迁移学习全面指南:概念、应用、优势、挑战
【编者按】Springboard AI顾问、前Intel数据科学家Dipanjan (DJ) Sarkar全面介绍了迁移学习的概念、应用、优势、挑战,重点关注深度迁移学习。

导言
人类具备在任务间迁移知识的内在能力。我们在学习一件任务时获取的知识,可以用来解决相关任务。任务越是相关,我们迁移(交叉应用我们的知识)起来就越容易。一些简单的例子:
知道如何骑自行车,学习如何开车。
知道如何弹奏古典钢琴,学习如何弹奏爵士钢琴。
知道数学和统计学,学习机器学习。

在上面每个场景中,我们试图学习新的方面和新的主题时都不用一切从头学起。我们迁移和利用过去学到的知识!
目前而言,传统机器学习和深度学习算法传统上是设计用于独立工作的。这些算法被训练来解决特定任务。一旦特征空间分布改变,模型需要从头开始。迁移学习的想法是超越这一孤立学习范式,利用从一项任务中获取的知识解决相关的任务。在这篇文章中,我们将全面介绍这些概念以及迁移学习的真实世界应用,甚至还将展示一些可以上手的例子。具体而言,我们将介绍以下内容:
迁移学习的动机
理解迁移学习
迁移学习策略
用于深度学习的迁移学习
深度迁移学习策略
深度迁移学习类型
迁移学习应用
案例研究一:数据可用性限制下的图像分类
案例研究二:大量分类、少量可用数据情况下的多类细粒度图像分类
迁移学习优势
迁移学习挑战
结语和后续预告
我们将介绍一般高层概念意义上的迁移学习(机器学习和统计建模的时代就有这一概念),不过,本文将重点介绍深度学习。
注意:这里的案例研究将包括逐步的细节(代码和输出),这些都是基于实际的试验得到。我们在编写Hands on Transfer Learning with Python一书(详见文末)的过程中实现并测试了这些模型。
网上关于迁移学习的信息极多,本文的目标是在介绍理论概念的同时演示可供实际上手的深度学习应用的例子。所有的例子均基于keras框架(tensorflow后端),这个框架既适合老手,也适合刚开始深度学习的人!对PyTorch感兴趣?欢迎转换这些例子,并联系我,我会在这里和GitHub上列出你的工作。
迁移学习的动机
我们已经简单讨论了人类并不从头学习每件事情,而能迁移之前领域所学至新领域和任务。由于真通用人工智能的一时狂热,数据科学家和研究人员相信迁移学习可以进一步推动AGI。事实上,著名教授和数据科学家吴恩达(涉及Google Brain、百度、斯坦福、Coursera)在NIPS 2016上给过一个超棒的演讲,Nuts and bolts of building AI applications using Deep Learning,其中他提到:
监督学习之后——迁移学习将是ML商业成功的下一个驱动者。
我推荐感兴趣的读者观看他在NIPS 2016上讲的有趣教程:
https://youtu.be/wjqaz6m42wU
如访问YouTube遇到问题,可在论智公众号(ID: jqr_AI)留言AndrewNg获取下载地址。
事实上,迁移学习不是21世纪10年代才出现的概念。NIPS 1995工作坊Learning to Learn: Knowledge Consolidation and Transfer in Inductive Systems被认为提供了这一领域研究的初始动机。至此以后,Learining to Learn(元学习)、Knowledge Consolidation(知识巩固)、Inductive Transfer(推导迁移)和迁移学习(transfer searning)可以互换使用。一如既往,不同的研究人员和学术文本基于不同的上下文给出了不同的定义。Goodfellow等所著知名的《Deep Learning》(深度学习)一书,在讨论概括性的上下文环境中提到了迁移学习。他们的定义如下:
利用一种设置下已经学到的情况,以提升另一设置的概括性。
因此,迁移学习的关键动机,特别是考虑深度学习这一上下文,在于大多数解决复杂问题的模型需要大量数据,然而,考虑到标注数据点所需的时间和精力,监督模型获取大量标注数据可能真的很困难。一个简单的例子是ImageNet数据集,其中包括几百万张预训练为不同类别的图像,感谢斯坦福多年来的艰辛努力!

然而,在每个领域中获得这样的数据集很难。此外,大多数深度学习模型为一个具体领域甚至一项特定任务专门化,尽管这些也许是当前最佳模型,精确性非常高,战胜了一切基准,但仅仅是在一些特定数据集上如此。用于新任务时,这些模型的表现会有显著下降,而新任务也许仍和训练模型的任务相似。这形成了迁移学习的动机,超越特定任务和领域,试图找到一种方法,利用从预训练模型中取得的知识解决新问题!
理解迁移学习
首先,迁移学习并不是一个深度学习特定的新概念。它在构建、训练机器模型的传统方法,和使用遵循迁移学习原则的方法论之间,有着鲜明的不同。
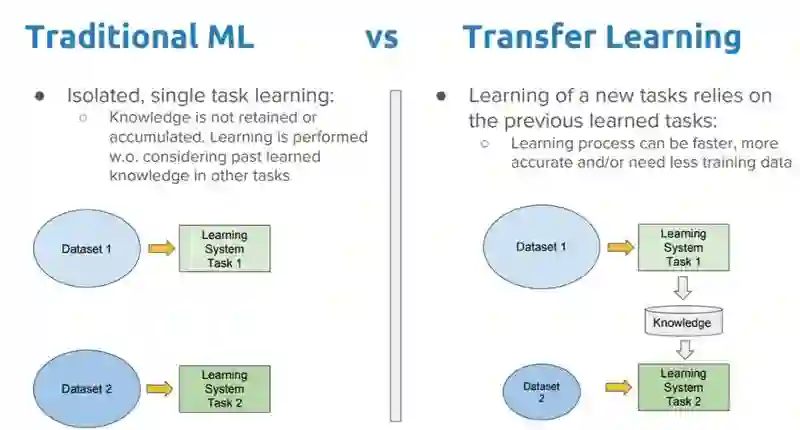
传统方法是孤立的,纯粹基于特定任务、数据集训练孤立模型。没有保留可以从一个模型迁移到另一个模型的任何知识。在迁移学习中,你可以利用之前训练的模型中得到知识(特征、权重等),训练新模型,甚至可以应对新任务数据较少的问题。
让我们通过一个例子更好地理解前面的解释。假定我们的任务是识别图像中的物体(领域限定为餐馆)。我们将这一任务记为T1。给定这一任务的数据集,我们训练一个模型,并加以调试,使其在相同领域(餐馆)的未见数据点上表现良好(推广)。当我们不具备给定领域任务所需的足够训练样本时,传统的监督ML算法无法工作。假定我们现在需要检测公园或咖啡馆图像中的物体(记为T2)。理想情况下,我们应该能够应用为T1训练的模型,但在现实中,我们会面临表现退化和模型概括性不好的问题。这背后有多种原因,大多数情况下可以归纳为模型在训练数据和领域上的偏差。
迁移学习应该让我们可以利用之前学习任务所得的知识,并应用于新的相关任务。如果我们在任务T1上明显有更多数据,我们可以利用其所学,并推广这一知识(特征、权重)至任务T2(明显数据更少)。在计算机视觉领域,边缘、形状、角落、亮度之类特定的低层特征可以在任务间分享,从而使得任务间的知识迁移成为可能!同样,如同之前图中所示,在学习新的目标任务时,现有任务中的知识可以作为额外输入。
形式化定义
现在让我们看下迁移学习的形式化定义,再用它来理解不同的策略。Pan和Yang的论文A Survey on Transfer Learning(迁移学习调研)使用领域、任务、边缘概率表示用来理解迁移学习的框架。该框架定义如下:
领域D定义为由特征空间𝜒和边缘概率P(X)组成的双元素元组,其中X是样本数据点。因此,在数学上,我们可以将该领域表示为D = {𝜒, P(X)}。xi表示𝜒内的一个特征向量。
另一方面,任务T可以定义为由标签空间γ和目标函数η组成的双元素元组。就概率学的角度而言,目标函数也可记为P(γ|X)。
基于以上定义和表示,我们可以如此定义迁移学习:
给定源领域DS、相应的源任务TS,及目标领域DT和目标任务TT,迁移学习的目标是让我们基于DS和TS中所得的信息学习DT中的目标条件概率分布P(YT|XT),且DS ≠ DT或TS ≠ TT。在大多数情形下,我们假定可以得到的标注目标样本的数目有限,比标注源样本要指数级地少。
以上定义摘自Sebastian Ruder的文章:http://ruder.io/transfer-learning/
场景
根据之前的定义,现在让我们看下迁移学习的典型场景:
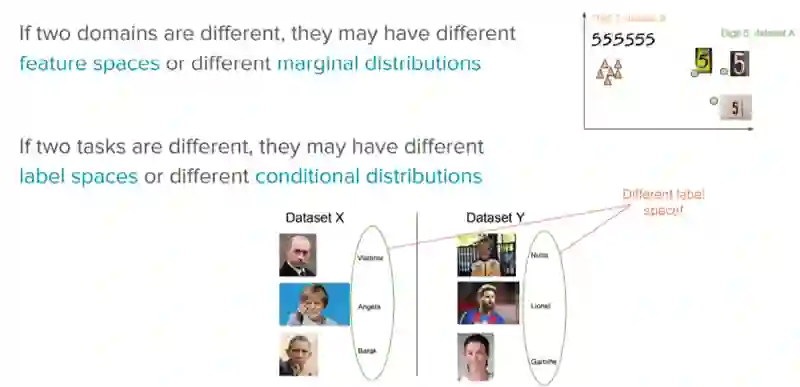
𝜒S ≠ ** 𝜒T** 源领域和目标领域的特征空间不一样,例如,用两种语言书写的文档。
P(XS) ≠ P(XT) 源领域和目标领域的边缘概率分布不一样,例如,讨论不同主题的文档。
𝛶S ≠ 𝛶T两个任务的标签空间不一样,例如,目标任务中给文档分配另一套不同于源任务的标签。在实践中,这个场景往往和下一个场景同时发生,这是因为,两个不同的任务有不同的标签空间,却有完全一致的条件概率分布,这种情况极为罕见。
P(YS|XS) ≠ P(YT|XT) 源任务和目标任务的条件概率分布不一样,例如,源文档和目标文档的分类不均衡。实践中这一场景相当常见,过采样、欠采样、SMOTE之类的方法在该场景下应用广泛。
关键点
在迁移学习的过程中,必须回答下面三个重要的问题:
迁移什么: 这是整个过程的第一步,也是最重要的一步。我们需要分清哪部分知识是来源特定的,哪部分是来源和目标之间共享的。
何时迁移: 可能有些场景下迁移知识并不会改善表现,反而会使事情更糟(也称为负迁移)。迁移学习的目标是改善目标任务的表现/结果,而不是劣化。我们需要小心什么时候迁移,什么时候不迁移。
如何迁移: 当我们搞明白迁移什么还有何时迁移后,我们就可以进一步确定在领域/任务间实际迁移知识的方式了。本文后面的部分会详细介绍这部分内容。
迁移学习策略
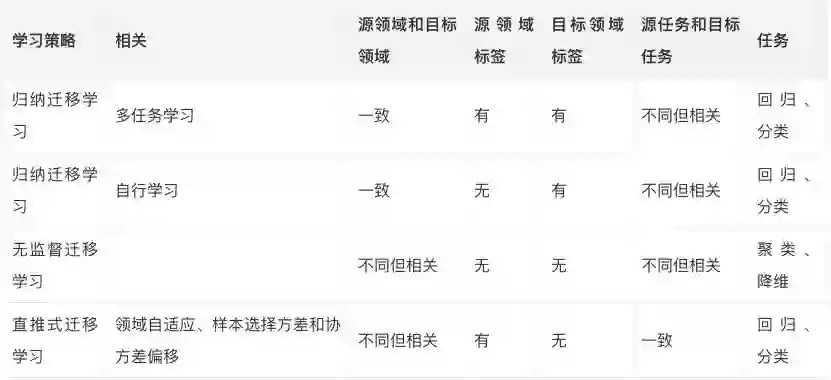
根据领域、任务、数据可用性,我们可以选择不同的迁移策略和技术,详见下图(摘自我们之前提到的论文A Survey on Transfer Learning)。
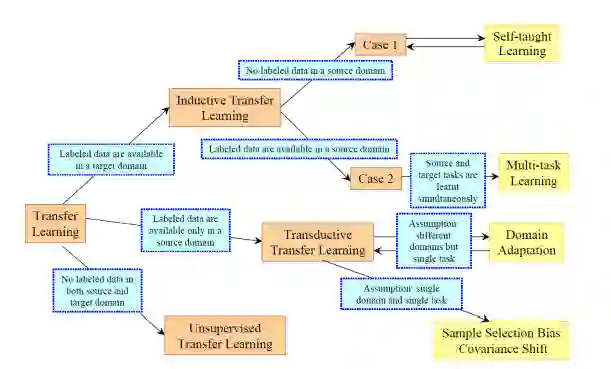
我们可以从这张示意图看到,迁移学习可以归为三类:
归纳迁移学习: 源领域和目标领域一致,而源任务和目标任务不同。取决于源领域是否包含标注数据,可以进一步划分为两个子类别:多任务学习和自行学习。
无监督迁移学习: 和归纳迁移学习一样,领域一致,任务不同。只不过源领域和目标领域都没有标注数据。
直推式迁移学习: 源任务和目标任务相似,但相应的领域不同。源任务有大量标注数据,而目标领域没有标注数据。这一类别可以进一步分为特征空间不同和边缘概率分布不同两种子类别。
下表总结了上面三个类别的不同点:
从迁移什么的角度,迁移学习可以分为以下类别:
实例迁移 在目标任务中复用源领域的知识通常属于理想场景。在大多数情形下,源领域数据无法直接复用。相反,源领域中的一些具体实例可以用来改进目标任务的结果。比如,Dai等提出AdaBoost扩展TrAdaBoost就属于这一类。
特征表示迁移 通过识别可以用于目标领域的良好特征表示,最小化领域散度并降低误差率。取决于标注数据的可用性,可以应用监督或无监督方法进行特征表示迁移。
参数迁移 相关任务的模型可能共享一些参数或者超参数的先验分布。这和多任务学习不同,多任务学习同时学习源任务和目标任务,而在参数迁移中,我们可以对目标领域的损失函数应用额外的权重,以改善总体表现。
关系知识迁移 和上面三类不同,关系知识迁移试图处理非IID(非独立同分布)数据。例如,社交网络数据可以利用关系知识迁移技术。
下表总结了上述两种分类系统之间的关系:

下面,我们将这些对迁移学习的理解应用于深度学习背景。
用于深度学习的迁移学习
DL下的深度学习
流言: 除非你的问题有一百万标注数据,你无法进行深度学习。
现实
你可以从未标注数据学习有用的表示。
你可以基于易于生成标签的相邻的代理目标训练。
你可以从相关任务迁移学习到的表示。
深度学习模型属于归纳学习的代表。归纳学习算法的目标是从一组训练样本中推断出映射关系。例如,在分类情形下,模型学习输入特征到分类标签之间的映射。这样的学习器要想很好地推广到未见数据上,它的算法需要遵循和训练数据分布相关的一些假定。这些假定称为归纳偏差。归纳偏差或假定可以通过多种因素体现,例如受限的假设空间,还有在假设空间中的搜索过程。因此,这些偏差会影响给定任务和领域上的模型如何学习和学习什么。
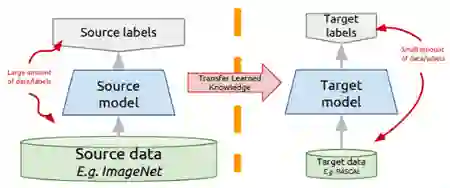
迁移学习:思路
不必为你的任务从头训练一个深度网络,相反,你可以:
选取一个在不同领域为不同的源任务训练的网络
使其适应目标领域和目标任务。
变体:
领域相同,任务不同
领域不同,任务相同
归纳迁移学习利用源任务的偏差帮助完成目标任务。这可以通过不同方式实现,例如调整目标任务的归纳偏差,限制模型空间,收紧假设空间,调整搜索过程本身。
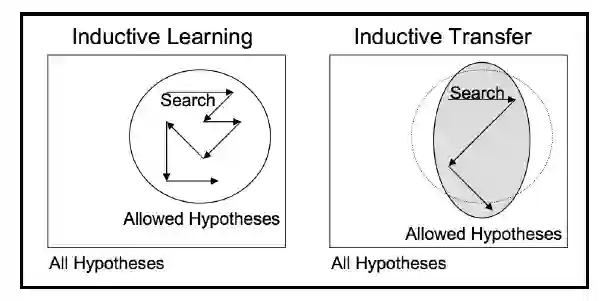
归纳迁移之外,归纳学习算法同样利用贝叶斯和层次化迁移技术,帮助改善目标任务的学习和表现。
深度迁移学习策略
近年来,深度学习取得了显著的进展,让我们可以处理复杂问题,得到惊人结果。然而,深度学习系统所需的训练时间和数据量比传统ML系统要多得多。人们在计算机视觉和自然语言处理(NLP)等领域开发、测试了各种取得当前最优表现(有时和人类表现相当甚至超过人类表现)的深度学习网络。大多数情况下,开发者会分享这些网络的细节,供他人使用。这些预训练网络/模型形成了深度学习环境中迁移学习(深度迁移学习)的基础。让我们看下深度迁移学习的两种最流行的策略。
作为特征提取器的现成预训练模型
深度学习系统和模型属于层叠架构,在不同层学习不同的特征。接着这些层最后连接最终层(在监督学习情形下通常是一个全连接层)以得到最终输出。这样的层叠架构让我们可以利用Inception V3或VGG之类的预训练网络,去其最终层,将其作为固定的特征提取器,用于其他任务。
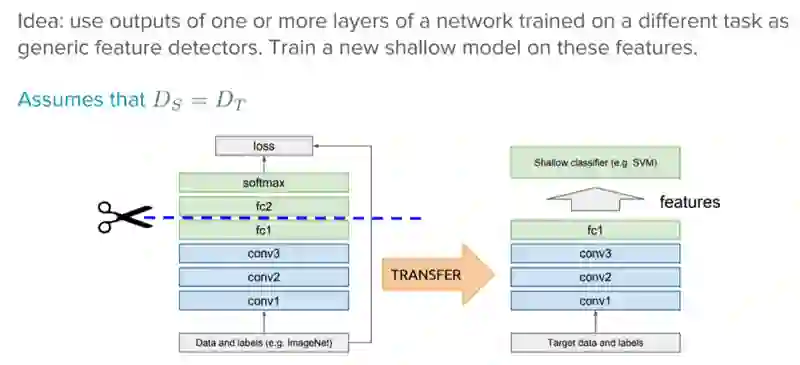
这一想法的关键在于只使用预训练模型的权重层提取特征,在为新任务训练新数据的时候不更新这些预训练层。
例如,如果我们使用不带最终分类层的AlexNet,它会基于其隐藏状态帮助我们将新领域任务中的图像转换为4096维的向量,从而让我们可以利用源领域任务的知识,提取新领域任务的特征。基于深度神经网络进行迁移学习时,这是使用最广泛的方法之一。
现在你可能会产生一个疑问,在实践中,这些预训练的现成特征提取器在不同任务上的表现如何?

毫无疑问,在现实世界任务中,这种做法效果真的很好。如果嫌上面的图不够清楚,那么我们放大一下上图右侧的比较:
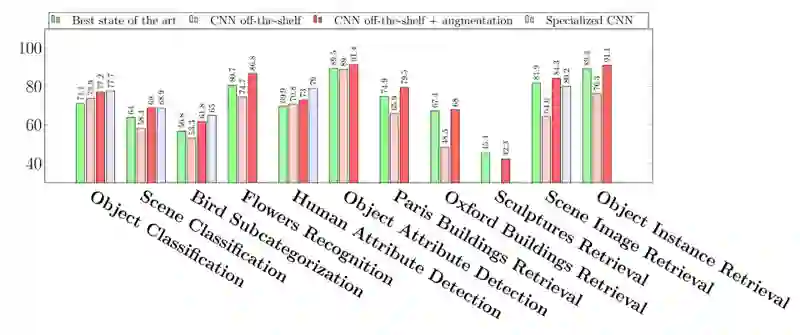
可以看到,在不同的计算机视觉任务中,预训练模型的表现都非常出色。
微调现成预训练模型
这里我们并不仅仅替换最终的分类/回归层,同时还选择性地重新训练之前的一些层。深度神经网络是高度可配置架构,有各种超参数。如前所述,前面的层捕捉通用特征,后面的层更关注手头的特定任务。比如,在下图的人脸识别问题中,前面的低层学习很通用的特征,而高层则学习任务特定的特征。
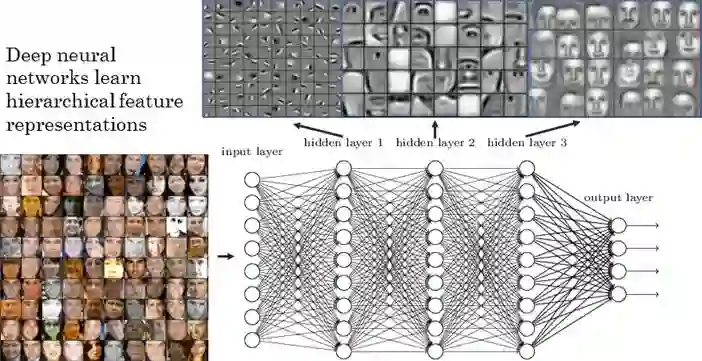
基于这一洞见,我们在重新训练时可以冻结(固定权重)特定层,微调剩余层以匹配我们的需求。在这一情形下,我们利用了网络总体架构的知识,并将其状态作为重训步骤的开始。这有助我们在更短的时间内取得更好的表现。

冻结还是微调?
这就带来一个问题,我们应该冻结网络层将它们作为特征提取器呢,还是应该同时微调网络层呢?
这取决于目标任务。如果目标任务的标签匮乏,而且我们希望避免过拟合,那就冻结。相反,如果目标任务的标签更丰富,那就微调。一般而言,我们可以通过给不同层设置不同的学习率找到冻结和微调之间的折衷。
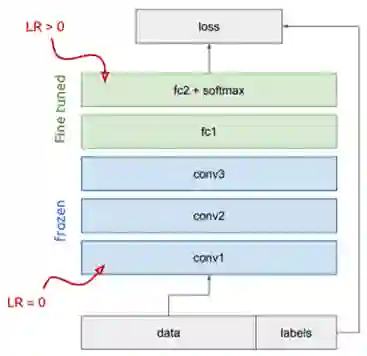
预训练模型
迁移学习的基础需求之一是有在源任务上表现良好的模型。幸运的是,深度学习世界相信分享。许多不同领域的当前最先进的深度学习架构被相关团队开放分享,例如计算机视觉和NLP,深度学习应用最流行的两个领域。预训练模型通常以百万参数/权重的形式分享,这些参数/权重是模型训练至稳定状态后取得的。每个人都可以通过不同方式使用预训练模型。著名的深度学习Python库keras,提供了下载一些流行的模型的接口。你也可以通过网络获取预训练模型,因为大多数模型是开源的。
计算机视觉的一些流行模型:
VGG-16
VGG-19
Inception V3
Xception
ResNet-50
自然语言处理任务的一些词嵌入模型:
Word2Vec
GloVe
FastText
最近,NLP迁移学习方面有一些非常优秀的进展,其中最著名的是Google的普适句编码器和BERT。
这两个进展很有潜力,我非常确定真实世界应用很快就会广泛采用。
深度迁移学习类型
迁移学习方面的文献经过了多次迭代,如前所述,相关的术语比较随意,经常可以互相替换。因此,有时候要区分迁移学习、领域自适应、多任务学习挺让人迷惑的。放轻松,这些都是相关的术语,试图解决类似的问题。一般来说,你应该总是将迁移学习看成一般概念或原则,试图使用源任务-领域的知识解决目标任务。
领域自适应
通常,领域自适应指源领域和目标领域的边缘概率不同的场景。源领域和目标领域数据分布的内在偏移,意味着我们需要进行一些调整才能迁移学习。例如,标记为正面、负面的影评语料库和产品评论的情绪分析语料库是不一样的。在影评上训练的分类器在分类产品评论时会见到不同的分布。因此,这些场景下的迁移学习将使用领域自适应技术。
领域混淆
之前我们了解了不同的迁移学习策略,甚至讨论了从源领域/任务到目标领域/任务迁移什么,何时迁移,如何迁移。特别是,我们讨论了特征表示迁移如何有用。值得再次强调的是,深度学习网络的不同层捕捉了不同的特征。我们可以利用这一事实学习领域不变的特征,并提升它们在不同领域间的可迁移性。我们并不让模型学习任何表示,而是使两个领域的表示尽可能地接近。这可以通过直接对表示本身应用特定的预处理步骤达成。Baochen Sun、Jiashi Feng、Kate Saenko的论文Return of Frustratingly Easy Domain Adaptation(容易得要死的领域自适应的回归)讨论了其中一些技术,Ganin等的论文Domain-Adversarial Training of Neural Networks(神经网络的领域对抗训练)也讨论了这种提高表示相似性的技术。这一技术背后的基本思路是在源模型中加入另一个目标,通过混淆领域自身鼓励相似性。领域混淆正是由此得名。
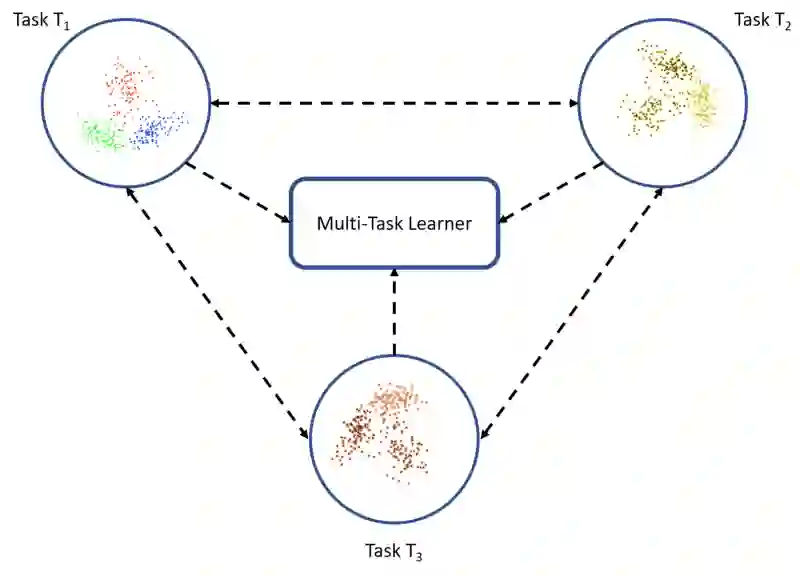
多任务学习
在迁移学习的世界中,多任务学习的调调有点不一样。在迁移学习情形下,同时学习多个任务,不区分源任务和目标任务。在这一情形下,学习器一下子从多个任务中接收信息,而在迁移学习中,学习器刚开始对目标任务一无所知。
单样本学习
深度学习系统对数据有着天然的饥渴,因为它们需要许多训练样本才能学习权重。这是深度神经网络的限制因素之一,尽管人类学习不存在这一问题。例如,一旦小孩知道了苹果是什么样的,他可以很容易地识别另一品种的苹果(只需一个或少量训练样本);而ML和深度学习算法就没有这个能力。单样本学习是迁移学习的一个变体,我们根据单个或少量训练样本尝试推理所需输出。在不可能为每个可能分类(假设这是一个分类任务)获取标注数据的真实世界场景下,以及经常加入新分类的场景下,单样本学习尤为有用。一般认为,李飞飞及其协作者的里程碑论文One Shot Learning of Object Categories(目标类别的单样本学习)创造了单样本学习这一术语,开启了单样本学习这一子领域的研究。该论文提出了一个贝叶斯框架的变体,用于目标类别的表示学习。后来人们改进了这一方法,并应用了深度学习系统。
零样本学习
零样本学习是迁移学习的又一极端变体,基于未标注数据学习一项任务。这也许听起来难以置信,如果这一方法真的有效,那将置大多数监督学习算法于何地?零数据学习或零样本学习方法在其训练阶段做了巧妙的调整,利用额外的信息来理解未见数据。Goodfellow等的《深度学习》一书是这样讲述零样本学习的:在这一场景下学习了三个变量,传统的输入变量x,传统的输出变量y,和一个描述任务的随机变量T。训练模型学习条件概率分布P(y|x,T)。在机器翻译这类的场景下,零样本学习很方便,因为我们可能甚至都没有目标语言中的标签。
迁移学习应用
毫无疑问,深度学习是从迁移学习中受益良多的算法类别。下面是一些例子:
NLP中的迁移学习: 对ML和深度学习而言,文本数据提出了各种各样的挑战。通常,我们使用不同的向量化技术转换文本。基于不同的训练数据集,我们得到了Word2Vec和FastText之类的嵌入。通过从源任务迁移知识,它们可以用于不同的任务,例如情绪分析和文档分类。除此之外,普适句编码器和BERT这类较新的模型毫无疑问地展现了未来的无穷可能。
音频/语言中的迁移学习: 类似NLP和计算机视觉,深度学习也在基于音频数据的任务中得到了广泛应用。例如,针对英语的自动语音识别(ASR)模型成功用于提升德语等其他语言的识别表现。自动识别说话人则是迁移学习大有助益的另一个例子。
计算机视觉中的迁移学习: 基于不同的CNN架构,深度学习在多种计算机视觉任务上的应用取得了相当大的成功。Yosinski及其协作者的论文How transferable are features in deep neural networks(深度神经网络中特征的迁移性如何)揭示了低层如何提取边缘等计算机视觉特征,最终层如何作用于任务特定的特征。因此,这些发现帮助我们在风格迁移和人脸识别等目标任务中利用VGG、AlexNet、Inception等现有的当前最先进模型,目标任务和这些模型原本训练的任务不同。
现在,让我们探索一些真实世界的案例,搭建一些深度迁移学习模型!
案例研究一:数据可用性限制下的图像分类
我们将在每个类别的训练样本量非常少的限制下处理一个图像分类问题。我们所用的数据集可以从Kaggle获取。
主要目标
我们将使用kaggle上非常流行的猫狗数据集:https://www.kaggle.com/c/dogs-vs-cats/data
我们的主要目标是创建一个可以成功辨识猫狗的深度学习模型。
图片来源:becominghuman.ai
用ML术语来说,这是一个基于图像的二元分类问题。在开始之前,我首先要感谢Francois Chollet,不仅是因为他创建了惊人的深度学习框架keras,还因为他在Deep Learning with Python一书中讨论了迁移学习在真实世界问题中的有效性。我在这里对迁移学习真实威力所作的描绘借鉴了Chollet书中的内容,所有的结果都是在我自己的GPU云(AWS p2.x)上得到的。
创建数据集
首先从上文提及的数据集页面下载train.zip,并解压为一个文件夹。该文件夹包含25000张猫狗图像,也就是说,每个类别有12500张图像。尽管我们可以使用所有25000张图像训练一些很好的模型,但是如果你没忘了的话,我们有一个附加限制,每个类别的图像数量很少。所以让我们为此创建自己的数据集。
import glob
import numpy as np
import os
import shutil
np.random.seed(42)
files = glob.glob('train/*')
cat_files = [fn for fn in files if 'cat' in fn]
dog_files = [fn for fn in files if 'dog' in fn]
len(cat_files), len(dog_files)
输出:
(12500, 12500)
看,我们可以确认每个类别有12500张图像。现在让我们创建小数据集,3000张图像用作训练集,1000张图像用作验证集,1000张图像用作测试集(每种动物类别的比例一致)。
cat_train = np.random.choice(cat_files, size=1500, replace=False)
dog_train = np.random.choice(dog_files, size=1500, replace=False)
cat_files = list(set(cat_files) - set(cat_train))
dog_files = list(set(dog_files) - set(dog_train))
cat_val = np.random.choice(cat_files, size=500, replace=False)
dog_val = np.random.choice(dog_files, size=500, replace=False)
cat_files = list(set(cat_files) - set(cat_val))
dog_files = list(set(dog_files) - set(dog_val))
cat_test = np.random.choice(cat_files, size=500, replace=False)
dog_test = np.random.choice(dog_files, size=500, replace=False)
print('Cat datasets:', cat_train.shape, cat_val.shape, cat_test.shape)
print('Dog datasets:', dog_train.shape, dog_val.shape, dog_test.shape)
输出:
Cat datasets: (1500,) (500,) (500,)
Dog datasets: (1500,) (500,) (500,)
创建好数据集之后,我们将其写入磁盘上不同的文件夹,以备日后使用。
train_dir = 'training_data'
val_dir = 'validation_data'
test_dir = 'test_data'
train_files = np.concatenate([cat_train, dog_train])
validate_files = np.concatenate([cat_val, dog_val])
test_files = np.concatenate([cat_test, dog_test])
os.mkdir(train_dir) if not os.path.isdir(train_dir) else None
os.mkdir(val_dir) if not os.path.isdir(val_dir) else None
os.mkdir(test_dir) if not os.path.isdir(test_dir) else None
for fn in train_files:
shutil.copy(fn, train_dir)
for fn in validate_files:
shutil.copy(fn, val_dir)
for fn in test_files:
shutil.copy(fn, test_dir)
由于这是一个图像分类问题,我们将使用CNN模型。我们将首先尝试从头搭建一个简单的CNN模型,接着尝试通过正则化和图像增强等技术改进结果。接下来,我们将尝试使用一个预训练模型,以释放迁移学习的真实力量。
预备数据集
在建模之前,先加载和预备好数据集。
import glob
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import ImageDataGenerator, load_img, img_to_array, array_to_img
%matplotlib inline
IMG_DIM = (150, 150)
train_files = glob.glob('training_data/*')
train_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in train_files]
train_imgs = np.array(train_imgs)
train_labels = [fn.split('\\')[1].split('.')[0].strip() for fn in train_files]
validation_files = glob.glob('validation_data/*')
validation_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in validation_files]
validation_imgs = np.array(validation_imgs)
validation_labels = [fn.split('\\')[1].split('.')[0].strip() for fn in validation_files]
print('Train dataset shape:', train_imgs.shape,
'\tValidation dataset shape:', validation_imgs.shape)
输出:
Train dataset shape: (3000, 150, 150, 3)
Validation dataset shape: (1000, 150, 150, 3)
很清楚,我们有3000张训练图像,1000张验证图像。每张图像的尺寸为150 × 150,共有三个通道(RGB),所以每张图像的维度为(150, 150, 3)。现在我们将每张图像的像素值从(0, 255)归一化至(0, 1),以便深度学习模型使用。
train_imgs_scaled = train_imgs.astype('float32')
validation_imgs_scaled = validation_imgs.astype('float32')
train_imgs_scaled /= 255
validation_imgs_scaled /= 255
print(train_imgs[0].shape)
array_to_img(train_imgs[0])

上面的输出显示了训练集中的一张样本图像。现在让我们设置一些基本配置参数,并将文本分类标签编码为数值:
batch_size = 30
num_classes = 2
epochs = 30
input_shape = (150, 150, 3)
# 编码文本类别标签
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(train_labels)
train_labels_enc = le.transform(train_labels)
validation_labels_enc = le.transform(validation_labels)
print(train_labels[1495:1505], train_labels_enc[1495:1505])
输出:
['cat', 'cat', 'cat', 'cat', 'cat', 'dog', 'dog', 'dog', 'dog', 'dog'] [0 0 0 0 0 1 1 1 1 1]
可以看到,我们的编码方案将cat(猫)标签赋值为0,dog(狗)标签赋值为1。一切就绪,我们可以开始构建第一个基于CNN的深度学习模型了。
从头构建的简单CNN模型
我们将从创建一个基本的CNN模型开始,它包括三个卷积层,搭配最大池化和下采样。
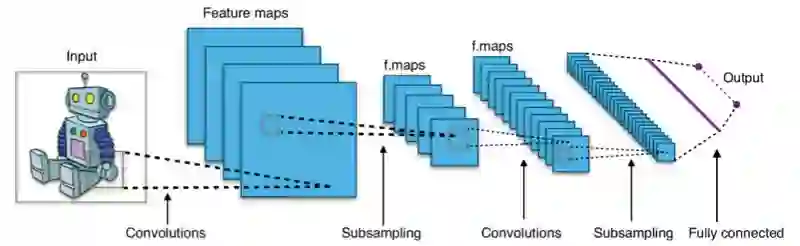
我们假定你具有足够多的关于CNN的知识,所以这里不会介绍其理论细节。欢迎参考我的书或网络上的其他资源了解卷积神经网络。现在让我们使用Keras搭建CNN模型。
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.models import Sequential
from keras import optimizers
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
model.summary()
输出:
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 148, 148, 16) 448
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 74, 74, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 72, 72, 64) 9280
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 34, 34, 128) 73856
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 17, 17, 128) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 36992) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 18940416
_________________________________________________________________
dense_2 (Dense) (None, 1) 513
=================================================================
Total params: 19,024,513
Trainable params: 19,024,513
Non-trainable params: 0
_________________________________________________________________
上面的输出显示了基本CNN模型的概况。如前所述,我们使用三个卷积层来提取特征。扁平层将第三个卷积层输出的128张17 × 17的特征映射图压平,传入密集层,以得到图像应该是狗(1)还是猫(0)的最终预测。下面让我们使用fit函数训练我们的模型:
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled, validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
简单解释下上面代码中涉及的一些重要术语:
batch_size指明每次迭代传给模型的图像数。
网络层单元的权重在每次迭代后更新。
迭代总数总是等于样本总数除以batch_size。
一个epoch指整个数据集在网络中训练过一次。
我们将batch_size设为30,而我们的训练数据共有3000个样本。这意味着每个epoch共有100次迭代。总共训练30个epoch,并在1000张图像的验证集上加以验证。
Train on 3000 samples, validate on 1000 samples
Epoch 1/30
3000/3000 - 10s - loss: 0.7583 - acc: 0.5627 - val_loss: 0.7182 - val_acc: 0.5520
Epoch 2/30
3000/3000 - 8s - loss: 0.6343 - acc: 0.6533 - val_loss: 0.5891 - val_acc: 0.7190
...
...
Epoch 29/30
3000/3000 - 8s - loss: 0.0314 - acc: 0.9950 - val_loss: 2.7014 - val_acc: 0.7140
Epoch 30/30
3000/3000 - 8s - loss: 0.0147 - acc: 0.9967 - val_loss: 2.4963 - val_acc: 0.7220
从训练精确度和验证精确度来看,我们的模型出现过拟合了。我们可以绘制出模型的精确度和损失曲线,这样看起来更清楚。
f, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
t = f.suptitle('Basic CNN Performance', fontsize=12)
f.subplots_adjust(top=0.85, wspace=0.3)
epoch_list = list(range(1,31))
ax1.plot(epoch_list, history.history['acc'], label='Train Accuracy')
ax1.plot(epoch_list, history.history['val_acc'], label='Validation Accuracy')
ax1.set_xticks(np.arange(0, 31, 5))
ax1.set_ylabel('Accuracy Value')
ax1.set_xlabel('Epoch')
ax1.set_title('Accuracy')
l1 = ax1.legend(loc="best")
ax2.plot(epoch_list, history.history['loss'], label='Train Loss')
ax2.plot(epoch_list, history.history['val_loss'], label='Validation Loss')
ax2.set_xticks(np.arange(0, 31, 5))
ax2.set_ylabel('Loss Value')
ax2.set_xlabel('Epoch')
ax2.set_title('Loss')
l2 = ax2.legend(loc="best")
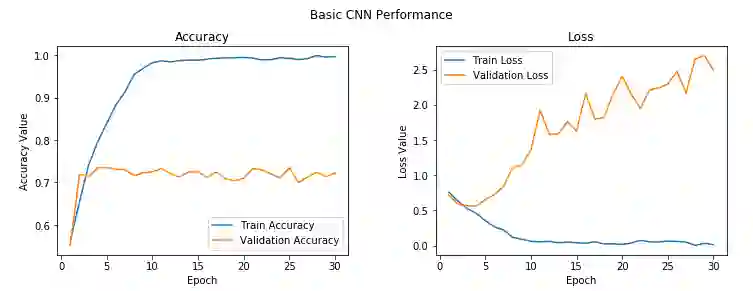
我们可以很清楚地看到,2-3个epoch之后,模型开始在训练数据上过拟合了。我们在验证集上得到的平均精确度是72%,这并不是一个糟糕的开始!我们能够改进模型吗?
带正则化的CNN模型
让我们再加一个卷积层,另一个密集隐藏层,改进下CNN模型。除此之外,我们将在每个隐藏密集层后加上0.3的dropout,引入一些正则化。dropout基本上是深度神经网络中正则化的强力方法。它可以分别应用于输入层和隐藏层。dropout随机掩码网络层的一部分单元的输出(归零)。我们加上的是0.3的dropout,也就是归零密集层中30%单元的输出。
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(),
metrics=['accuracy'])
history = model.fit(x=train_imgs_scaled, y=train_labels_enc,
validation_data=(validation_imgs_scaled, validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
输出:
Train on 3000 samples, validate on 1000 samples
Epoch 1/30
3000/3000 - 7s - loss: 0.6945 - acc: 0.5487 - val_loss: 0.7341 - val_acc: 0.5210
Epoch 2/30
3000/3000 - 7s - loss: 0.6601 - acc: 0.6047 - val_loss: 0.6308 - val_acc: 0.6480
...
...
Epoch 29/30
3000/3000 - 7s - loss: 0.0927 - acc: 0.9797 - val_loss: 1.1696 - val_acc: 0.7380
Epoch 30/30
3000/3000 - 7s - loss: 0.0975 - acc: 0.9803 - val_loss: 1.6790 - val_acc: 0.7840
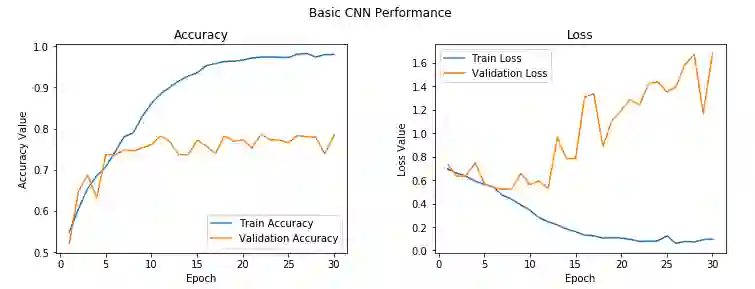
很明显,模型还是过拟合了,不过模型开始过拟合的时间要略微晚一点,78%的验证精确度也比原本的结果略微好一点。模型过拟合的原因是我们的训练数据太少了,模型在每个epoch中不断看到同样的样本。克服这一缺陷的一种方法是利用图像增强策略,使用现有图像的变体来增强现有的训练数据。在下一节我们将介绍这一方法的细节,现在让我们先保存模型,以待以后在测试数据上评估其表现。
model.save('cats_dogs_basic_cnn.h5')
搭配图像增强的CNN模型
让我们使用恰当的图像增强策略加入更多数据,改进我们的正则化CNN模型。由于之前的模型在相同的少量数据上训练,它无法很好地概括数据,最终在若干epoch后过拟合。图像增强背后的思路是我们对训练数据集中的现有图像进行一一些处理,例如旋转、裁切、翻转、缩放,等等,以生成新的调整过的现有图像。
Keras框架有一个出色的工具ImageDataGenerator可以帮助我们进行以上所有操作。
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3, rotation_range=50,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2,
horizontal_flip=True, fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
ImageDataGenerator提供了大量选项,我们只使用了其中一些。你可以查看文档了解更多细节。在我们的训练数据生成器中,我们对原始图像进行了一些转换,以生成新图像。这些操作包括:
使用zoom_range参数指定随机缩放图像,倍数为0.3。
使用rotation_range参数指定随机旋转图像50度。
使用width_shift_range和height_shift_range参数随机横向或纵向平移图像,平移量为宽度或高度的20%.
使用shear_range参数指定随机剪裁图像
使用horizontal_flip参数指定随机水平翻转一半图像。
使用fill_mode参数指定在应用上述操作(特别是翻转或平移)后填充新像素。这里我们根据相邻周边像素值填充新像素。
为了加深理解,让我们看下生成图像大概是什么样的。我们将从训练数据集中选取两张图像,第一张是猫图。
mg_id = 2595
cat_generator = train_datagen.flow(train_imgs[img_id:img_id+1], train_labels[img_id:img_id+1],
batch_size=1)
cat = [next(cat_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(16, 6))
print('Labels:', [item[1][0] for item in cat])
l = [ax[i].imshow(cat[i][0][0]) for i in range(0,5)]

我们为训练图像生成了新版本(平移、旋转、缩放)并分配了猫标签,这样模型可以从这些图像中提取相关特征,并记住这些是猫。现在让我们看下图像增强在狗图像上的效果。
img_id = 1991
dog_generator = train_datagen.flow(train_imgs[img_id:img_id+1], train_labels[img_id:img_id+1],
batch_size=1)
dog = [next(dog_generator) for i in range(0,5)]
fig, ax = plt.subplots(1,5, figsize=(15, 6))
print('Labels:', [item[1][0] for item in dog])
l = [ax[i].imshow(dog[i][0][0]) for i in range(0,5)]
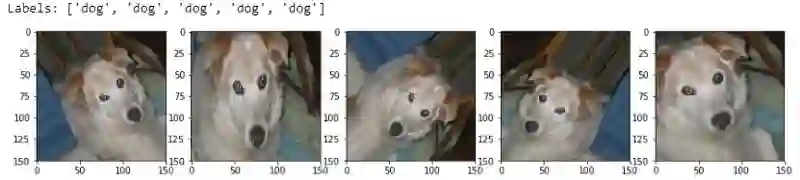
从上面的例子我们可以直观地感受到图像增强是怎么创建新图像的。图像增强应该能帮助缓解过拟合现象。由于我们只需将验证图像(原始图像)传给模型用作评估,所以我们在验证生成器中仅仅归一化了图像像素值(至0、1之间)而没有应用任何转换。我们只在训练图像上应用图像增强转换。现在让我们基于增强的图像训练模型,看看效果如何。
train_generator = train_datagen.flow(train_imgs, train_labels_enc, batch_size=30)
val_generator = val_datagen.flow(validation_imgs, validation_labels_enc, batch_size=20)
input_shape = (150, 150, 3)
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.models import Sequential
from keras import optimizers
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3), activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100,
validation_data=val_generator, validation_steps=50,
verbose=1)
我们仍然使用了之前的网络架构,但降低了优化器的默认学习率,并传入了大量随机变换的图像,以防模型陷入局部极小值或出现过拟合。由于我们现在使用数据生成器,所以需要对代码略作调整,才能训练模型。我们将使用keras的fit_generator函数训练模型。train_generator每次生成30张图像,所以我们将使用steps_per_epoch参数,并将其设为100,这样,每个epoch我们的模型将在3000张从训练数据中随机生成的图像上训练。val_generator每次生成20张图像,所以我们将validation_steps参数设为50,在所有1000张验证图像上验证模型的精确度(别忘了我们并没有增强验证数据集)。
Epoch 1/100
100/100 - 12s - loss: 0.6924 - acc: 0.5113 - val_loss: 0.6943 - val_acc: 0.5000
Epoch 2/100
100/100 - 11s - loss: 0.6855 - acc: 0.5490 - val_loss: 0.6711 - val_acc: 0.5780
Epoch 3/100
100/100 - 11s - loss: 0.6691 - acc: 0.5920 - val_loss: 0.6642 - val_acc: 0.5950
...
...
Epoch 99/100
100/100 - 11s - loss: 0.3735 - acc: 0.8367 - val_loss: 0.4425 - val_acc: 0.8340
Epoch 100/100
100/100 - 11s - loss: 0.3733 - acc: 0.8257 - val_loss: 0.4046 - val_acc: 0.8200
验证精确度提高到了82%,比之前的模型提高了近4-5%。另外,训练精确度和验证精确度相似,意味着模型不再过拟合了。
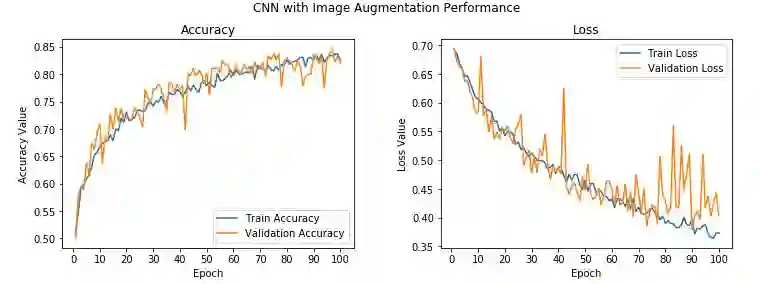
尽管验证精确度和验证损失还是有一些尖峰,总体上而言,它们接近训练精确度和训练损失,这意味着我们的模型比之前的概括性要好。同样,我们保存这一模型,以待以后在测试数据集上评估。
model.save('cats_dogs_cnn_img_aug.h5')
现在我们将尝试利用迁移学习的力量,看看能否创建一个更好的模型!
通过预训练CNN模型使用迁移学习
预训练模型的两种流行使用方式为:
使用预训练模型作为特征提取器
微调预训练模型
我们将在这一节介绍这两种做法的细节。我们使用的预训练模型是流行的VGG-16模型,该模型由牛津大学的Visual Geometry Group创建,是一个用于大规模视觉识别的深度卷积网络。
VGG-16这样的预训练模型是在具有大量多种图像类别的巨大数据集(ImageNet)上预训练过的模型。所以该模型应该已经学习到了健壮的层次特征,具备CNN模型特征学习的空间、旋转、平移不变性。因此,这个在归属1000个不同类别的一百万张图像上学习到良好的特征表示的模型,可以作为一个优秀的特征提取器,提取计算机视觉任务中的新图像的特征。这些新图像也许是ImageNet数据集中不存在的,或者也许属于完全不同的类别,但模型应该仍然能够从这些图像中提取相关特征。
使用预训练模型作为面向新图像的高效特征提取器,在解决多样、复杂的计算机视觉任务上给我们带来了优势,例如使用更少的图像创建猫狗分类器,创建狗品种分类器,创建面部表情分类器,等等!在我们的问题上释放迁移学习的威力之前,让我们先简要讨论下VGG-16的模型架构。
理解VGG-16模型
VGG-16模型是基于ImageNet数据集的16层(卷积层和全连接层)网络,用于图像识别和分类。该模型是由Karen Simonyan和Andrew Zisserman在他们的论文Very Deep Convolutional Networks for Large-Scale Image Recognition中提出的。我建议所有感兴趣的读者去阅读这篇杰出的论文。下为VGG-16模型的架构示意图。

从图中我们可以很清楚地看到一共有13个卷积层,使用3 × 3的卷积过滤器,搭配用于下采样的最大池化层,每层具有4096个单元的全连接隐藏层两层,后接一个具有1000个单元的密集层,其中每个单元表示ImageNet数据集中的一个图像类别。由于我们将使用自己的全连接密集层预测图像是猫还是狗,所以我们不需要最后三层。我们更关心前五块,以便将VGG模型作为高效的特征提取器使用。
在一个模型中,我们直接将VGG模型作为特征提取器使用,冻结所有五个卷积块,以确保它们的权重在每个epoch训练时不会更新。在另一个模型中,我们将对VGG模型进行微调,解冻最后两个块(块4和块5),这样在我们训练自己的模型的时候,它们的权重能在每个epoch训练时更新。
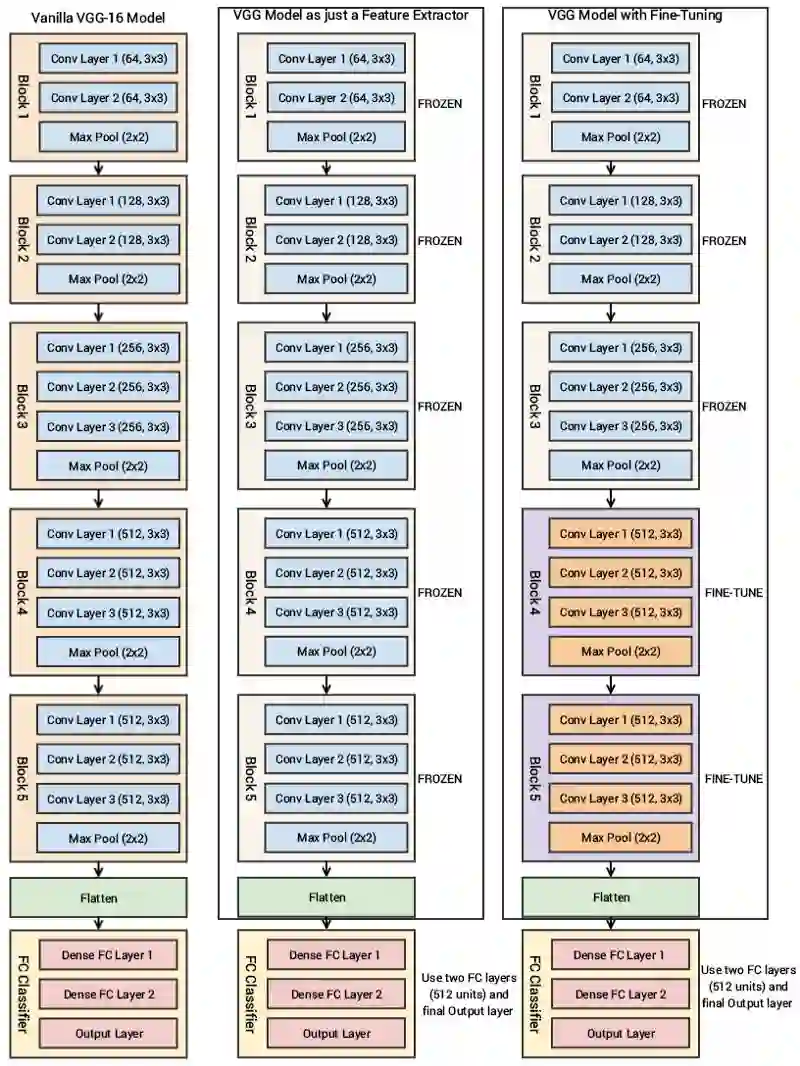
也就是说,我们使用VGG-16模型的卷积块,然后扁平化(来自特征映射)的最终输出,以便传入我们的分类器自己的密集层。
作为特征提取器的预训练CNN模型
让我们用Keras加载VGG-16模型,并冻结卷积块以直接作为图像特征提取器使用。
from keras.applications import vgg16
from keras.models import Model
import keras
vgg = vgg16.VGG16(include_top=False, weights='imagenet',
input_shape=input_shape)
output = vgg.layers[-1].output
output = keras.layers.Flatten()(output)
vgg_model = Model(vgg.input, output)
vgg_model.trainable = False
for layer in vgg_model.layers:
layer.trainable = False
import pandas as pd
pd.set_option('max_colwidth', -1)
layers = [(layer, layer.name, layer.trainable) for layer in vgg_model.layers]
pd.DataFrame(layers, columns=['Layer Type', 'Layer Name', 'Layer Trainable'])
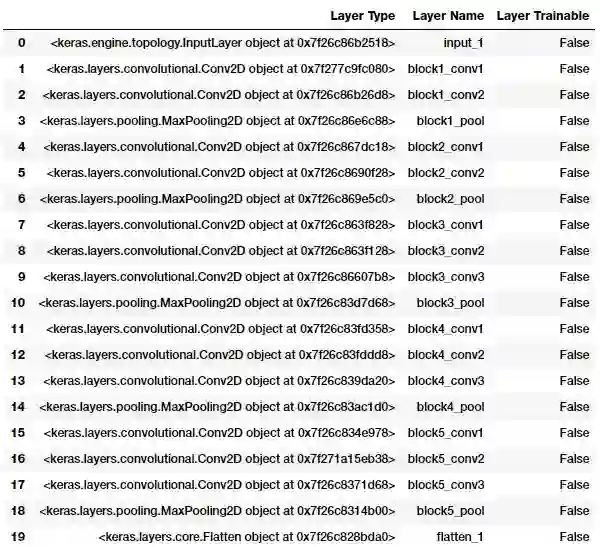
从上面的输出我们可以很清楚地看到,我们冻结了VGG-16模型的所有层,这很好,因为在模型训练过程中,我们不希望它们的权重发生变动。VGG-16模型最后的激活特征映射(block5_pool的输出)提供了瓶颈特征,这些特征经扁平化处理后可以传入全连接的深度神经网络分类器。下面的代码片段显示了训练数据集中某一样本图像的瓶颈特征。
bottleneck_feature_example = vgg.predict(train_imgs_scaled[0:1])
print(bottleneck_feature_example.shape)
plt.imshow(bottleneck_feature_example[0][:,:,0])
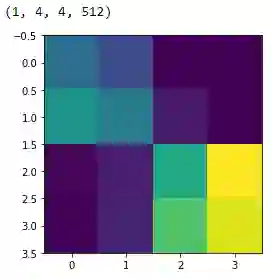
我们扁平化VGG模型的瓶颈特征以便传入全连接分类器。节省模型训练时间的一种方式是使用VGG模型提取训练集和验证集中的所有特征,将其作为输入传给我们的分类器。现在让我们提取训练集和验证集的瓶颈特征。
def get_bottleneck_features(model, input_imgs):
features = model.predict(input_imgs, verbose=0)
return features
train_features_vgg = get_bottleneck_features(vgg_model, train_imgs_scaled)
validation_features_vgg = get_bottleneck_features(vgg_model, validation_imgs_scaled)
print('Train Bottleneck Features:', train_features_vgg.shape,
'\tValidation Bottleneck Features:', validation_features_vgg.shape)
输出:
Train Bottleneck Features: (3000, 8192)
Validation Bottleneck Features: (1000, 8192)
上面的输出表明我们成功地提取了3000张训练图像和1000张验证图像的扁平化瓶颈特征(维度为1 × 8192)。现在让我们搭建深度神经网络分类器的架构,并将这些特征作为输入。
rom keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, InputLayer
from keras.models import Sequential
from keras import optimizers
input_shape = vgg_model.output_shape[1]
model = Sequential()
model.add(InputLayer(input_shape=(input_shape,)))
model.add(Dense(512, activation='relu', input_dim=input_shape))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['accuracy'])
model.summary()
输出:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_2 (InputLayer) (None, 8192) 0
_________________________________________________________________
dense_1 (Dense) (None, 512) 4194816
_________________________________________________________________
dropout_1 (Dropout) (None, 512) 0
_________________________________________________________________
dense_2 (Dense) (None, 512) 262656
_________________________________________________________________
dropout_2 (Dropout) (None, 512) 0
_________________________________________________________________
dense_3 (Dense) (None, 1) 513
=================================================================
Total params: 4,457,985
Trainable params: 4,457,985
Non-trainable params: 0
_________________________________________________________________
如前所述,长度为8192的瓶颈特征向量作为分类模型的输入,密集层的架构和之前的模型一样。现在让我们开始训练模型。
history = model.fit(x=train_features_vgg, y=train_labels_enc,
validation_data=(validation_features_vgg, validation_labels_enc),
batch_size=batch_size,
epochs=epochs,
verbose=1)
输出:
Train on 3000 samples, validate on 1000 samples
Epoch 1/30
3000/3000 - 1s 373us/step - loss: 0.4325 - acc: 0.7897 - val_loss: 0.2958 - val_acc: 0.8730
Epoch 2/30
3000/3000 - 1s 286us/step - loss: 0.2857 - acc: 0.8783 - val_loss: 0.3294 - val_acc: 0.8530
Epoch 3/30
3000/3000 - 1s 289us/step - loss: 0.2353 - acc: 0.9043 - val_loss: 0.2708 - val_acc: 0.8700
...
...
Epoch 29/30
3000/3000 - 1s 287us/step - loss: 0.0121 - acc: 0.9943 - val_loss: 0.7760 - val_acc: 0.8930
Epoch 30/30
3000/3000 - 1s 287us/step - loss: 0.0102 - acc: 0.9987 - val_loss: 0.8344 - val_acc: 0.8720
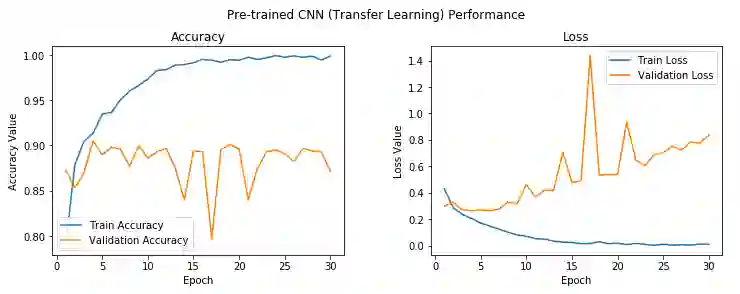
模型的验证精确度接近88%,比之前的搭配图像增强的基本CNN模型提升了近5-6%,这很好。不过我们的模型看起来还是过拟合了。第五个epoch后,模型的训练精确度和验证精确度差距很大。不过总体上来说,看起来这是我们目前为止得到的最佳模型。下面让我们尝试下在这个模型上加上图像增强。不过,在此之前,先将模型保存到磁盘。
model.save('cats_dogs_tlearn_basic_cnn.h5')
搭配图像增强的作为特征提取器的预训练CNN模型
我们将在训练集和验证集上使用和之前一样的数据生成器:
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3, rotation_range=50,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2,
horizontal_flip=True, fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow(train_imgs, train_labels_enc, batch_size=30)
val_generator = val_datagen.flow(validation_imgs, validation_labels_enc, batch_size=20)
现在让我们创建深度学习模型并训练它。这次我们不会提取瓶颈特征,因为我们将在数据生成器上训练。因此,我们将vgg_model对象作为输入传给我们的模型。我们也略微调低了学习率,因为我们将训练100个epoch,不想让模型网络层出现任何突然的权重调整。别忘了VGG-16模型的层仍然是冻结的,我们仅仅将它作为基本的特征提取器使用。
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, InputLayer
from keras.models import Sequential
from keras import optimizers
model = Sequential()
model.add(vgg_model)
model.add(Dense(512, activation='relu', input_dim=input_shape))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=2e-5),
metrics=['accuracy'])
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100,
validation_data=val_generator, validation_steps=50,
verbose=1)
输出:
Epoch 1/100
100/100 - 45s 449ms/step - loss: 0.6511 - acc: 0.6153 - val_loss: 0.5147 - val_acc: 0.7840
Epoch 2/100
100/100 - 41s 414ms/step - loss: 0.5651 - acc: 0.7110 - val_loss: 0.4249 - val_acc: 0.8180
Epoch 3/100
100/100 - 41s 415ms/step - loss: 0.5069 - acc: 0.7527 - val_loss: 0.3790 - val_acc: 0.8260
...
...
Epoch 99/100
100/100 - 42s 417ms/step - loss: 0.2656 - acc: 0.8907 - val_loss: 0.2757 - val_acc: 0.9050
Epoch 100/100
100/100 - 42s 418ms/step - loss: 0.2876 - acc: 0.8833 - val_loss: 0.2665 - val_acc: 0.9000
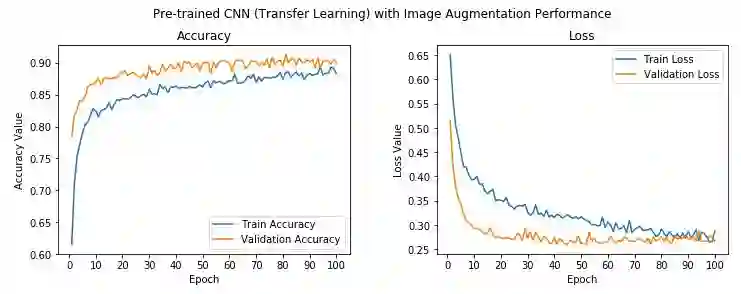
可以看到,我们模型的验证精确度达到了90%,略高于之前的模型,训练精确度和验证精确度也相当接近,意味着模型没有过拟合。让我们保存模型至磁盘,以待以后在测试数据上进一步评估。
model.save('cats_dogs_tlearn_img_aug_cnn.h5')
现在我们将微调VGG-16模型以创建最后一个分类器,其中将解冻块4和块5。
微调预训练CNN模型搭配图像增强
我们将解冻VGG模型的第4、第5卷积块,前三个卷积块则保持冻结状态:
vgg_model.trainable = True
set_trainable = False
for layer in vgg_model.layers:
if layer.name in ['block5_conv1', 'block4_conv1']:
set_trainable = True
if set_trainable:
layer.trainable = True
else:
layer.trainable = False
layers = [(layer, layer.name, layer.trainable) for layer in vgg_model.layers]
pd.DataFrame(layers, columns=['Layer Type', 'Layer Name', 'Layer Trainable'])
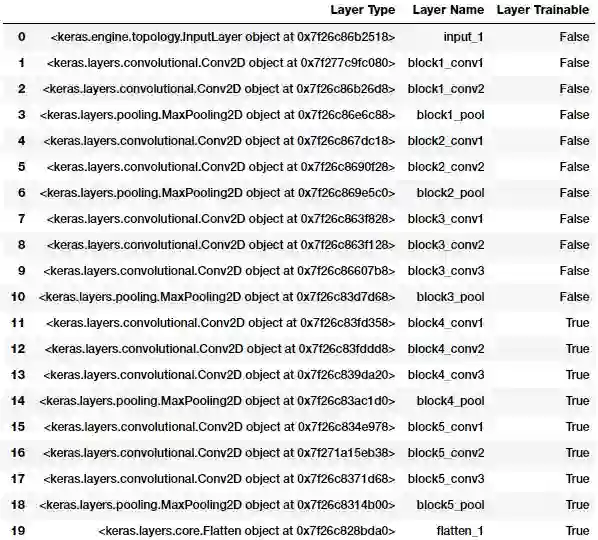
从上面的输出,我们可以很清楚地看到,块4和块5的预训练卷机层和池化层现在处于可训练状态。这意味着这些层的权重也会随着我们在每个epoch中传入每个数据批次而通过反向传播得到更新。我们将使用和之前模型一样的数据生成器和模型架构。我们稍微降低了学习率,因为我们不想陷入任何局部极小值,也不想突然大幅度更新VGG-16模型的可训练层,以免对整个模型造成负面影响。
train_datagen = ImageDataGenerator(rescale=1./255, zoom_range=0.3, rotation_range=50,
width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2,
horizontal_flip=True, fill_mode='nearest')
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow(train_imgs, train_labels_enc, batch_size=30)
val_generator = val_datagen.flow(validation_imgs, validation_labels_enc, batch_size=20)
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, InputLayer
from keras.models import Sequential
from keras import optimizers
model = Sequential()
model.add(vgg_model)
model.add(Dense(512, activation='relu', input_dim=input_shape))
model.add(Dropout(0.3))
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.3))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-5),
metrics=['accuracy'])
history = model.fit_generator(train_generator, steps_per_epoch=100, epochs=100,
validation_data=val_generator, validation_steps=50,
verbose=1)
输出:
Epoch 1/100
100/100 - 64s 642ms/step - loss: 0.6070 - acc: 0.6547 - val_loss: 0.4029 - val_acc: 0.8250
Epoch 2/100
100/100 - 63s 630ms/step - loss: 0.3976 - acc: 0.8103 - val_loss: 0.2273 - val_acc: 0.9030
Epoch 3/100
100/100 - 63s 631ms/step - loss: 0.3440 - acc: 0.8530 - val_loss: 0.2221 - val_acc: 0.9150
...
...
Epoch 99/100
100/100 - 63s 629ms/step - loss: 0.0243 - acc: 0.9913 - val_loss: 0.2861 - val_acc: 0.9620
Epoch 100/100
100/100 - 63s 629ms/step - loss: 0.0226 - acc: 0.9930 - val_loss: 0.3002 - val_acc: 0.9610
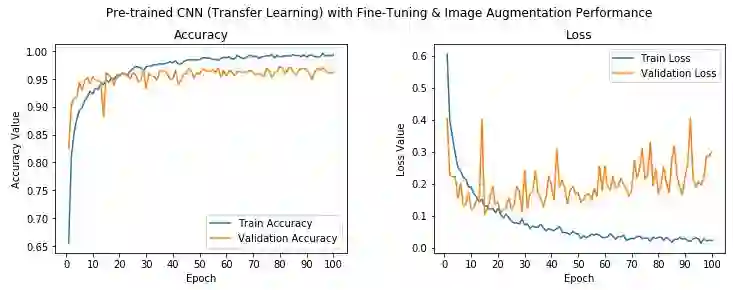
可以看到,我们的模型取得了96%左右的验证精确度,比之前的模型提高了6%,比最初的基本CNN模型提高了24%。这充分显示了迁移学习的有用性。精确度数值真的很出色,尽管模型看起来也许稍微有点过拟合。让我们使用以下代码保存模型至磁盘。
model.save('cats_dogs_tlearn_finetune_img_aug_cnn.h5')
下面让我们在测试数据集上评估所有模型的实际表现。
在测试数据上评估深度学习模型
我们将在测试数据集上评估我们之前搭建的5个模型。我们将使用model_evaluation_utils这一辅助模块帮助评估模型表现。首先,让我们加载必要的依赖和保存的模型。
# 加载依赖
import glob
import numpy as np
import matplotlib.pyplot as plt
from keras.preprocessing.image import load_img, img_to_array, array_to_img
from keras.models import load_model
import model_evaluation_utils as meu
%matplotlib inline
# 加载保存的模型
basic_cnn = load_model('cats_dogs_basic_cnn.h5')
img_aug_cnn = load_model('cats_dogs_cnn_img_aug.h5')
tl_cnn = load_model('cats_dogs_tlearn_basic_cnn.h5')
tl_img_aug_cnn = load_model('cats_dogs_tlearn_img_aug_cnn.h5')
tl_img_aug_finetune_cnn = load_model('cats_dogs_tlearn_finetune_img_aug_cnn.h5')
# 加载其他配置
IMG_DIM = (150, 150)
input_shape = (150, 150, 3)
num2class_label_transformer = lambda l: ['cat' if x == 0 else 'dog' for x in l]
class2num_label_transformer = lambda l: [0 if x == 'cat' else 1 for x in l]
# 加载VGG模型以提取瓶颈特征
from keras.applications import vgg16
from keras.models import Model
import keras
vgg = vgg16.VGG16(include_top=False, weights='imagenet',
input_shape=input_shape)
output = vgg.layers[-1].output
output = keras.layers.Flatten()(output)
vgg_model = Model(vgg.input, output)
vgg_model.trainable = False
def get_bottleneck_features(model, input_imgs):
features = model.predict(input_imgs, verbose=0)
return features
接下来我们将在测试数据集上做出预测,以测试模型的表现。在做预测前,先加载并准备好测试数据集。
IMG_DIM = (150, 150)
test_files = glob.glob('test_data/*')
test_imgs = [img_to_array(load_img(img, target_size=IMG_DIM)) for img in test_files]
test_imgs = np.array(test_imgs)
test_labels = [fn.split('/')[1].split('.')[0].strip() for fn in test_files]
test_imgs_scaled = test_imgs.astype('float32')
test_imgs_scaled /= 255
test_labels_enc = class2num_label_transformer(test_labels)
print('Test dataset shape:', test_imgs.shape)
print(test_labels[0:5], test_labels_enc[0:5])
输出:
Test dataset shape: (1000, 150, 150, 3)
['dog', 'dog', 'dog', 'dog', 'dog'] [1, 1, 1, 1, 1]
预备好数据集后,让我们预测所有测试图像的分类以评估每个模型的表现。
模型1:基本CNN模型
predictions = basic_cnn.predict_classes(test_imgs_scaled, verbose=0)
predictions = num2class_label_transformer(predictions)
meu.display_model_performance_metrics(true_labels=test_labels, predicted_labels=predictions,
classes=list(set(test_labels)))

模型2:基本CNN搭配图像增强
predictions = img_aug_cnn.predict_classes(test_imgs_scaled, verbose=0)
predictions = num2class_label_transformer(predictions)
meu.display_model_performance_metrics(true_labels=test_labels, predicted_labels=predictions,
classes=list(set(test_labels)))

模型3:预训练CNN特征提取器
test_bottleneck_features = get_bottleneck_features(vgg_model, test_imgs_scaled)
predictions = tl_cnn.predict_classes(test_bottleneck_features, verbose=0)
predictions = num2class_label_transformer(predictions)
meu.display_model_performance_metrics(true_labels=test_labels, predicted_labels=predictions,
classes=list(set(test_labels)))

模型4:预训练CNN特征提取器搭配图像增强
predictions = tl_img_aug_cnn.predict_classes(test_imgs_scaled, verbose=0)
predictions = num2class_label_transformer(predictions)
meu.display_model_performance_metrics(true_labels=test_labels, predicted_labels=predictions,
classes=list(set(test_labels)))

模型5:微调预训练CNN搭配图像增强
predictions = tl_img_aug_finetune_cnn.predict_classes(test_imgs_scaled, verbose=0)
predictions = num2class_label_transformer(predictions)
meu.display_model_performance_metrics(true_labels=test_labels, predicted_labels=predictions,
classes=list(set(test_labels)))

我们看到,每个后续模型比之前的模型表现要好,这和我们的期望是相符的,因为我们在每个新模型上尝试了更高级的技术。
最差的模型是基本CNN模型,模型精确度和F1评分约为78%,最好的模型是搭配图像增强的使用迁移学习的微调模型,模型精确度和F1评分约为96%,考虑到我们的训练数据集只有3000张图像,这真是一项惊人的成果。现在让我们绘制下最差和最优模型的ROC曲线。
# 最差模型 - 基本CNN
meu.plot_model_roc_curve(basic_cnn, test_imgs_scaled,
true_labels=test_labels_enc,
class_names=[0, 1])
# 最优模型 - 搭配图像增强的微调模型
meu.plot_model_roc_curve(tl_img_aug_finetune_cnn, test_imgs_scaled,
true_labels=test_labels_enc,
class_names=[0, 1])
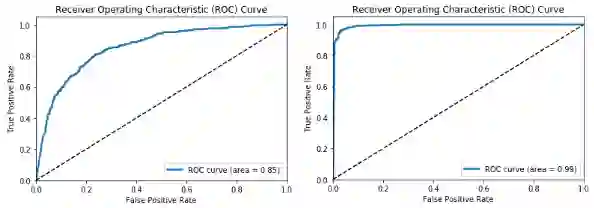
这一鲜明的对比说明了预训练模型和迁移学习能够带来多大的不同,特别是在数据较少的限制下处理复杂问题时。我们鼓励你在自己的数据上尝试类似的策略。
迁移学习优势
我们在之前的小节中已经介绍过迁移学习的一些优势。通常来说,迁移学习让我们能够创建可以进行各种任务的更加强健的模型。
有助于解决具备若干限制的复杂真实世界问题。
处理可用标注数据很少甚至几乎没有的问题。
便于根据领域和任务将一个模型的知识迁移到另一个中。
为未来某一天达成强通用智能提供了道路!
迁移学习挑战
迁移学习具有巨大的潜力,常常也能增强现有学习算法。然而,和迁移学习相关的一些问题尚有待更多研究和探索。除了要回答迁移什么、何时迁移、如何迁移还很难之外,负迁移和迁移界限是迁移学习面临的主要挑战。
负迁移: 我们目前讨论过的情形都是通过从源任务迁移知识改进目标任务的表现。但有些情形下,迁移学习可能导致表现下降。负迁移指从源领域/任务迁移知识到目标领域/任务没有带来任何改善,反而导致目标任务的总体表现下降的场景。可能有各种各样的原因会导致负迁移,比如源任务和目标任务并不足够相关,再比如迁移方法不能很好地利用源任务和目标任务之间的关系。避免负迁移十分重要,这需要仔细的调查。Rosenstien及其协作者的工作从实践经验的角度展示了在太不相关的源任务和目标任务上,暴力迁移会降低目标任务的表现。Bakker及其协作者则通过贝叶斯方法和其他一些技术探索基于聚类识别相关性的方案,以避免负迁移。
迁移界限: 量化迁移学习中影响迁移质量和可行性的迁移量也很重要。Hassan Mahmud及其协作者使用Kolmogorov复杂度证明了用来分析迁移学习和测量任务相关性的特定理论界限,从而估计迁移量。Eaton及其协作者提出了一种基于图的方法以测量知识迁移。本文不会讨论这些技术的细节,我们鼓励读者自行探索这些主题!
结语和后续预告
这也许是我写过的最长的博客文章,全面介绍了迁移学习的概念、策略,重点关注深度迁移学习,及其挑战和优势。我们也通过两个真实世界案例研究让你对如何实现这些技术有所了解。如果你正在阅读这段话,我要为你读完这么长一篇文章而点赞!
毫无疑问,迁移学习将成为机器学习和深度学习成功应用于业界主流的关键驱动因素之一。我绝对希望能看到更多预训练模型,还有更多使用这一概念和方法论的创新案例研究。你也可以期待我后续的文章:
用于NLP的迁移学习
音频数据的迁移学习
生成式深度学习的迁移学习
图像说明等更复杂的计算机视觉问题
我们希望能看到更多迁移学习和深度学习的成功例子,让我们可以创建更智能的系统,让世界更美好,同时达成我们的个人目标!
我最近写的书Hands on Transfer Learning with Python包括了上文的所有内容,你可以在Packt或Amazon购买此书。
没时间阅读这本书或者现在不想花钱?别担心,你仍可以通过GitHub仓库访问所有示例代码:dipanjanS/hands-on-transfer-learning-with-python 感谢我的合著者Raghav和Tamoghna和我一起编写此书。
感谢Francois Chollet和他惊人的杰作Deep Learning with Python,文章中用到的一些例子借鉴了这本书。
有任何反馈,或者想和我一起进行数据科学、人工智能方面的研究,或者想在TDS上发表文章,都欢迎在LinkedIn上联系我(dipanzan)。
感谢Durba编辑本文。
点击【阅读原文】,查看更多案例~