手把手教你用TensorFlow、Keras打造美剧《硅谷》中的“识别热狗”APP

来源:机械鸡
作者:瑶瑶
本文长度为10000字,建议阅读20分钟+
本文手把手教你开发自己的app~

HBO热播剧《硅谷》最近推出了一款能够识别“热狗”和“不是热狗”的人工智app(就像这部剧第四季第四集里的Jian Yang展示的一样),这款app目前已在安卓和iOS上架,但仅限美国、加拿大用户下载。
当你对着食物照片拍摄后(或者你可用手机里的照片),它会告诉你这个物体是「Hotdog or Not Hotdog」,这就是它全部的作用,整个应用功能非常简单。

为了准确地识别热狗,作者开发了一个能够直接在手机上运行的神经网络结构,并用TensorFlow,Keras和Nvidia GPU来训练它。
虽然功能很可笑,但这款应用是一个可操作性强的、利用深度学习和边缘运算(edgecomputing)的例子。所有的AI程序都百分百在用户的设备上运行,所拍摄的照片不用离开手机就能被处理。
这使得用户享有更好的体验(无需往返云端),离线使用功能,以及更好的隐私保护。这也使我们在拥有百万用户的情况下依然零开销运行应用,和传统的那些基于云端的AI相比为我们省下很大一部分花费。

作者开发应用的装备(图中eGPU用于训练“不是热狗”的AI)
这款应用是由一个开发者用一台笔记本电脑和一个GPU手动编辑数据开发的。这个例子告诉我们,以现在的科技,不需要科技公司的支持,个人开发者及爱好者也能利用有限的资源开发有趣的应用。废话不多说,下面我们就来手把手教你开发自己的app。
目录
一、App
二、从原型到产品
1、原型
2、TensorFlow,Inception结构和迁移学习
3、Keras和SqueezeNet
三、DeepDog架构
1、训练
2、在手机上运行神经网络
3、通过神经网络来改变应用程序行为
4、用户体验,开发者体验以及AI的恐怖谷
一、App
这款应用会先让你拍张照片,然后告诉你你拍的是不是热狗。这个功能直截了当,算是对ImageNet这类近期的AI应用的致敬。虽然我们比任何人在热狗上投资的工程资源都要多,但这款app也有犯傻的时候。

看来只要有番茄酱就是热狗
相反,有时候它也能在复杂情况下展示它机智的一面。Engadget曾如此报道:“太神奇了!我用这款app在20分钟内的体验比我用Shazam(一款能猜歌名的应用)两年来的体验还要好。”
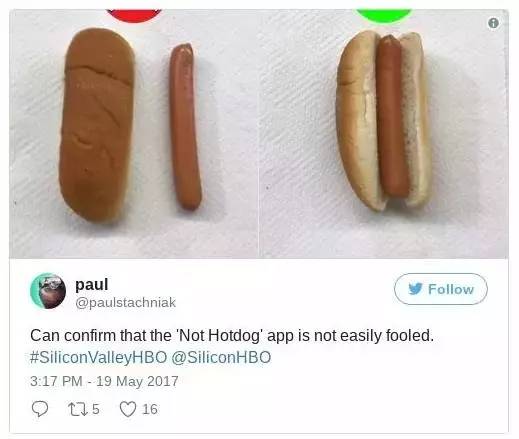
看来骗不了‘不是热狗’啊
二、从原型到产品
不知道你有没有这样的经历:当你在读Hacker News(一家关于计算机黑客和创业公司的社会化新闻网站)的时候,你会想:“他们A轮融资1000万就弄出来个这?我一个周末就能做得出来好吗!”
那么这款app会让你有同样的感觉,而且它的原型确实仅用一个周末,利用谷歌云端平台的Vision API和React Native打造出来的。
但上架应用市场的最终版是我们又花了几个月的时间(兼职)打磨出来的。我们做了一些外行们不能理解的优化。我们花了数周最大化了应用的准确度,AI训练时间,测试时间,以及迭代我们的setup和tooling,这些工作使我们的迭代开发更高效。
另外,我们还花了一整个周末优化在iOS和安卓上的用户体验(不说了,说多了都是泪啊
平时大多数技术博文和学术文章都会跳过这个部分,直接展示他们最终的方案。但为了能给大家一个前车之鉴,我们在这里把我们试过的不可行方案缩略一下放在这里。在这之后我们会介绍最后成功了的方案。
1、原型
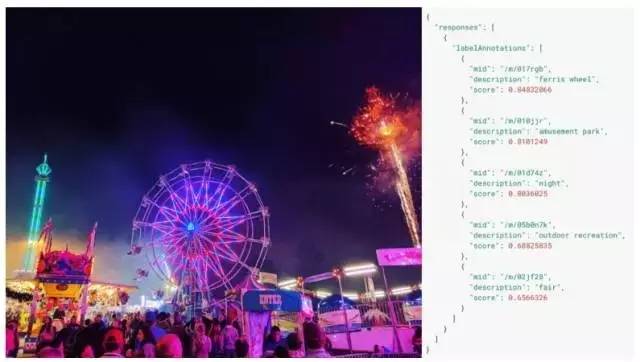
Google Cloud Vision文档的示例图像和相应的API输出
我们选择用React Native来搭建原型是因为,一方面它是块很好的试验田,另一方面它能帮助我们很快地支持许多设备。事实证明我们的选择是正确的。
在这个项目后续的工作中,我们依旧保留了React Native:虽然它并没有一直简化我们的工作量,而且我们特意限制了这款应用的设计,但最终React Native还是胜任了这项工作。
我们在制作原型时所用的- 谷歌云端的Vision API很快就被我们弃用了。原因有以下三条:
它识别热狗的准确率很一般。虽然它擅长识别大量物件,但你单单让它识别一种东西就很困难了。在我们2016年试用它的时候就有许多失败的案例。
因为它是云端服务的原因,它会比在设备上运行慢得多(网!太!慢!),而且不支持离线功能。而且一旦照片离开设备就会触发一些涉及隐私和法律条款的考虑。
最后,一旦应用上线,使用谷歌云端服务的费用就会很高昂。
考虑到这些因素,我们开始尝试现在流行的“边缘计算”,在这里意味着先在我们自己的笔记本电脑上训练神经网络,然后再将其传输并直接嵌入我们的移动设备。这样的话,神经网络执行推理,就能直接在用户手机上运行了。
2、TensorFlow,Inception结构和转移学习
通过一次偶然的机会和TensorFlow团队的Pete Warden聊过后,我们意识到了TensorFlow能够直接嵌入一个iOS设备中运行的能力,所以我们开始往这个方向上探索。在React Native之后,TensorFlow成了我们第二个敲定下来的开发工具。
我们只花了一天时间,就把TensorFlow的Objective C++相机示例整合到我们的React Native的库里,使用他们的迁移学习脚本(transfer learning script)花了多一点的时间。
迁移学习脚本能够帮助你重新训练插Inception结构,使其能够处理更具体的图片问题。Inception是谷歌用于解决图片识别问题时搭建的一组神经结构的名称。有的Inception是训练完毕并且设置过权重的。绝大多数情况下,图片识别网络都在ImageNet上训练过。
ImageNet每年都会举办比赛,旨在挖掘能够最好地识别超过两万种不同物品(包括热狗)的神经网络结构。但是就像谷歌云端的Vision API,这个比赛虽然横向纵向都有筛选,但面对两万物品的识别,算法仍有所欠缺。这种情况下,迁移学习就是要拿出一套经过完整训练的神经网络,把它重新训练成一个能够更好完成单项具体任务的工具。
这就牵扯到一定程度的“遗忘”,要么就直接剪切stack里的整个一层,要么就慢慢擦掉神经网络中分辨其他物件(比如说椅子)的能力,转而专注于识别你需要的物件(在这个应用中就是热狗了)。
所说到的这个神经网络(Inception)是用了ImageNet里1400万张图训练出来的,我们只用了几千张热狗的图片,就大大提高了它对热狗的识别能力。
迁移学习的最大好处就是,你能比从零开始更快地获得更好的结果,并且还用不着使用很多数据。一套完整的训练不仅需要用多个GPU和上百万图片,而且要耗费几个月的时间。迁移学习一般能在几小时之内用一台笔记本电脑和两三千张图搞定。
我们遇到的一大难题是,确定哪些称得上是热狗而哪些不是。
定义“什么是热狗”竟出乎意料的难(切成一段一段的香肠算不算?如果算的话,哪些肠可以呢?),而且这还牵扯到不同文化和地域对热狗的理解。
同样的,app这种开放式的环境意味着我们需要处理几乎无限多的用户输入。虽说有一些计算机识别问题是相对有限的(比如用X光图来检查螺栓有无质量缺陷),我们所面临的将会是自拍,风景照,和大量的食物图片。
可以说,这种开发方式是不错的,而且也确实带来了优化结果。但是,我们因为以下两个原因弃用了这种方式:
第一,我们的训练数据一定是严重失衡的,因为“不是热狗”的例子要比“是热狗”的例子多得多。
这就意味着,如果你用3张热狗图和97张非热狗图来训练你的算法,就算它识别的结果显示有0%的热狗和100%的非热狗,那么默认来说它的准确率仍高达97%!这就算使用TensorFlow进行迁移学习也不能直截了当地解决。换句话说,这基本上就告诉我们必须得用深度学习模型从头来控制训练和导入权重了。
这个时候我们决定硬着头皮上,利用Keras(一款深度学习软件库,在TensorFlow的基础上提供更加美观便捷的抽象abstractions)重新开始。
Keras里自带了一些很厉害的训练工具, 以及一个权重类别的选项,完美符合我们这种训练数据严重失衡的情况。我们利用这个机会试用了诸如VGG的其他时下流行的神经结构,但一个问题迟迟没有解决:这些结构都不能很好地与iPhone兼容。
它们占了太大的内存,导致其他app崩溃。还有一点就是它们计算处理的时间有时需要10秒以上,这从用户体验的角度来说是很不妙的。我们试过很多方式试图减轻这个问题,但是最终这些神经结构对于手机来说还是太大了。
3、Keras和SqueezeNet
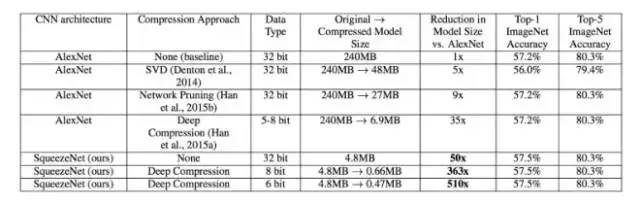
图:SqueezeNet SqueezeNet 与AlexNet(计算机视觉架构鼻祖)
给你一个的时间概念吧,这大概是我们项目的中间点左右。到这时,用户界面已经完成90%了,基本不会做什么改动了。但是事后看来,当时的神经网络最多只做了20%。
我们对难度有了一定的把握,也有了一个不错的数据组,但最终的神经结构代码还一行都没码呢。当时我们的神经代码还不能稳定地在手机上运行,我们的准确率甚至都要在之后的几周里才会有显著的提升。
我们所面临的最直接的问题很简单,如果Inception和VGG都太大了,那么有没有一个更简单的,训练完毕的神经网络能够让我们用来迁移学习的呢?
我们探索了Xception,Enet和SqueezeNet。我们很快就决定使用SqueezeNet。
SqueezeNet拥有明确的定位功能,这可以作为嵌入式深度学习的解决方案。另外,在GitHub上有训练完毕的Keras模型可以调用(耶!开源网站!)
那么这可以造成多大的差别呢?一个像VGG这样的结构需要用到差不多一亿三千八百万个参数(模拟神经元和神经元间数值的必要数字)。Inception已经有了很大提高了,只需用2300万个参数。SqueezeNet比较下来只需要125万个参数。
这会带来两个好处:
在训练过程中,使用一个小型网络要快得多。内存中没有这么多参数需要map,这就意味着你可以进行同时训练(增大批量),而且神经网络会汇集(预估出数学公式)得更快些。
在开发过程中,这个模型更小更快。SqueezeNet只需要10MB以内的RAM,而像Inception这样的会需要100MB以上的RAM。这个差距很大,而且还特別重要,因为有些移动设备没有100MB的RAM。小型的神经网络运算起来也比大的更快捷。
当然,既然有得就有失:
小型神经系统的“记忆力”就不行了:它处理不了复杂的任务(比如识别两万个不同的物件),甚至连复杂从属项(比如分辨纽约式热狗和芝加哥式热狗)都傻傻分不清。
就此推论,小型的神经网络总体来说在准确率上会逊于大型神经网络。当试图识别ImageNet的2万种不同物件时,SqueezeNet的准确率只有58%,而VGG的是72%。
在小型神经网络上使用迁移学习也更难一些。理论上来说,我们是可以用对付Inception和VGG一样的办法,来处理SqueezeNet的:先让它遗忘一些信息,然后重新特别训练它识别热狗和非热狗的能力。
但在实际应用过程中,我们发现这种方式使得我们很难调整学习进度,而且得到的结果总是没有从零开始训练SqueezeNet来的好。这个问题也有可能来源于我们项目的开放性(用户自己拍照上传图片)。
一般来说,小型神经网络很少会出现过拟合(overfit)的情况,但我们在使用几个“小”结构的时候遇到过这样的问题。过拟合意味着你的神经网络太专一了,只能识别你训练它的热狗照片而不能举一反三融会贯通。
用人类的例子来类比就好像一个人仅仅记住了你给他看得那张热狗照片,而不会把概念抽象化,无法意识到热狗就是一根香肠夹在面包里,有时会佐以调味料等等。如果你给他看一张全新的热狗照片(和原来那张不同),他会说这不是热狗。
因为一个小型神经网络通常“记忆力”更差一些,那么我们不难理解,为什么对于它们来说专攻一件物品会更难一些。但是有好几次,我们的小型神经网络的准确率一下跳到99%,然后突然就不能识别之前训练中没有出现过的图片了。
这种问题在我们加入足够的数据集后就消失了。数据集在这里意味着我们会对导入的图片做适当的随机改动(拉伸或扭曲),所以相较于一千张图里的每一张都训练一百次,我们用对这一千张图进行有意义的改动,使得神经网络不会仅仅记住图片,而是记住热狗的组成(面包,香肠,调味料等等),与此同时又不失灵活变通的能力(而不是记住某一张图里的特殊像素)。

Keras Blog里的数据示例
在这段时间里,我们开始尝试着精调神经网络结构。特别是我们开始使用批规范化(Batch Nomalization),并尝试了不同的激活函数(activation functions)。
批规范化能够通过将stack里的数值”光滑化“来帮助你的神经网络学得更快。具体为什么批规范化能有这个功能还没有被完完全全理解,但它能使你的神经网络用更少的训练达到更高的准确率,或者用同样多的训练一下子达到更高的准确率。
激活函数是一种内部函数,用来检测你的“神经元”是否被激活。很多学术文章中仍使用ReLU(Rectified Linear Unit 线性整流函数),但我们用ELU获得了最好的结果。
在给SqueezeNet加上批量范化和ELU之后,我们从零开始,训练出了准确率在90%以上的神经网络。但是,我们的神经网络还是相对比较脆弱的,这意味着同样的网络会在有些时候过度拟化,但在面对实际测试时又会出现拟化不足的情况。就算是在数据组里增加更多的范例并且增加训练数据也没能达到我们的预期。
所以尽管这个阶段的工作成效不错,而且做出了一个完全能在iPhone上使用的app,但瞬间我们就转移到我们的第四个,也就是最后一个结构了。
三、DeepDog结构
from keras.applications.imagenet_utils import _obtain_input_shape
from keras import backend as K
from keras.layers import Input, Convolution2D, SeparableConvolution2D, \
GlobalAveragePooling2d \
Dense, Activation, BatchNormalization
from keras.models import Model
from keras.engine.topology import get_source_inputs
from keras.utils import get_file
from keras.utils import layer_utils
def DeepDog(input_tensor=None, input_shape=None, alpha=1, classes=1000):
input_shape = _obtain_input_shape(input_shape,
default_size=224,
min_size=48,
data_format=K.image_data_format(),
include_top=True)
if input_tensor is None:
img_input = Input(shape=input_shape)
else:
if not K.is_keras_tensor(input_tensor):
img_input = Input(tensor=input_tensor, shape=input_shape)
else:
img_input = input_tensor
x = Convolution2D(int(32*alpha), (3, 3), strides=(2, 2), padding='same')(img_input)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(32*alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(64 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(128 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(128 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(256 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(256 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
for _ in range(5):
x = SeparableConvolution2D(int(512 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(512 * alpha), (3, 3), strides=(2, 2), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = SeparableConvolution2D(int(1024 * alpha), (3, 3), strides=(1, 1), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('elu')(x)
x = GlobalAveragePooling2D()(x)
out = Dense(1, activation='sigmoid')(x)
if input_tensor is not None:
inputs = get_source_inputs(input_tensor)
else:
inputs = img_input
model = Model(inputs, out, name='deepdog')
return model
1、设计
我们最后的结构很大一部分是受谷歌在4月17日在MobileNets论文的启发。这篇文章称谷歌会推出一个新的神经结构,这个结构只用4百万左右的参数就能在我们这种简单的项目上达到能与Inception相媲美的准确率。
这意味着它是SqueezeNet(对我们的意图来说过度简化的结构)和Inception/VGG之间的完美权衡。这篇文章还提到了该神经网络调整大小和难度的功能,能够在内存和准确率之间取舍,这可解决了我们当时的心头病。
距离app必须上线的不到一个月的时候,我们热切地想要重建文章中的结果。然而戏剧性是,在文章发布的当天,一个来自伊斯坦布尔工业大学的学生Refik Can Malli率先在GitHub上公开提供了Keras的代码。
我们最后的结构和MobileNets的结构,或者说与传统的结构有显著的不同,尤其是:
我们在处理时候没有使用批量范化, 因为Xception的文章(特别详尽地讨论了深度网络上的卷积)似乎在指出批量范化实际上会使我们的这种结构准确率下降。不使用批量范化同时还能减小我们的神经网络大小。
我们用ELU取代了ReLU。就像我们之前的SqueezeNet实验,ELU相较ReLU提供了更高的融合速度和准确度。我们并没有使用PELU。因为虽然好用,但这个激活函数似乎在我们每次使用它时都会陷入二进制状态。所以我们的我们网络的准确率在从一个批量到达另一个批量的时候会在0%和100%中往复,而不是循序渐进地增长。这个问题发生的原因我们也不清楚,有可能是因为implementation错误或是用户错误。我们试着合并图片中的宽/高轴,但没有成效。
我们没用SELU。在对iOS和安卓的发布(release)进行了一番调查后,得到的结果与PELU的非常类似。我们怀疑SELU不能作为一种激活函数的捷径来单独使用。事实上,正如文章的题目映射的,SELU是狭义SNN结构中的一部分。
我们在使用ELU的时候继续使用了批量范化。虽然有很多迹象表明这一步是不必要的,但是我们每次运行试验的时候,如果没加批量范化就无法融汇。这有可能是因为我们结构太小。
我们是在激活之前使用批量范化的。虽然这是最近大家热议的主题,但我们在小型神经网络上在激活之后加入批量范化的试验都不能很好的融汇。
为了优化神经网络,我们使用了周期学习率(Cyclical Learning Rates,CLR)以及(小伙伴)Brad Kenstler的 Keras 模型)。CLR可以扎实地找出训练时的最优学习进度(optimallearning rate)。更重要的是,通过上下调整学习进度,它能帮助我们达到比传统优化器更高的最终准确率。因为以上的两个原因,我们决定以后都用CLR来训练神经网络。
我们觉得没有必要调整MobileNets结构里 α 或 ρ 的值。因为我们的模型足够小,在α = 1的时候足以达成目标。ρ = 1我们的运算也足够快了。但是,如果比较旧的移动设备或者嵌入式平台上运行的话就有必要调整了。
所以这个stack是怎么工作的?深度学习经常给大家一种“黑盒”的感觉。但虽然很多部分确实比较神秘,但我们所用的神经网络经常会向我们泄露一些信息,以揭露它是如何工作的。我们可以看到stack里的层以及这些层是如何激活特定的输入图片的。这告诉了我们每一层分别识别香肠,面包,以及热狗的其他特点的能力。

2、训练
数据的质量是至关重要的。提供的训练数据有多好,这个神经网络结构才会好。提高训练数据的水准是我们在这个项目上最花时间的三件事之一。
我们所做的比较关键的提升有以下这些:
获取更多图片以及更多样化的图片(长宽,背景,灯光,文化差异,透视远景,构图等等)。
将图片类型比对到预期的产品输入值(用户图片)。我们的猜测是,人们大多数情况下用户会拍摄热狗或其他其他食物的图片,或者有的时候人们会试图用随机的物品来考验该应用,所以我们的在建立数据组的时候考虑到了这些因素。
给你的神经网络提供一些可能会以假乱真的相似图片。和热狗最容易混淆的是其他的食物(比如汉堡,或者光是香肠,亦或是小胡萝卜和烧熟的小番茄)。我们的数据组中体现了这一点。
预期的图片扭曲:在手机的情况下,大多数图片的质量会比用单反的“平均水平”要低。手机摄像时的灯光也不尽如人意。移动设备拍摄的照片一般会更暗或者有一定的角度。大规模的数据集是解决问题的关键。
另外我们还推测如果用户手头上没有热狗,他们会在谷歌上搜索热狗的图片,然后用手机拍摄电脑频幕,而这会导致另一种扭曲(如果拍照有角度会造成图片的倾斜,如果用手机相机拍摄液晶显示器还会有光点和和明显的莫列波纹)。
这些特定的扭曲很容易迷惑我们的神经网络,这和最近发表的一些有关卷积网络难以抵抗噪音的学术文章有异曲同工之处。利用Keras的通道转换(channel shift)功能可以解决大部分问题。

图:Wikimedia 扭曲示例:莫列波纹和光点。
有些边边角角的问题很难察觉。尤其是用柔焦或背景虚化得到的照片有时也会迷惑我们的神经网络。这个问题很难解决。
第一,用柔焦拍摄的热狗照片很少(我们想想就饿了)。
第二,如果我们花大量神经网络容量来训练识别柔焦的能力是弊大于利的,因为绝大多数用移动设备拍摄的图片没有这个功能。我们选择基本不考虑这个问题。
我们最后的数据组是15万张图片,其中只有3000张热狗的照片:热狗只有这么点,但不是热狗的东西多了去了。这里49:1的失衡我们用Keras类的权重设置来弥补。其余的14万7千张图中大多数是食物,有大概三千张不是食物,这能够帮助我们的网络更好地融会贯通,不被一个穿着热狗外衣的实物所迷惑。
我们数据扩容的条件如下:
我们所添加的旋转在 ±135 度之间-远大于平均值,因为我们敲代码的时候不考虑手机的方向。
高和宽移动20%
剪切范围30%
缩放范围10%
通道转换(channel shift)20%
随机水平翻转以帮神经网络提高概括归纳的能力
这些数字都是我们基于尝试和我们对该app实际运用理解的直觉所得,并不是严谨地通过实验得来的。
我们数据准备中的最后关键就是运用Patrick Rodriguez的Keras 多进程图像数据生成器(multiprocess image data generator)。
虽然Keras有自带的多线和多元处理的implementation,我们试验发现Patrick的数据库运行得更快(具体原因我们还没空仔细研究)。这个库帮助我们将训练时间缩短了三分之二。
这个神经网络是在用一台2015 MacBook Pro以及外接的GPU训练的。我们当时的eGPU用的是Nvidia GTX 980 Ti,但如果我们现在开始做的话会买一个1080 Ti。
我们当时能以128张图片一批的速度训练网络。我们的神经网络一共训练了240次(epoch),也就是说我们运行15万张图用了240次。这花了80个小时。
我们分以下三个阶段训练神经网络:
第一阶段运行112次训练(以一级8次训练来完成7个完整的CLR cycle)。
我们的学习率在0.005到0.03之间,基于triangular 2 方法(意思是最大学习率每16次就减半一次)。
第二阶段再运行64次训练(以一级8次训练来完成4个CLR cycle),学习率在0.0004到0.0045之间,仍基于triangular 2 方法。
第二阶段再运行64次训练(以一级8个训练来完成4个CLR cycle),学习率在0.000015到0.0002之间,仍基于triangular 2 方法。
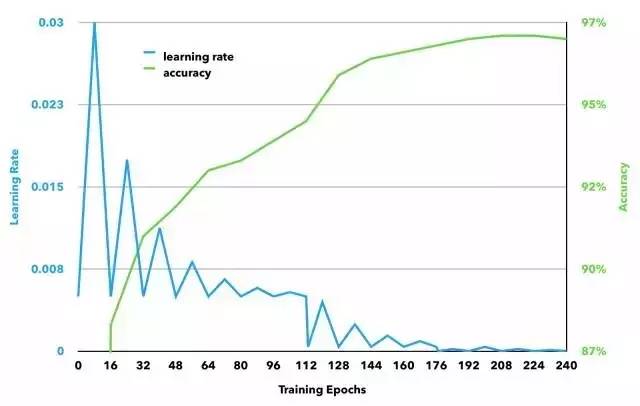
更新:之前一版的图表有错误信息
虽然学习率是通过运行由CLR文章所推荐的线性实验所得,但实际上这些数字还是不难理解的。每一接单的最大值都是前一阶段最小值的一半左右,这与行业里推荐的标准(如果在训练时遇到准确率的平台期,要减半你的学习率)是相符的。
为了节省时间,我们有一部分训练是在一个Paperspace P5000运行实例(instance)的Ubantu上进行的。在这部分训练中,我们能够将批量大小翻倍。我们发现这样的话,每个阶段的最优学习率也差不多翻倍了。
3、在手机上运行神经网络
虽说我们已经搭建了一个相对紧凑的神经结构,而且也将其训练成了可以适应移动环境的结构了,但我们还要做不少工作才能让它很好地运行。试图直接运行这种高级神经网络结构很快就会消耗几百MB的RAM,而现在的大多数手机都没有这么多余的内存了。抛开优化神经网络不说,你操作图片的方式,甚至加载TensorFlow本身都会对你的神经网络运行速度、RAM使用量以及濒临系统崩溃的用户体验带来影响。
这可能就是这个项目最神秘的部分了。关于它我们几乎找不到任何信息,这或许是因为目前在移动设备上运行深度学习应用的例子少之又少。但是,我们在这里要感谢TensorFlow的团队,特别是Pete Warden,Andrew Harp和Chad Whipkey的耐心。
通过化整我们神经网络的权重,我们把网络大小压缩到了原来的四分之三。
最终,不同于使用我们训练中任意的存储值,我们的这项优化会选出N个最常出现的值,并将你的神经网络中所有的参数设置成这些值。这在压缩之后可以减小神经网络的大小。
然而这对于未经压缩的app大小或内存用量是没有任何影响的。我们并没有把这项优化放到最后的产品上,因为一方面我们的神经网络已经足够小了,另一方面,我们没有时间量化这项化整对于app准确率的影响。
通过将TensorFlow软件库编译到iOS系统来对其进行优化。
从TensorFlow软件库中移除不必要的运算法则:TensorFlow从某种意义上而言是一台虚拟机器(virtual machine),它能够理解一个数字或者任意TensorFlow运算法则:相加,相乘,字串串接(Concatenation)等等。
你可以在编译到iOS的过程中,通过从TensorFlow软件库中移除不必要的运算法则,来省下很大一部分内存。
其他的提升也可行。比如,笔者的另一项不相干的工作歪打正着地在安卓二进制大小上有了1MB的提升。所以由此可以推测,在TensorFlow的iOS代码中也有地方可以改进优化。
除了在iOS上使用TensorFlow这个选项,我们还关注过Apple自带的深度学习软件库(BNNS, MPSCNN以及后来的CoreML)。我们本可以在Keras上设计神经网络,在TensorFlow上训练,然后导出全部的数值,重新再BNNS或MPSCNNimplement(也可以直接由CoreML导入),然后将参数加载到新的implementation上去。
但是,这些新的Apple软件库的最大障碍就是它们只能在iOS 10+上使用,而我们想让app在更早版本的iOS上也能够使用。随着iOS 10+被公众使用采纳,以及框架的更新换代,在不久的将来,我们或许就不需要再用TensorFlow了。
#import <CodePush/CodePush.h>
…
NSString* FilePathForResourceName(NSString* name, NSString* extension) {
// NSString* file_path = [[NSBundle mainBundle] pathForResource:name ofType:extension];
NSString* file_path = [[[[CodePush.bundleURL.URLByDeletingLastPathComponent URLByAppendingPathComponent:@"assets"] URLByAppendingPathComponent:name] URLByAppendingPathExtension:extension] path];
if (file_path == NULL) {
LOG(FATAL) << "Couldn't find '" << [name UTF8String] << "."
<< [extension UTF8String] << "' in bundle.";
}
return file_path;
}
…
AIManager.mm hosted with ❤ by GitHub
import React, { Component } from 'react';
import { AppRegistry } from 'react-native';
import CodePush from "react-native-code-push";
import App from './App';
class nothotdog extends Component {
render() {
return (
<App />
)
}
}
require('./deepdog.pdf')
const codePushOptions = { checkFrequency: CodePush.CheckFrequency.ON_APP_RESUME };
AppRegistry.registerComponent('nothotdog', () => CodePush(codePushOptions)(nothotdog));
index.ios.js hosted with ❤ by GitHub
我们的项目还有什么不同?
其实还有很多事情我们没时间做的或者试过没成的,这些是我们日后所要探索的想法:
更仔细地精调我们数据增长参数。
端到端,即应用程序最终确定的抽象方法,如我们的应用程序是否有2个或更多类别的热狗识别阈值是什么(我们最终有应用程序说“热狗”如果识别大于0.90,而默认值为0.5),重量加倍等。
在app中添加一个反馈机制 -- 如果出现错误时可以允许用户吐槽,或者能够app主动优化神经网络。
使用比224 x 224像素更高的图片识别分辨率。最终我们要使用一个大于1.0的MobileNets ρ 值。
4、用户体验 ,开发者体验以及AI 的恐怖谷
最后,我们要说说用户体验,开发者体验以及内置偏见给一个AI app开发造成的巨大影响。每一点我都可以再写一篇博文(甚至一本书),但是在这里我们就讲讲这三件事儿在我们自己的经验中非常扎实的影响。
用户体验在AI app开发中的每一阶段都要比传统app来的关键。目前还没有深度学习算法可以带给你完美的结果,但是有很多情况中,深度学习和用户体验的合适组合会带给你几近完美的结果。
合适的用户体验预期无可替代,尤其可以将开发人员在设计神经网络时引向正途, 对使用软件的用户设定合适的预期,并且帮助解决无可避免的AI bug。如果搭建AI app没有用户体验为上的理念,就好象不用随机梯度下降法(Stochastic Gradient Descent)来训练神经网络:你会最终在搭建完美AI的途中陷入恐怖谷(Uncanny Valley)的最低值。
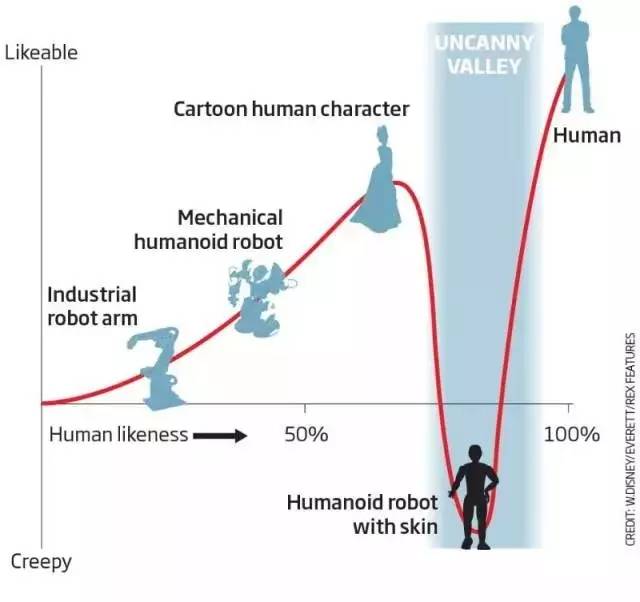
图: New Scientist
开发者体验同样至关重要,因为深度学习训练需要花费很长的时间,而且你要等程序训练完才能运行。我们建议你先注重开发者体验,因为之后总能优化运行时间(手动GPU并行,多元数据注入,TensorFlow管道,甚至可以重新implement你的caffe2 / pyTorch)如果有了好用的,而且维护得很好的训练及运行神经网络的环境,即使你用的是像TensorFlow那样相对初级的API和文档,你的开发者体验也会得到大大的提升。
同样的道理,你很难以低廉的价格获得拥有在本地GPU环境下,来自主开发的灵活性。能够在本地查看/编辑图片,并且使用你喜欢的工具来编辑代码,可以大大提升开发AI项目的质量和速度。
说到AI app的自带偏见,可能绝大多数的其他AI应用会遇到比我们更棘手的问题。但就连我们这款简单的app都会遇到文化偏见的难题。比如,我们的app无法识别法式热狗,亚洲热狗,或者其他我们没有接触到的种类。
我们需要认识到的是,AI并不能做出比人类更好的决策,它们是由不完美的人类设计出来的,那么它们沾染上人类的偏见也是无可厚非的。
感谢所有用过并分享这款app的伙伴们!我们这几个月来天天盯着热狗的图片,打开门看窗外满世界都是热狗了......
作者: Tim Anglade
编译:瑶瑶领先
原文:http://t.cn/RKqcNrm
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。

公众号底部菜单有惊喜哦!
企业,个人加入组织请查看“联合会”
往期精彩内容请查看“号内搜”
加入志愿者或联系我们请查看“关于我们”






