Soft-Masked BERT:文本纠错与BERT的最新结合
 !
!
阅读大概需要10分钟 ![]()
跟随小博主,每天进步一丢丢 ![]()


1. 文本纠错示例与难点
2. 文本纠错常用技术
3. 如何将 BERT 应用于文本纠错
4. 文本纠错最优模型:Soft-Masked BERT(2020-ACL)
5. 立马上手的纠错工具推荐
生活中常见的文本错误可以分为(1)字形相似引起的错误(2)拼音相似引起的错误 两大类;如:“咳数”->“咳嗽”;“哈蜜”->“哈密”。错别字往往来自于如下的“相似字典”。


Wrong: "我想去埃及金子塔旅游。"
Right: "我想去埃及金字塔旅游。"
Wrong: "他的求胜欲很强,为了越狱在挖洞。"
Right: "他的求生欲很强,为了越狱在挖洞。"
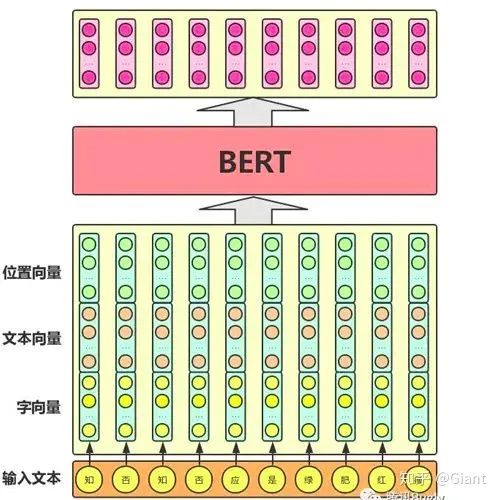
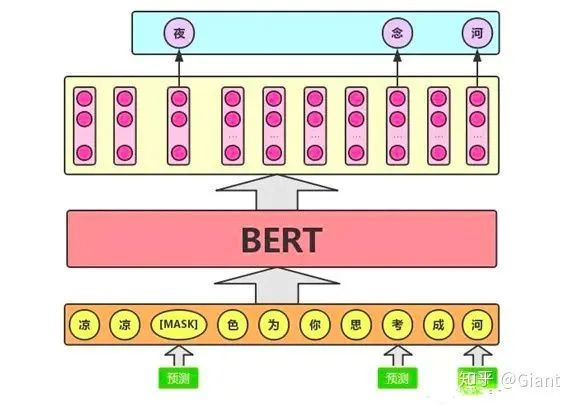
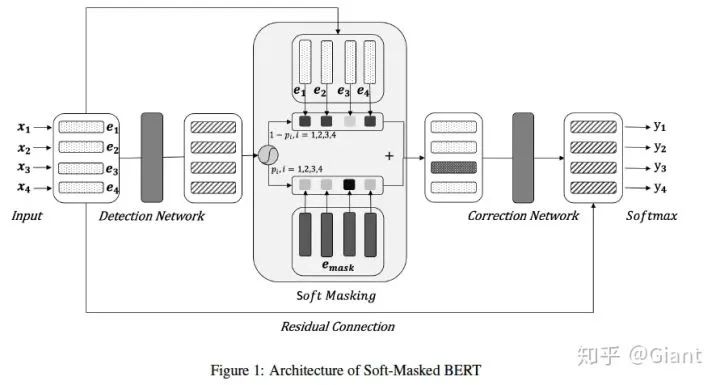
论文简要分析
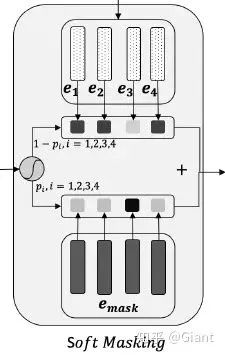
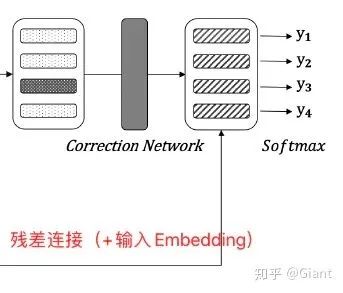
检测网络 与 Soft Masking
 的概率乘上 masking 字符的特征
的概率乘上 masking 字符的特征
 ,以
,以
 的概率乘上原始的输入特征,最后两部分相加作为每一个字符的特征,输入到纠正网络中。原文描述:
的概率乘上原始的输入特征,最后两部分相加作为每一个字符的特征,输入到纠正网络中。原文描述:

纠正网络
 (残差连接)作为每个字符最终的特征表示。
(残差连接)作为每个字符最终的特征表示。


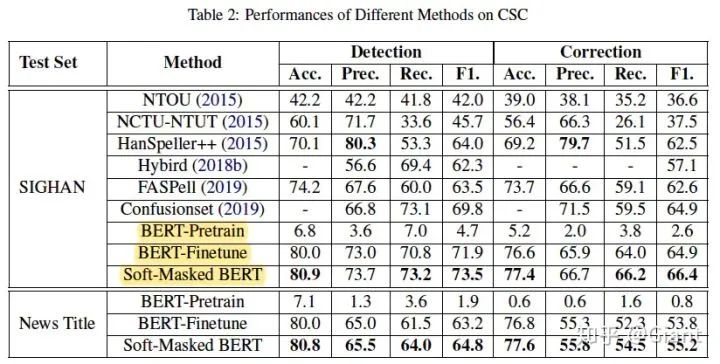
实验结果

对京东新人度大打折扣 --> 对京东信任度大打折扣
我想买哥苹果手机 --> 我想买个苹果手机
Reference
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦

登录查看更多
相关内容
Arxiv
0+阅读 · 2020年10月15日
Arxiv
8+阅读 · 2019年3月22日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2020年10月15日
Arxiv
8+阅读 · 2019年3月22日