从基础知识到实际应用,一文了解「机器学习非凸优化技术」
选自arXiv
机器之心编译
优化技术在科技领域应用广泛,小到航班表,大到医疗、物理、人工智能的发展,皆可看到其身影,机器学习当然也不例外,且在实践中经历了一个从凸优化到非凸优化的转变,这是因为后者能更好地捕捉问题结构。本文梳理了这种转变的过程和历史,以及从机器学习和信号处理应用中习得的经验。本文将带领读者简要了解几种广泛使用的非凸优化技术及应用,介绍该领域的丰富文献,使读者了解分析非凸问题的简单步骤所需的基础知识。更多详细内容请查看原论文。
优化作为一种研究领域在科技中有很多应用。随着数字计算机的发展和算力的大幅增长,优化对生活的影响也越来越大。今天,小到航班表大到医疗、物理、人工智能的发展,都依赖优化技术的进步。
在这段兴奋期的大部分时间,由于我们对凸集合和凸函数的深入了解,我们主要聚焦于凸优化问题。但是,信号处理、生物信息学和机器学习等领域的现代应用通常不满足于仅使用凸函数,因为非凸公式能够更好地捕捉问题结构。
近期出现了一些论文开始探讨非凸优化,不过第一批论文仍然坚持使用凸优化,致力于证明特定类别的非凸问题(具备与这些问题的自然实例类似的合适结构)可以在没有损失的前提下转换成凸问题。更准确地说,原始的非凸问题和修改后的凸问题具备共同的最优解,因此凸问题的解也可以自动解决非凸问题!但是,这种方法需要耗费大量时间解决所谓的松弛凸问题(relaxed convex problem)。
第二批论文研究在避免松弛凸优化的情况下可证明的非凸优化技术,并用于解决原本形式的非凸问题,似乎取得了与凸松弛方法同等质量的结果。伴随这些较新结果的是新的实现:对于稀疏恢复(sparse recovery)、矩阵补全(matrix completion)、稳健式学习(robust learning)等大量应用,这些直接技术能更快地收敛到最优解,速度通常比基于松弛凸优化的技术提高一个数量级甚至更多,而准确率与后者差不多。
本文旨在讲述这一实现的历史,以及从机器学习和信号处理应用的角度中学得的经验。本文将介绍非凸优化问题和可获取对此类问题极具扩展性解决方案的大量结构。本文将认真分析和利用额外的任务结构,证明之前避免的 NP-hard 问题现在具备在近线性时间内运行的求解器。本文将告知读者如何在不同的应用领域查找此类结构,使读者深入了解分析此类问题和提出更新解决方案的基础工具和概念。
论文: Non-convex Optimization for Machine Learning

论文地址:https://arxiv.org/abs/1712.07897
摘要:大量机器学习算法通过解决优化问题来训练模型、执行推断。为了准确捕捉学习和预测问题,经常出现的稀疏或低秩等结构化约束或目标函数本身都被设计成非凸函数。对运行在高维空间或训练张量模型和深层网络等非线性模型的算法尤其如此。
将学习问题表达为非凸优化问题的便利方式使算法设计者获得大量的建模能力,但是此类问题通常是 NP-hard 难解决的问题。之前流行的解决方案是将非凸问题近似为凸优化,使用传统方法解决近似(凸)优化问题。但是该方法可能造成损失,且对于大规模优化来说难度较高。
另一方面,解决非凸优化的直接方法在多个领域中取得了巨大成功,现在仍是从业者常用的方法,因为这种方法通常由基于凸松弛的技术,流行的启发式方法包括投影梯度下降(projected gradient descent)和交替最小化(alternating minimization)。但是,人们通常不了解其收敛性和其他特性。
本文展示了一些近期进展,这些进展可以填补我们对这些启发式方法长期以来的认识不足。本文将带领读者了解几种广泛使用的非凸优化技术及应用。本文目标是介绍该领域的丰富文献,以及使读者了解分析非凸问题的简单步骤所需的技术。

图 1:章节阅读建议顺序图示。例如,3、4 章介绍的概念有助于第 9 章的理解,而通读第 6 章则对此无必要。类似地,我们推荐先读第 4 章再读第 5 章,不过读者可以选择读完第 3 章后直接阅读第 7 章。
第 1 部分:引言和基础工具。这部分提供介绍性说明和凸优化中的一些基础概念和算法工具。推荐不熟悉数值优化的读者阅读这部分内容。
第 2 部分:非凸优化基元。这部分使读者了解非凸优化问题中最广泛使用的基元。
第 3 部分:应用。这部分介绍机器学习和信号处理领域中四个有趣的应用,探索如何使用之前介绍的非凸优化技术解决这些问题。
第一章 简介
这一部分将为后续讨论打下基础,并为读者提供一些非凸优化问题的基本概念与动机,我们将尝试使用现实生活的案例解释这些基本概念。
1.1 非凸优化
优化问题的一般形式可以表示为如下形式:
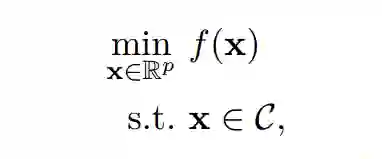
其中 x 为该优化问题的变量,f:R^p → R 为该问题的目标函数,C ⊆ R^p 为优化问题的约束集。当非凸优化应用到机器学习中时,目标函数可以允许算法设计者编码适当和期望的行为到机器学习模型中,例如非凸优化中的目标函数可以表示为衡量拟合训练数据好坏的损失函数。正如 Goodfellow 所说,一般的非凸优化和深度学习中的非凸优化,最大的区别就是深度学习不能直接最小化性能度量,而只能最小化损失函数以近似度量模型的性能。而对目标函数的约束条件允许约束模型编码行为或知识的能力,例如约束模型的大小。
凸优化问题研究的目标函数是凸函数,对应的约束集为凸集,我们将在第二章正式定义这些术语。一个最优化问题通常会违反一个或多个凸优化条件,即它们通常会有非凸目标函数和非凸约束集等限制,因此这一类的最优化问题可以称为非凸优化问题。在本论文中,我们将讨论带有非凸目标函数和非凸约束(§ 4, 5, 6, 8)的非凸优化问题,还有带有非凸约束和凸目标函数(§ 3, 7, 9, 10, 8)的最优化问题。这些非凸优化的问题在很多应用领域上都有广泛的体现。
1.2 非凸优化的动机
目前很多应用都频繁地要求学习算法在极高维度的空间中进行运算。例如网页文本分类问题就要求基于 n-gram 的表征有数百万甚至更高的维度,推荐系统同样有数百万的推荐条目和数百万的推荐用户,而像人脸识别、图像分类和生物信息学中的基因检测等单一处理任务同样有非常高维度的数据。
处理这种数据和模型需要对模型的学习施加一个结构化约束,这种约束不仅有助于正则化学习问题,同时还经常有助于防止优化问题变得病态。例如如果我们知道用户如何评价一个推荐条目,那么我们将希望推断该用户将如何评价其它的推荐条目,这通常可以用于广告推荐中。为了做到这一点,我们必须明白用户对一些商品的评价如何影响另一些商品的评价,并针对这种影响添加一些结构化约束。因为如果没有这些结构,那么推断任何新用户的评价都是不可能的。正如我们将在下文看到的,这种结构化约束通常都属于非凸问题。
在其它应用中,学习任务的自然目标函数是非凸函数,特别在深度学习中是高度非凸目标函数。常见的训练深度神经网络和张量分解等问题都涉及到本文所述的非凸优化。此外,即使非凸目标函数和约束允许我们准确地建模学习问题,但它们同样对算法的设计者提出了很严峻的挑战,即如何令高度非凸的目标函数收敛到一个十分理想的近似最优解。非凸优化并不像凸优化,我们并没有一套便利的工具来解决非凸问题,甚至已知有几个非凸问题是 NP-hard,我们总是只能近似地、显著地减小或增大目标函数的值。由于一系列非凸问题使得最优化变得更加困难,有时候不仅求最优解是 NP-hard,连近似求最优都是 NP-hard [Meka et al., 2008]。
1.4 凸松弛方法
面对非凸问题及其与 NP-hard 之间的关系,传统的解决方案是修改问题的形式化或定义以使用现有工具解决问题。通常通过凸松弛来进行,以使非凸问题编码为凸问题。由于该方法允许使用类似的算法技术,所谓的凸松弛方法得到了广泛研究。例如,推荐系统和稀疏回归问题都应用了凸松弛方法。对于稀疏线性回归,凸松弛方法带来了流行的 LASSO 回归。
现在,这类更改通常给问题带来巨大改变,松弛公式对于原始问题来说不是好的解决方案。但是,如果该问题具备较好的结构,那么在仔细的松弛处理后,这些扭曲(distortion,松弛差距)就消失了,即凸松弛问题的解也适用于原始的非凸问题。
这种方法很流行也很成功,但是也有局限性,最显著的缺点就是可扩展性(scalability)。尽管凸松弛优化问题在多项式时间中是可解决的,但在大规模问题中高效地应用这种方法通常比较困难。
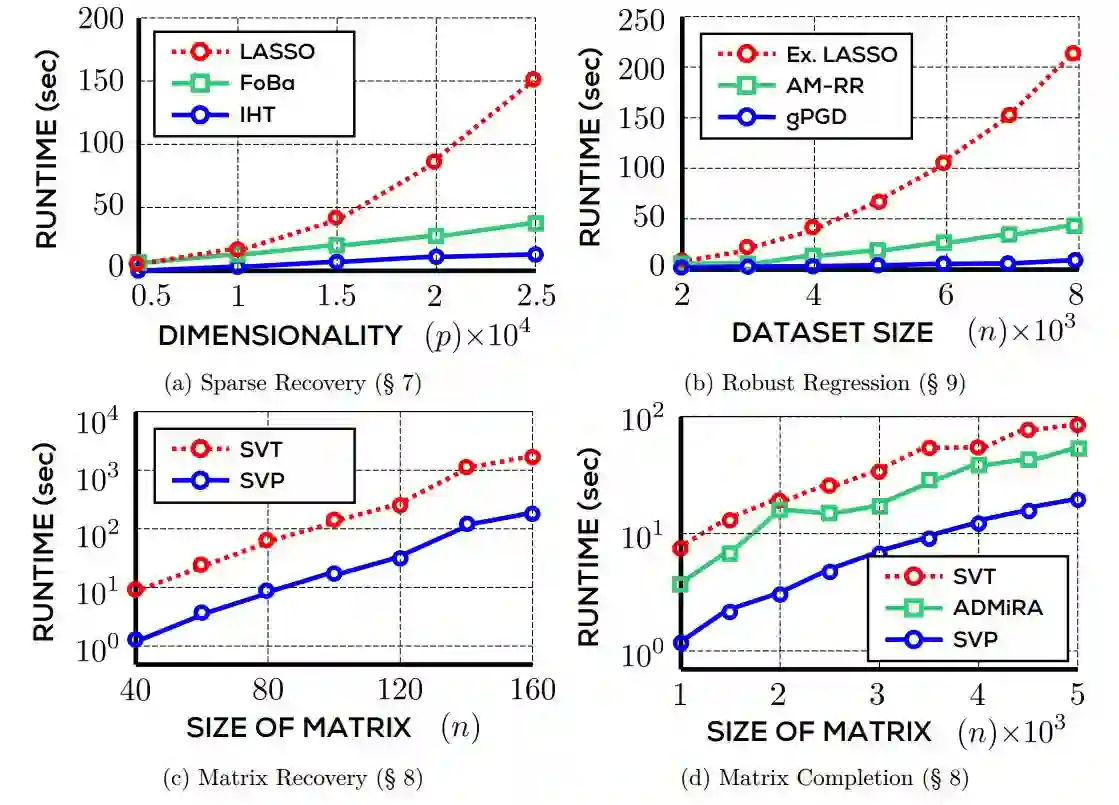
图 1.3:不同方法在四个非凸优化问题上的运行时实验对比。LASSO、extended LASSO 和 SVT 是基于松弛的方法,IHT、gPGD、FoBa、AM-RR、SVP 和 ADMiRA 是非凸方法。在所有情况中,非凸优化技术比基于松弛的方法快出一个数量级。注意图 1.3c 和 1.3d 使用对数尺度的 y 轴。
1.5 非凸优化方法
有趣的是,近年来,机器学习和信号处理领域出现了一种新方法,不对非凸问题进行松弛处理而是直接解决。引起目标是直接优化非凸公式,该方法通常被称为非凸优化方法。
非凸优化方法常用的技术包括简单高效的基元(primitives),如投影梯度下降、交替最小化、期望最大化算法、随机优化及其变体。这些方法在实践中速度很快,且仍然是从业者最喜欢用的方法。
但是,最初看来这些方法似乎注定要失败,因为前面提到的 NP-hard 问题很难解决。不过,一系列深入、具备启发性的结果证明了,如果该问题具备较好的结构,那么不仅可以使用松弛方法,还可以使用非凸优化算法。在这类案例中,非凸方法不仅能避免 NP-hard,还可以提供可证明的最优解。事实上,在实践中它们往往显著优于基于松弛的方法,不管是速度还是可扩展性,见图 1.3。
非常有趣的一点是,允许非凸方法避免 NP-hard 结果的问题结构与允许图松弛方法避免失真和较大松弛差距的结构类似!因此,如果问题具备较好的结构,则基于凸松弛的方法和非凸技术都可以成功,但是,非凸技术通常可以提供更具扩展性的解决方案。
第三章 非凸投影梯度下降
本章介绍和研究用于非凸优化问题的梯度下降方法。第 2 章研究了适合解决凸优化问题的投影梯度下降方法。不幸的是,凸问题中使用的这种算法和分析技术不适用于非凸问题。事实上,非凸问题是 NP-hard 的,因此,通常不期望有算法技术可以解决此类问题。
但是,情况并不是那么糟糕。如第 1 章所讨论的,非凸优化的几个重大突破展示了具备较好额外结构的非凸问题可以在多项式时间中得到有效解决。这里,我们将研究投影梯度下降方法在此类结构化非凸优化问题上的内部工作原理。
讨论分为三部分。第一部分是约束集,尽管是非凸的,但它们具备额外的结构可使投影高效实施。第二部分是目标函数中帮助优化的结构特性。第三部分是展示和分析适用于非凸问题的 PGD 算法的简单扩展。我们将看到对于具备较好结构目标函数的问题和约束集,类 PGD 算法可在多项式时间内收敛至全局最优,且收敛速度是线性的。
本章重点是基础概念的概述和阐释。我们将试图用轻松、易于理解的方式分析具备非凸目标函数的问题。但是,概述仅限于我们所展示结果的精细度。本章所讨论结果不是可能的最优结果,下面的章节中将介绍更精细、更针对特定问题的结果,也会详细讨论特定应用。
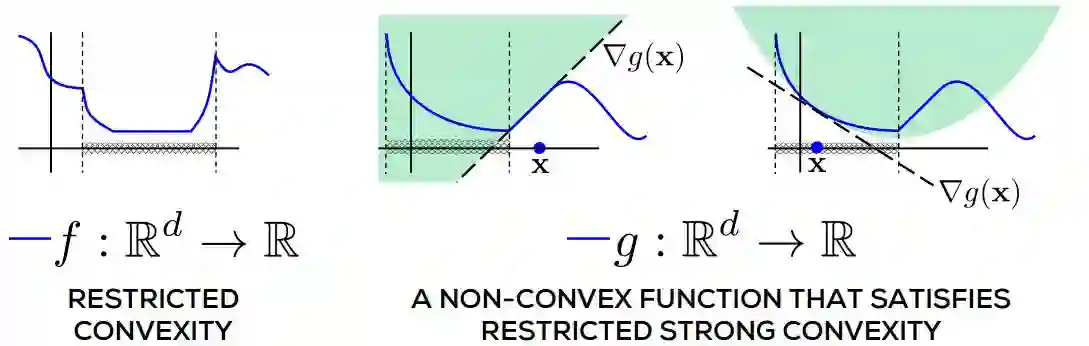
图 3.1:限制性凸性的描述。f 在整个实线上明显是非凸的,但在由虚垂直线界定的交叉阴影区域内是凸的。g 是一个非凸函数,满足限制性的强凸性。交叉阴影区域之外(再次由虚垂直线界定),当其曲线低于切线时,g 甚至不能为凸,但是在该区域内,它已实际表现出强凸性。
投影梯度下降算法已在算法 1 中陈述。该过程通过采取以梯度为指导的步骤生成迭代 x_t,以努力减少局部函数值。最后,它返回最后的迭代,平均迭代或者最佳的迭代。

算法 2 概述了用于解决非凸优化问题的广义投影梯度算法(gPGD)的过程。读者将会发现这非常类似于算法 1 之中的 PGD。然而,一个关键的区别是所做的投影:PGD 利用了凸投影,而 gPGD 利用了非凸投影(如果涉及到一个非凸约束集 C)。

第五章 EM 算法
在本节中,我们会简述最大期望(Expectation Maximization/EM)的原理。该原理是被人们广泛使用的学习算法的基础,如用于学习高斯混合模型,用于学习隐马尔科夫模型(HMM)的 Baum-Welch 算法,以及混合回归。EM 算法是 Lloyd 算法用于 K-均值聚类的一个变体。
尽管 EM 算法在表面上遵循了我们在§5 中研究的交替最小化原则,但由于其在概率学习环境中学习潜变量模型的广泛适用性,我们认为深入理解 EM 方法是非常有意义的。为了让阅读体验自成体系,我们首先会花一些时间在概率学习方法中构建符号。
算法 4 概括了 gAM 对潜在变量学习问题的适应性。注意,算法中的步骤 4 和 6 可以在几个问题上非常有效地执行。

算法 5 给出了 EM 算法的整体框架。实现 EM 算法需要两个过程,其一是构造与当前迭代(期望步骤或 E 步骤)对应的 Q 函数,另一个是用于最大化 Q 函数(最大化步骤或 M 步骤)以获得下一迭代。


机器之心发布首份《人工智能技术趋势报告》,纵览人工智能的 23 个分支技术。明晰历史发展路径,解读现有瓶颈及未来发展趋势。点击阅读原文,立即获取报告完整版。


