苏宁孙鹏飞:苏宁易购大数据在搜索中的应用丨易观A10

近日,2018易观A10大数据应用峰会在北京如期召开,本次峰会以“数造未来 精益成长”为主题。来自国内外的大数据实践者、资本掌舵人、企业家、技术大咖、运营专家、应用开发者以及知名媒体人齐聚一堂,共同讨论和分享在数据驱动下的企业精益成长之道。

苏宁云商IT总部搜索算法团队负责人孙鹏飞
在10月27日下午举行的数据挖掘专场论坛上,苏宁云商IT总部搜索算法团队负责人孙鹏飞做了题为《苏宁易购大数据在搜索中的应用》的演讲。演讲主要分享了搜索数据挖掘应用场景的具体体现。以下为其演讲实录:
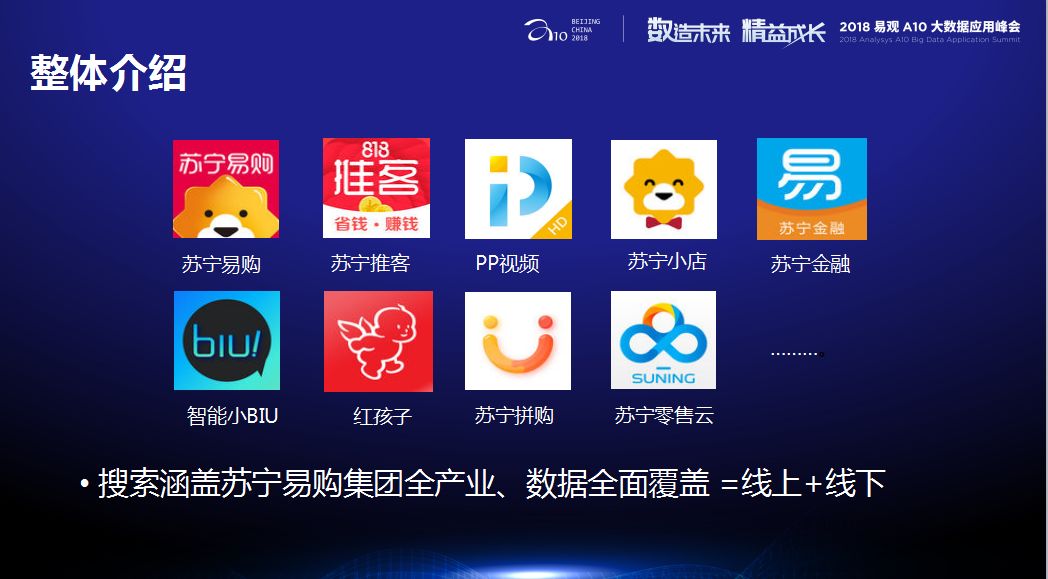
今天分享的主要内容是大数据技术在搜索当中的应用,我们首先来整体看下搜索为哪些产品提供服务?我们这里有苏宁易购、苏宁推客、PP视频、苏宁小店、苏宁金融等,大家可以看到我们的数据已经覆盖到了线上和线下。
我们支撑这么多产品线,是因为采用了三层的体系架构。最左边这部分是我们数据生成模块,中间是数据加工模块,最右边是数据应用。我们可以看到,在数据生成模块,主要由以下几部分组成:Spider爬取的一些数据、商品数据、视频等结构化数据,以及用户行为数据,最后一块是我们的图片库,图片库包括商品的图片信息,还有异构图片信息,我们都会根据不同的用户场景建立不同的管道,为我们不同的业务提供服务。在数据加工层面,针对不同的业务场景去建立不同的业务模型,为我们数据应用提供相应的支持和服务。在数据应用层里面都会把这些包装好,对外提供相应的服务。
搜索数据挖掘应用场景
下面我来介绍一下今天主要分享内容,即数据挖掘应用场景。主要包括架构方面的一些优化、个性化搜索排序,还有Query分析、智能导购、知识图谱等等。
首先我们先来看下架构方面的优化。我们知道搜索引擎都是对检索的商品数据建立倒排,提供检索服务,根据用户query去召回一些商品。但这只能解决80%的问题,20%的热词,召回商品数量非常多,直接影响召回速度,以至于我们后面的级联排序无法正常实现。所以我们这里做了一个小小的尝试,建立一个加权的倒排索引,使我们整体性能得到了提升。我们加权的依据是根据商品的浏览、购买等一些行为数据,预先建模,并通过这个模型算出相应的商品质量分,通过商品质量分干预这些商品在倒排表中出现的位置,做数据截断,加速我们的检索性能。
优化前后对比分析,可以看到整体的响应时间缩短了近乎一倍,性能得到大幅提升。但是有人会问,我们这样做会不会影响召回商品的质量?其实恰恰相反,因为我们是通过模型计算相应的商品质量分,保证在召回的过程当中,把高质量商品召回过来;同时基于截断的数据进行排序提高了排序结果的精准度,进而提升整体服务质量,使得用户体验变得更好。
下面来介绍下搜索的大脑——Query分析系统。它主要是理解和分析用户背后的意图,包括如下几个模块:类目预测、智能纠错、成分识别、知识扩展、品类关系识别,以及品牌关系识别。
在这里我们结合知识图谱,以及关系模型去计算、分析Query的成分,最终识别出相应的品类、品牌及属性,理解用户背后的意图,为精准召回提供服务。
搜索个性化排序。谈到个性化,自然而然会想到千人千面。在电商领域,建立用户画像和商品画像;对于用户画像,基于用户的行为对用户打标签,提取用户的偏好及兴趣标签。在建画像的过程当中,也遇到了一些问题。例如,如何去评价画像的准确度?此外,不同品类下它的购买力偏好是不一致的。比如说,一个用户在手机品类下,他可能比较喜欢iPhone,iPhone在手机里应该属于一个高端品牌,所以他的购买力是一个高端用户;但是他换到家电,换到冰箱洗衣机的时候,他可能是一个中低端的用户,所以这个里面不同品类购买力是不一样。
我们看一下是怎么构建我们的用户画像?以及怎么把用户画像和我们的应用结合起来?我们在做的过程中发现用户画像需要和Query系统结合起来,为引擎去提供服务。在这里有几个好处:Query可以实时分析一个用户的意图,可以根据这个意图对标签进行一个裁减。同时,还可以根据意图,对标签进行加权,这样可以更好地为整个引擎去提供服务,并且可以制定一些排序策略。
下面看看是怎样设计整体架构?首先整体架构是一个三层体系,online、offline、near-line。在offline阶段,利用用户行为数据、商品数据及外部异构数据,建立复杂的模型,获得用户的长期行为偏好;在near-line阶段,对用户行为数据进行相应的实时分析,建立一个准实时的模型,计算用户的短期偏好;在online阶段,结合offline和near-line的模型数据以及query分析和反作弊系统,建精排模型实现个性化排序。
介绍完架构后,再介绍下算法模型体系。这里采用multi-task learning,从下至上依次是:input layer,representation layer,multi-task layer。下面举例介绍下多任务学习,如任务一是CTR任务,在该任务中训练CTR模型,得到表示层的信息。将表示层信息应用于任务二、任务三。此外,任务二里面可以对任务一里面学到的表示层的信息,进行微调,以满足任务二的需求,共享表示层,加快模型的迭代速度。
刚才谈到了个性化排序,有排序存在,就一定会有一些作弊行为,这里面在介绍下反作弊系统,保障排序的公平、公正。下面来看看我们是怎么做的呢?最底层就是数据分析平台,我们会把日志数据、商品数据,还有店铺的数据收集上来之后,进行分析、提取相应的feature,然后在识别引擎里进行作弊识别,最终提供一个相应的服务。
下面介绍一下,最核心的学习引擎,大家知道反作弊问题是一个样本不均衡,作弊的数据比起正常的数据少了很多。所以我们在建模型之初考虑这一点,采用集成学习思想,构建多个弱分类器组成一个强度分类器,综合地去判定是否属于作弊行为,然后进行相应的输出打分。
这几年,随着深度学习和大数据技术的发展,越来越多人将其结合起来,应用于不同的产品上,特别是在智能导购类,智能助手类的应用。我们团队很早的开始尝试这方面的研发工作,2016年底的时候推出了第一版智能导购的产品。经过了几年改造,产品现在比较完善,不仅能支持智能导购,还可以支持售前、售后客服,甚至还支持其他助手类服务。
整体的架构体系如下,首先最上层是处理用户的输入,包括语音和文本,将这些信息输出到我们的路由层;路由层是两部分组成,一个是分析这些数据背后的意图,另一个是提取相应的属性信息,为不同的机器人引擎提供相应的服务;第三层是机器人引擎层,我们现在已经接入了三大类的一个机器人:第一个机器人,任务型的机器人,比方说问天气、订票、财务机器人;第二个机器人,导购型的机器人,比如我想买手机,买便宜型的手机,这种是任务型的机器人;第三个机器人,闲聊型的机器人。
最下面这一层是我们API的服务,以及由语料库组成的知识库等等。
下面详细介绍一下各个模块。先来介绍一下意图识别,我们将意图识别问题抽象成分类问题,在上线之初,利用SVM进行意图分类,它可以解决85%问答的需求,但是还有15%分析不出来,这是由于语义鸿沟造成的。所以我们考虑用深度学习技术去实现它,这里选用CNN的网络,没有选用其他更复杂的网络?因为我们发现CNN从准确率和效率上可以满足我们上线的需求。虽然可以通过复杂的网络把准确率提高一些,但是它的性能就会极具下降,这样用户体验就变得非常差,所以我们从准确率和效率两方面考虑,选择了CNN。在CNN里面我们做了一个小小的改进,就是在输入层融入了符号化向量特征,下面我会详细介绍一下。比如,右边是华为手机完整的知识图谱,可以看到知识的表示。当我们拿到用户的Query信息,我们会结合知识图谱对其进行向量化,一同拼接作为CNN的输入。这样做的好处是通过增加一些feature,使得整个CNN准确率进一步提升;同时,对性能上的损失不大,在上线要求的范围内。
再来介绍一下槽位提取,或者属性提取。这个阶段主要是把属性抽取这个问题转换成一个序列标注问题。这里面我们尝试了用字进行序列标注,还有用词进行序列标注。但是在对比的过程中发现,以词进行序列标注的效果更好一些。我们通过一些案例去分析后,得出一个结论:因为词的语义信息可能更完整一些,在序列标注的时候,就可以获得更好的标注效果。
下面我来介绍一下客服机器人。在客服问答中经常用的一个技术,就是基于检索式的机器人,因为我们已经构建了庞大的问答知识库,95%的问题可以从库中检索出相应的答案。故这里面采用了Deep Match模型,避免语义鸿沟的问题。
最后介绍一下搜索的知识图谱,这几年我们尝试了很多新技术,也沉淀下来去做了很多方面的尝试;现有平台也给我们提供的一些相应服务和技术支撑上,基于此去构建了整个知识图谱。
可以看到,底层是由分布式的存储、分布式的检索、流式计算,以及人工标注的系统,自动标注的系统构成的。上面是知识获取,知识获取之后,会对这些知识进一步提炼,提炼出所需要的一些实体,比方说构建一些三元组,构建一些边的关系等,形成了我们的知识图谱。
知识图谱构建完了之后,我们需要做另外一方面的尝试,就是知识的推理。我们会预先推理出一些东西,存在库里面,为图谱的应用提供服务。比如说会挖掘一些边关系,还有一些知识的理解,一些实体的理解等等,为我们图谱的应用提供相应的服务。
最后是应用层,我们会对所有的产品提供服务,比如刚才介绍的问答系统,结合知识图谱,提高意图识别的精准度。
之后是商品参数的一个纠错。因为买家在上架的新品过程中,经常会遇到属性维护错误,挂错类目等问题,利用知识图谱,建立相应的模型,帮他纠错,并且还可以主动提示这些商家应该维护哪些信息。
最后一块是Query分析,Query分析过程中大部分的数据支撑都来源于知识图谱,知识图谱的好坏直接影响Query分析结果。