单目视频无监督深度学习的结构化方法
文 / Google 机器人团队研究员 Anelia Angelova
对自主机器人而言,感知场景深度是一项重要任务,因为准确估算机器人与目标之间距离的能力对避开障碍、安全规划和导航至关重要。我们可以通过光学雷达等设备的传感器数据获取(和了解)深度,同时也可以通过机器人运动和因此产生的不同场景视角,以无监督方式,仅从单目摄像机了解深度。如此一来,我们还可以学习 “自我运动”(机器人/摄像机在两个帧之间的运动),并据此了解机器人自身的定位。虽然此方法由来已久(得益于运动恢复结构和多视图几何学范式),但基于学习的新技术已提升目前的技术水平。更具体地说是通过深度神经网络进行无监督深度学习和自主运动,其中包括 Zhou 等人的研究和我们自己之前的研究(在训练期间对齐场景 3D 点云)。
尽管我们已做出这些努力,但学习预测场景深度和自主运动仍是一项持续性挑战,而在处理高动态场景和准确估算移动目标的深度时尤其如此。由于之前的无监督单目学习研究工作并未对移动目标进行建模,因此可能一直错估目标深度,而这往往会导致我们将其深度映射为无穷大的值。
在《不使用传感器的深度预测:利用单目视频无监督学习的架构》(Depth Prediction Without the Sensors: Leveraging Structure for Unsupervised Learning from Monocular Videos)(本文将于 AAAI 2019 大会上发布)一文中,我们提出一种新方法,能够对移动目标进行建模,并产生高质量的深度估算结果。相较于之前的单目视频无监督学习方法,我们的方法可以获取移动目标的正确深度。在此论文中,我们还提出一项无缝在线优化技术,该技术可以进一步提升学习质量,并可应用于跨数据集转移。此外,为了鼓励大家开发出更先进的机载机器人学习方法,我们在 TensorFlow 中开放了 源代码(https://github.com/tensorflow/models/tree/master/research/struct2depth)。

之前的研究(中间列)无法正确估算移动目标的深度,并将其映射为无穷大的值(热图中的深蓝色区域)。我们的方法(右列)提供更准确的深度估算
架构
我们方法的关键理念是将架构引入到学习框架中。也就是说,我们将单目场景当作由移动目标(包括机器人自身在内)组成的 3D 场景,而不是依靠神经网络来直接学习深度。我们将各个运动建模为场景中的独立变换(旋转和平移),然后将其用于为 3D 几何物体建模以及估算所有物体的运动。此外,了解哪些目标可能会移动(例如,汽车、人、自行车等)有助于我们了解这些目标的单独运动矢量(即使它们可能为静态也可以)。通过将场景分解成单个 3D 目标,我们可以更准确地了解场景中的深度和自我运动,在极其动态的场景中尤其如此。
我们在 KITTI 和 Cityscapes 城市驾驶数据集中测试了这种方法,发现其表现优于目前最先进的方法,而且在质量方面接近将立体视频对用作训练监督的方法。重要的是,我们能够正确获取采用与自我运动车辆相同的速度移动的汽车深度。在此之前,这一直是非常具有挑战性的工作。在以下案例中,移动中的车辆以静态形式出现(在单目输入中),并将相同的行为展现为静态视野,进而推断出无限大的深度。虽然立体输入可以解决这种模糊性,但我们的方法首次能够从单目输入中正确推断深度。

之前有关单目输入的研究无法获取移动目标,并会将它们错误地映射至无穷大的值
此外,由于我们的方法会分别处理各个目标,因此算法能够提供每个单独目标的运动矢量,即对目标前进方向的估算:

动态场景的深度结果示例以及对单个目标的运动矢量估算(我们也估算了旋转角度,但为简单起见,并未展示出来)
除了这些成果以外,此项研究还为进一步探究无监督学习方法能够取得哪些成果提供了动力,因为相比于立体或光学雷达传感器,单目输入的成本更低,也更易于部署。如下图所示,在 KITTI 和 Cityscapes 数据集中,监督传感器(无论是立体传感器还是光学雷达传感器)会丢失值,而且有时候可能与摄像机输入存在偏差,这是由延时造成的情况。

中间行是 KITTI 数据集中的单目视频输入深度预测,与光学雷达传感器测得的实际深度相比,后者未能涵盖完整场景,并且会丢失值且存在噪声值。我们未在训练期间使用实际深度
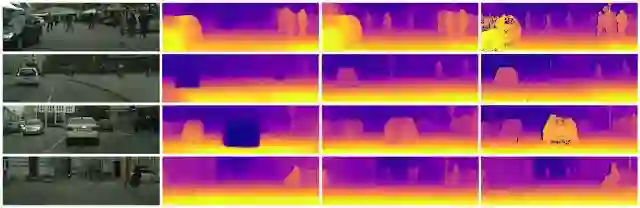
在 Cityscapes 数据集中的深度预测。从左到右依次为:图像、基线、我们的方法和立体传感器提供的实际深度。请注意,立体传感器提供的实际深度有丢失值。另请注意,我们的算法能够在没有实际深度监督的情况下得出这些结果
自我运动
我们的结果还提供极其先进的自我运动估算,这对自主机器人而言至关重要,因为它可以提供在环境中运动的机器人的定位。下面的图片展示了通过我们的方法得出的结果。我们从所推断的自我运动中得出速度和转向角度并将其可视化。虽然深度和自我运动的输出对标量有效,但我们可以看到,它能够在减速和停止时估算出自己的相对速度。
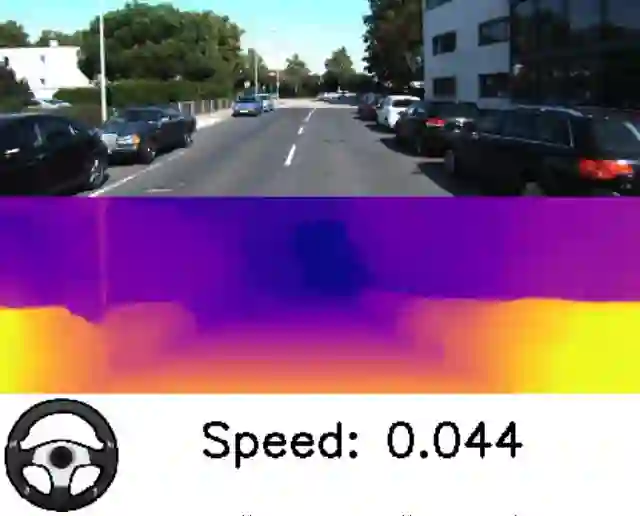
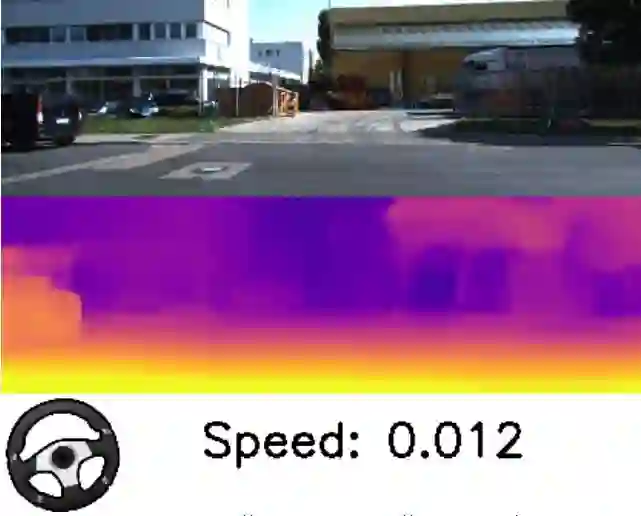
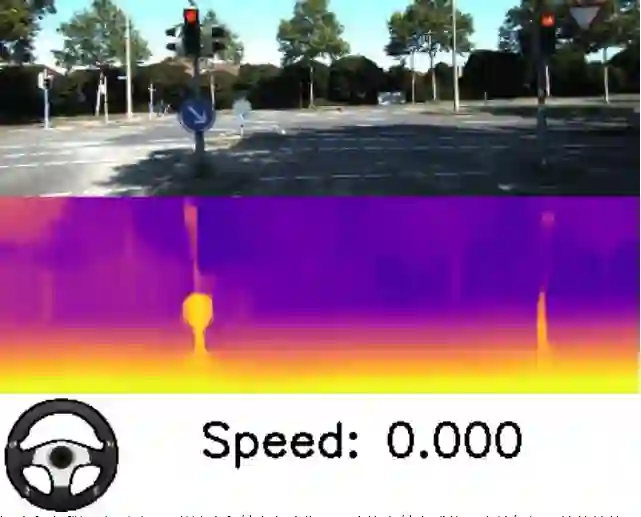
深度和自我运动预测。跟随速度和转向角度指示观察汽车转向或停下来等红灯时的估算值
跨范围转移
在转换至未知环境时的适应性是学习算法的一个重要特征。在此项研究中,我们进一步引入一种在线优化方法,能够在收集新数据的同时继续进行在线学习。下面的示例展示了在 Cityscapes 中进行训练以及在 KITTI 中完成在线优化后,估算深度质量的提升情况。

在 Cityscapes 数据集中训练以及在 KITTI 中测试时的在线优化。这些图像展示了已训练模型和经过在线优化的已训练模型的深度预测。经过在线优化的深度预测更好地勾勒出场景中的目标
我们在明显不同的数据集和环境中进一步测试,即在由 Fetch 机器人收集的室内数据集中进行测试,但在城市户外驾驶 Cityscapes 数据集中进行训练。不出所料,这些数据集之间存在巨大差异。尽管如此,我们发现在线学习技术能够获取比基线更准确的深度估算。
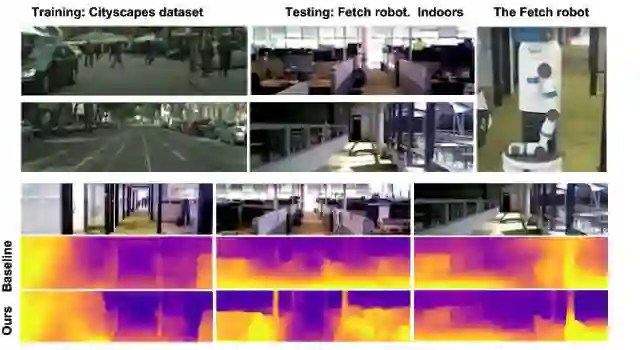
将学习模型从 Cityscapes(从移动汽车中收集的户外数据集)转换至由 Fetch 机器人在室内收集的数据集时的在线适应结果。最下面一行展示了应用在线优化后的提升深度
总而言之,此项研究涉及无监督深度学习和来自单目摄像机的自主运动,而且解决了高动态场景中的问题。它实现了高质量的深度估算和自主运动结果,而且其质量可媲美立体摄像机,还提出在学习过程中整合架构的理念。更值得一提的是,我们提出将无监督深度学习、仅从单目视频中了解自主运动,以及在线适应整合起来,这是一个强大的概念,因为它不仅能够以无监督的方式从简单视频中学习,还可以轻松迁移到其他数据集中。
致谢
此项研究由 Vincent Casser、Soeren Pirk、Reza Mahjourian 和 Anelia Angelova 完成。我们要感谢 Ayzaan Wahid 在数据收集方面的帮助,以及 Martin Wicke 和 Vincent Vanhoucke 的支持与鼓励。
更多 AI 相关阅读:



