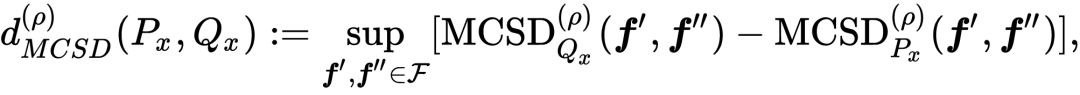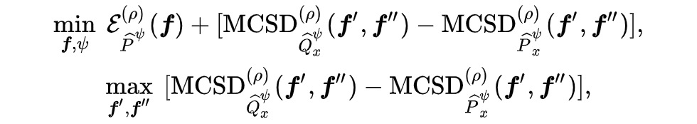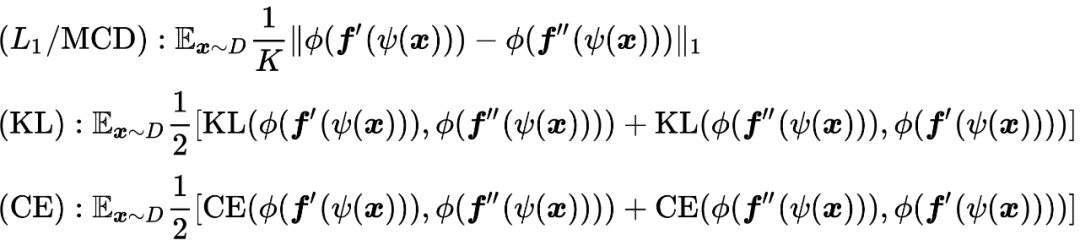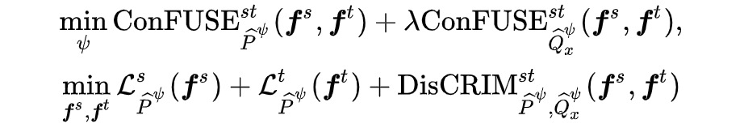©作者|张亚斌
学校|香港理工大学
研究方向|迁移学习
本文介绍我们最近的一篇 TPAMI 工作:Unsupervised Multi-Class Domain Adaptation: Theory, Algorithms, and Practice。
Unsupervised Multi-Class Domain Adaptation: Theory, Algorithms, and Practice
https://arxiv.org/abs/2002.08681
https://github.com/YBZh/MultiClassDA
理论方面: 基于对 score functions 差异的充分度量,我们提出了 MCSD divergence 来充分衡量两个 domain 的 divergence;进而引出新的 theoretical bound.
算法方面: 基于 MCSD divergence 提出了两个新的算法框架:McDalNets 和 SymNets. McDalNets 统一了 MCD, DANN, MDD 等经典算法,SymNets 对我们 CVPR 论文的初始版本进行了改进。
实践方面: 在 Closed set, partial, and open set 三个任务多个数据集上验证了我们方法的有效性。
域适应(domain adaptation)是迁移学习中的重要课题。该课题的目标是:
输入有标签的源域数据和无标签的目标域数据,输出一个适用于目标域的模型。 源域和目标域假设任务相同但是数据分布不同。
既然源域和目标域的数据分布不同,该任务的经典解决方法是:
找到一个特征空间,将分布不同的源域和目标域数据映射到该特征空间后,希望源域和目标域的数据分布差异尽可能小;这样基于源域数据训练的模型,就可以用于目标域数据上。
因此如何找到该特征空间,更具体来说,如何衡量两个域数据分布之间的差异是域适应任务的核心问题。
通过对抗训练的方式实现两个域的数据分布对齐在域适应任务中被广泛采用
[1]
。近期很多对抗域适应的算法采用特征映射网络和分类器进行对抗的方式
[2,3,4,5]
。
虽然基于分类器进行对抗训练的方法
[2,3,4,5]
取得了不错的结果,但是这些算法与现有理论并不是完全吻合的;也就是说,理论和算法之间存在一定的差距。出于此目的,我们对现有的域适应理论进行了改进,使其可以更好的支撑现有算法。
同时,基于该理论框架,我们提出了一系列新的算法,并在 closed set, partial, and open set 域适应三个任务上验证了其有效性。该文章的要点可以总结如下:
1. 理论方面:提出了 Multi-Class Scoring Disagreement (MCSD) divergence 来衡量两个域数据分布之间的差异;其中 MCSD 可以充分衡量两 个 scoring hypotheses(可以理解为分类器)之间的差异。基于 MCSD divergence, 我们提出了新的 Adaptation Bound,并详细讨论了我们理论框架和之前框架的关系。
2. 算法方面:基于 MCSD divergence 的理论,我们提出了一套新的代码框架 Multi-class Domain-adversarial learning Networks (McDalNets)。McDalNets的不同实现与近期的流行方法相似或相同,因此从理论层面支撑了这些方法
[2,3,4,5]
。此外,我们提出了一个新的算法 SymmNets-V2, 该方法是我们之前会议工作
[3]
的改进版本。
3. 实践方面:我们在 closed set, partial, and open set 三种实验设置下验证了我们提出方法的有效性。
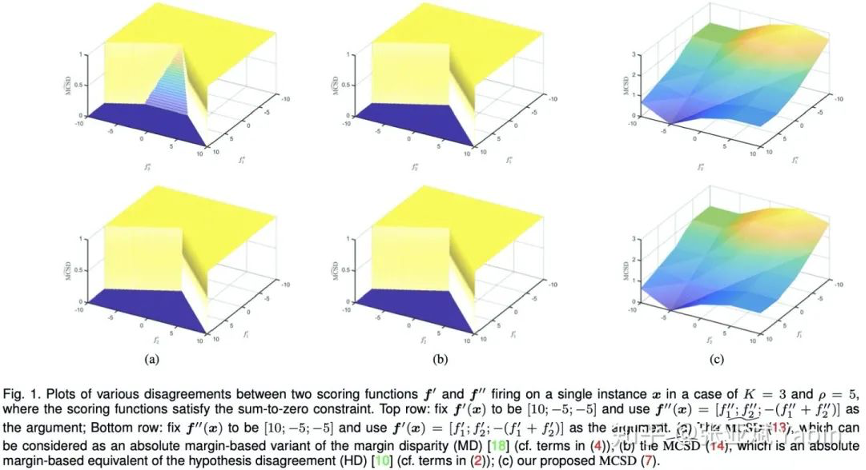
如上文所言,如何衡量两个域之间的差异是域适应任务的核心问题。为了更加细粒度地衡量两个域之间的差异,我们引入了如下的 MCSD divergence:
充分衡量了 scoring functions
在域 D 上的不一致性(相对于下面将要描述的其他度量方法)。
是 ramp loss,
指代 absolute margin function
的第 k 个值。上述定义有些复杂,我们接下来对其直观描述:
的每一列
计算了 violations of absolute margin function
,进而
度量
了
之间margin violations 的差异,一个直观的例子如 Fig 1(c) 所示:
到了这里,大家应该会疑惑:这个 MCSD divergence 看上去挺复杂的,它有什么好处?MCSD 的优势如下:
理论角度:MCSD 可以充分度量 两个 scoring functions 的差异!!同时导出后续的 bound.
算法角度:对 scoring functions 的差异的充分度量可以直接支撑基于分类器进行对抗训练的方法 [2,3,4,5].
为了展示 MCSD 对 scoring functions 差异的充分度量,我们基于 absolute margin function
引入其他 domain divergence
[6,7]
的变种或等效形式。
基于 MCSD divergence, 我们可以得到如下的 bound:
,其中
是 targer error,
是 source error,
可视为与数据集合 hypothesis space 相关的常数。相应的 PAC bound 也可以导出。
总的来说,我们提出了一种 MCSD divergence 来充分度量两个 scoring functions 的差异,进而提出了一种新的 adaptation bound. 那么充分度量两个 scoring functions 的差异有什么好处呢?后续的对比实验经验性的回答了该问题。
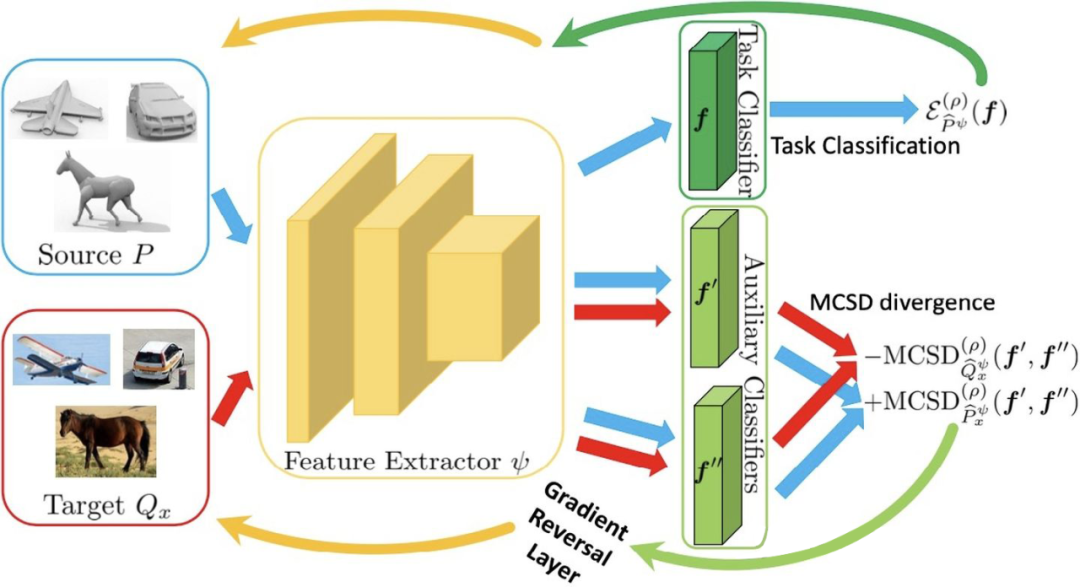
上述理论可以推导出一系列的算法,我们将这些算法统一命名为 McDalNets。基于上述 bound, 为了最小化 target error
,我们需要找到可以最小化
的 feature extractor
以及可以最小化 source error
的
和
。将
展开成
的形式可以得到如下的优化目标:
其中
分别是分布
,
经由映射
得到的特征分布。该优化目标如下图所示:
上 述目标仍然难以直接优化,因为 ramp loss
会导致梯度消失的问题。为了便于优化,我们引入了一些 MCSD 的替代度量方法。这些替代度量方法应该具有如下特点:
当
在 domain 上的输出越趋于一致,替代度量方法的值越小
当
在 domain 上的输出越差异越大,替代度量方法的值越大
我们在本文中采用了三种 MCSD 的替代度量方法,分别是:
其中
是 softmax 函数,
是 KL 散度,
是交叉熵函数。其他具有上述两点特点且便于优化的函数都可以用来作为 MCSD 的替代度量方法。
当采用
loss 作为替代度量时,McDalNet 与 MCD
[2]
方法极其相似。需要强调的是,虽然 MCD 算法是从
-divergence
[7]
推导而出的,但是 MCD 算法与
-divergence 存在明显 gap:MCD 算法采用 L_1 loss 衡量了classifiers outputs 在 element-wise 的差异,而
-divergence只考虑了classifiers 类别预测的不一致性。
考虑到 MCSD 是基于对 classifiers outputs 在 element-wise 的差异的度量,因此 MCSD divergence 可以更直接,更紧密的支撑 MCD 这类基于 classifiers outputs 差异做对抗训练的方法。
类似
,我们也可以基于
和
得到对应的类似 McDalNet 的算法。其中基于
得到的方法完全等效于 DANN
[1]
,基于
得到的方法是 MDD
[6]
的一个变种。
我们将不同 McDalNet 的算法在标准的域适应数据集上进行对比,结果如下图所示:
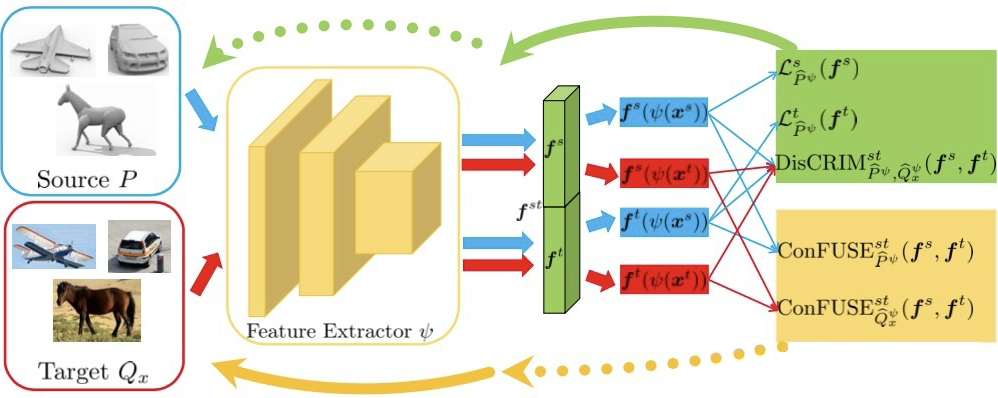
除了上述的 McDalNet 框架,基于 MCSD divergence, 我们还引入了一个 Domain-Symmetric Networks (SymmNets) 的新框架,如下图所示。
该框架是基于 CVPR 的论文
[3]
做的改进,因此我们称之为 SymmNets-V2. 相对于 McDalNets, SymmNets-V2 没有额外的 task classifier,而是将其与 classifiers for 域对齐进行了合并。
该方法在网络结构上的鲜明特点是将两个 classifiers 拼接到一起,并用拼接得到的 classifier 用作域对齐;通过这种方式,我们赋予了两个 classifiers 明确的 domain 信息,同时取得了更优的实验结果。SymmNets-V2 的优化目标如下:
对于熟悉 DANN
[1]
的读者,可以将 SymmNets 看做将 category information 引入 DANN 的直接扩展。具体来说,如果我们分别将
中的所有类别当成整体,那么整体化之后的
就分别对应着 DANN 二分类 domain classifier 中的源域和目标域;
这样 SymmNets 中的增大/减小
的输出差异就对应着 DANN 中的 domain discrimination/domain confusion. 将 DANN 二分类 domain classifier 中的源域和目标域扩展成由
拼接成的 2K 分类器,可以为在域对齐过程中引入 category information 做好模型结构准备。
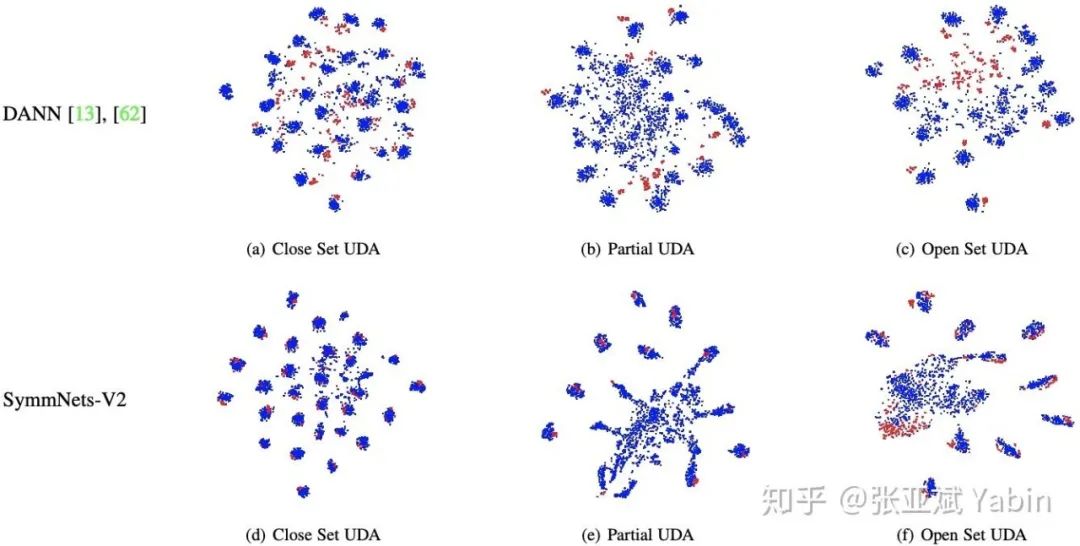
我们在 closed set, partial, and open set domain adaptation 三个任务共七个数据集上验证了我们提出的 McDalNets 和 SymmNets 的有效性。
相对 closed set 的任务,partial and open set domain adaptation 任务中的难度增大很大程度是两个域中共享类别的样本与其中一个域中独有类别的样本在 adaptation 过程中发生了错误对齐带来的;
因此 SymmNets 中对 category information 的引入和对 category level alignment 的促进可以极大的缓解该错误对齐现象,从而对 partial 和 open set domain adaptation 带来帮助。
最后,我们通过如下的 t-SNE 可视化来说明我们提出的 SymmNets 的有效性。
[1] Domain-Adversarial Training of Neural Networks, JMLR16
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。