ECCV2020|语义分割的落地应用:故障检测与异常检测
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
明天,极市平台将继续独家直播由山东大学主办的“可视计算”学术专题报告。国内外的知名学术专家,会就各自领域的基础理论、应用前景与前沿技术等方面进行专题报告。请大家锁定直播时间7月17日(星期五)—7月19日(星期日)。详情戳这里,在极市平台后台回复“61”,即可获取直播链接。
论文名:Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation
论文地址:https://arxiv.org/pdf/2003.08440.pdf
代码地址: 未开源
语义分割在自动驾驶、医学影像分割等方面有着广泛的应用。在这些领域,语义分割结果的准确性是非常重要的,比如医学影像的分割结果如果出错,那么将直接影响之后对于病情的判断。但是我们也知道,在实际应用中,对于输入到训练好的语义分割模型中的图像,实际上是没有groud truth的。那么,我们该如何知道对于这一输入图像:1)分割结果到底是好是坏?(故障检测);2)如果输入图像图像中出现了给定类别之外的异常类别,我们又如何能够直接感应到?(异常检测)
一、简介
先形象化的理解一下故障检测与异常检测这两个概念:

图一:故障检测(左)、异常检测(右)示例
故障检测(Failure Detection):
在本文中,故障检测有两个目标:1)给出预测的分割结果与“真值”的在当前图像上存在的类别的交并比(这个真值是不存在的。你可能会想不存在怎么比较?不是开玩笑吗?别急后面的方法部分会告诉你如何比较),如图一(左)右上部分;2)定位到预测错误的区域,如图一(左)右下部分。还是没有真值,那么又是如何完成错误的定位的呢?
异常检测/分割(Anomaly Segmentation):
一场检测简单点来说就是,我们现实生活中的目标的类别是要远远多于我们训练好的语义分割模型所定义的类比的(比如PASCAL VOC2012的类别就只有21类)。那么万一在实际应用过程中输入图像出现了这些在训练阶段语义分割模型没有定义到的类别,我们该如何第一时间检测到这一类别,并在分割出属于该异常类别的目标在图中的位置呢(如图一(右))?
二、方法
现在我们明确一下我们的目标以及所拥有的已知条件:
目标: 现实语义分割的落地场景中,输入到语义分割模型中的图像是没有真值的,但是我们又想知道分割结果的好坏,所以我们的目标是进行故障检测(Failure Detection) 和 异常检测/分割(Anomaly Segmentation)。
已知条件: 1)输入图像x;2)训练好的语义分割模型M;3)输入图像的经过语义分割模型M后的预测结果y^.
下面我们来看一下作者是怎么应用上述已知条件来完成上述目标的。
首先,作者利用对抗生成网络GAN的原理(当然作者论文中用的是cGAN [1])使用预测图y^作为GAN的输入,输出了合成的原图x^.其大致过程如图二(上)所示。
有对GAN不熟悉的可以参考:
GAN学习指南:从原理入门到制作生成Demo

图二:cGAN合成原图的过程(上),以GT合成原图为例。完整的进行故障检测与异常检测的过程(下)
随后,作者设计了一个比较模块,来通过比较合成图x^与原图x之间的差别来完成故障检测与异常检测的目标。作者的假设是,如果x^类似于x, 那么y^就类似于y。然而,由于GAN中的生成器G的优化并不能保证合成图像x^风格与原始图像x相同,所以简单的相似性测量,如测量x和x^之间的L1距离是不准确的。所以作者针对故障检测与异常检测两个不同的任务设计了不同的比较模块F。比较模块的目标是输出C^:
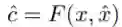
对于不同的任务,C^的含义不同.
在故障检测中,C^代表的是C^iu与C^m的集合。C^iu和C^m就是前面在简介中所提到的预测的分割结果与“真值”的在当前图像上存在的类别的交并比与定位到预测错误区域的error map。他们的形状分别为长为L的一维向量与宽高分别为w,h(即原图宽高)二维map。
在异常检测中,C^代表的是对于异常目标的分割图,它的形状为宽高分别为w,h(即原图宽高)二维map。
我们来看看作者是如何具体设计比较模块的:
故障检测:
图三:故障检测的比较模块,利用孪生网络。
作者利用孪生网络(siamese network)来比较合成图像与原始图像的差别。孪生网络,简单点来说就是网络结构一样,参数共享的两个网络。这里的网络使用的是ResNet-18。输入如图所示。主要过程通过图相信大家都能看懂,这里主要讲一下这个网络在训练阶段是通过什么来监督的:
我们知道在训练阶段我们的输入图像是有真值的。所以我们可以去计算预测图与真值的每个类别iou,即Ciu:
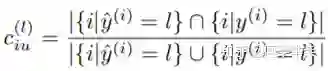
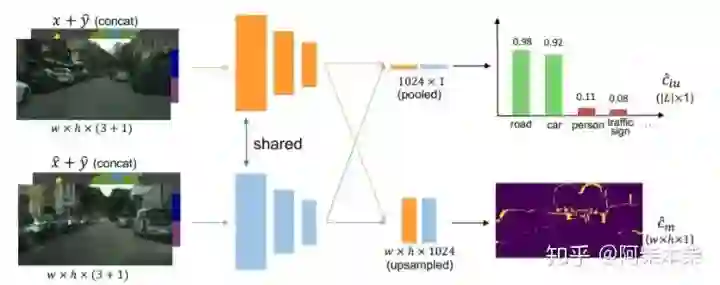
其中,l代表的是其中的第l类。右上角的i代表第i个像素。那么我们就可以以Ciu为监督信息,以L1 loss为损失函数去监督网络训练。这样,训练好的网络可以去预测C^iu。
而对于error map 的预测的话,同样由于训练过程中有着真值y。所以可以计算出真正的error map,即Cm:
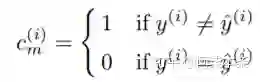
以此为监督信息,并使用二元交叉熵损失函数去监督网络训练。这样,训练好的网络可以去预测C^m。
以上两个损失函数可以写为:
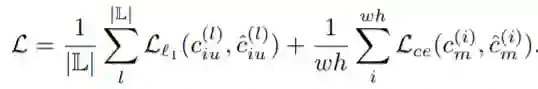
异常检测:
与故障检测一样,首先在训练图像上训练一个cGAN生成器G,它使用分割对象标签来合成图像。给定一个语义分割模型M,我们得到其预测yˆ = M (x)和获取的合成图像xˆ = G(yˆ)。由于yˆ中只包含了给定的类别,所以xˆ也只包含了给定的类别。因此xˆ与x会差别很大。所以将x与xˆ再次输入M中时,M最后一层所提取的特征也会有很大的差别。作者用余弦距离作为指标来定义x与xˆ在M最后一层特征上的差异:
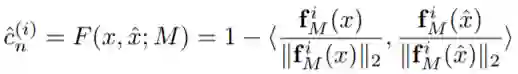
这个公式中f代表着M最后一层的特征图。i代表特征图中的第i个像素。
这样就直接得到了我们之前在简介中图一所看到的异常分割的分割结果。
三、实验
Cityscapes:
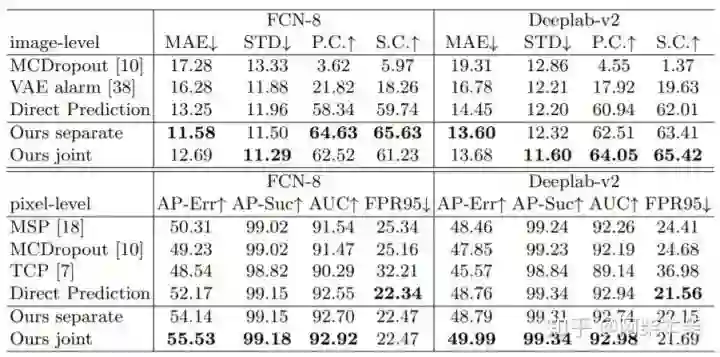
表1:在Cityscapes数据集上的实验。我们在FCN-8和Deeplab-v2的分割结果中进行失败检测。“Ours separate”和““Ours joint”意味着分别训练我们网络中的图像级和像素级故障检测头。
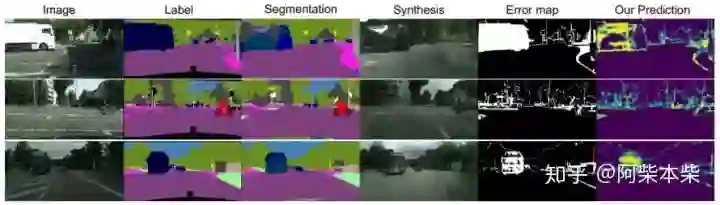
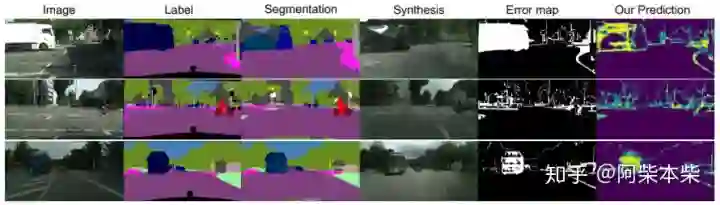
图一:Cityscapes数据集上的可视化
表二:StreetHazards数据集的异常分割结果

图二:Visualizations on the StreetHazards dataset.
参考文献:
[1]Mirza, M., Osindero, S.: Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784 (2014)
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




