺乏做出判断需要的上下文。在若干种误差同样常见的时候,将一些样本标记为“很难”也许有助于你将精力花在容易得到改进的地方。类似地,将一些样本标记为“很容易”也许有助于你找出系统中细小的错误,导致模型在容易的情形上犯错。这有点像在数据的不同子集上估计“最优误差率”,接着深入进展空间最大的子集。
注意,上面的许多诊断有着直接、明显的解决方案。例如,如果训练数据太少了,那就获取更多训练数据!我们发现在心智上分隔分析阶段和(下面的)选型阶段是有帮助的,因为我们很容易陷入随机尝试各种方法,而没有真正分析背后问题的状况。另外,保持开阔的思路,勤于返回误差分析阶段,经常能够揭示有用的洞见,有助于改善你的决策。
例子

众所周知,卫星数据噪声很多,常常需要仔细检查
例如,Insight Data Science的Jack Kwok在创建一个帮助灾后重建的分割系统时,注意到尽管分割模型在卫星图像训练集上表现良好,在验证集上的表现却很差。这是因为验证集包含受到飓风袭击的城市,这些飓风图像的画质比训练数据差,更加模糊。通过在训练阶段增加一个额外的数据增强步骤,在图像上应用模糊滤镜,有助于降低训练集和验证集的表现差异。
在语音识别系统上,对验证集的深入误差分析可能揭示具有和大多数用户很不一样的浓重口音的说话人贡献了不成比例的误差数量。那么接着就可以检查下训练集,看看是否具备足够比例的类似口音样本,这些样本是否正确标注,训练算法能否成功拟合这些样本。部分用户类别代表性不够或者错误标注是一个机器学习偏见的例子。Google的语音系统采取的一种解决方案是主动向口音很重的用户请求更多训练数据。

选型
找出处理瓶颈的最简单方式
完成分析之后,你对模型造成了哪些类型的误差和影响表现的是哪些因素已经心中有数。就给定的诊断而言,也许有若干潜在的解决方案,下一步就是把它们列举出来,并制定优先级。
有些诊断直接导向潜在的解决方案。例如,如果你的优化器看起来没有调好,你可以尝试不同的学习率,或者考虑干脆换一种优化算法。如果训练数据集过小,收集更多的训练数据可能是合理、快速、容易的解决方案。
我们建议ML工程师及其团队列出尽可能多的也许有效的想法,接着采用简单、快速的解决方案。如果现有的解决方案可能有效(例如,使用你的工具箱中已经实现的另一种优化算法),就从现有方案开始。尽管更复杂的方法也许看起来能在一次巨大的转变中解决更多问题,我们常常发现多次快速迭代带来的改进超过了摸索当前最先进技术带来的收益。如果你可以在标注1000个数据点和研究最前沿的无监督学习方法中做选择,我们觉得你应该选择收集和标注数据。如果你可以从一些简单的启发式算法开始,就这么干。
窍门
取决于你的瓶颈,这里是一些常见的解决方案。
如果你需要调整优化器,以更好地拟合数据:
对数值优化器而言,尝试调整学习率或动量设定。从一个小动量(0.5)开始通常是最容易奏效的方法。
尝试不同的初始化策略,或者从预训练模型开始。
尝试一种容易调参的模型。在深度学习中,残差网络和带批归一化的网络可能训练起来要容易一点。
如果模型不能很好地拟合训练数据:
使用更大、更有表达力的那类模型。例如,使用决策树时,你可以配置更深的决策树。
检查训练集中模型出错的样本,看看有没有错误标注或缺失项。花时间清洗训练数据可以显著改善结果。
如果模型难以推广至验证集:
增加更多训练数据。注意,也许需要集中添加和验证集中所见误差类别类似的训练样本。
基于真实训练样本,生成新样本,以增强数据。例如,如果你注意到树检测器在有雾的图像上一贯表现糟糕,那么可以加上增强步骤,使用OpenCV让图像看起来雾蒙蒙的。
扩大搜索超参数的范围,或者进行更细致的搜索,确保找到在验证集上表现最佳的模型。
尝试不同的正则化方式(例如神经网络的权重衰减、dropout,决策树的剪枝)。
尝试不同类型的模型。不同类型的模型可以改变拟合和推广的表现,所以很难知道什么时候这个方法有用。深度学习的一大优势在于,有范围很广的神经网络构件可供尝试。如果你使用传统的模型(例如决策树或高斯混合模型),切换不同类型的模型需要花费更多精力。如果新模型内含的假定更正确,那么这一改变也许会有帮助——但最好先从容易的模型开始尝试。

实现
只创建需要创建的,快速创建
你知道应该尝试什么,并且已经简化了问题,现在只不过是实现而已……“只不过”。这一阶段的目标是快速创建原型,这样你就可以测量结果,并从中学习,然后快速开启下一轮循环。因此,我们建议你集中精力创建当前试验需要的东西。注意,尽管这一阶段的目标是快速学习,而不是打磨一切,你的实现仍然需要是正确的,这样你就可以频繁地检验代码是否能如期望一般工作。
窍门
在收集和标注数据时:
经常查看数据。查看原始数据,查看预处理后的数据,查看标签。这些再强调也不为过!仅仅是在收集、标注数据的流程中留心一点,就能捕捉许多误差。在Insight Data Science,我们经常碰到和数据清洗、包围盒坐标、分割掩码相关的bug。
标注、清洗数据是日常任务。大多数人高估了收集、标注数据的代价,却低估了在数据匮乏的环境下解决问题的难度。如果方法得到,很容易就在一分钟内标注用于分类问题的20张图像。你是愿意花一小时标注图像,得到一个包含1200张图像的数据集,再花一小时解决一个简单的分类问题,还是花3周时间尝试让一个模型基于5个样本学习?
当你为新模型写代码时,从一个类似的现有实现开始。许多论文现在都公布代码——所以在重新实现论文中的一个想法前,先获取配套的代码,因为论文常常漏掉一些细节。这会为你节省几小时乃至几天。如果可能的话,不管是什么问题,我们都建议遵循以下步骤:
寻找一个解决类似问题的模型实现。
在本地重现现有模型的实现(同样的数据集和超参数)
慢慢调整模型实现和数据工作流以匹配你的需求
重写需要重写的部分
编写测试以检查梯度、张量值、输入数据、标签的格式对不对。刚开始设置模型的时候就写测试,这样,如果捕捉到了错误,就不会再犯。

测量
打印测试结果和决定是否可以发布需要考虑的其他测度(例如,生产环境限制)。
如果表现某种程度上在提高,那么你也许处于正确的方向上。这种情况下,现在也许是完善你知道工作良好的那些部件的时机。另外,确保团队里的其他成员能够重现你的试验结果。
另一方面,如果表现在下降,或者没怎么提高,你需要决定是再试一下(重返分析阶段)还是放弃当前想法。如果ML循环的每一步都相对廉价,那就更容易做出决策:你不必花费过多精力让你的代码趋于完美,再尝试一次也不会花费太多时间——所以你可以根据想法的风险和收益做出决策,而不会受到沉没成本的干扰。
窍门
有用的表现测度包括ML方面的精确度和损失,以及商业价值测度。记住商业价值测度是最终的测度,因为正是它们决定了你创建的产品的有用程度。如果测试测度(ML代码优化的目标)偏离了商业测度,那么测量阶段结束之后,应该停下来考虑修改优化标准或测试集。
既然每个开发循环的末尾总是需要打印测度,同时计算分析阶段所需的其他测度会比较方便。
经常情况是,你最终创建了一个类似“控制面板”的东西,其中包含测试测度和商业测度,还有其他有用的数据。这在团队协作中特别有用。
优化循环
尽管机器学习任务具有内在的不确定性,上面的ML工程循环将帮助你有条不紊地迈向一个更好的模型。不幸的是,它一点也不神奇——你需要发展在每个阶段做出良好决策的能力,例如识别表现瓶颈,决定尝试哪种解决方案,如何正确地实现它们,以及如何测量应用的表现。你也需要习惯快速迭代的节奏。因此,你也应该花时间思考如何提高迭代的质量和速度,这样可以在每次循环中最大化进展,并且可以快速地完成多次迭代。
窍门
如果分析阶段拖慢了你的进度,那就创建一个脚本,总结每次试验结果,从训练集和验证集搜集误差,并以良好的格式打印出来。这种包含常用诊断信息的“控制面板”可以帮助你战胜“啊!我又得手工运行这些分析了……不如试试这个随机解决方案吧”这样的想法。
如果你觉得自己对到底尝试什么毫无头绪,那就随便选一样。一下子尝试做太多事情会拖慢你的进度。有时候你可以在运行试验的时候回过头来尝试另一个想法!
收集数据是取得更好表现的常用方式。如果获取更多数据听起来很痛苦,但是确实可以改变结果,那么也许应该投资让数据更容易收集、清洗、标注的工具。
如果你觉得自己陷入了困境,诊断不出瓶颈,或者选不出接下来试验的模型,考虑向专家咨询。领域专家经常能够就误差分析提供宝贵的洞见(例如,指出导致某些情形困难或容易的微妙差别),而研究论文或有经验的ML从业者也许可以为你提供值得尝试的创造性解决方案(如果你可以和他们分享详细的分析,他们可以更好地帮助你)。
良好的实现技能很重要,代码规范可以防止bug产生。话是这么说,由于相当大比例的想法会失败,因此在迭代过程中,在试验代码中使用一些临时性的不规范做法也没什么大不了的,毕竟失败的代码最终会被丢弃。一旦你确信自己取得了有用的进展,你可以在下一次循环之前根据规范清理代码。
如果试验时间过长,考虑花点时间看看能不能优化代码。或者和系统专家讨论下如何让训练更快。拿不定主意的时候,考虑升级GPU,或者并行运行更多试验,这些是ML试验“时忙时闲”问题久负盛名的解决方案。
和其他决策一样,仅当可以解决当前痛点的时候才致力于这些事项。有些团队花了太多时间创建“完美”的框架,最后发现真正的问题在别的地方。
结语
ML项目内在地具有不确定性,我们上面推荐的方法可以作为引导你前进的扶手。由于试验的命运不确定,你很难为达成特定的精确度目标而负责,但你至少可以负责完成误差分析,列出想法列表,编码实现,看看它们表现如何。就我们的经验而言,拒绝那些闪闪发光的模型的召唤,果断地集中精力于取得递增的进展,可以在研究和应用中导向杰出的成果。这曾经转变了很多团队,让无数Insight Data Science的工程师得以交付前沿项目。
如果你有什么要问的,欢迎留言,或通过Twitter联系两位作者(EmmanuelAmeisen和adampaulcoates)。
感谢Lacey Cope和Adam Coates对本文草稿给出的反馈。
原文地址:https://blog.insightdatascience.com/how-to-deliver-on-machine-learning-projects-c8d82ce642b0

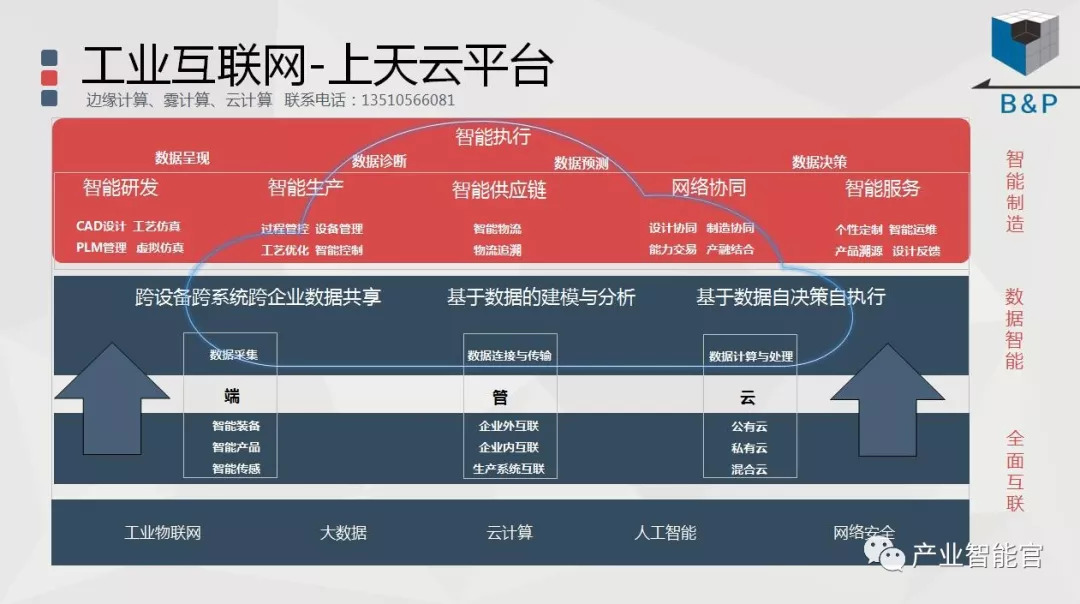
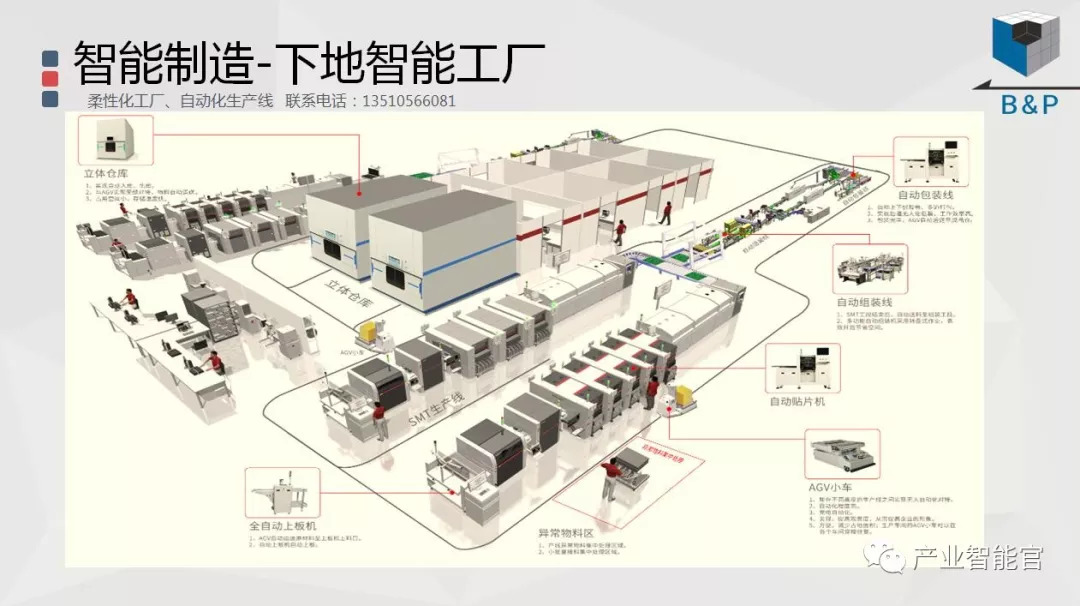
工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进产业OT(工艺+自动化+机器人+新能源+精益)技术和新一代信息IT技术(云计算+大数据+物联网+区块链+人工智能)深度融合,在场景中构建状态感知-实时分析-自主决策-精准执行-学习提升的机器智能认知计算系统;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。
版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。