干货分享 | 详解特征工程与推荐系统及其实践(附PPT)
云脑科技机器学习训练营11月13日正式开始啦!量子位作为合作媒体独家为大家分享课程干货内容。
本期内容简介
主题:亿级用户电商平台推荐系统挑战
主讲人:张本宇(云脑科技创始人&CEO)

内容要点:
协同过滤 Collaborative Filtering
特征工程 Feature Engineering
推荐系统实战注意点
分享内容实录
首先我们看一下机器学习的五大环节。
一是特征工程。第二是算法定义和调参,就是你该选择什么样的算法,用什么样的参数进行调节。第三是数据采集和清洗,接下来是实现这个算法并进行优化。‘I’代表和业务生产系统集成,所以我们就会简称为FaDAI这五大步骤。特征工程是这五大环节最重要的一部分。

我们会简单介绍一下特征工程,以及一些常见的特征工程的方法。
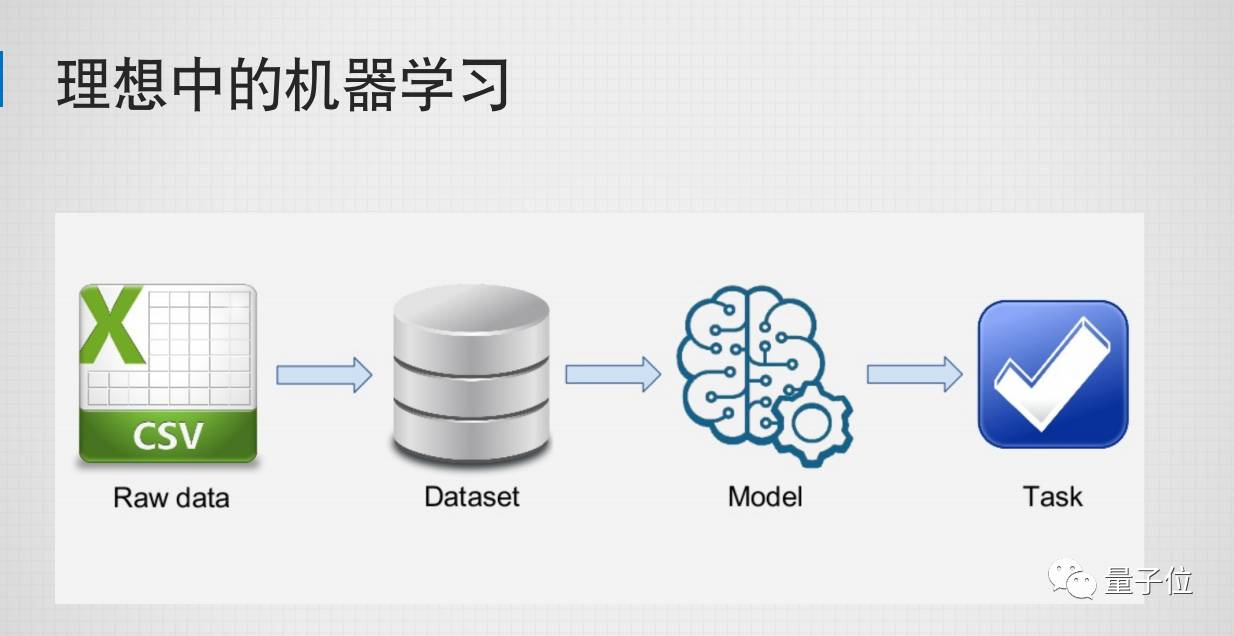
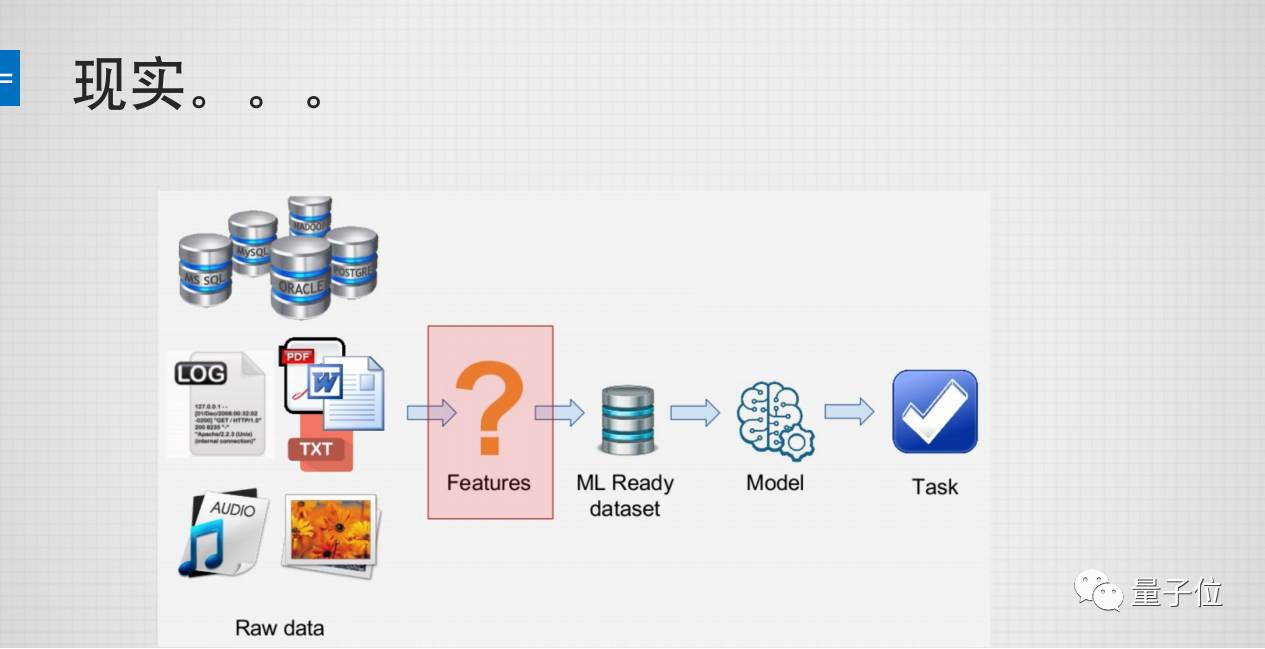
引用一下吴恩达的话:“应用机器学习其实就是在做特征工程,特征工程是非常难、耗时、也是需要专业知识的一个工作。”我们理想中机器学习的情况:有很干净的Raw data,然后变成可学习的Dataset, 通过某些算法学出某些模型,然后解决一个问题,这是最理想的一个状态。但现实中,我们会有各种各样的数据,有的从数据库来,有的从日志来,有的从半结构结构化文档来,有的从无结构的音频、图片中来。从中抽取什么特征,才能够被我们机器学习所使用,从而能学习出模型解决出问题呢?
接下来我们看一下针对变量类型的特征,这里实际上有几大类的变量类型。有分类型的特征变量,也有数值型的特征,还有两个比较特殊的是时间和空间,接下来我们也会一一介绍。
对于离散型的特征枚举一些例子:你的操作系统是什么类型?有可能是桌面,有可能是平板,有可能是手机。那你的user_id是什么?有121545,或者别的一些id。 这种类型的特征是最需要特征工程的,因为它的取值空间非常巨大,经常会导致稀疏数据。所以说从效率和精度上来说,都是对模型一个巨大的挑战。
那最简单的一个特征工程,叫做One-Hot encoding。举例来说,platform这个维度有三个取值:desktop、mobile、tablet。 那我们可以转换成三个特征,如果平台是在desktop上,那这个特征就取1,如果在mobile上,那这个特征就取1,如果在tablet上,那这个特征就取1,这是一个非常稀疏的结构。举例来说,如果有十万个站点,那就十万维,这是十万维只有这一个维度上取1,其他都取0。

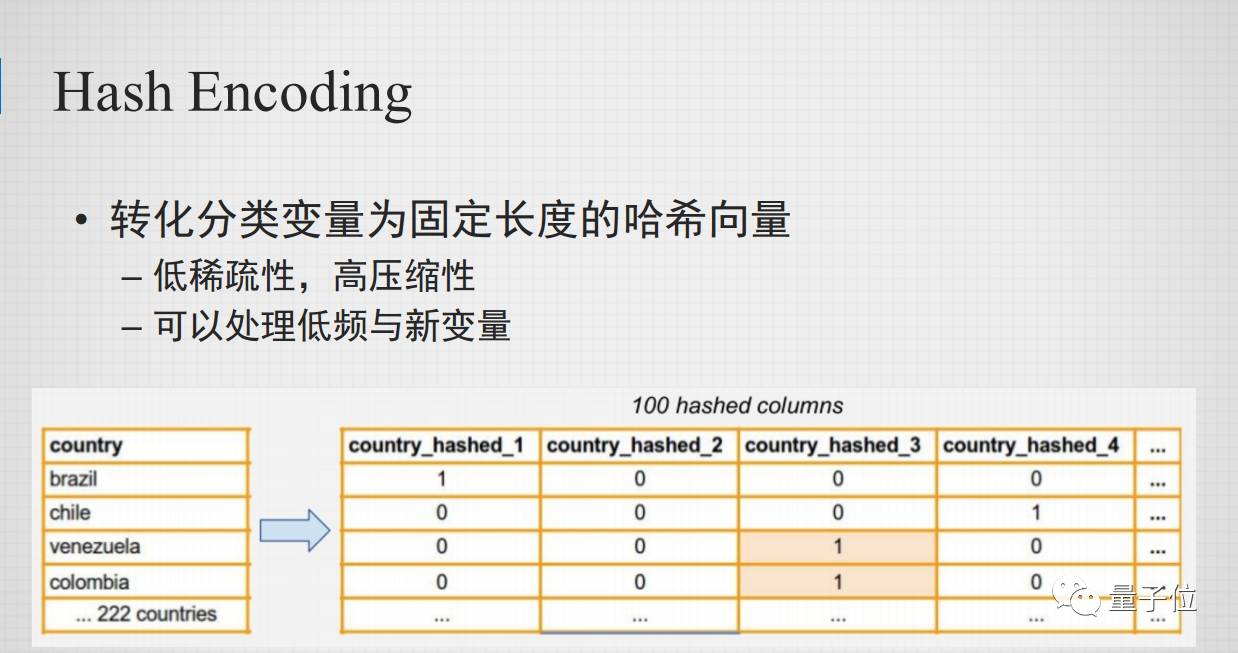
一种比较常见的方法就是做Hash Encoding。举例来说:有200多个国家,用Hash的方法把它转化为100多列,但用刚才One-Hot的方法就有200多列,但用Hash方式表达,参数是可调的,所以它可以缩成100、50,甚至10。那它会有一定的代价,比如说巴西和智利被放在一列,但是这两个国家可能有不同的特性,但他们必须share同样的位置。这是它们潜在的一个问题,但稀疏性是可以控制的,也可以处理低频和一些新的变量。这里隐含的条件是有一个假设,这个假设是有些特征可以share同一个位置。这个假设在深度学习中也会有使用。所以在实践中发现很多时候并不会影响实际的结果,只要你的参数空间相对是足够的,就是它有足够的表达能力。这个也是相对比较常见的一个方法 像有些比较知名、开源的机器学习的工具都有这样的一个功能。
另外一个是计数型的Encoding,就是把它变成全局的count。比如广告id:423654,他看了多少次,点击了多少次,直接把它转化成一个统计量,可以是观看的次数,点击的次数,广告的CTR。就是用不同的id,每个id有不同的权重,变成浮点数上的一个特征,共享一个权重。这里有一个假设,它跟全局统计有某种线性关系,或者在某个转化空间之后有线性关系。
还有一个是我们关心的异常值对整个统计的影响,那我们可能就从绝对值改为一个相对值,相对值就是它排序的一个次序,比如说按CTR排序,最好的CTR有什么特征。
最后是在神经网络中常见的做法,就是把分类变量转换为嵌入式变量,做Embedding。比如说你有十万个不同sites,把它投影到64维或者128维的vector上面,相当于原来需要十万个Free parameters,现在只需要64维或128维。之所以能这样做,原来的十万维空间是非常稀疏的,64维或者128维是更稠密的表达,所以还是有非常强的表达意义,好处就是内存需求会更少,相对来说精度也会更高。
有同学问Hash和Embedding的区别,Embedding本身是需要学习出来的,比如说id1它投影到怎样的Embedding空间,通过学习来获得。而哈希是通过预定义的哈希函数,直接投影过去,本身的哈希函数是不需要学习的。这里它最基础的逻辑是不一样的,Hash Encoding也就是说你这两维特征可以share相同的weight。比如说巴西和智利放在同一列中,他们有相同的权重,而Embedding实际上是一种distributional的表达方式。它的意思是说巴西可能使用64维上不同取值来代表,智利也是同样用这64维,所以这64维,每一列都参与表达不同的国家,每一个国家都由这64维来表达。它们两个的基本思路上是有所区别的。
我们现在进入到数值变量,数值变量主要有两种,一种是浮点数和一种是定点数,定点数也就是整数。很多时候数值变量也可以当成模型的直接输入来使用。但是基本上也都需要一定的特征工程,因为实践中它的取值范围会很分散,实际上对模型的影响也比较大。
首先我们看一下缺失数据,缺失数据一种最简单的做法是转化为空白,或者NaN,但实际上空白都会当成0来处理,这其实不是一种最好的表达。这时候其实更好的是使用平均值、中位值,或者模值,或者由其他模型来生成一些值。但常见来说平均值和中位值就足够好了。那第二种情况可能会做一些rounding,就是忽略掉一些小数位上的变化,因为有时候小数位过高会是一种噪音。他本身的观测实际上没有这么高的精度,所以很多时候精度是一些更低阶的噪音带来的。或说我们希望他在某些特征上有一定的鲁棒性。比如说这个例子,它在乘10取整后,实际上某种程度上可以当成分类、离散型的变量,比如说12345678910,当然它变成分类变量之后,实际上是产生了一个约束,10一定比9好,9一定比8好,它有个排序的次序和关系。所以这就是要看实际工作中,这样一个约束是否成立。
然后还有一种情况是对取整的进一步拓展,二次化,0和1,超过0的就是1,因为很多时候我们需要关注它定性上的一些特性。再做一些扩展就是做Binning,就是做分块,离散化,切到若干个bin里面去,这个bin是等宽的,1到2,2到3,3到4 ,取值落到这里面的个数是多少。另外还有一种分法是落入某个桶的分法平均,尽量的平均,这样横轴就是平均的。
还有的时候取值的范围跨度太大或太小,这时候就采用某种非线性的变化,比如说log的transformation,让它在两个有extreme的value range上相对来说更smooth一些,更有区分力。这也是非线性的一种常用手段。虽然它非常简单,但实际上的效果是不错的。List还有取平方或者开方。
最后一种是对数组做一定的normalization,有两种方法:一种是minmax找到最小值最大值,把他们normalize到0到1之间,还有一种是做一个比较标准的正态化,就是减去mean 再除以var,但要对数据的分布有个基本的了解。这里有另一种方法,是对数值向量做归一化,这也是为了防止数值上面一些outlier的点,主要还是为了数值上的稳定性。
这里是一种特征生成的方法,比如说原始特征是X1,X2,通过两两交互能够生成新的特征,也带来一定的非线性。后面要讲的推荐系统FFM本质上就是使用这样的方法。
接下来是时间变量,本质上是一种连续值,但是实际上有一些特殊的处理,有时会忽略掉一些奇怪的问题,要注意一下。首先要注意一下时区的问题,是应该用local的时间还是同一时区,要根据具体问题来定,还有夏令时的问题。具体要根据场景来定。时间是连续值,很多时候也要进行分段,有时候会有一定语义的分法,比如早上,中午,晚上这样的切分。实际上对切分本身来说也可以做成有重叠的, 比如说5点到9点是early morning,8点到11点是morning,这样8点到9点就同时属于两个bin,这也是可以的。第二个就是对它的某些时间趋势做一个特征,就是它所消耗的时间,上周所消耗的时间,或者是相对消耗时间上的一个变化。
还有一些场景下我们关注一些特殊的时间,比如说节假日、双十一。举例来说这些做用电量的预测,那么春节可能是一个非常强的特征。春节大城市的用电量会急剧下降,世界杯前、发工资又要做一些特殊的推荐可能是实践中需要考虑的东西。时间间隔:比如说上一次点击广告的时间,两次点击的间隔,因为会假设用户的兴趣会随着时间变量发生变化。
和时间相对应的是空间上的变量,有可能是GPS坐标,也有可能是语义上的地址、邮编、城市、省,或是与特定位置的距离。很多时候地点是连续的特征流,每一秒可能都有GPS 的坐标,他可能需要进行异常的监测,因为GPS并不是那么的精准可靠。也可以基于外部资源强增地点信息:包括这个区域的人口情况、收入情况等。
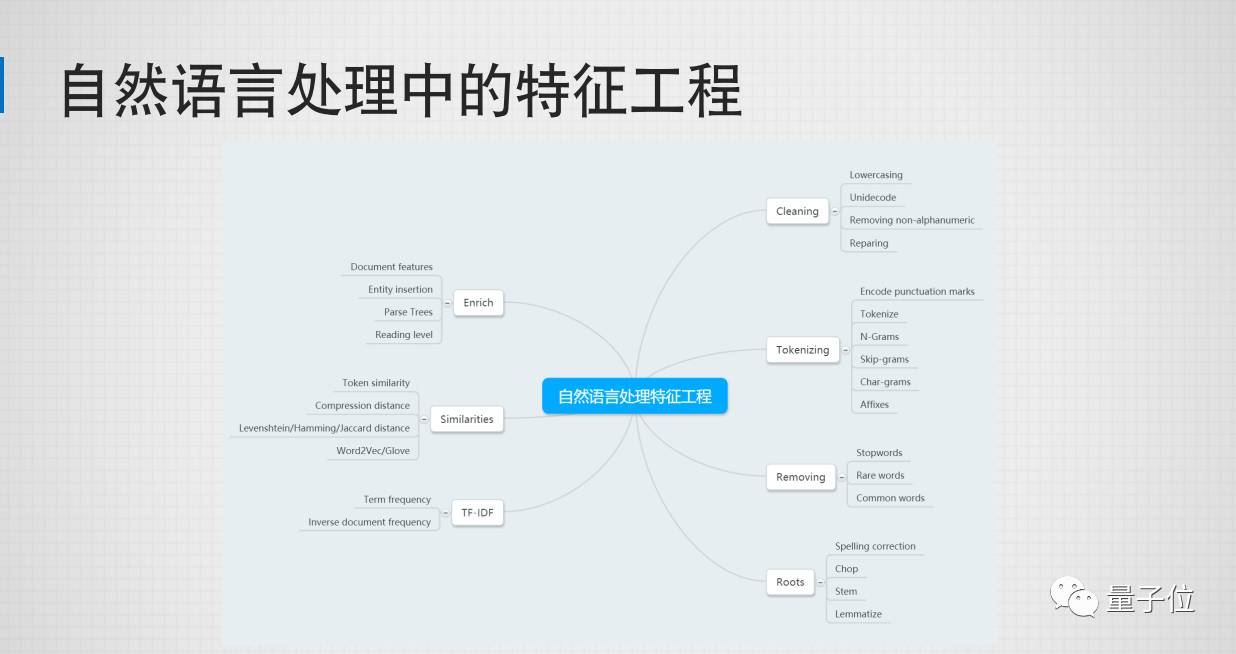
接下来我们看一下自然语言处理的特征工程。文本本质上也是一种分类变量,所以他会有一些传统的做法,比如说:Bag of words ,TF-IDF,也有比较新的Embedding 或Topic models。
Bag of words是One-Hot encoding的一种表达,TF-IDF是对Bag of words的一种简单改进,它feature取值不仅仅取决于出现或不出现,它希望在这个feature的取值上能够反映这个单词对语义的相对重要性。Term Frequency 代表着一个词如果在文档中出现的次数越多,它可能的重要性越高。另外一方面,如果这个词在出现的文章个数越少,说明这个词更有区分性或者越具有代表性。 所以TF代表的是Term Frequency,IDF是words出现在document 的Frequency,两者相乘是信息检索领域对特征取值进行re-weighting的一种常见的方法。

有了两个文档的TF-IDF向量之后,就可以定义这个向量的相似性,可以用Cosine来定义,Cosine可以理解为一个normalize的内积,把两个特征进行L2的正则,它们之间的关系就是内积,或者说是两个向量之间的夹角。
Textual Similarity 是简单的进行一些定量的计算,比如说从一个文本转换成另一个文本难易程度的一个计算。Word2vec实际上是Embedding的一种方法,需要定义某种损失函数来学习,最终是哪种损失函数满足最终我们所期望的损失函数。Topic models本质上是进行某种矩阵的分解,目的是在高维的空间上进行低维的表达,能够更完整的刻画数据,这个在推荐系统上也会用到。
推荐系统是一种非常广泛的机器学习的领域,和广告系统密切相关。区别是业务上的逻辑,本质上算法可以互相借鉴。
协同过滤本质是用别的用户来为这个用户进行推荐和过滤,假设A和B在都看过的item非常相似,那么A和B可能会share相似的list. 比如某些items 只有B看过,那么A很可能和B会有相同的喜好。Item可能是广告、电影、音乐等等。
举例来说绿代表喜欢,红色代表不喜欢,我们要看一下该用户对电视机的喜好程度,什么样的用户和他会比较像?我们会注意到第二个和第三个用户,我们会借鉴第二、三个用户的喜好来猜测它在电视机上的喜好,也意味着它喜欢第三个物品。
协同过滤分为三个步骤:1用户需要对某个物品表现出他的喜好性。2.用算法去找到和他比较相似的用户。3.基于用户做一个推荐。
这是基于user的推荐,接下来还会举例基于item的推荐。
首先他需要确定一个度量方法,可以度量user之间的相似性,也可以度量item之间的相似性。假定这样一个item都是使用一个特征向量的表达,那么它的相似性可以通过欧氏距离或皮尔逊相关系数来度量。欧氏距离实际上是最简单的一种度量方式,但很多时候也是非常好用的方法。
假设两个向量是n维空间的两个点,那么这两个点的距离就是欧氏距离。距离我们需要转化为相似性,有时候越小越好,有时候越大越好。所以我们会用图中的一个变化。本质上是把无穷区间投影到0,1区间。皮尔逊系数本质上也是刻画两者之间的相似性。Cosine 也是基于内积的一个变化,如果在一个超球面上,它和欧氏距离有简单的对应关系。有了这样一个距离之后,我们可以找相似的label,有两种找法:1.找最近的K个邻居。2.找相似性小于或大于某种程度的一些邻居。这两种方法在实践中都有使用。
Item-item Filtering:现在有用户ABC和物品ABC, 我们考虑是否要把物品C推荐给用户C。我们看物品C和哪一个物品经常一起出现,发现是物品A。用户C被推荐了物品A,因此把物品C推荐给他。User-item Filtering 考虑对用户A进行推荐,先找到和A相似的可能是用户C,看用户C有说明额外的物品是用户A不知道的,物品D是用户A不知道的,那么D就会推荐给A。这两个可能是不同的维度,用哪种方法更好,也要看数据具体的特征来定。


无论是哪种方法都会有一些缺点:1.复杂度是O(n^2)的,会随着用户数和物品数增高。无论是用Item-item Filtering还是User-item Filtering,本身feature vector的维度就很高,用来计算相似度或差异度的开销就会更大,会有一个O(n)的增长。找相似的 item的做法有O(n)的复杂度;2.如何对新的用户进行推荐。
因式分解机试图来解决带来的一些问题,这个工作是10年Steffen提出的,他从另外一个角度来增强模型,同时也取得了很好的效果。他关注点在特征间的协同作用,比如说将两两特征组合起来。举一个广告的例子,他关心的是用户是否有点击这个广告(1或者0),展示了用户的一些特征,国家、点击的时间、还有广告的类型,这是一个简化的数据集,使用One-Hot encoding。
最简单的方法是把所有特征进行One-Hot 表达,也不对日期等别的特征进行哈希等别的方法的处理。把这样一个矩阵放回到推荐的系统中,比如用户和电影的推荐,每行代表用户和电影的关系,用户和电影都进行了One-Hot 表达,时间做了一个normalization,y是好与不好。推荐系统除了协同过滤,另一种方法是把它当成回归问题,那回归问题X就是这些特征,y就是rating,最简单的一个模型就是线性回归。线性回归实际上是赋予每个特征一个权重,然后相加,再加一个先验。然后就得到一个预测值,我们希望预测值尽可能的接近真实的y。
当只使用原始特征时可能表达能力不够强。比如说在USA且今天是Thanksgiving,这是一个非常重要的信息,我们可能需要对这样的特征进行组合然后构造新的特征。但这些组合空间可能会非常巨大,组合数是n方的关系。比如有200个国家,30个节日,再结合其他特征如站点,相乘就会非常巨大。我们仔细观察特征组它们之间可能不是相互独立的,有一些可以share的参数,这些share的参数是一些非常重要的概念,在Hash Encoding、CNN、RNN上都会用到。比如说美国和Thanksgiving的组合,它与中国和中国的新年的组合非常有关联,所以它们俩之间可以用相同的latent factors进行刻画。
找 latent factor传统的技术是做矩阵因式分解,比如说我们有非常大的矩阵是nm的,我们通过找到两个nk和km的矩阵相乘可以重构出这样一个nm的矩阵,就是SVD或者LSI,可能有不同的名词但是有相同的做法。所以这个想法就被延展到了FFM上面,这里最关键的想法是把wij定义成vi 乘以vj的内积,vi是k维上的一个元素,这样的一个好处是把O(n^2)的复杂度降到O(n)的复杂度。所以wij就不是任意的一个参数,它是受限制的一个参数。所以FM可以被表达成下面这样一个式子,它不在是O(n^2)的复杂度,而是O(nk)这样一个问题,k是一个可选的参数,不会随着数据量或特征的增长而变化。计算量看起来更大了,但实际上有很多计算是重复的,通过简单的变化可以变成O(nk)的复杂度。

相关学习资源
以上就是此次课程的相关内容,在量子位微信公众号对话界面回复“171118”,可获得完整版PPT。
— 完 —
加入社群
量子位AI社群11群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot4入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot4,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态




