迁移学习前沿探究探讨:低资源、领域泛化与安全迁移
大数据文摘转载自AI科技评论
作者:王晋东
整理:维克多
迁移学习是机器学习的一个重要研究分支,侧重于将已经学习过的知识迁移应用于新的问题中,以增强解决新问题的能力、提高解决新问题的速度。
4月8日,在AI TIME青年科学家——AI 2000学者专场论坛上,微软亚洲研究院研究员王晋东做了《迁移学习前沿探究探讨:低资源、领域泛化与安全迁移》的报告,他提到,目前迁移学习虽然在领域自适应方向有大量研究,相对比较成熟。但低资源学习、安全迁移以及领域泛化还有很多待解决的问题。
针对这三方面的工作,王晋东提供了三个简单的、新的扩展思路,以下是演讲全文,AI科技评论做了不改变原意的整理。
今天介绍迁移学习三个方向的工作:低资源、领域泛化与安全迁移。迁移学习英文名称:Transfer learning,基本范式是通过微调“重用”预训练模型。纵观机器学习的绝大多数应用,都会采用这种预训练+微调的范式,节省成本。
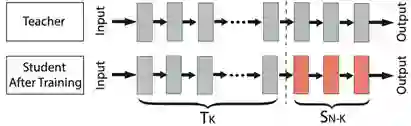
上图迁移学习范式示例,在Teacher网络模型中,经过输入、输出一整套流程训练,已经获得比较好的性能。Student模型想要训练,则可以固定或者借用Teacher网络的Tk层,然后单独根据任务微调模型,如此可以获得更好的性能。
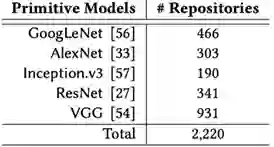
目前,在CV领域,已经存在ResNet;在NLP领域已经有BERT、RoBERT等模型可供使用。如上图,2016年GitHub上有个统计,关于迁移学习的Repository总计有2220个,当前可能会更多。

上图展示了,过去五年,迁移学习领域在顶级会议上取得的进展。最早是吴恩达在NIPS16上表示迁移学习在未来非常重要;然后,CVPR2018上有一篇最佳论文是关于迁移学习的;同年,IJCAI18上,有团队用迁移学习的手法赢得ADs竞赛;2019年,ACL会议上,有学者强调迁移学习的范式在NLP领域非常重要,一年后,一篇迁移学习论文拿到了该会议的最佳论文提名。
一直到去年,深度学习三巨头表示,现实的世界中,数据分布不稳定,有必要开发快速适应小数据集变化的迁移模型。
事实上,随着我们认知越来越多,会逐渐认识到迁移学习有很多问题待解决,需要不断开发新的方法。
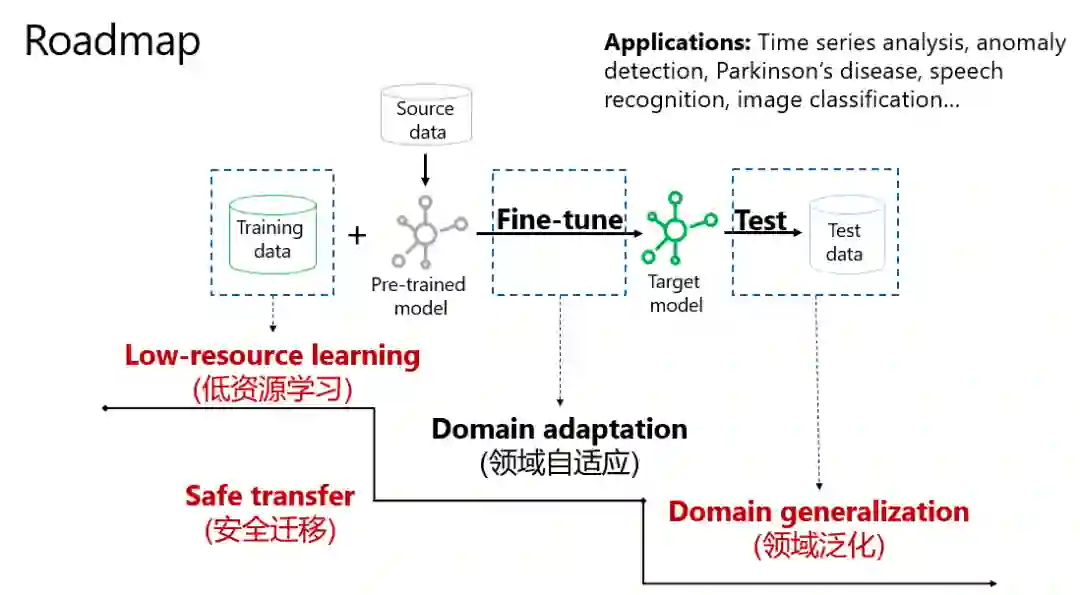
在移学习范式中,如果训练数据和预训练模型刚好匹配,则能开发出性能优越的应用;如果有较大差异,则可以借助“外援数据”进行修正,然后获得目标模型,进而在测试(未知)数据上获得较好表现。
从训练数据到测试数据,整套流程中,其实存在很多问题,例如:
低资源学习,即如何在小数据情况下,如何设置迁移模型;
领域自适应,即如何解决当训练集和测试集的数据分布存在偏差;
领域泛化,如何从若干个具有不同数据分布的数据集(领域)中学习一个泛化能力强的模型;
同时,整个过程还需要时刻注重安全迁移,确保隐私不泄露,模型不“中毒”等等。
目前,领域自适应方面已经有大量研究成果、该领域相对较成熟。但低资源学习、安全迁移以及领域泛化等方面还有很多待解决的问题。
低资源学习
低资源学习的本质是,依赖少量的有标签的样本去学习泛化能力强的模型,期望其在未知的数据上表现良好。但问题在于,在各种场景下如何确保小数据中的标签仍然含有知识、且这些知识能被迁移到大量的无标签数据上。
经典的工作来自于NeurIPS 2020,当时谷歌在论文中提出FixMatch算法,通过一致性正则和基于阈值的置信度来简化半监督学习,设置固定阈值调整迁移学习的知识。
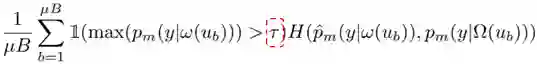
公式如上,模型学习的置信度要根据阈值来判定,如果大于一定的域值,就使用这些数据进行训练和预测;否则这些数据则不参与下次训练。
那么,对于半监督学习而言,预训练模型仅考虑阈值就足够了吗?谷歌在论文中,将阈值设置为0.95,显然这个数字是由谷歌的实验得出,其实我们在真实世界中,永远无法得知的取值是多少。
基于此,需要学习一个更真实的阈值,也即开发一种自适应学习,让模型根据数据灵活决定值。为了验证这一想法,我们先回答“选择固定阈值还是灵活阈值”。
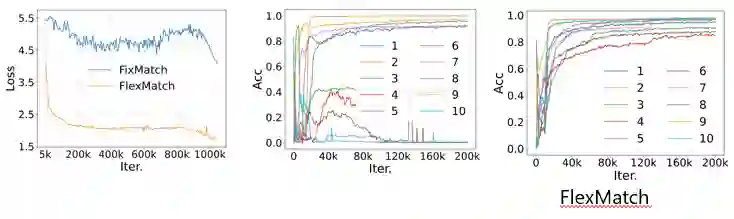
如上图(左)所示,固定阈值的Loss下降的特别慢。同时,通过对比两种选择的ACC指标也能证明,如上图(中),对于不同的类别,需要设置不同的阈值。
在“动态调整”的思想下,我们在NeurIPS 2021上提出FlexMatch算法,有以下几个特点:
对于不同的类别,能进行不同程度的阈值自适应;
对于不同的样本,设置不同阈值;
测试阶段,需要对阈值“一视同仁”
全程无人工干扰,全自动学习阈值
实验结果表明,如上图(右)所示,在同样的数据集上,该方法呈现正向曲线,效果比较稳定。FlexMatch的设计思想借用了“课程学习”,半监督学习常用给不确定样本打伪标签的策略,伪标签的学习应该是循序渐进的迁移的过程,即由易到难的过程,然后类别的学习也是由易到难的过程。同时,FlexMatch采取了聚类假设:类别和阈值息息相关。
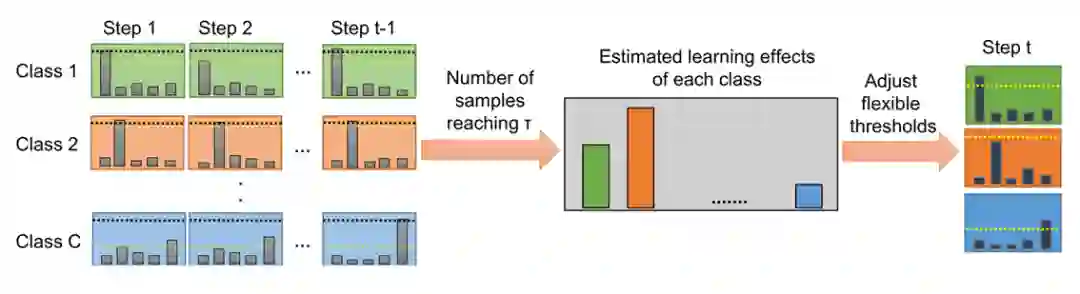
以上是该思想的流程图,和FixMatch大同小异,不同之处是强调在不同类别上,会预估学习难度,然后自适应调整阈值。
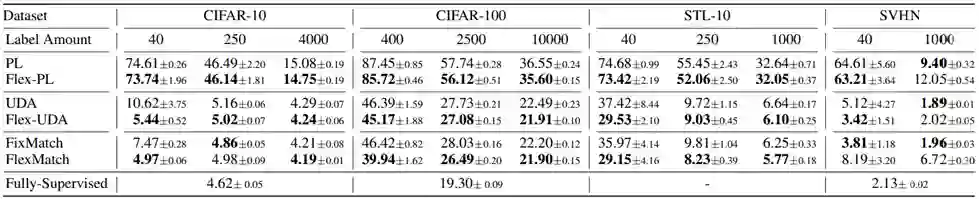
以上是在CIFAR10/100、SVHN、STL-10和ImageNet等常用数据集上进行了实验,对比了包括FixMatch、UDA、ReMixmatch等最新最强的SSL算法。实验结果如上表所示,可以发现FlexMatch在标签有限的情况下能显著改进。在未引入新的超参数、无额外计算的情况下,对于复杂任务,也有显著改进,且收敛速度显著提升。
值得一提的是,针对该领域,我们开源了一个半监督算法库TorchSSL,目前已支持算法有:Pi-Model,MeanTeacher,Pseudo-Label,VAT,MixMatch,UDA,ReMixMatch,FixMatch。
低资源应用
现实世界中存在大量语言,但有很少的标注数据,世界上有7000种语言,常用的语言也就那么几十种,剩下绝大大多数都是低资源的语言。需要对小数据进行模型训练,同时能够避免模型过拟合。所以,针对低资源语言的自动语音识别(ASR)仍然是端到端(E2E)模型的一个挑战。
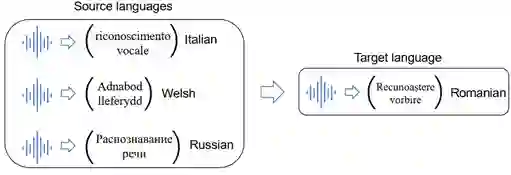
迁移学习的解决方案是,对资源丰富的语言进行预训练,对资源低的语言进行微调,对资源丰富的语言和资源低的语言进行多任务学习,同时对资源丰富的语言进行元学习,以快速适应资源不足的语言。
具体而言,要发现语言之间的联系,例如上图表明,不同的语言、不同的语系之间会有相似、相关性。这些语言具体怎么分布,有哪些相似性?我们的目标是如何自适应学习这种关系。
当前主要有两种方法:隐式、显式。其中,隐式是指不对他们的关系做任何假设,通过网络直接学习;显式是指假设语言之间存在线性关系,简化算法。
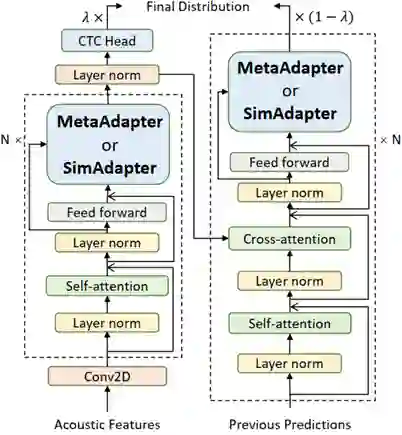
基于上述两点,我们就设计了两个简单的算法MetaAdapter和SimAdapter。前者能够直接学习不同语言之间的关系;后者假设语言之间是线性关系,用注意力机制进行学习。同时,结合MetaAdapter和SimAdapter,我们设计了SimAdapter+,能达到更好的效果。具体模型结构如下所示,只用微调数据里面的参数,就可以去完成网络的训练。
领域泛化
领域泛化的目的是利用多个训练分布来学习未知领域的通用模型。存在数据属性随时间动态变化,导致动态分布变化等问题。因此,需要捕捉数据的动态分布变化,例如如何量化时间序列中的数据分布。
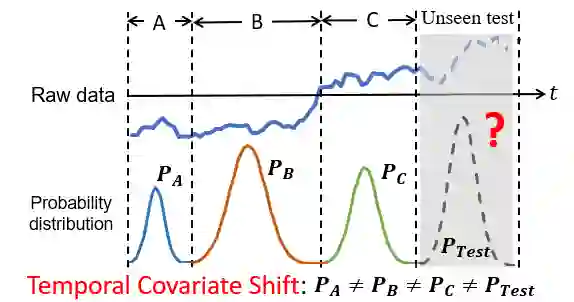
针对上述挑战,我们提出AdaRNN。首先将时间序列中分布动态改变的现象定义为时序分布漂移 (Temporal Covariate Shift, TCS)问题,如上图所示将一段时间的数据分为A、B、C以及未知数据,可以看出A、B之间,B、C之间以及A、C之间的数据分布相差比较大,如何解决?分两步走:先来学习数据最坏情况下的分布,然后匹配最坏分布的差距。
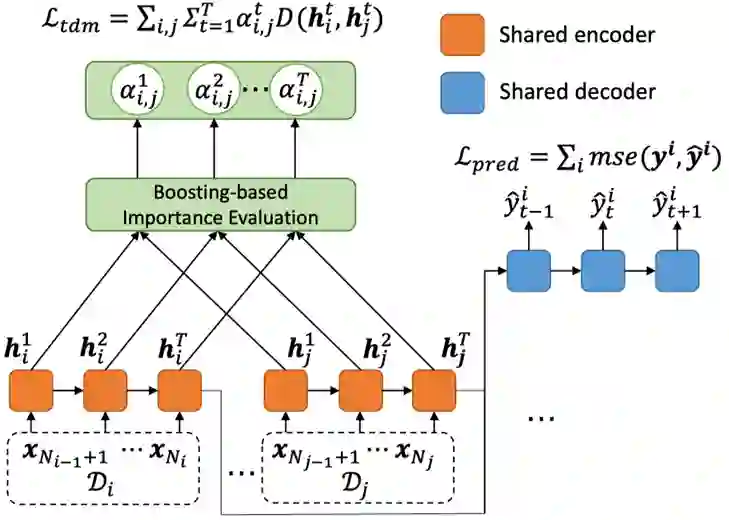
具体而言,采用聚类方法优化问题,然后用贪心算法求解序列分布,将数据分成几段;最后,设计领域泛化进行匹配分布。
我们在四个真实数据集上测试了算法的效果,包括1个分类任务(行为识别)和3个回归任务(空气质量预测、用电量预测和股价预测)。实验结果表明,模型性能有一定的提升。此外,我们发现不仅在RNN上,Adaptive方法对于Transformer结构也一样有效。
安全迁移
安全迁移体现在迁移学习的各个方面,例如如何确保迁移学习模型不会被滥用?如何在保证效果的同时降低迁移模型的复杂性?如何进行安全的迁移学习、避免模型受到恶意攻击而对用户造成影响?
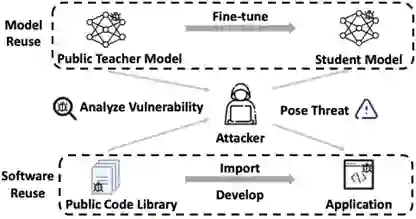
举个例子,在软件工程领域,如果软件有恶意BUG,一旦你在开源社区下载该软件,不仅会继承该软件好的功能,也会继承它的容易受攻击的弱点。另外,如果黑客知道用户的软件使用了哪段开源代码,便可以对你的应用软件发动相应攻击。
我们统计了一下,在Teacher到student的微调范式中,Student可以从Teacher中继承那些易受攻击的弱点的概率为50%~90%。换句话说,最坏的情况是Teacher怎么被攻击,Student便可以被攻击。因为Teacher的模型是公开的。
因此,安全迁移研究的目的是如何减少预训练模型被攻击的情况,同时还能维护性能。这其中会解决未知攻击、DNN模型缺乏可解释性等难题。

我们考虑两种攻击:对抗攻击,例如熊猫图片中加入某些噪声,AI会将其识别成长臂猿;后门攻击,神经网络结构本身就存在一些可能被利用的东西,例如输入数字7,然后输出数字8。
针对安全迁移问题,我们提出ReMoS算法,主要思想是:找出网络有用权重,剔除无用权重。第一步:需要计算神经元;第二步:评估Teacher模型对Student模型的重要性,计算两者之差;根据以上两步,就可以轻松裁减不需要的权重。
实验结果发现,ReMoS方法几乎不会显著增加计算量,其收敛速度与微调模型基本一致,显著好于从头开始训练。
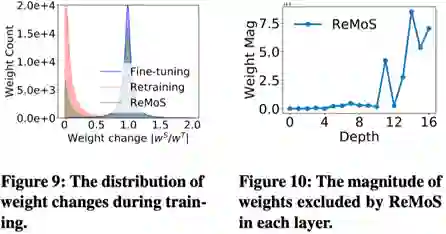
上图(右)画出了剪枝之后的权重和网络层的关系。此结果说明随着网络层数据的加深,网络越来越与学生任务相关,因此,在深层的权重大部分被重新初始化了。这一发现也符合深度网络可迁移性的结论。
总结一下,今天主要介绍了三方面,低资源学习、领域泛化以及安全迁移。我为这三个方面提供了三个简单的、新的扩展思路。希望接下来的研究者能够设计出更好的框架,新的理论,然后在迁移学习的安全性方面去做一些探索。