大规模均衡分割与层次聚类
文 / NYC 算法与优化研究团队研究员 Hossein Bateni 和软件工程师 Kevin Aydin
解决大规模优化问题通常始于图分割,这就意味着需要将图的顶点分割成聚类,然后在不同的机器上处理。我们需要确保聚类具有几乎相同的大小,这就催生了均衡图分割问题。简单地说,我们需要将给定图的顶点分割到 k 个几乎相等的聚类中,同时尽可能减少被分割切割的边数。这个 NP 困难问题在实践中极其困难,因为适用于小型实例的最佳逼近算法依赖半正定规划,这种规划对更大的实例来说不切实际。
这篇博文介绍了我们开发的分布式算法,这种算法更适合大型实例。我们在 WSDM 2016 论文中介绍了这种均衡图分割算法,并且已将这种方法运用到 Google 内部的多个应用中。我们最近发表的 NIPS 2017 论文通过理论与实证研究详细介绍了这种算法。
通过线性嵌入实现均衡分割
我们的算法先将图的顶点嵌入到一条直线中,然后按照线性嵌入顺序,以分布式方式处理顶点。我们检查了各种方式来查找初始嵌入,并应用四种不同的技术(例如局部交换和动态规划)获取最终分割。最佳初始嵌入基于 “亲和聚类”。
亲和层次聚类
亲和聚类是一种基于 Borůvka 经典最大开销生成树算法的凝聚型层次图聚类。与上面讨论的一样,这种算法是我们均衡分割工具的关键部分。它首先会将每个顶点置于各自的聚类中:v0、v1,依此类推。然后在每次迭代中,从每个聚类中选择开销最高的边,以便包含更大的合并聚类:在第一轮中包含 A0、A1 和 A2 等,在第二轮中包含 B0 和 B1等,依此类推。合并集合会自然生成一个层次聚类,并产生叶顶点(一度顶点)的线性序。下图说明了这一点,底部数字对应于顶点的顺序。
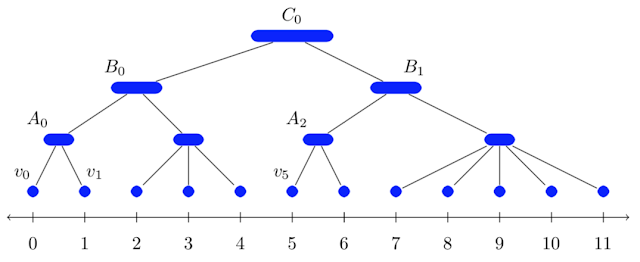
我们的 NIPS’17 论文说明了我们如何在大规模并行计算 (MPC) 模型中有效运行亲和聚类,特别是使用分布式哈希表 (DHT) 显著缩短运行时间。这篇论文也介绍了算法的一个理论研究。我们报告了具有数十万亿条边的图的聚类结果,并观察到在 “聚类质量” 方面,亲和聚类在实践中优于 k-均值等其他聚类算法。这段视频包含结果汇总,并说明了与顺序单链接凝聚算法相比,这种并行算法如何生成更优质的聚类。
注:视频链接 https://www.youtube.com/watch?v=1IOEFNGPNJc
与之前工作的比较
在将这种算法与(分布式)均衡图分割中的之前工作进行比较时,我们侧重于 FENNEL、Spinner、METIS,以及近期一种基于标签传播的算法。我们报告了在多个公共社交网络和大型专属地图图表中取得的结果。对于 Twitter 关注关系图,我们看到比之前的结果(Ugander 和 Backstrom 等人于 2013 年取得)有 15-25% 的一致改进,而对于 LiveJournal 图,我们的算法也仅仅在 k = 2 时稍逊于 FENNEL 的结果,除此之外均优于其他所有算法。
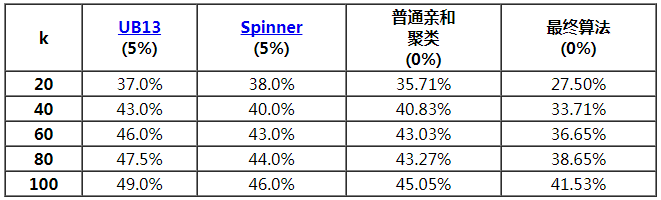
下表显示了在 Twitter 图中通过不同算法为各种 k 值(聚类数量)获得的切割边百分比。括号中的数字表示大小失衡系数:即最大与最小聚类大小的相对差异。这里的 “普通亲和聚类” 表示我们算法的第一个阶段,在这个阶段中,我们仅构建了层次聚类,没有对切割执行进一步处理。请注意,这已经可以与之前的最佳结果(显示在下表的前两列中)相媲美了,在切割更少的边的同时获得完美(因而更好的)平衡(即,0% 失衡)。表格中的最后一列包含我们的算法在进行后期处理之后的最终结果。
应用
我们将均衡图分割运用到多个应用中,包括 Google 地图驾驶路线、网页搜索服务后端,以及为实验性设计寻找实验组。例如在 Google 地图中,世界地图图表存储在多个分片中。与可以在一个分片内处理的查询相比,跨越多个分片的导航查询的开销明显更大。利用论文中介绍的方法,我们可以通过将分片失衡系数从 0% 增大至 10% 的方式减少 21% 的跨分片查询。
如我们的论文中所述,对真实流量的实时实验显示,与希尔伯特嵌入基准技术相比,我们的切割优化技术将多分片查询的数量减少了 40%。这反过来又会降低响应查询时的 CPU 使用率。在未来的博文中,我们将讨论这项工作在网页搜索服务后端中的应用,在这个用例中,均衡分割已经帮助我们设计了一个具有缓存感知能力的负载平衡系统,大大降低了我们的缓存未命中率。
更多 AI 相关阅读:




