时间序列深度学习:状态 LSTM 模型预测太阳黑子(上)
作者:徐瑞龙 整理分享量化投资与固定收益相关的文章
博客专栏:
https://www.cnblogs.com/xuruilong100
本文翻译自《Time Series Deep Learning: Forecasting Sunspots With Keras Stateful Lstm In R》
由于数据科学机器学习和深度学习的发展,时间序列预测在预测准确性方面取得了显着进展。随着这些 ML/DL 工具的发展,企业和金融机构现在可以通过应用这些新技术来解决旧问题,从而更好地进行预测。在本文中,我们展示了使用称为 LSTM(长短期记忆)的特殊类型深度学习模型,该模型对涉及自相关性的序列预测问题很有用。我们分析了一个名为“太阳黑子”的著名历史数据集(太阳黑子是指太阳表面形成黑点的太阳现象)。我们将展示如何使用 LSTM 模型预测未来 10 年的太阳黑子数量。
教程概览
此代码教程对应于 2018 年 4 月 19 日星期四向 SP Global 提供的 Time Series Deep Learning 演示文稿。可以下载补充本文的幻灯片。
这是一个涉及时间序列深度学习和其他复杂机器学习主题(如回测交叉验证)的高级教程。如果想要了解 R 中的 Keras,请查看:Customer Analytics: Using Deep Learning With Keras To Predict Customer Churn。
本教程中,你将会学到:
用
keras包开发一个状态 LSTM 模型,该 R 包将 R TensorFlow 作为后端。将状态 LSTM 模型应用到著名的太阳黑子数据集上。
借助
rsample包在初始抽样上滚动预测,实现时间序列的交叉检验。借助
ggplot2和cowplot可视化回测和预测结果。通过自相关函数(Autocorrelation Function,ACF)图评估时间序列数据是否适合应用 LSTM 模型。
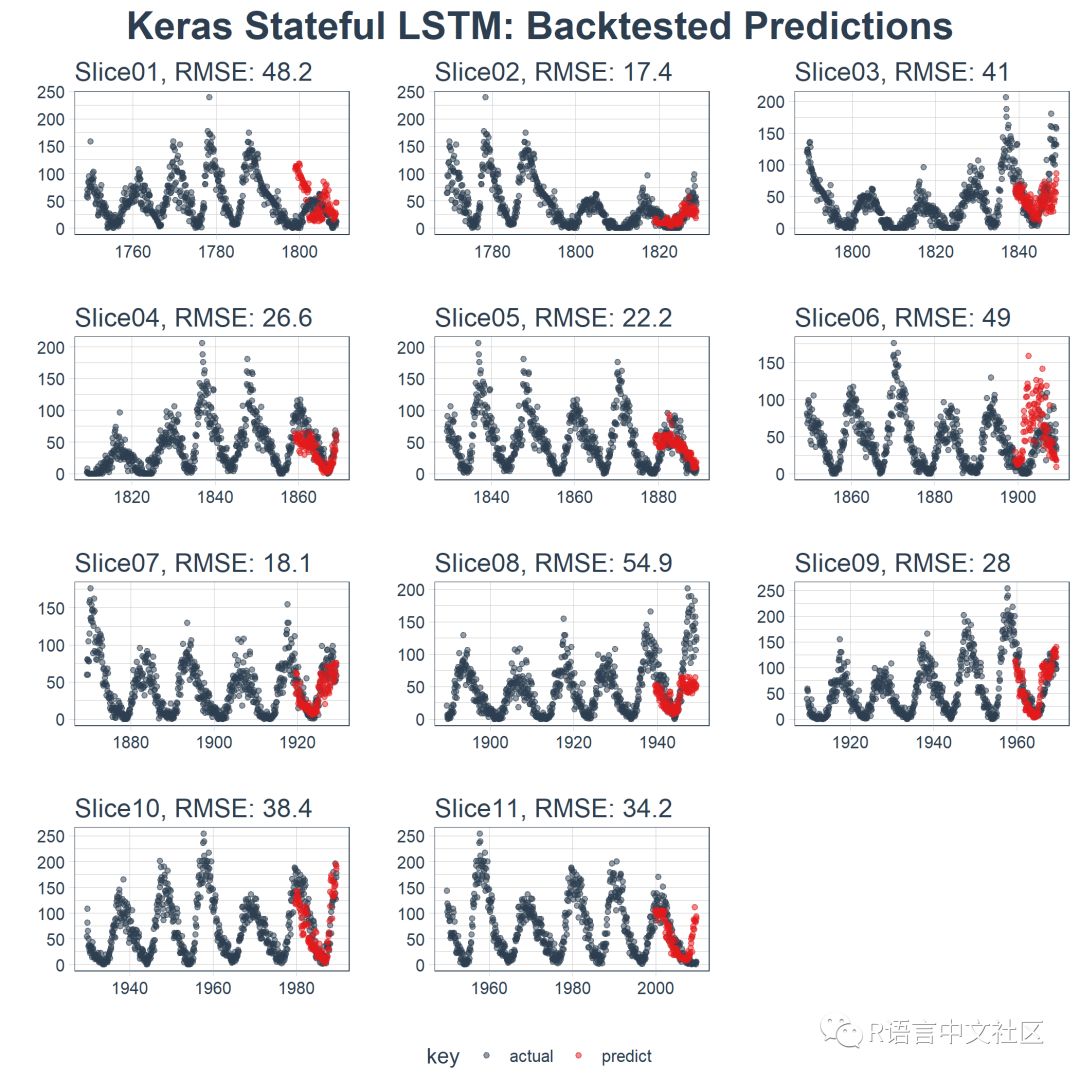
本文的最终结果是一个高性能的深度学习算法,在预测未来 10 年太阳黑子数量方面表现非常出色!这是回测后状态 LSTM 模型的结果。
商业应用
时间序列预测对营收和利润有显着影响。在商业方面,我们可能有兴趣预测每月、每季度或每年的哪一天会发生大额支出,或者我们可能有兴趣了解消费者物价指数(CPI)在未来六年个月如何变化。这些都是在微观经济和宏观经济层面影响商业组织的常见问题。虽然本教程中使用的数据集不是“商业”数据集,但它显示了工具-问题匹配的强大力量,意味着使用正确的工具进行工作可以大大提高准确性。最终的结果是预测准确性的提高将对营收和利润带来可量化的提升。
长短期记忆(LSTM)模型
长短期记忆(LSTM)模型是一种强大的递归神经网络(RNN)。博文《Understanding LSTM Networks》(翻译版)以简单易懂的方式解释了模型的复杂性机制。下面是描述 LSTM 内部单元架构的示意图,除短期状态之外,该架构使其能够保持长期状态,而这是传统的 RNN 处理起来有困难的:
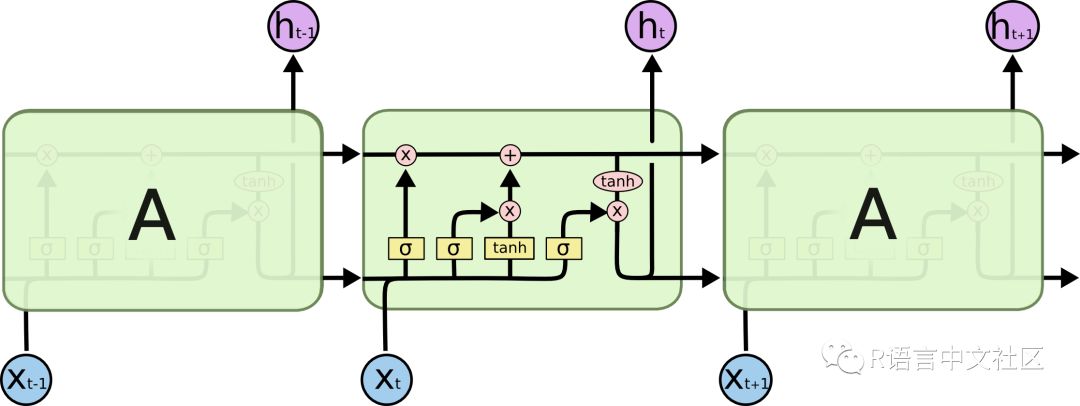
来源:Understanding LSTM Networks
LSTM 模型在预测具有自相关性(时间序列和滞后项之间存在相关性)的时间序列时非常有用,因为模型能够保持状态并识别时间序列上的模式。在每次处理过程中,递归架构能使状态在更新权重时保持或者传递下去。此外,LSTM 模型的单元架构在短期持久化的基础上实现了长期持久化,进而强化了 RNN,这一点非常吸引人!
在 Keras 中,LSTM 模型可以有“状态”模式,Keras 文档中这样解释:
索引 i 处每个样本的最后状态将被用作下一次批处理中索引 i 处样本的初始状态
在正常(或“无状态”)模式下,Keras 对样本重新洗牌,时间序列与其滞后项之间的依赖关系丢失。但是,在“状态”模式下运行时,我们通常可以通过利用时间序列中存在的自相关性来获得高质量的预测结果。
在完成本教程时,我们会进一步解释。就目前而言,可以认为 LSTM 模型对涉及自相关性的时间序列问题可能非常有用,而且 Keras 有能力创建完美的时间序列建模工具——状态 LSTM 模型。
太阳黑子数据集
太阳黑子是随 R 发布的著名数据集(参见 datasets 包)。数据集跟踪记录太阳黑子,即太阳表面出现黑点的事件。这是来自 NASA 的一张照片,显示了太阳黑子现象。相当酷!

来源:NASA
本教程所用的数据集称为 sunspots.month,包含了 265(1749 ~ 2013)年间每月太阳黑子数量的月度数据。
构建 LSTM 模型预测太阳黑子
让我们开动起来,预测太阳黑子。这是我们的目标:
目标:使用 LSTM 模型预测未来 10 年的太阳黑子数量。
1 若干相关包
以下是本教程所需的包,所有这些包都可以在 CRAN 上找到。如果你尚未安装这些包,可以使用 install.packages() 进行安装。注意:在继续使用此代码教程之前,请确保更新所有包,因为这些包的先前版本可能与所用代码不兼容。
# Core Tidyverse
library(tidyverse)
library(glue)
library(forcats)
# Time Series
library(timetk)
library(tidyquant)
library(tibbletime)
# Visualization
library(cowplot)
# Preprocessing
library(recipes)
# Sampling / Accuracy
library(rsample)
library(yardstick)
# Modeling
library(keras)
如果你之前没有在 R 中运行过 Keras,你需要用 install_keras() 函数安装 Keras。
# Install Keras if you have not installed before
install_keras()
2 数据
数据集 sunspot.month 随 R 一起发布,可以轻易获得。它是一个 ts 类对象(非 tidy 类),所以我们将使用 timetk 中的 tk_tbl() 函数转换为 tidy 数据集。我们使用这个函数而不是来自 tibble 的 as.tibble(),用来自动将时间序列索引保存为zoo yearmon 索引。最后,我们将使用 lubridate::as_date()(使用 tidyquant 时加载)将 zoo 索引转换为日期,然后转换为 tbl_time 对象以使时间序列操作起来更容易。
sun_spots <- datasets::sunspot.month %>%
tk_tbl() %>%
mutate(index = as_date(index)) %>%
as_tbl_time(index = index) sun_spots
## # A time tibble: 3,177 x 2##
# Index: index
## index value
## <date> <dbl>
## 1 1749-01-01 58.0
## 2 1749-02-01 62.6
## 3 1749-03-01 70.0
## 4 1749-04-01 55.7
## 5 1749-05-01 85.0
## 6 1749-06-01 83.5
## 7 1749-07-01 94.8
## 8 1749-08-01 66.3
## 9 1749-09-01 75.9
## 10 1749-10-01 75.5
## # ... with 3,167 more rows
3 探索性数据分析
时间序列很长(有 265 年!)。我们可以将时间序列的全部(265 年)以及前 50 年的数据可视化,以获得该时间系列的直观感受。
3.1 使用 COWPLOT 可视化太阳黑子数据
我们将创建若干 ggplot 对象并借助 cowplot::plot_grid() 把这些对象组合起来。对于需要缩放的部分,我们使用 tibbletime::time_filter(),可以方便的实现基于时间的过滤。
p1 <- sun_spots %>%
ggplot(aes(index, value)) +
geom_point(
color = palette_light()[[1]], alpha = 0.5) +
theme_tq() +
labs(title = "From 1749 to 2013 (Full Data Set)") p2 <- sun_spots %>%
filter_time("start" ~"1800") %>%
ggplot(aes(index, value)) +
geom_line(color = palette_light()[[1]], alpha = 0.5) +
geom_point(color = palette_light()[[1]]) +
geom_smooth(method = "loess", span = 0.2, se = FALSE) +
theme_tq() +
labs(
title = "1749 to 1800 (Zoomed In To Show Cycle)",
caption = "datasets::sunspot.month") p_title <- ggdraw() +
draw_label(
"Sunspots",
size = 18,
fontface = "bold",
colour = palette_light()[[1]])
plot_grid( p_title, p1, p2,
ncol = 1,
rel_heights = c(0.1, 1, 1))
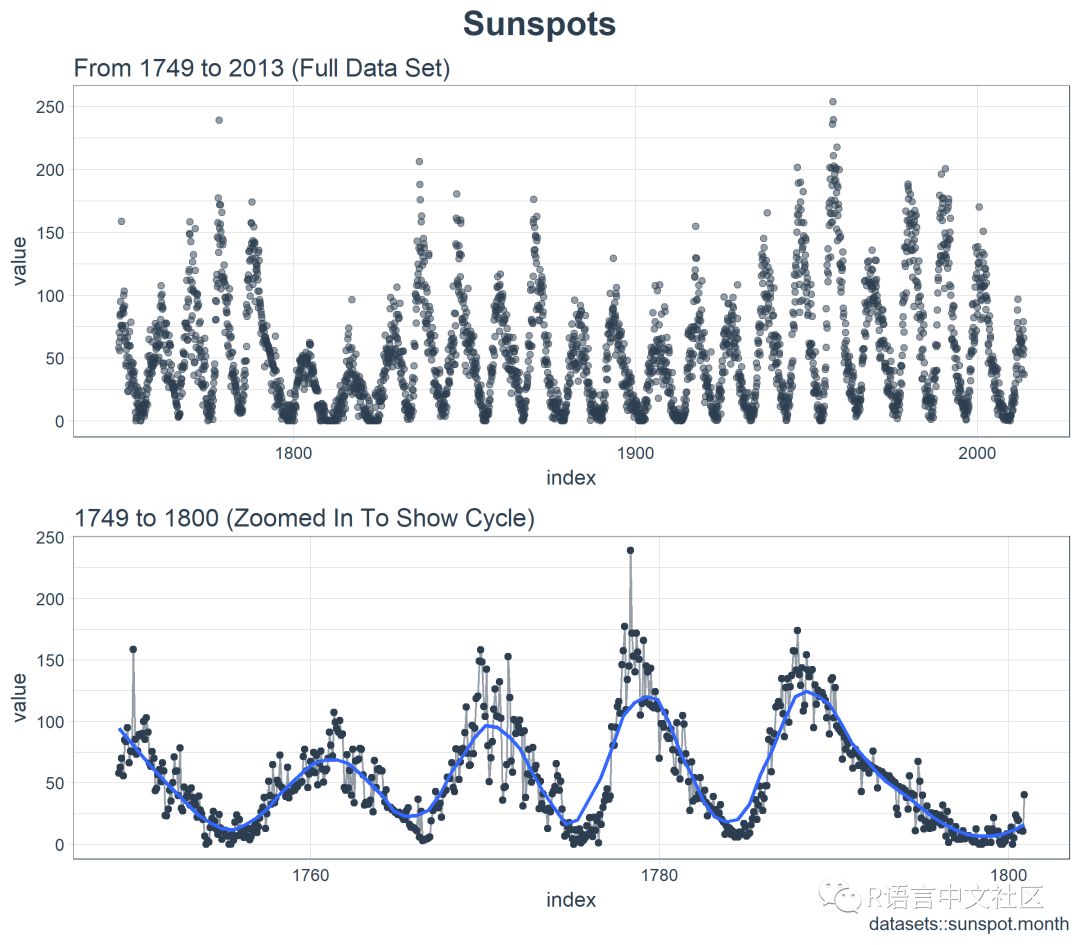
乍一看,这个时间序列应该很容易预测。但是,我们可以看到,周期(10 年)和振幅(太阳黑子的数量)似乎在 1780 年至 1800 年之间发生变化。这产生了一些挑战。
接下来我们要做的是确定 LSTM 模型是否是一个适用的好方法。LSTM 模型利用自相关性产生序列预测。我们的目标是使用批量预测(一种在整个预测区域内创建单一预测批次的技术,不同于在未来一个或多个步骤中迭代执行的单一预测)产生未来 10 年的预测。批量预测只有在自相关性持续 10 年以上时才有效。下面,我们来检查一下。
首先,我们需要回顾自相关函数(Autocorrelation Function,ACF),它表示时间序列与自身滞后项之间的相关性。stats 包库中的 acf() 函数以曲线的形式返回每个滞后阶数的 ACF 值。但是,我们希望将 ACF 值提取出来以便研究。为此,我们将创建一个自定义函数 tidy_acf(),以 tidy tibble 的形式返回 ACF 值。
tidy_acf <- function(data,
value,
lags = 0:20) {
value_expr <- enquo(value)
acf_values <- data %>%
pull(value) %>%
acf(lag.max = tail(lags, 1), plot = FALSE) %>%
.$acf %>%
.[,,1]
ret <- tibble(acf = acf_values) %>%
rowid_to_column(var = "lag") %>%
mutate(lag = lag - 1) %>%
filter(lag %in% lags)
return(ret)
}
接下来,让我们测试一下这个函数以确保它按预期工作。该函数使用我们的 tidy 时间序列,提取数值列,并以 tibble 的形式返回 ACF 值以及对应的滞后阶数。我们有 601 个自相关系数(一个对应时间序列自身,剩下的对应 600 个滞后阶数)。一切看起来不错。
max_lag <- 12 * 50
sun_spots %>%
tidy_acf(value, lags = 0:max_lag)
## # A tibble: 601 x 2
## lag acf
## <dbl> <dbl>
## 1 0. 1.00
## 2 1. 0.923
## 3 2. 0.893
## 4 3. 0.878
## 5 4. 0.867
## 6 5. 0.853
## 7 6. 0.840
## 8 7. 0.822
## 9 8. 0.809
## 10 9. 0.799
## # ... with 591 more rows
下面借助 ggplot2 包把 ACF 数据可视化,以便确定 10 年后是否存在高自相关滞后项。
sun_spots %>%
tidy_acf(value, lags = 0:max_lag) %>%
ggplot(aes(lag, acf)) +
geom_segment(
aes(xend = lag, yend = 0),
color = palette_light()[[1]]) +
geom_vline(
xintercept = 120, size = 3,
color = palette_light()[[2]]) +
annotate(
"text", label = "10 Year Mark",
x = 130, y = 0.8,
color = palette_light()[[2]],
size = 6, hjust = 0) +
theme_tq() +
labs(title = "ACF: Sunspots")
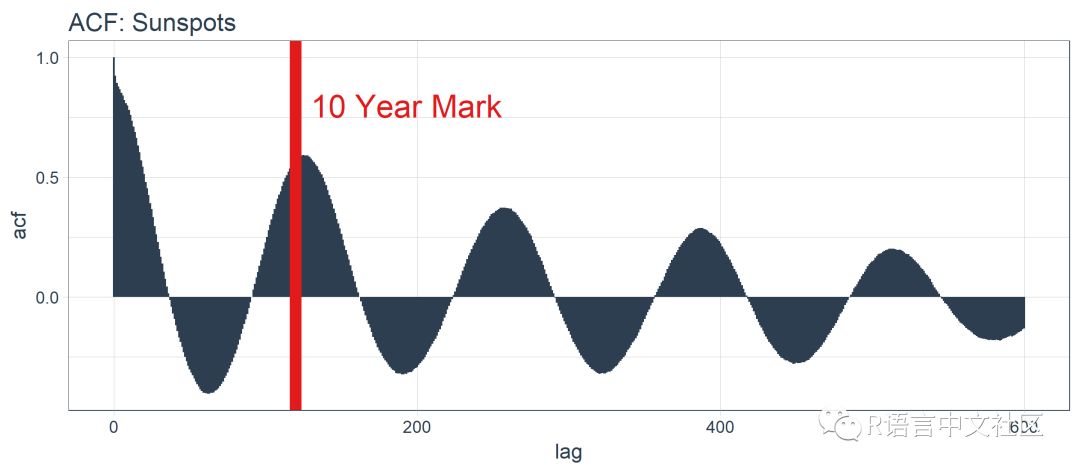
好消息。自相关系数在 120 阶(10年标志)之后依然超过 0.5。理论上,我们可以使用高自相关滞后项来开发 LSTM 模型。
sun_spots %>%
tidy_acf(value, lags = 115:135) %>%
ggplot(aes(lag, acf)) +
geom_vline(
xintercept = 120, size = 3,
color = palette_light()[[2]]) +
geom_segment(
aes(xend = lag, yend = 0),
color = palette_light()[[1]]) +
geom_point(
color = palette_light()[[1]],
size = 2) +
geom_label(
aes(label = acf %>% round(2)),
vjust = -1,
color = palette_light()[[1]]) +
annotate(
"text", label = "10 Year Mark",
x = 121, y = 0.8,
color = palette_light()[[2]],
size = 5, hjust = 0) +
theme_tq() +
labs(
title = "ACF: Sunspots",
subtitle = "Zoomed in on Lags 115 to 135")
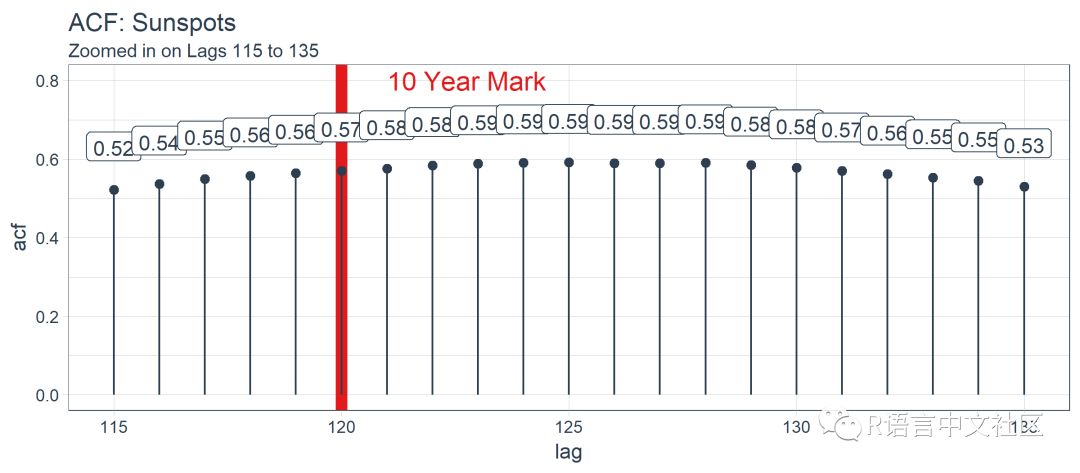
经过检查,最优滞后阶数位于在 125 阶。这不一定是我们将使用的,因为我们要更多地考虑使用 Keras 实现的 LSTM 模型进行批量预测。有了这个观点,以下是如何 filter() 获得最优滞后阶数。
optimal_lag_setting <- sun_spots %>%
tidy_acf(value, lags = 115:135) %>%
filter(acf == max(acf)) %>%
pull(lag) optimal_lag_setting
## [1] 125
4 回测:时间序列交叉验证
交叉验证是在子样本数据上针对验证集数据开发模型的过程,其目标是确定预期的准确度级别和误差范围。在交叉验证方面,时间序列与非序列数据有点不同。具体而言,在制定抽样计划时,必须保留对以前时间样本的时间依赖性。我们可以通过平移窗口的方式选择连续子样本,进而创建交叉验证抽样计划。在金融领域,这种类型的分析通常被称为“回测”,它需要在一个时间序列上平移若干窗口来分割成多个不间断的序列,以在当前和过去的观测上测试策略。
最近的一个发展是 rsample 包,它使交叉验证抽样计划非常易于实施。此外,rsample 包还包含回测功能。“Time Series Analysis Example”描述了一个使用 rolling_origin() 函数为时间序列交叉验证创建样本的过程。我们将使用这种方法。
4.1 开发一个回测策略
我们创建的抽样计划使用 50 年(initial = 12 x 50)的数据作为训练集,10 年(assess = 12 x 10)的数据用于测试(验证)集。我们选择 20 年的跳跃跨度(skip = 12 x 20),将样本均匀分布到 11 组中,跨越整个 265 年的太阳黑子历史。最后,我们选择 cumulative = FALSE 来允许平移起始点,这确保了较近期数据上的模型相较那些不太新近的数据没有不公平的优势(使用更多的观测数据)。rolling_origin_resamples 是一个 tibble 型的返回值。
periods_train <- 12 * 50
periods_test <- 12 * 10
skip_span <- 12 * 20
rolling_origin_resamples <- rolling_origin( sun_spots,
initial = periods_train,
assess = periods_test,
cumulative = FALSE,
skip = skip_span) rolling_origin_resamples
## # Rolling origin forecast resampling
## # A tibble: 11 x 2
## splits id
## <list> <chr>
## 1 <S3: rsplit> Slice01
## 2 <S3: rsplit> Slice02
## 3 <S3: rsplit> Slice03
## 4 <S3: rsplit> Slice04
## 5 <S3: rsplit> Slice05
## 6 <S3: rsplit> Slice06
## 7 <S3: rsplit> Slice07
## 8 <S3: rsplit> Slice08
## 9 <S3: rsplit> Slice09
## 10 <S3: rsplit> Slice10
## 11 <S3: rsplit> Slice11
4.2 可视化回测策略
我们可以用两个自定义函数来可视化再抽样。首先是 plot_split(),使用 ggplot2 绘制一个再抽样分割图。请注意,expand_y_axis 参数默认将日期范围扩展成整个 sun_spots 数据集的日期范围。当我们将所有的图形同时可视化时,这将变得有用。
# Plotting function for a single split
plot_split <- function(split,
expand_y_axis = TRUE,
alpha = 1,
size = 1,
base_size = 14) { # Manipulate data train_tbl <- training(split) %>%
add_column(key = "training") test_tbl <- testing(split) %>%
add_column(key = "testing") data_manipulated <- bind_rows( train_tbl, test_tbl) %>%
as_tbl_time(index = index) %>%
mutate(
key = fct_relevel( key, "training", "testing"))
# Collect attributes train_time_summary <- train_tbl %>%
tk_index() %>%
tk_get_timeseries_summary() test_time_summary <- test_tbl %>%
tk_index() %>%
tk_get_timeseries_summary()
# Visualize g <- data_manipulated %>% ggplot( aes(x = index,y = value,
color = key)) +
geom_line(size = size, alpha = alpha) +
theme_tq(base_size = base_size) +
scale_color_tq() +
labs(
title = glue("Split: {split$id}"),
subtitle = glue(
"{train_time_summary$start} to {test_time_summary$end}"),
y = "", x = "") +
theme(legend.position = "none") if (expand_y_axis) { sun_spots_time_summary <- sun_spots %>%
tk_index() %>%
tk_get_timeseries_summary() g <- g +
scale_x_date(
limits = c( sun_spots_time_summary$start, sun_spots_time_summary$end)) } return(g) }
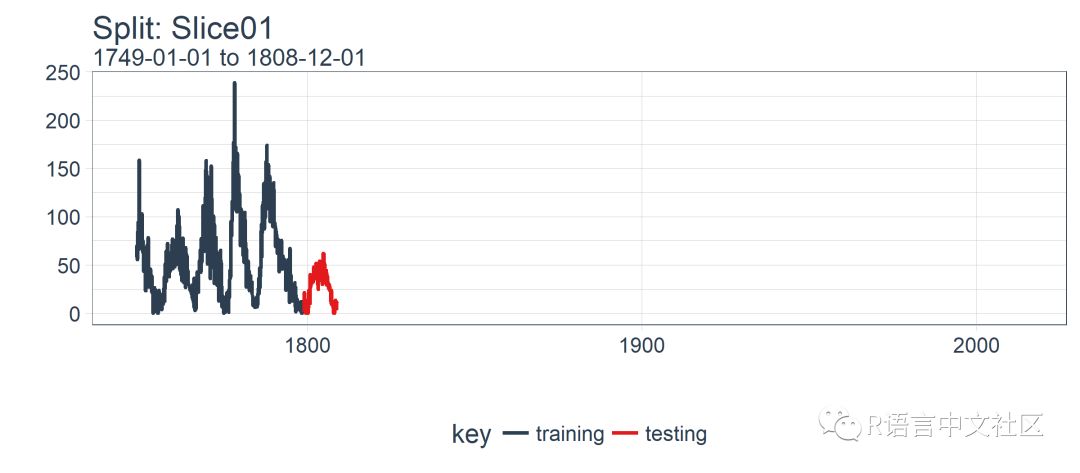
plot_split() 函数接受一个分割(在本例中为 Slice01),并可视化抽样策略。我们使用 expand_y_axis = TRUE 将横坐标范围扩展到整个数据集的日期范围。
rolling_origin_resamples$splits[[1]] %>%
plot_split(expand_y_axis = TRUE) +
theme(legend.position = "bottom")
第二个函数是 plot_sampling_plan(),使用 purrr 和 cowplot 将 plot_split() 函数应用到所有样本上。
# Plotting function that scales to all splits
plot_sampling_plan <- function(sampling_tbl, expand_y_axis = TRUE, ncol = 3,
alpha = 1,
size = 1,
base_size = 14, title = "Sampling Plan") { # Map plot_split() to sampling_tbl sampling_tbl_with_plots <- sampling_tbl %>%
mutate(
gg_plots = map( splits, plot_split, expand_y_axis = expand_y_axis,
alpha = alpha,
base_size = base_size)) # Make plots with cowplot plot_list <- sampling_tbl_with_plots$gg_plots p_temp <- plot_list[[1]] + theme(legend.position = "bottom") legend <- get_legend(p_temp) p_body <- plot_grid(
plotlist = plot_list, ncol = ncol) p_title <- ggdraw() +
draw_label( title,
size = 18, fontface = "bold",
colour = palette_light()[[1]]) g <- plot_grid( p_title, p_body, legend,
ncol = 1,
rel_heights = c(0.05, 1, 0.05))
return(g) }
现在我们可以使用 plot_sampling_plan() 可视化整个回测策略!我们可以看到抽样计划如何平移抽样窗口逐渐切分出训练和测试子样本。
rolling_origin_resamples %>%
plot_sampling_plan(
expand_y_axis = T,
ncol = 3, alpha = 1,
size = 1, base_size = 10, title = "Backtesting Strategy: Rolling Origin Sampling Plan")

此外,我们可以让 expand_y_axis = FALSE,对每个样本进行缩放。
rolling_origin_resamples %>%
plot_sampling_plan(
expand_y_axis = F,
ncol = 3, alpha = 1,
size = 1, base_size = 10,
title = "Backtesting Strategy: Zoomed In")
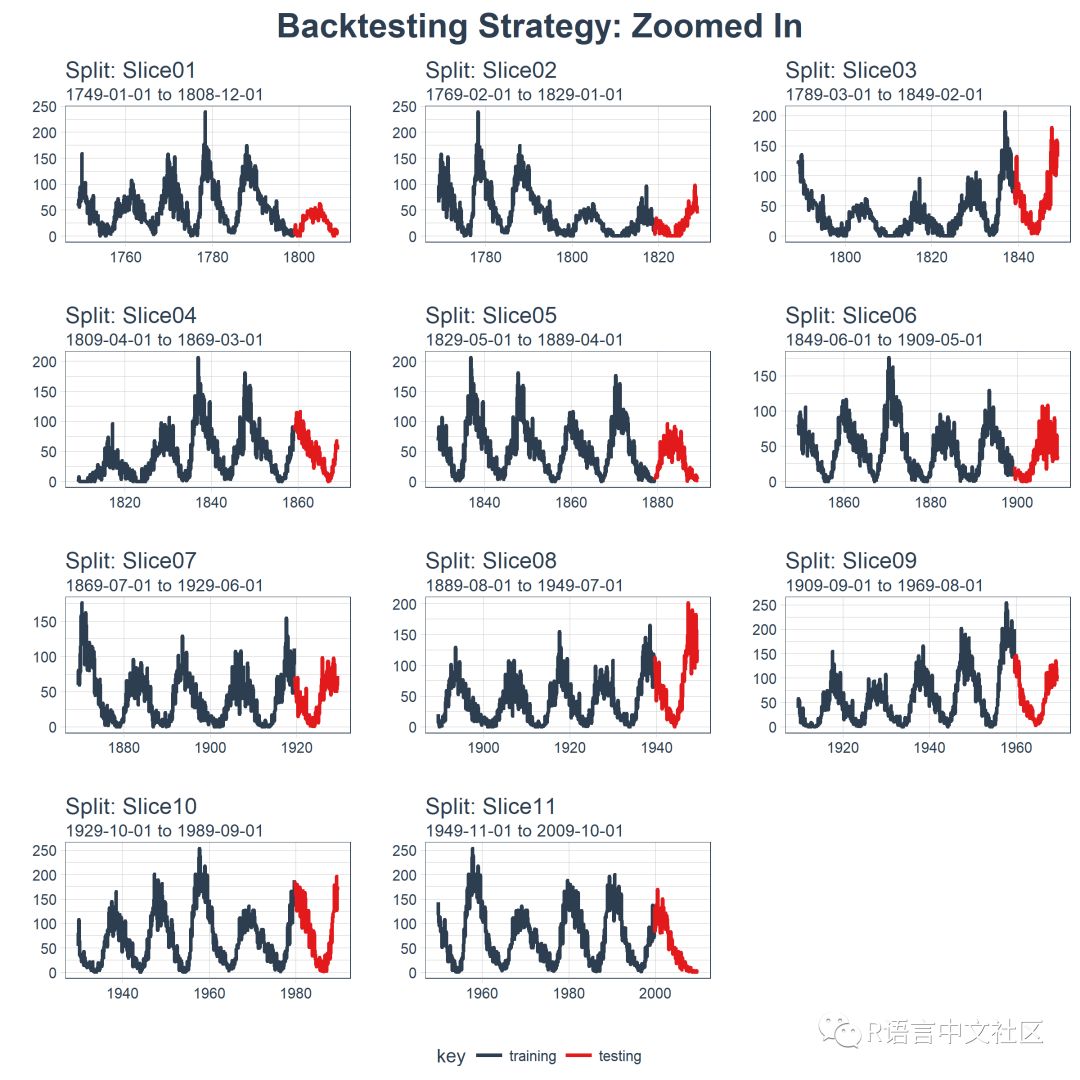
当在太阳黑子数据集上测试 LSTM 模型准确性时,我们将使用这种回测策略(来自一个时间序列的 11 个样本,每个时间序列分为 50/10 两部分,并且样本之间有 20 年的偏移)。

公众号后台回复关键字即可学习
回复 R R语言快速入门及数据挖掘
回复 Kaggle案例 Kaggle十大案例精讲(连载中)
回复 文本挖掘 手把手教你做文本挖掘
回复 可视化 R语言可视化在商务场景中的应用
回复 大数据 大数据系列免费视频教程
回复 量化投资 张丹教你如何用R语言量化投资
回复 用户画像 京东大数据,揭秘用户画像
回复 数据挖掘 常用数据挖掘算法原理解释与应用
回复 机器学习 人工智能系列之机器学习与实践
回复 爬虫 R语言爬虫实战案例分享




