超清还不够,插帧算法让视频顺滑如丝丨NeurIPS 2019


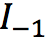 、
、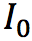 、
、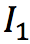 和
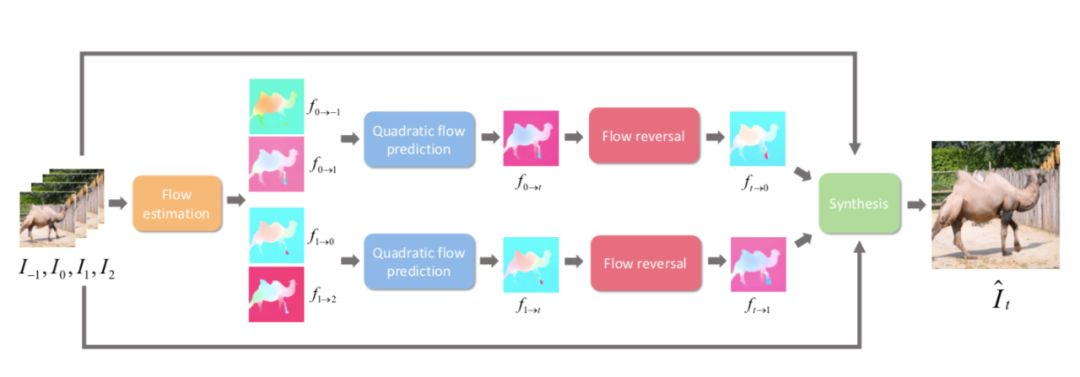
和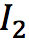 是输入视频连续的四帧。给定任意时刻t(0<t<1),该模型将最终生成t时刻的中间帧。而要得到
是输入视频连续的四帧。给定任意时刻t(0<t<1),该模型将最终生成t时刻的中间帧。而要得到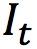 ,就需要更深入了解其中的两个关键技术:
二次方光流预测和光流逆转。
,就需要更深入了解其中的两个关键技术:
二次方光流预测和光流逆转。
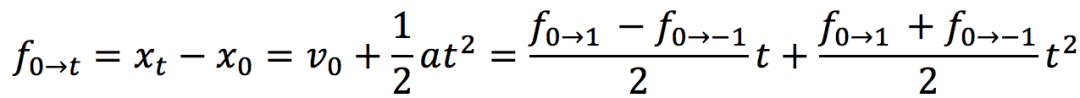
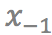 ,
,
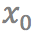 ,
,
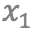 ,
,
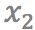 分别表示物体
分别表示物体
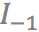 ,
,
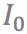 ,
,
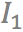 ,
,
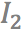 中的位置
中的位置
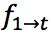 。此时,我们得到了含有加速度信息
。此时,我们得到了含有加速度信息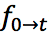 和。
和。
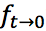 和
和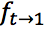 。
和
。通过以下转换公式可以高效的将和和转化为和,但是可能会造成逆转的光流在运动边界处出现强烈的振铃效应(见图4)。
。
和
。通过以下转换公式可以高效的将和和转化为和,但是可能会造成逆转的光流在运动边界处出现强烈的振铃效应(见图4)。
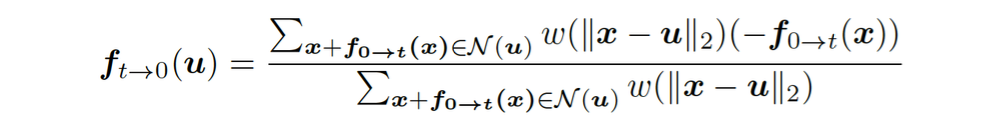
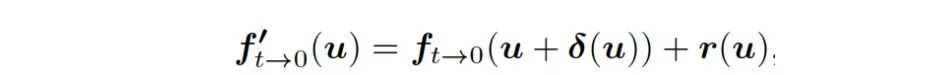




 点击“
阅读
原文
”加入 NeurIPS 交流群
点击“
阅读
原文
”加入 NeurIPS 交流群
登录查看更多
相关内容
Arxiv
4+阅读 · 2018年3月30日
Arxiv
6+阅读 · 2018年3月28日




相关VIP内容
相关资讯
相关论文
Arxiv
4+阅读 · 2018年3月30日
Arxiv
6+阅读 · 2018年3月28日