利用自适应域的元学习让机器人一次学会人类动作
人类和动物在学习新行为时,大部分只需要观察一次就能学会,然而想让机器人学习就没那么容易了。随着计算机视觉的发展,目前的技术能让机器人依靠人体姿势检测系统,模仿人类的动作进行学习。不过每次都需要人类“做示范”未免有些麻烦,本篇论文的研究人员们想出了新方法:让机器人通过一段只有一个人的视频来模仿学习。
此前的研究表明,机器人能通过观察示范学习一系列复杂的技能,例如倒水、打乒乓球、打开抽屉等。然而,机器人模仿最有效的方法与人类学习有很大的不同:机器人通常需要接到具体的动作示范或遥控操作,人类只需看别人做一遍就能了解。另外,人类还能根据环境变化改变策略,适应新情况。所以,我们怎样能让机器人像人类一样,通过观察第三方示范进行学习?
从原始视频中获得技能存在两大挑战。首先,人类演示者和机器人的外观及形态的差异会带来系统性的域转移(domain shift),即对应问题(correspondence problem)。其次,从原始视觉输入中学习通常需要大量数据,深度学习视觉系统一般要使用数十万至数百万的图像。而在本文中,我们展示了通过基于元学习的单一方法解决这两个挑战。
前期准备
该方法建立在之前的工作成果或者元学习的基础上,我们将对模型元学习算法进行扩展,它能够处理提供的数据(即人类演示)和评估设置(即机器人动作)之间的域转移。
元学习算法能快速有效地学习新任务,一般来说,元学习可以看作是发现任务之间存在的结构的功能。当模型从元测试集中提出新任务时,模型可以使用已知结构快速学习。算法(MAML)通过对深度网络的初始参数设置进行优化来实现这一点。在元训练之后,根据新任务的数据对学习参数进行微调。
模仿人类
在这一部分,我们将说明机器人一次性模仿人类学习的问题,并介绍我们的试验方法。从含有人类的视频中进行学习可以看做是一个推理问题,其目标是推断机器人的策略参数,它能将先验知识与少量证据结合来完成任务。为了从只有一个人的视频中有效学习,我们需要包含着对世界有着丰富视觉和物体理解的先验知识。
而试验方法包括两个阶段,在元训练阶段,我们需要利用人类和机器人的动作数据获取先验知识,然后通过快速学习模仿动作。这一方法的关键部分在于,它可以迁移到其他元学习算法中去。如MAML算法一样,我们将学习一系列初始参数,在经历过几次梯度下降后,模型还能有效地完成新任务。最终用于元目标的算法可以总结为:

在元训练阶段之后,学习到的先验知识将用于第二阶段。当机器人模仿人类的新动作时,必须将先验知识与新的人类示范动作结合,来推断解决新任务的策略参数。算法总结为:

时序适应目标学习
为了从人的视频中学习,我们需要一个适应目标,可以有效地捕捉视频中的相关信息,比如人的意图和与任务有关的对象。由于时序卷积在处理时序和数据序列时是有用的,所以我们选择用一个卷积网络表示适应目标。效果如图所示:
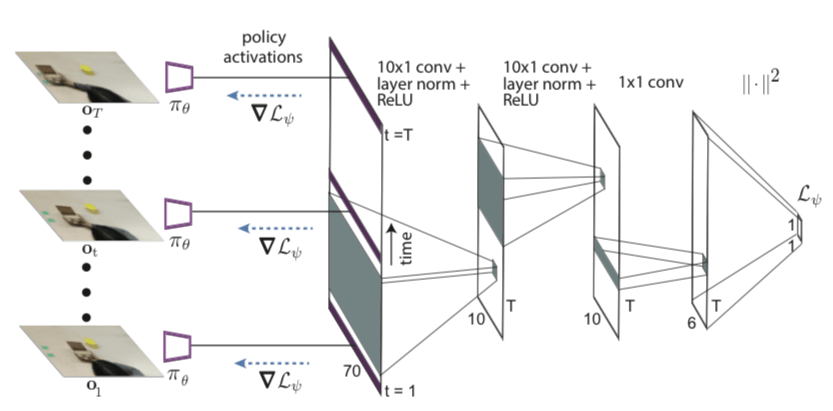
网络架构
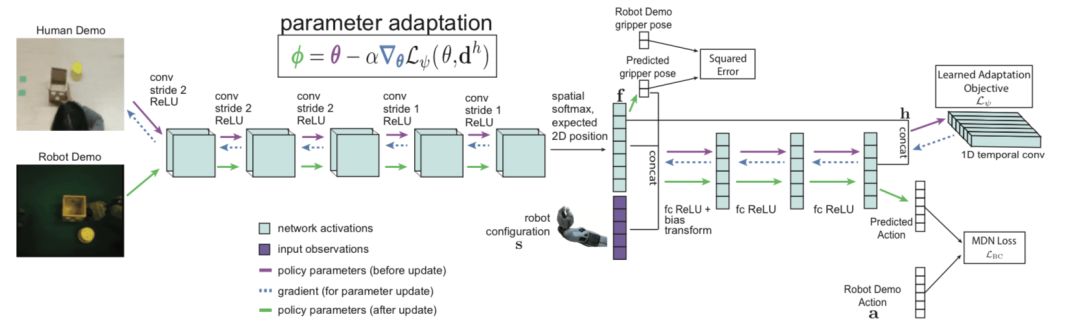
如图所示,网络架构是一个卷积神经网络,将RGB图像映射到动作分布。卷积网络从几个卷积层开始,然后被输送到通道空间的argmax中,为每个通道提取二维特征点f。接着我们将这些特征点与机器人结构连接在一起,该结构包括夹具上的3个非轴对齐的点。然后,我们将连接的特征点和机器人姿态传递给多个完全连接层。
实验过程
我们的实验主要想解决三个问题:
我们的方法能否有效地学习先验知识,让机器人能够通过仅有一人的视频学习操作新物体?
我们的方法能否从新的角度让机器人模仿人类动作?
我们所提出的方法与元学习方法以及其他方法有何不同?
为了进一步了解我们的方法以及其实用性,我们还要另外评估:
时序适应目标有多重要?
我们的方法能否用于多个机器人平台,以及用于动作或遥控示范的元训练?
为了进行评估,我们在7轴的PR2机械臂和Sawyer机器人上进行实验。
PR2实验过程
首先是用机械臂PR2进行物体的放置、前推、捡拾等动作的测试,具体过程如图:

整个过程的装置情况是这样的:

用于拍摄的是一台智能手机,从中看到的情况是这样的:

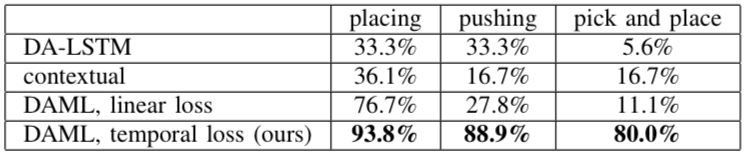
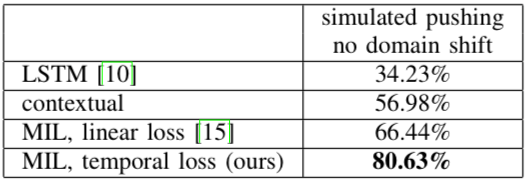
最后,PR2一次学习的评估情况展示在下表中,可以看到成功率大大高于之前的方法:
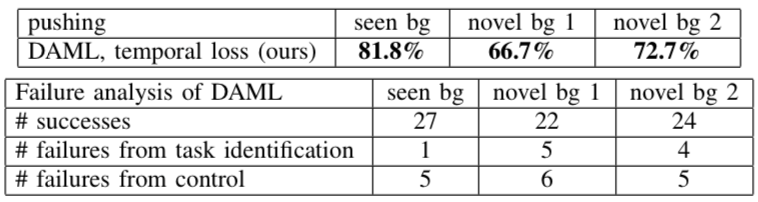
另外,研究人员还统计了PR2在做“推动”时发生的错误:
Sawyer实验过程
实验的另一个目标是我们的方法能否应用于别的平台上,于是我们选择了7个自由度的Sawyer进行验证。不同与PR2实验,动作空间将是末端执行器的单个指令姿态,我们将使用均方误差作为外部的元目标。

最终,在使用时序适应目标的实验中,成功率比没有使用的提高了14%,证明了从视频中学习时融合时间信息的重要性。
实验的局限性
虽然我们的工作成果能让机器人从视频中一次性学习操作新的物体,但是目前的实验还没有证明模型能够一次性学习全新动作。希望未来有更多的数据和更高性能的模型能实现这一目标。
原文地址:arxiv.org/pdf/1802.01557.pdf



