深度特征合成:自动化特征工程的运作机制

大数据文摘出品
编译:M.Y.Love、Hope、云舟
将机器学习的方法推广到新问题仍然存在着不小的挑战,其中最严峻的问题之一,就是人工提取特征的复杂性和高时间耗费性,本文就将带你了解自动化特征提取方法。
机器学习算法面临的最大技术障碍就是它们需要通过对数据的处理才能够运作——它们只能利用数值型数据进行预测。数据是由相关变量组成的,一般称为“特征”。如果计算得到的特征不能清晰地揭示预测信息,那么任何参数的调整都无法让模型表现得到提升。对数字特征进行提取的过程,我们称之为“特征工程”。
自动化特征工程能够对必要而繁琐的工作进行自动化处理,从而优化机器学习模型的构建和部署,这样数据科学家就可以更多地关注其他重要步骤。下面我们会介绍深度特征合成(DFS:Deep Feature Synthesis)的基本概念,这个自动化特征工程方法创建的特征能够与数据科学家自己创建的特征媲美。
始于MIT
DFS是2014年麻省理工学院计算机科学与人工智能实验室提出的一个概念。创始人Kalyan Veeramachaneni和Max Kanter利用DFS构建了一台“数据科学机器”,它可以针对复杂的多表格数据集自动构建预测模型。利用这个系统,他们在线上数据竞赛中取得了不错的成绩,在906支队伍中超越了615支人类参赛者组成的队伍。

在2015年IEEE数据科学和高级分析国际会议中,他们在同行评议的论文中分享了自己的研究工作。那个时候这个方法就已经成熟了,不仅给Feature Labs的产品提供了帮助,还推动了包括伯克利和IBM在内的全球科学家的研究工作。
理解深度特征合成
深度特征合成有三个关键概念需要理解:
1、特征源自数据集中数据点之间的关系。DFS擅长针对数据库或日志文件中常见的多表格数据集和交易数据集实施特征工程。之所以专注于这种数据,是因为它是企业中最常见的数据类型:Kaggle上一个对16,000个数据科学家进行的调查表明,对关系型数据集的探索占用了他们65%的工作时间。
2、对于多个数据集,很多特征是采用相似的数学运算得到的。我们采用客户购买记录的数据集来帮助大家理解。对于每个客户,我们可能会关心他们单次购买金额最高的订单。为此,我们将收集与客户相关的所有交易,并找到“购买金额最大值”的字段。对于其他问题,比如飞行航班的数据集,使用最大值提取可以发现“最长航班延误时间”,这有利于我们对将来的航班延误时间进行预测。
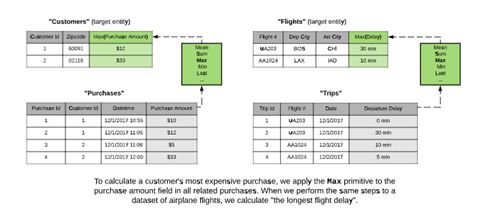
尽管在描述上有所差异,但这两者的数学原理是一样的。在这两种情况下,我们对数值列表采用相同的操作,生成基于特定数据集的新特征,这些与数据集本身无关的操作,我们称之为“基元”。
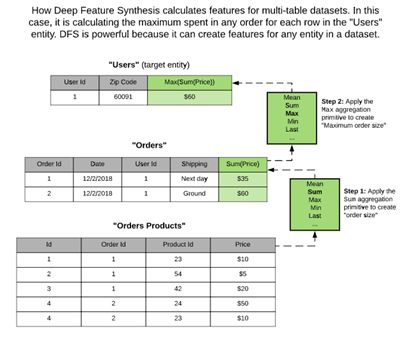
3、新的特征通常由先前获取的特征派生出来。基元是DFS的基石,它定义了输入和输出的类型,把基元组合起来就可以构造与人工创建的特征相媲美的复杂特征。
DFS可以根据关联特性跨实体应用基元,这就是我们能够基于多个表格创建特征的原因。我们可以通设置搜索的最大深度来控制创建特征的复杂度。
数据科学家经常会在交易数据或事件日志中计算“事件发生的平均时间间隔”,这个特征可以帮助我们预测欺诈行为或未来顾客的活跃时间。DFS可以通过组合Time Since和Mean两个基元来完成这个特征的提取。
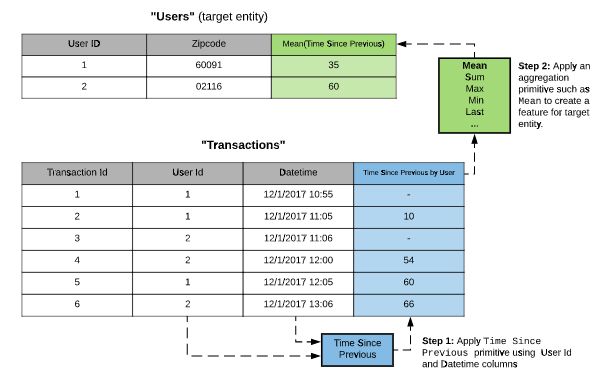
这个例子突出了基元的第二个优点——它们可以用参数化的方法快速枚举很多有意思的特征。不仅可以使用平均值,我们还可以用最大值、最小值、标准差或中位数来对时间间隔进行汇总,从而产生不同的特征。如果我们要向DFS添加一个新的基元——比如两个位置之间的距离——它将自动与现有基元进行组合,这个过程完全不需要额外的人工设置。
持续改进
在2017年9月,我们发布了DFS的开源计划,将项目开放广大资深的数据科学家进行测试。在此之后的三个月里,Featuretools成为了Github上解决特征工程问题最受欢迎的库。
这意味着任何群体的人都可以加入项目并贡献他们的基元,从而使所有用户收益。由于基元是独立于特定数据集定义的,因此只要数据类型相同,添加到Featuretools的任何新基元都可以运用到其他数据集中。有的时候可能是被用在相同领域中,但是也可以运用在完全不同的背景中。比方说,社区中的一个贡献者利用了2个基元来处理自由文本格式的数据。
处理时间
在模型拟合的时候我们有时很容易就会把与预测信息紧密相关的信息泄露到模型中去。之前零售商给客户的应用程序就是一个典型的例子:生产模型与公司的发展完全对不上号。他们希望预测谁会成为未来的客户,但是在模型中最重要的特征是顾客已经打开的邮件数量。在训练中模型的精度非常高,但是在实际应用中却完全不适用。
回头思考一下,理由其实很简单 - 这些潜在客户是在成为客户之后才开始阅读电子邮件的。这个公司在做人工特征工程的时候并没有排除事件发生之后(成为客户之后)才获得的数据。
Featuretools的DFS可以利用“截止时间”为每个特定时间的样本进行特征提取。它会模拟样本在过去时间点的情况,以确保在有效的数据上进行特征工程。这样可以减少标签泄露带来的问题,使数据科学家在使用这些模型的时候更有信心。
用自动化增强人性化
DFS可用于开发无人类介入的基准模型。然而,特征工程的自动化应被视为对人类知识经验的补充 - 它能够使数据科学家更加高效地构建更精确的模型。
对于许多问题,基准分数足以让人们确定方法是否有效。在一个案例中,我们在Kaggle上对1,257名人类竞争者进行了一项实验。我们使用DFS生成特征矩阵,然后使用回归器来创建机器学习模型。
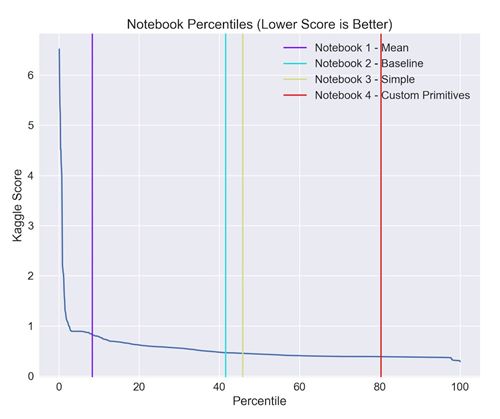
机器学习分数(RSME)与排行榜上的百分位数。随着分数下降,排行榜上的位置上升。彩色垂直线代表使用Featuretools的不同实验方法得到的排行榜位置。
我们发现,在几乎没有人类介入的条件下,DFS能够创建出优于两个基准模型的模型。在实际环境中,这是机器学习能够辅助特征工程的有力证据。进而,我们通过添加自定义基元来超越80%的竞争对手,并获得了接近最佳的得分。
应用深度特征合成
我们最近写了一篇文章,内容是关于使用自动化特征工程来提高全球银行欺诈检测模型的表现,从而提高利润。在这个案例中,我们要预测交易是否属于欺诈,我们根据进行交易客户的历史行为创建了特征。DFS创建了诸如“自上次交易以来的时间间隔”,“交易之间的平均时间间隔”和“使用此卡的最后一个国家/地区”等特征。所有这些特征都参考了各数据点之间的关系,并使用截止时间确保特征构建基于事件发生之前的数据。
得到的结果与银行现有的软件解决方案相比,误报数量下降了54%,从而减少了错误判断不良用户的次数。新的模型预计会为每200万笔交易带来190,000欧元的增收。
深度特征合成vs深度学习
深度学习可以对图像、文本和音频进行特征工程,但是通常需要大量样本进行训练,而DFS则针对公司使用的结构化事务和关系型数据集。
DFS生成的特征对于人类来说更容易解释,因为它们使用的是可以用自然语言轻松描述的基元组合。深度学习中的变换必须通过矩阵乘法来实现,而DFS中的基元可以转换为专业知识能够描述的任何函数。这增加了技术的可访问性,并为没有业务背景的机器学习专业人员提供了更多贡献自己专业知识的机会。
此外,深度学习通常需要大量样本来学习复杂的结构,而DFS则是基于数据集的特点来构建潜在特征的。对于许多企业来说,不一定有足够的样本来做深度学习,DFS则提供了一种能够基于更小的数据集来进行特征工程的方法,而且这些特征更加容易被人类所解释。
特征工程的美好未来
自动化特征工程极大地提高了机器学习的潜力,让数据科学团队能够更加快速地对收集的数据进行分析。有了自动化特征工程之后,数据科学家能够更快速地应对新的问题。更重要的是,数据科学家能够更好地在自己的业务背景中发挥自己的技能优势。
著名的机器学习教授Pedros Domingos曾经说过,“机器学习的圣杯之一是把越来越多的特征工程自动化。”我们由衷地赞同这个观点,能够在这个领域最前沿进行工作和研究的我们,实在是兴奋至极!
相关报道:
https://www.featurelabs.com/blog/deep-feature-synthesis/?from=singlemessage&isappinstalled=0
【今日机器学习概念】
Have a Great Definition
志愿者介绍
后台回复“志愿者”加入我们