美剧《硅谷》深度学习APP获艾美奖提名:使用TensorFlow和GPU开发


《硅谷》中演示了一款识别热狗的软件Not Hotdog,可以在安卓和IOS下载
新智元报道
来源:Medium
作者:Tim Anglade
编辑:闻菲
【新智元导读】继AI制作动画人物、创作剧本、编辑电影之后,今天,一款AI软件正式获得黄金时段艾美奖提名:热播电视剧《硅谷》中一个使用深度学习自动识别热狗的软件再度走入公众视野,使用TensorFlow和英伟达GPU开发。

不知道你有没有看过热播美剧《硅谷》。作为近年来最佳职场喜剧之一,《硅谷》为我们展现了程序员不为人知的一面。《硅谷》在嬉笑怒骂间描绘了一部IT业创业辛酸史,不仅如此,人工智能、机器学习、加密货币……剧集的主题一直紧跟现实硅谷圈的潮流。

其中,在第四季第四集就出现了一个使用深度学习算法识别热狗的APP Not Hotdog,而且现在这款APP也能在安卓和iOS下载。
今天,制作这款的APP的Tim Anglade(是的,这款APP是他一个人制作的,当然得到了很多人的帮助)在Twitter上宣布,这款AI软件正式获得了黄金时段艾美奖提名!
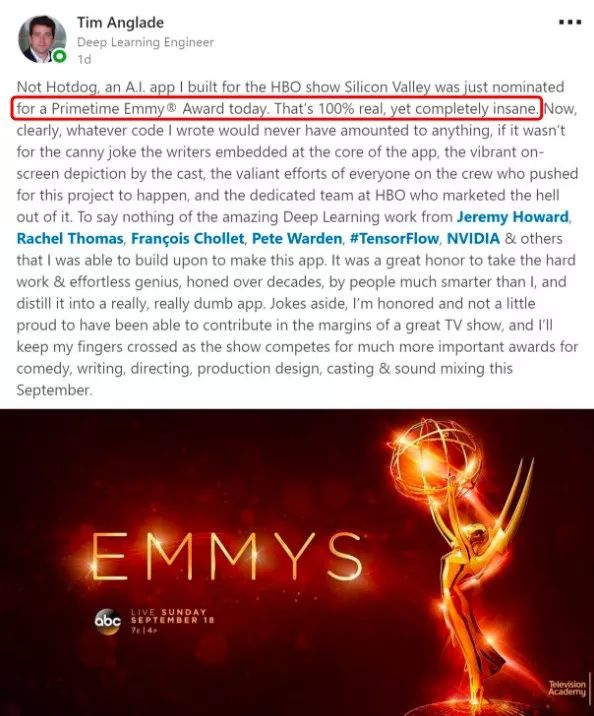
实际上,在剧集播出后,这款APP就在硅谷掀起了一股话题热潮,因为当时正是图像识别的热度达到巅峰时期。
《硅谷》剧组决定在剧集里做一个能够在手机上运行的热狗识别软件。实现这一目标,Tim Anglade他们设计了一个直接在手机上运行的定制神经架构,并使用Tensorflow,Keras和Nvidia GPU进行训练。
虽然只是用来识别热狗(或者不是热狗),但这款APP无疑是深度学习和边缘计算的一个亲切使用案例。所有的AI工作都由用户的设备100%供电,处理图像时无需离开手机。这为用户提供了更快捷的体验(无需往返云端),离线可用性和更好的隐私。
要知道,那时候还没有TensorFlow Lite,100%在手机端实现物体识别还算是相对超前的概念。
这也使得整个APP能以0美元的成本运行,即使在100万用户的负载下,与传统的基于云的AI方法相比,可以节省大量成本。
这款APP是由一个开发人员自己在内部开发的,用一台笔记本电脑和附加GPU运行,使用手工收集的数据。

作者的开发环境,就是这样简单!
作为一款从剧集中诞生的衍生品,着实火热了一把,还在苹果开发者大会得到了宣传。

作者Tim Anglade在Medium上超详细地介绍了这款APP的设计、开发,从原型到产品的过程,可以阅读原文了解详情。

下面,我们将摘选介绍这款APP的技术细节,使用了什么架构、如何训练,有什么要点。
对非技术公司,个人开发人员和业余爱好者等时间和资源有限的人,构建自己的深度学习APP,是再好不过的上手材料。
他们的最终架构在很大程度上受谷歌在2017年4月17日发布的论文MobileNet的推动,这种新的神经网络架构具有类似Inception的准确性,但只有4M左右的参数。

部分代码截图
之前团队考虑过SqueezeNet,但SqueezeNet对于他们想要实现的目标来说又太简单了,Inception或VGG则不能在手机上运行。MobileNet更适宜在移动端运行,这在当时是他们的首要考虑因素。
距离APP发布还有不到一个月的时间,团队正在努力重现该论文的结果。但是,在MobileNet论文发表后的一天之内,伊斯坦布尔技术大学的学生Refik Can Malli已经在GitHub上公开提供了Keras实现代码。深度学习社区的开放性和活跃性令人赞叹。
团队的最终架构叫做Deepdogs,与MobileNets架构有很大不同,特别是:
没有在深度和逐点卷积(depthwise and pointwise)使用批量标准化(BN)和激活,因为XCeption论文似乎表明这样做会导致这种类型的体系结构的准确性降低。同时,这样还具有减小网络规模的好处。
使用了ELU而不是ReLU。与SqueezeNet实验一样,激活函数使用ELU比ReLU提供了卓越的收敛速度和最终精度。
没有使用PELU。虽然这种方法不错,但只要我们尝试使用它,这个激活函数似乎就会陷入二元状态,网络准确性不会逐步提高,而是从一批到下一批在~0%到100%之间交替。目前还不清楚为什么会发生这种情况。
没有使用SELU。我们简单做了个调查,iOS和Android版本之间使用SELU导致结果与PELU非常相似。我们怀疑SELU不应该作为激活函数被单独使用,而是正如其论文的标题所暗示的那样,作为狭义(narrowly-defined)SNN架构的一部分。
使用ELU维持BN。有许多迹象表明BN应该是不必要的,但是,在没有BN的情况下运行的每个实验都完全无法收敛。这可能是由于架构很小造成的。
在激活之前使用了BN。虽然现在关于这一点有所争议,但他们的小型网络在激活后做BN的实验也未能收敛。
为了优化网络,使用了Cyclical Learning Rates和Brad Kenstler的Keras实现。

在训练时,团队做了细致的数据增强和处理工作,解决了一些由闪光灯(如下)等造成的图像扭曲等问题。
数据集的最终构成是150k图像,其中只有3k是热狗——热狗再多花样就那么几种,但是长的像热狗而不是热狗的东西则太多了。这个比例 49:1的不平衡通过设置Keras的权重为49:1来解决。在剩余的147k图像中,大多数都是食物,只有3k张非食物照片,这是为了帮助网络更多地概括,如果图像中出现红色服装中的人物,就不会被欺骗去将其识别为热狗。

闪光灯和moiré 造成的扭曲变形
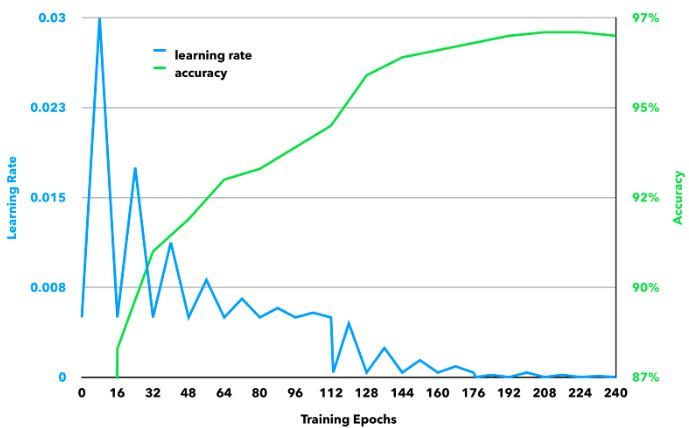
最终的训练学习率和精度是这样的:

APP遇到番茄酱的情况还是会失效(但你要这样在手臂上挤番茄酱也真没办法)
设计出了一个相对紧凑的神经体系结构,并且训练它来处理在移动环境中可能发现的情况,但是,仍然还需要做很多工作才能使其正常在手机上运行。
关于如何让Deepdog在手机上运行,可能是这个项目中最神秘的部分。因为在当时能找到在移动设备上运行商用深度学习APP的资料还相当匮乏。于是,他们咨询了Tensorflow团队,得到了特别是Pete Warden,Andrew Harp和Chad Whipkey的文档以及慷慨帮助。
舍入网络的权重有助于将网络压缩到其大小的约25%。本质上,不是使用从训练中派生的任意stock value,而是优化选择N个最常见的值,并将网络中的所有参数设置为这些值,从而大大减少压缩后网络的大小。但是,这对未压缩的APP大小或内存使用量没有影响。不过,团队没有使用这项优化,因为他们的网络足够小。
商用开发编译时,使用-Os来优化TensorFlow库
从TensorFlow库中删除不必要的操作:TensorFlow在某些方面就像是一个虚拟机,从中移除不必要的操作,可以节省大量的权重(和内存)。
团队不是在iOS上使用TensorFlow,而是使用苹果的内置深度学习库(BNNS,MPSCNN和更高版本的CoreML)。他们在Keras中设计网络,使用TensorFlow进行训练,导出所有权重值,使用BNNS或MPSCNN重新实现网络(或通过CoreML导入),并将参数加载到新的实现当中。
如果你觉得动态地将JavaScript注入到应用程序中很酷,那就试试在应用程序中注入神经网络吧!
他们使用的最后一个产品技巧是利用CodePush和苹果相对宽松的服务条款,在提交给应用商店后实时注入我们的神经网络的新版本。虽然这主要是为了帮助在发布后快速地向用户提供准确的改进,但是你可以使用这种方法来大幅扩展或改变应用程序的特性集,而不必再通过应用程序商店的审查。
有很多事情没有成功,或者我们没有时间去做,这些就是我们将来要研究的想法:
更仔细地调整我们的数据增强参数。
端到端测量准确性,即应用程序最终确定抽象事项,例如我们的程序是否有2个或更多的类别,Hotdog识别的最终阈值是什么(我们最终让应用程序说“Hotdog”,如果识别在权重四舍五入后,等于0.90而不是默认值0.5)
在应用中建立一个反馈机制——如果结果是错误的,让用户发泄不满,或者积极改进神经网络。
用一个更大的分辨率而不是224 x 224像素识别图像——本质上使用MobileNetsρ值> 1.0
最后,不得不指出用户体验、开发人员体验和内置偏见对开发人工智能应用明显和重要的影响。这三件事在我们的经验中有非常具体的影响:
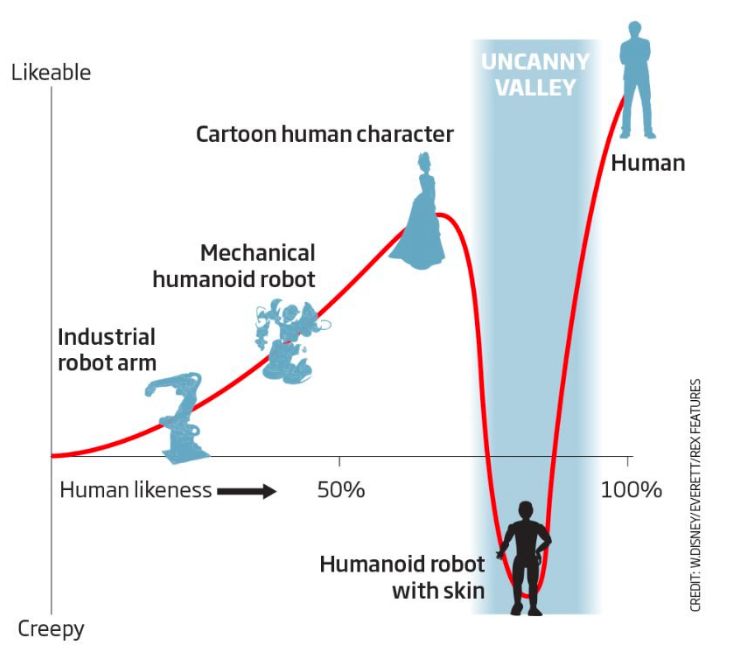
用户体验(User Experience) 在人工智能应用开发的每个阶段都比传统应用更重要。目前还没有深度学习算法能够给你带来完美的结果,但在很多情况下,深度学习+用户体验的正确组合将导致无法区分完美的结果。当开发人员设置正确的路径来设计他们的神经网络,在用户使用应用程序时设置正确的期望,以及优雅地处理不可避免的AI故障时,正确的UX期望是不可替代的。在没有用户体验第一思维模式的情况下构建AI应用程序就像训练没有随机梯度下降的神经网络:在构建完美的AI用例的过程中,最终会陷入Uncanny Valley的局部最小值。
DX(开发人员体验) 也非常重要,因为深度学习训练时间是等待程序编译时的新内容。我们建议您首先使用DX(因此使用了Keras),因为总是可以为以后的运行优化运行时间(手工的GPU并行化、多进程数据增强、TensorFlow pipeline,甚至是咖啡因2 / pyTorch的重新实现)。
即使是使用相对迟钝的API和文档(如TensorFlow)的项目,也可以通过为训练和运行神经网络提供一个经过高度测试、高度使用、维护良好的环境来大大改进DX。
出于同样的原因,很难同时拥有自己的本地GPU进行开发的成本和灵活性。能够在本地查看/编辑图像,用您喜欢的工具编辑代码而不延迟,这极大地提高了人工智能项目的开发质量和速度。
大多数人工智能应用程序将比我们的应用程序受到更严重的文化偏见,举个例子,我们在初始数据集中引发了内置偏见,这使得应用程序无法识别法国式Hotdog、亚洲Hotdog等等我们没见过的东西。
重要的是要记住,人工智能并不比人类做出“更好”的决定——他们通过人类提供的训练集感染了我们人类的偏见。
原文链接:https://medium.com/@timanglade/how-hbos-silicon-valley-built-not-hotdog-with-mobile-tensorflow-keras-react-native-ef03260747f3
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号: aiera2015_3 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。




