【机器学习】想要预测未来,机器学习有种“神秘力量”

数据科学实际上涵盖了许多学科,包括统计推断、分析学、可视化、分类与预测。通常情况下,大家最感兴趣的当属预测。
一提到预测未来,无论是发掘产品的潜在客户还是预知股价的后期走向,这些听起来都非常神奇。如果能够准确地预知未来,那我们就掌握了一项非凡的技能。
机器学习在预测未来这一“神秘力量”的发展中发挥了很大的作用。随着预测模型的复杂性不断提高(可解释性也随之降低),它们将能够发现先前未发现的相互关系,并且充分利用之前无法使用的数据资料。
但是就其本质而言,预测其实是非常简单的。本文将介绍一种关于预测的心智模型,该模型的学习或许能够帮你解开心中对于预测的迷惑,并且将预测加入到自己的定量工具箱中进行进一步学习。
利用线性回归进行预测
在学习统计学时,最早接触的模型之一就是线性回归。线性回归分析不仅功能强大,而且易于理解。因此在预测时,它也是一个非常好的辅助手段。
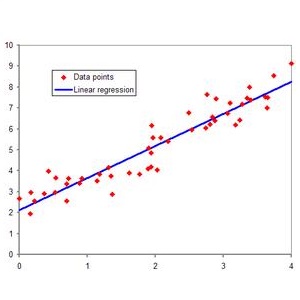
用通俗易懂的语言来说,线性回归就是要找到一条最适合的线,并且这条线要穿过尽可能多的数据点。描绘这条线就能够发现数据的趋势和走向。在以下这幅图中,标蓝的线就是最优拟合线。接下来,让我们进一步分析一下这幅图。
1. 图中每个点都代表一个观测值。每个观测值的纵坐标表示的是因变量(也就是要预测的对象)的值,而横坐标代表的则是自变量的值。
2. 从图中可以看出,自变量和因变量之间存在很明显的正相关线性关系(注意观察这些点向上和向右的分布趋势)。
3. 最优拟合线是指顺应总体趋势的那条线,并且要穿过图中尽可能多的点。最优拟合线能够反映出自变量和因变量之间的相互关系。
但是说了这么多,这和预测未来又有什么关系呢?假设我们要预测美国GDP的增长趋势,并且我们猜测GDP增长与企业利润率(也就是每个公司的纯利润)之间存在一定关系。因此,我们将以上假设绘制成一幅图,并且从中发现了以下关系。(图中所涉及所有数据纯属虚构,仅在本文中用于阐述目的)
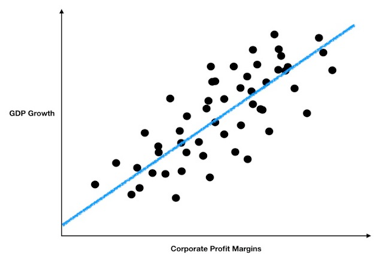
从图中可以看到很明显的正相关关系。但是,光凭这一点就可以说企业利润越大,美国GDP的增长就越快吗?先别这么快下结论,在这个时候应该时刻在脑子里提醒自己这样一句话:相互关系并不意味着因果关系。
的确,经济扩张经常会带来企业利润的增长。但是,我们所要研究的是能否通过企业利润预测经济的增长。为此,需要稍微调整一下分析方法。
• 错误:当前的企业利润VS. 当前的GDP增长
• 正确:当前的企业利润VS. 下一年的GDP增长
区分好这一点非常重要,因为要找的不是与GDP增长同时发生变化的相关变量,而是能够预测GDP增长前景的影响因素。换言之,需要找到与下一时期的GDP增长存在相互关系的自变量(因变量则是下一年度GDP增长的变化)。所以,需要重新构建一幅散点图。
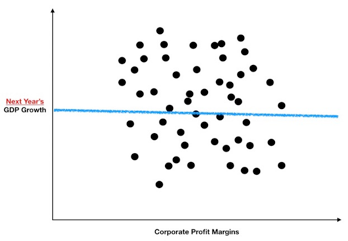
再仔细观察一下这幅图,这次还能找到正相关关系吗?由此可见,预测未来没那么容易。当我们把一个变量转换为其未来状态(也就是说测量其预测相关性)时,那么原先非常明显的同时相关性就会不复存在。
然而,这并不意味着预测未来就毫无希望。因为通常只要发挥创造性思维,并且进行深入的研究,还是能够找出一些预测关系的。但是,最好也别期待其相关性会有多么的强或者明显,因为从我的个人经历来看(对金融市场进行预测的经历),预测相关性只要在0.20到0.30之间就已经非常不错了。
用于理解预测的心智模型
假设继续研究未来GDP增长与其他变量之间的关系,可以画出以下这幅关系图。
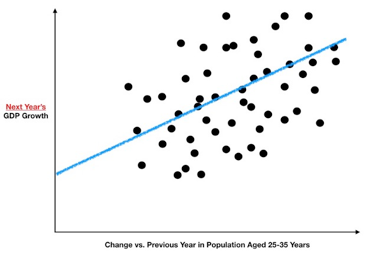
可以发现,未来的GDP增长趋势与目前年轻人(25至35岁)的就业率之间存在一定关系。从图中可以看出,虽然其正相关性没有之前的研究(GDP增长与企业利润直接的同时相关性)那么强,但是可以使用该预测关系来建立一个预测模型。(再次强调,图中所涉及所有数据纯属虚构,并且仅在本文中用于阐述目的)
但是,如何构建预测模型呢?实际上,我们已经在图中构建出来了,因为蓝色的那条最优拟合线就是我们的模型。在进行预测时,只需要先了解目前就业青年人口数量(也就是图中金色虚线所表示的数值),然后再观察金色虚线与蓝色最优拟合线交点的纵坐标所对应的值(图中绿色虚线),而这个值就是所预测的值。
听到这里,是不是觉得很棒?预测是不是超级简单?其实,如果预测涉及多个自变量或者需要用到更加复杂的预测算法,其预测过程也是如此。
但是就其本质而言,预测到底意味着什么?事实上,每一种预测,无论其涉及的模型有多复杂,其实都是一种条件期望。所谓的条件期望,不过是一种期望值,或者说平均值。
然而现在,你突然发现自己用XGBoost进行回归预测所得到的值不过是一个平均值而已,那不就是刚开始在统计课上学的最基础的概念嘛!
确实如此,但稍微有一点区别。如果你还不相信,那我们来做一个思维小游戏。假设我要求你去预测明天的天气,并且不能上网查,那么你会怎么做?这时你或许会进行以下推测,“因为昨天很热,并且现在是八月的圣何塞,因此我预测明天也是一个炎热的晴天。”
为什么你会得出这样一个结论呢?因为你在记忆中组建了一个关于每一天的“心智库存”,而这一点你自己可能都没有意识到。然后,你知道自己是在圣何塞,并且现在是夏天,前几天都非常热。因此在你的“心智库存”中,平均每天的天气与前几天都差不多,都是炎热的晴天。
因此你在做出这个预测时,只过滤筛选了相关的观测值(夏天的圣何塞,并且前几天都很热),然后取其平均值。而这,是我们作为人类在做出预测时的本能反应。何况我们人类都这样,为什么还要求模型和机器不能这样呢?其实,无论是模型还是机器,它们的预测原理和人类没什么不同,只不过它们处理数据的量更大,并且更加公正没有偏见而已。
因此,为了能更好地理解对未来的预测,我建议大家把每一次预测都看作是对平均值的探讨,并且该平均值是基于相关性最高的先前观测值。总而言之,预测未来不过是在回答下面这个问题:如果我看到过去也发生了类似的事情,那么接下来通常会发生什么?
可视化条件平均值(即预测)
上文有说到,预测其实是指条件平均值。为了能更加清楚而直观地理解这一点,可以对上文中的例子进行可视化处理。以下这幅图就是处理过后的线性回归模型,也就是最后的预测模型。在这幅图中,金色的矩形代表当自变量在某一特定范围内时,其所对应的部分观测值。例如,图中左边第一个矩形表示的是:当就业青年人口增长率(也就是位于X轴的自变量)处于0%与0.1%之间时,GDP增长观测值(也就是位于Y轴的因变量)的大小。
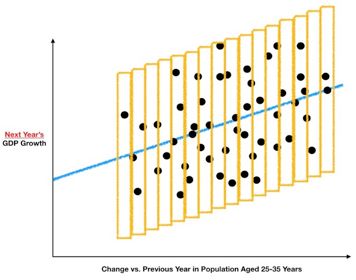
仔细观察就会发现,图中的蓝色预测线(最优拟合线)大体上处于每一个金色矩形的中部。这是为什么呢?实际上,这一巧合是人为设计的,因为每一个矩形的中部代表着该部分观测值的平均值(上文说过每个矩形代表一部分观测值)。如果把这些矩形再进行细分(随着矩形数量的增加,其宽度也逐渐减小),许许多多的条件平均值(每个矩形中部所代表的值)最终就会汇聚于这一条回归线上。
在这个时候,你或许会疑惑,有些矩形的中部很明显不是这部分观测值的平均值啊。比如第一个矩形里面只有一个观测值,并且位于预测线的上方。所以,怎么能立马得出结论说预测线就代表着条件平均值,或者是该部分的平均值呢?
实际上,对于简单的线性回归模型来说,由于回归算法在自变量和因变量之间强加了一种线性关系,所以条件平均值与每一部分观测值的平均值并不会完全匹配。但是这些值在这一过程中也不会丢失,因为心智模型仍然会发挥作用。
为了找到最优拟合线,在回归分析过程中最常使用的方法是最小二乘法。该方法就像一串的条件平均值,但是有一些扭曲和拉扯。为了更加清楚地理解这种方法,我们可以把它比喻成投票:
• 假设每一个金色的矩形都代表一个独立的选区。
• 每一个选区都想把自己选区内蓝色预测线的值(也就是每个金色矩形竖直方向的中点值)往自己这边拉,使其尽可能的接近自己选区的平均值(也就是该选区内所有黑点的纵坐标平均值)。
• 这个时候,如果某一个选区拉动了预测线,那么这次移动就会影响到其他所有选区内预测线的值(因为预测线必须是一条直线)。
• 然而,每个选区影响预测线的能力其实与该选区内观测值的数量成正比,也就是说,某个选区内观测值数量越多,其对预测线的影响力也就越大。
因此最后的结果就是,每一个选区都尽自己最大的努力来拉扯预测线,使其朝自己的平均值方向移动。与此同时,每个选区也受着其他选区的拉扯力的影响,尤其是那些观测值多的选区。最终,这条预测线在稳定下来之后就会呈现出以下特点:
1. 每一个选区或多或少都得到了满足,并且朝自己的平均值方向移动了预测线。
2. 所有的平均值都纳入了考虑范围(因为每一个选区都想把预测线朝自己的平均值方向移动)。
虽然从严格意义上来说,通过线性回归所做出的预测并不能算作是条件平均值。但是,它们其实也差不了多少,因为每一个选区都想把预测线朝自己的平均值方向移动一点。
结语
条件平均值能怎样帮助我们更好地理解预测呢?实际上,条件平均值是进行每一次预测的基石。在预测过程中,无论涉及的算法有多复杂,其本质都是为了找出与预测目标最相似的观测值。基于这些最为相似的观测值,算出其平均值,最后再根据平均值来作出进一步预测。
有一些算法只会使用到非数值的类属特征,并且通过条件平均值来作出预测,比如K近邻算法和线性回归模型。
因此,预测未来也并不是一种什么神秘力量。无论是算法还是人类,都无法基于现有数据来对未来作出精准的预测。我们能做到只是通过分析过去发生的事情,并且以此作为指导以推断未来可能出现的情况。
提示
在构建预测算法时,应时刻记住以下两点。
首先,因为对未来的预测是基于对过去的分析,所以背景资料就显得尤为重要。如果环境完全不同于模型所接受训练的历史数据,那么预测也不会很准确。
第二,为了避免出现过度拟合,可以构建一个心智模型。在构建模型时,为了让模型能够合理地概括并且反映出其特点,必须遵循以下两条原则:
1. 确保每个条件平均值要涵盖足够多的观测值(如果观测值过少,那么其平均值就更有可能出现偏差)。为此,可以尝试减少自变量的数量,因为如果变量太多,那么矩形就会变得过窄,每个矩形内观测值的数量也会随之减少。
2. 在使用某些算法时需要注意,有的选区会给自己选区内的预测值施加过多的影响。如果一个算法内包含过多的非线性关系,比如多项式回归和深度神经网络,那么每个选区就会使该选区内预测值等于其平均值。然而,这将会大大降低预测结果的合理性和稳定性,从而也无法清楚地反映出其总体趋势。

先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。