模型独立学习:多任务学习与迁移学习


文章作者:邱锡鹏 复旦大学计算机科学技术学院教授、博士生导师
内容来源:《神经网络与深度学习》
注:文末有赠书活动哦!
导读:机器学习的学习方式包括监督学习和无监督学习等。针对一个给定的任务,首先要准备一定规模的训练数据,这些训练数据需要和真实数据的分布一致,然后设定一个目标函数和优化方法,在训练数据上学习一个模型。此外,不同任务的模型往往都是从零开始来训练的,一切知识都需要从训练数据中得到。这也导致了每个任务都需要准备大量的训练数据。在实际应用中,我们面对的任务往往难以满足上述要求,比如训练任务和目标任务的数据分布不一致,训练数据过少等。这时机器学习的应用会受到很大的局限。并且在很多场合中,我们也需要一个模型可以快速地适应新的任务。因此,人们开始关注一些新的学习方式。
本文中将介绍两种典型的“模型独立的学习方式”:多任务学习和迁移学习。这里“模型独立”是指这些学习方式不限于具体的模型,不管是前馈神经网络、循环神经网络还是其他模型。
01
一般的机器学习模型都是针对单一的特定任务,比如手写体数字识别、物体检测等。不同任务的模型都是在各自的训练集上单独学习得到的。如果有两个任务比较相关,它们之间会存在一定的共享知识,这些知识对两个任务都会有所帮助。这些共享的知识可以是表示(特征)、模型参数或学习算法等。目前,主流的多任务学习方法主要关注于表示层面的共享。
多任务学习(Multi-task Learning)是指同时学习多个相关任务,让这些任务在学习过程中共享知识,利用多个任务之间的相关性来改进模型在每个任务上的性能和泛化能力。多任务学习可以看作是一种归纳迁移学习(Inductive Transfer Learning),即通过利用包含在相关任务中的信息作为归纳偏置(Inductive Bias)来提高泛化能力[Caruana, 1997]。
1. 共享机制
多任务学习的主要挑战在于如何设计多任务之间的共享机制。在传统的机器学习算法中,引入共享的信息是比较困难的,通常会导致模型变得复杂。但是在神经网络模型中,模型共享变得相对比较容易。深度神经网络模型提供了一种很方便的信息共享方式,可以很容易地进行多任务学习。多任务学习的共享机制比较灵活,有很多种共享模式。图10.1给出了多任务学习中四种常见的共享模式,其中A、B和C表示三个不同的任务,橙色框表示共享模块,蓝色框表示任务特定模块。
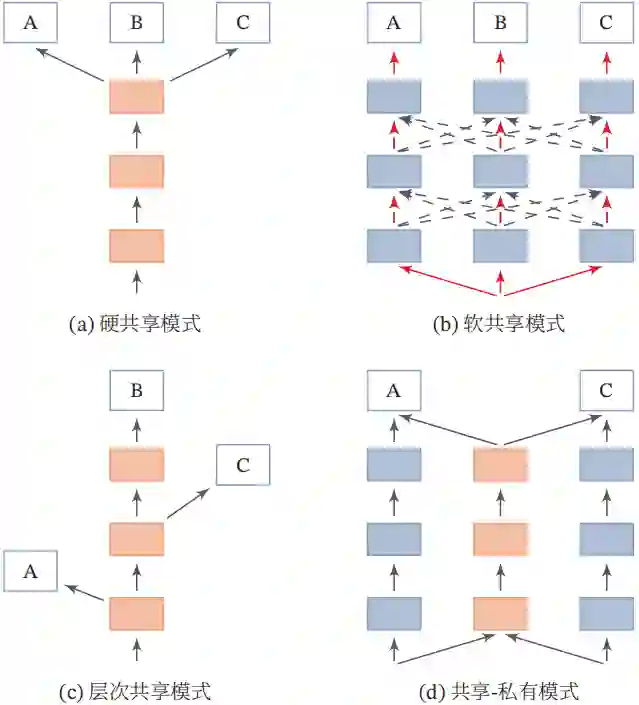
这四种常见的共享模式分别为:
硬共享模式:让不同任务的神经网络模型共同使用一些共享模块(一般是低层)来提取一些通用特征,然后再针对每个不同的任务设置一些私有模块(一般是高层)来提取一些任务特定的特征。
软共享模式:不显式地设置共享模块,但每个任务都可以从其他任务中“窃取”一些信息来提高自己的能力。窃取的方式包括直接复制使用其他任务的隐状态,或使用注意力机制来主动选取有用的信息。
层次共享模式:一般神经网络中不同层抽取的特征类型不同,低层一般抽取一些低级的局部特征,高层抽取一些高级的抽象语义特征。因此如果多任务学习中不同任务也有级别高低之分,那么一个合理的共享模式是让低级任务在低层输出,高级任务在高层输出。
共享-私有模式:一个更加分工明确的方式是将共享模块和任务特定(私有)模块的责任分开。共享模块捕捉一些跨任务的共享特征,而私有模块只捕捉和特定任务相关的特征。最终的表示由共享特征和私有特征共同构成。
2. 学习步骤
在多任务学习中,每个任务都可以有自己单独的训练集。为了让所有任务同时学习,我们通常会使用交替训练的方式来“近似”地实现同时学习。
假设有M个相关任务,第m个任务的训练集为Dm,包含Nm个样本。
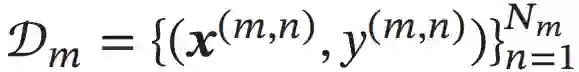
其中x(m,n)和y(m,n)表示第m个任务中的第n个样本以及它的标签。
假设这M个任务对应的模型分别为fm(x;θ),1≤m≤M,多任务学习的联合目标函数为所有任务损失函数的线性加权。
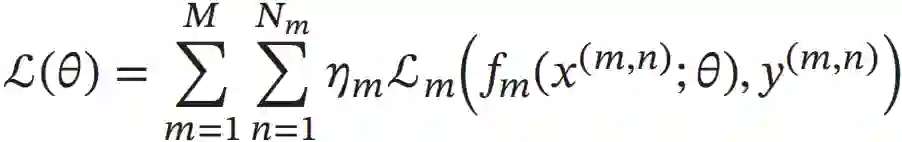
其中Lm(·)为第m个任务的损失函数,ηm是第m个任务的权重,θ表示包含了共享模块和私有模块在内的所有参数。权重可以根据不同任务的重要程度来赋值, 也可以根据任务的难易程度来赋值。通常情况下,所有任务设置相同的权重,即ηm= 1,1≤m≤M。
多任务学习的流程可以分为两个阶段:
联合训练阶段:每次迭代时,随机挑选一个任务,然后从这个任务中随机选择一些训练样本,计算梯度并更新参数;
单任务精调阶段:基于多任务学习得到的参数,分别在每个单独任务进行精调。其中单任务精调阶段为可选阶段。当多个任务的差异性比较大时,在每个单任务上继续优化参数可以进一步提升模型能力。
多任务学习中联合训练阶段的具体过程如算法10.4所示:

多任务学习通常可以获得比单任务学习更好的泛化能力,主要有以下几个原因:
多任务学习在多个任务的数据集上进行训练,比单任务学习的训练集更大。由于多个任务之间有一定的相关性,因此多任务学习相当于是一种隐式的数据增强,可以提高模型的泛化能力。
多任务学习中的共享模块需要兼顾所有任务,这在一定程度上避免了模型过拟合到单个任务的训练集,可以看作是一种正则化。
既然一个好的表示通常需要适用于多个不同任务,多任务学习的机制使得它会比单任务学习获得更好的表示。
在多任务学习中,每个任务都可以“选择性”利用其他任务中学习到的隐藏特征,从而提高自身的能力。
标准机器学习的前提假设是训练数据和测试数据的分布是相同的。如果不满足这个假设,在训练集上学习到的模型在测试集上的表现会比较差。而在很多实际场景中,经常碰到的问题是标注数据的成本十分高,无法为一个目标任务准备足够多相同分布的训练数据。因此,如果有一个相关任务已经有了大量的训练数据,虽然这些训练数据的分布和目标任务不同,但是由于训练数据的规模比较大,我们假设可以从中学习某些可以泛化的知识,那么这些知识对目标任务会有一定的帮助。如何将相关任务的训练数据中的可泛化知识迁移到目标任务上,就是迁移学习(Transfer Learning)要解决的问题。
具体而言,假设一个机器学习任务T的样本空间为X×Y,其中X为输入空间,Y为输出空间,其概率密度函数为p(x,y)。为简单起见,这里设X为D维实数空间的一个子集,Y为一个离散的集合。
一个样本空间及其分布可以称为一个领域(Domain):D=(X,Y,p(x,y))。给定两个领域,如果它们的输入空间、输出空间或概率分布中至少一个不同,那么这两个领域就被认为是不同的。从统计学习的观点来看,一个机器学习任务T定义为在一个领域D上的条件概率p(y|x)的建模问题。
迁移学习是指两个不同领域的知识迁移过程,利用源领域(Source Domain)DS中学到的知识来帮助目标领域(Target Domain)DT上的学习任务。源领域的训练样本数量一般远大于目标领域。
表10.1给出了迁移学习和标准机器学习的比较。

迁移学习根据不同的迁移方式又分为两个类型:归纳迁移学习(Inductive Transfer Learning)和转导迁移学习(Transductive Transfer Learning)。这两个类型分别对应两个机器学习的范式:归纳学习(Inductive Learning)和转导学习(Transductive Learning)[Vapnik, 1998]。一般的机器学习都是指归纳学习,即希望在训练数据集上学习到使得期望风险(即真实数据分布上的错误率)最小的模型。而转导学习的目标是学习一种在给定测试集上错误率最小的模型,在训练阶段可以利用测试集的信息。
归纳迁移学习是指在源领域和任务上学习出一般的规律,然后将这个规律迁移到目标领域和任务上;而转导迁移学习是一种从样本到样本的迁移,直接利用源领域和目标领域的样本进行迁移学习。
1. 归纳迁移学习
在归纳迁移学习中,源领域和目标领域有相同的输入空间XS=XT,输出空间可以相同也可以不同,源任务和目标任务一般不相同TS≠TT,即pS(y|x)≠pT(y|x)。一般而言,归纳迁移学习要求源领域和目标领域是相关的,并且源领域DS有大量的训练样本,这些样本可以是有标注的样本,也可以是无标注样本。
当源领域只有大量无标注数据时,源任务可以转换为无监督学习任务,比如自编码和密度估计任务。通过这些无监督任务学习一种可迁移的表示,然后再将这种表示迁移到目标任务上. 这种学习方式和自学习(Self-Taught Learning)[Raina et al., 2007]以及半监督学习比较类似。比如在自然语言处理领域,由于语言相关任务的标注成本比较高,很多自然语言处理任务的标注数据都比较少,这导致了在这些自然语言处理任务上经常会受限于训练样本数量而无法充分发挥深度学习模型的能力。同时,由于我们可以低成本地获取大规模的无标注自然语言文本,因此一种自然的迁移学习方式是将大规模文本上的无监督学习(比如语言模型)中学到的知识迁移到一个新的目标任务上。从早期的预训练词向量(比如word2vec [Mikolov et al., 2013]和GloVe [Pennington et al., 2014]等)到句子级表示(比如ELMO [Peters et al., 2018]、OpenAI GPT [Radford et al., 2018]以及BERT[Devlin et al., 2018]等)都对自然语言处理任务有很大的促进作用。
当源领域有大量的标注数据时,可以直接将源领域上训练的模型迁移到目标领域上。比如在计算机视觉领域有大规模的图像分类数据集 ImageNet [Deng et al., 2009]。由于在ImageNet数据集上有很多预训练的图像分类模型,比如AlexNet[Krizhevsky et al., 2012]、VGG [Simonyan et al., 2014]和ResNet[He et al., 2016]等,我们可以将这些预训练模型迁移到目标任务上。
在归纳迁移学习中,由于源领域的训练数据规模非常大,这些预训练模型通常有比较好的泛化性,其学习到的表示通常也适用于目标任务。归纳迁移学习一般有下面两种迁移方式:
基于特征的方式:将预训练模型的输出或者是中间隐藏层的输出作为特征直接加入到目标任务的学习模型中。目标任务的学习模型可以是一般的浅层分类器(比如支持向量机等)或一个新的神经网络模型。
精调的方式:在目标任务上复用预训练模型的部分组件,并对其参数进行精调(fine-tuning)。
假设预训练模型是一个深度神经网络,这个预训练网络中每一层的可迁移性也不尽相同 [Yosinski et al., 2014]。通常来说,网络的低层学习一些通用的低层特征,中层或高层学习抽象的高级语义特征,而最后几层一般学习和特定任务相关的特征。因此,根据目标任务的自身特点以及和源任务的相关性,可以有针对性地选择预训练模型的不同层来迁移到目标任务中。
将预训练模型迁移到目标任务上通常会比从零开始学习的方式更好,主要体现在以下三点 [Torrey et al., 2010]:
初始模型的性能一般比随机初始化的模型要好;
训练时模型的学习速度比从零开始学习要快,收敛性更好;
模型的最终性能更好,具有更好的泛化性。
归纳迁移学习和多任务学习也比较类似,但有下面两点区别:
多任务学习是同时学习多个不同任务,而归纳迁移学习通常分为两个阶段,即源任务上的学习阶段和目标任务上的迁移学习阶段;
归纳迁移学习是单向的知识迁移,希望提高模型在目标任务上的性能,而多任务学习是希望提高所有任务的性能。
2. 转导迁移学习
转导迁移学习是一种从样本到样本的迁移,直接利用源领域和目标领域的样本进行迁移学习[Arnold et al., 2007]。转导迁移学习可以看作一种特殊的转导学习(Transductive Learning)[Joachims, 1999]。转导迁移学习通常假设源领域有大量的标注数据,而目标领域没有(或只有少量)标注数据,但是有大量的无标注数据. 目标领域的数据在训练阶段是可见的。
转导迁移学习的一个常见子问题是领域适应(Domain Adaptation)。在领域适应问题中,一般假设源领域和目标领域有相同的样本空间,但是数据分布不同pS(x,y)≠pT(x,y)。
根据贝叶斯公式,p(x,y)=p(x|y)p(y)=p(y|x)p(x),因此数据分布的不一致通常由三种情况造成:
协变量偏移(Covariate Shift):源领域和目标领域的输入边际分布不同pS(x)≠pT(x),但后验分布相同pS(y|x)=pT(y|x),即学习任务相同TS=TT。
概念偏移(Concept Shift):输入边际分布相同pS(x)=pT(x),但后验分布不同pS(y|x)≠pT(y|x),即学习任务不同TS≠TT。
先验偏移(Prior Shift):源领域和目标领域中的输出标签y的先验分布不同pS(y)≠pT(y),条件分布相同pS(x|y)=pT(x|y). 在这样情况下,目标领域必须提供一定数量的标注样本。
广义的领域适应问题可能包含上述一种或多种偏移情况。目前,大多数的领域适应问题主要关注于协变量偏移,这样领域适应问题的关键就在于如何学习域无关(Domain-Invariant)的表示。假设pS(y|x)=pT(y|x),领域适应的目标是学习一个模型f:X→Y使得:
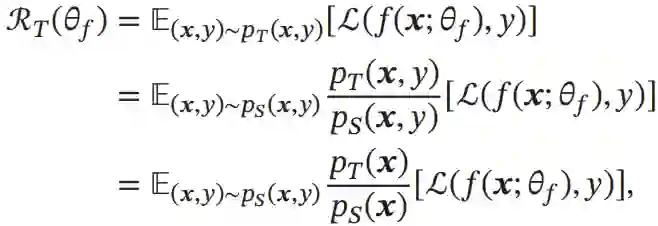
其中L(·)为损失函数,θf为模型参数。
如果我们可以学习一个映射函数g:X→Rd,将x映射到一个特征空间中,并在这个特征空间中使得源领域和目标领域的边际分布相同pS(g(x;θg))=pT(g(x;θg)),∀x∈X,其中θg为映射函数的参数,那么目标函数可以近似为:
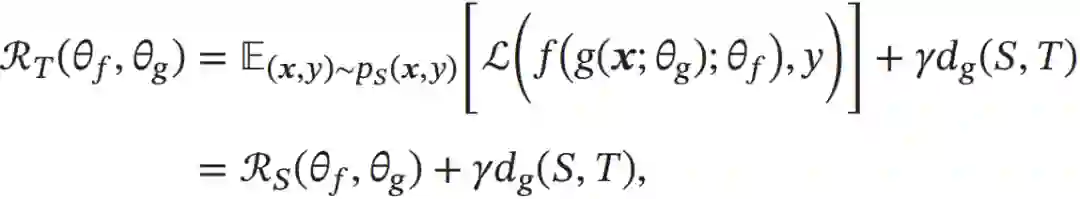
其中RS(θf,θg)为源领域上的期望风险函数,dg(S,T)是一个分布差异的度量函数,用来计算在映射特征空间中源领域和目标领域的样本分布的距离,γ为一个超参数,用来平衡两个子目标的重要性比例。这样,学习的目标是优化参数θf,θg使得提取的特征是领域无关的,并且在源领域上损失最小。
令
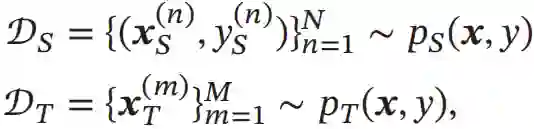
分别为源领域和目标领域的训练数据,我们首先用映射函数g(x,θg)将两个领域中训练样本的输入x映射到特征空间,并优化参数θg使得映射后两个领域的输入分布差异最小。分布差异一般可以通过一些度量函数来计算,比如 MMD (Maximum Mean Discrepancy)[Gretton et al., 2007]、CMD(Central Moment Discrepancy)[Zellinger et al., 2017]等,也可以通过领域对抗学习来得到领域无关的表示 [Bousmalis et al., 2016; Ganin et al., 2016]。
以对抗学习为例,我们可以引入一个领域判别器c来判断一个样本是来自于哪个领域。如果领域判别器c无法判断一个映射特征的领域信息,就可以认为这个特征是一种领域无关的表示。
对于训练集中的每一个样本x,我们都赋予z∈{1,0}表示它是来自于源领域还是目标领域,领域判别器c(h,θc)根据其映射特征h=g(x,θg)来预测它来自于源领域的概率p(z=1|x)。由于领域判别是一个两分类问题,h来自于目标领域的概率为1-c(h,θc)。
因此,领域判别器的损失函数为:
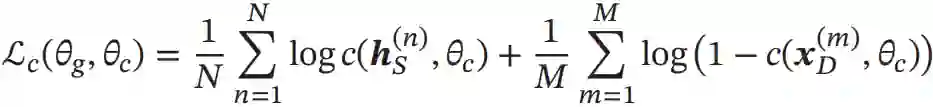
其中hS(n)=g(xS(n),θg),hD(m)=g(xD(m),θg) 分别为样本xS(n)和xD(m)的特征向量。
这样,领域迁移的目标函数可以分解为两个对抗的目标。一方面,要学习参数θc使得领域判别器c(h,θc)尽可能区分出一个表示h=g(x,θg)是来自于哪个领域;另一方面,要学习参数θg使得提取的表示h无法被领域判别器c(h,θc)预测出来,并同时学习参数θf使得模型f(h;θf)在源领域的损失最小。
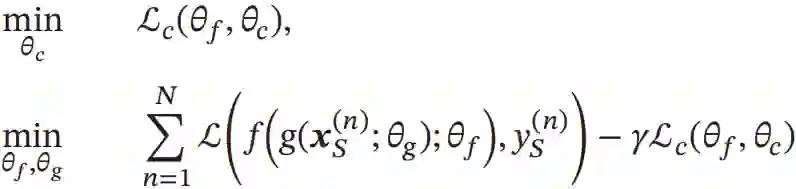
03
目前,神经网络的学习机制主要是以监督学习为主,这种学习方式得到的模型往往是任务定向的,也是孤立的。每个任务的模型都是从零开始来训练的,一切知识都需要从训练数据中得到,导致每个任务都需要大量的训练数据。这种学习方式和人脑的学习方式是不同的,人脑的学习一般不需要太多的标注数据,并且是一种持续的学习,可以通过记忆不断地累积学习到的知识。本文主要介绍了俩种和模型无关的学习方式:
多任务学习是一种利用多个相关任务来提高模型泛化性的方法,可以参考文献[Caruana, 1997; Zhang et al., 2017]。
迁移学习是研究如何将在一个领域上训练的模型迁移到新的领域,使得新模型不用从零开始学习。但在迁移学习中需要避免将领域相关的特征迁移到新的领域 [Ganin et al., 2016; Pan et al., 2010]。迁移学习的一个主要研究问题是领域适应[Ben-David et al., 2010; Zhang et al., 2013]。
今天的分享就到这里,谢谢大家。
——本文摘自邱锡鹏教授新书《神经网络与深度学习》,经出版方授权发布。
如果您喜欢本文,欢迎点击右上角,把文章分享到朋友圈~~
社群推荐:
欢迎加入 DataFunTalk NLP 交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:datafun-coco ),回复:NLP,逃课儿会自动拉你进群。
04

福利时间:《神经网络与深度学习》——豆瓣评分9.5!复旦大学邱锡鹏教授力作,周志华、李航联袂推荐,深受好评的深度学习讲义“蒲公英书”正式版!系统整理深度学习的知识体系,由浅入深地阐述深度学习的原理、模型以及方法。更适合中文读者自学与入门的深度学习图书!使你掌握神经网络与深度学习技术的基本原理,知其然也知其所以然。上市不到一周即荣登京东和当当新书榜榜首!
本期活动为大家带来5本正版新书。在本文评论中回复谈谈你对邱教授这本蒲公英书的理解,2020年6月4日20点前,评论点赞数前5名的读者将获赠正版图书1本。没中奖的读者也可以点击下方链接购买。赠书由机械工业出版社华章公司提供,在此表示感谢。

作者介绍
▬
邱锡鹏,复旦大学计算机科学技术学院教授、博士生导师,于复旦大学获得理学学士和博士学位。主要研究领域包括自然语言处理、机器学习、深度学习等,在相关领域的权威国际期刊、会议上发表学术论文60余篇,获得计算语言学顶级国际会议ACL 2017杰出论文奖、全国计算语言学会议CCL 2019最佳论文奖,2015年入选首届中国科协青年人才托举工程,2018年获得中国中文信息学会“钱伟长中文信息处理科学技术奖青年创新一等奖”,入选由“清华—中国工程院知识智能联合研究中心和清华大学人工智能研究院”联合发布的2020年人工智能(AI)全球最具影响力学者提名。该排名参考过去十年人工智能各子领域最有影响力的会议和期刊发表论文的引用情况,排名前10的学者当选该领域当年最具影响力学者奖,排名前100的其他学者获最具影响力学者提名奖。作为项目负责人开源发布了两个自然语言处理开源系统FudanNLP和FastNLP,获得了学术界和产业界的广泛使用。目前担任中国中文信息学会青年工作委员会执行委员、计算语言学专委会委员、语言与知识计算专委会委员,中国人工智能学会青年工作委员会常务委员、自然语言理解专委会委员。
参考文献:
PS:详细参考文献请查阅原书
1.Caruana R. Multi-task learning[J]. Machine Learning, 1997, 28(1):41-75.
2.Chen Z, Liu B. Lifelong machine learning[J]. Synthesis Lectures on Artificial Intelligence and Machine Learning, 2016, 10(3):1-145.
3.Deng J, Dong W, Socher R, et al. Imagenet: A large-scale hierarchical image database[C]//Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009: 248-255.
4.Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
5.Finn C, Abbeel P, Levine S. Model-agnostic meta-learning for fast adaptation of deep networks[C]//Proceedings of the 34th International Conference on Machine Learning-Volume 70. JMLR. org, 2017: 1126-1135.
6.French R M. Catastrophic forgetting in connectionist networks[J]. Trends in cognitive sciences, 1999, 3(4):128-135.
7.Freund Y, Schapire R E, et al. Experiments with a new boosting algorithm[C]//Proceedings of the International Conference on Machine Learning: volume 96. 1996: 148-156.
8.Friedman J, Hastie T, Tibshirani R, et al. Additive logistic regression: a statistical view of boosting [J]. The annals of statistics, 2000, 28(2):337-407.
9.Ganin Y, Ustinova E, Ajakan H, et al. Domain-adversarial training of neural networks[J]. Journal of Machine Learning Research, 2016, 17(59):1-35.
关于我们:

点击【阅读原文】了解更多 AI 好书!
一个在看,一段时光!👇


