动态RCNN | 动态训练实现高质量目标检测(附源码)
计算机视觉研究院专栏
作者:Edison_G
今天突然看到这篇有一小段时间的文章了,技术还是很喜欢的,就拿来和大家一起分享。
深入分享之前,我先带大家回顾下之前又一个动态CNN(DCNN(dynamic CNN))的,我们就从这个技术开始,有兴趣的一起来学习!然后我们正式开始一起学习动态RCNN技术及其动态训练。

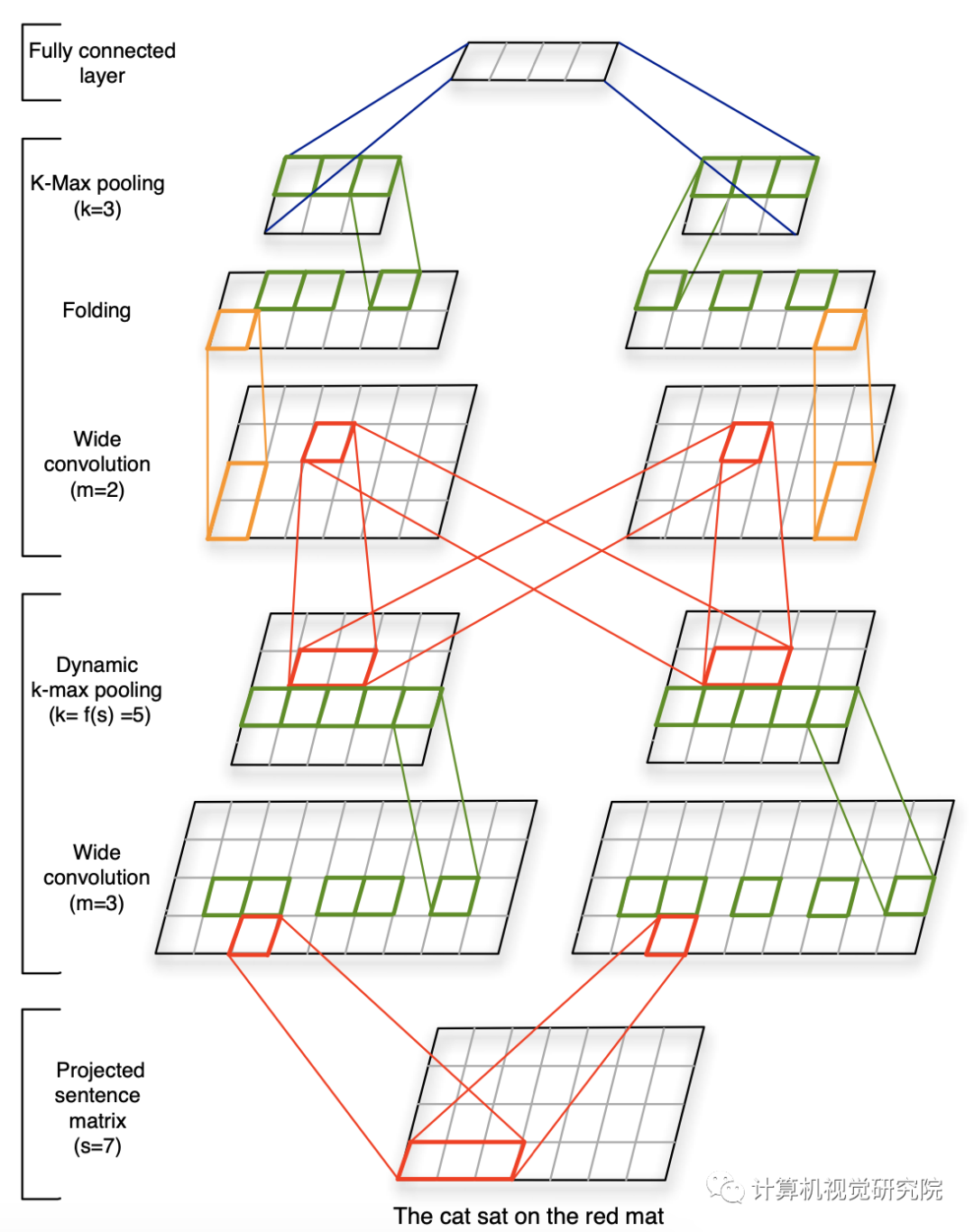
模型采用动态K-max pooling取出得分top-k的特征值,能处理不同长度的句子,并在句子中归纳出一个特征图,可以捕捉短和长期的关系。并且该模型不依赖解析树,适用于任何语言基。
宽卷积
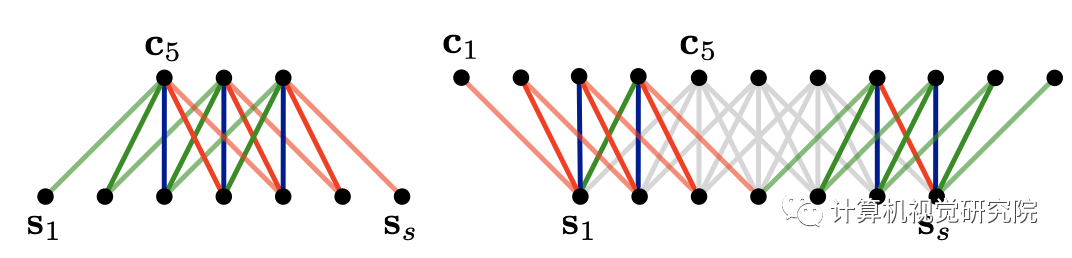
一维卷积一般都用于对文本进行卷积操作,它分为宽卷积(wide convolution)和窄卷积(narrow convolution),宽卷积的输出使feature map 的宽度更宽,类似n-gram,如下图所示:
-
宽卷积可以确保过滤器中的所有权重达到整个句子,包括边缘的单词。 -
宽卷积保证了滤波器应用到输入语句上,总会产生一个有效的非空结果c,独立于滤波器宽度m和句子长度s。
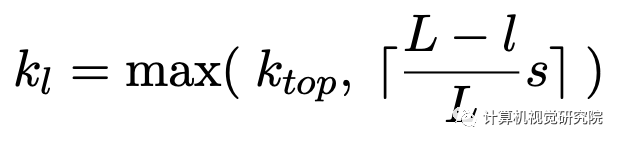
DRCNN
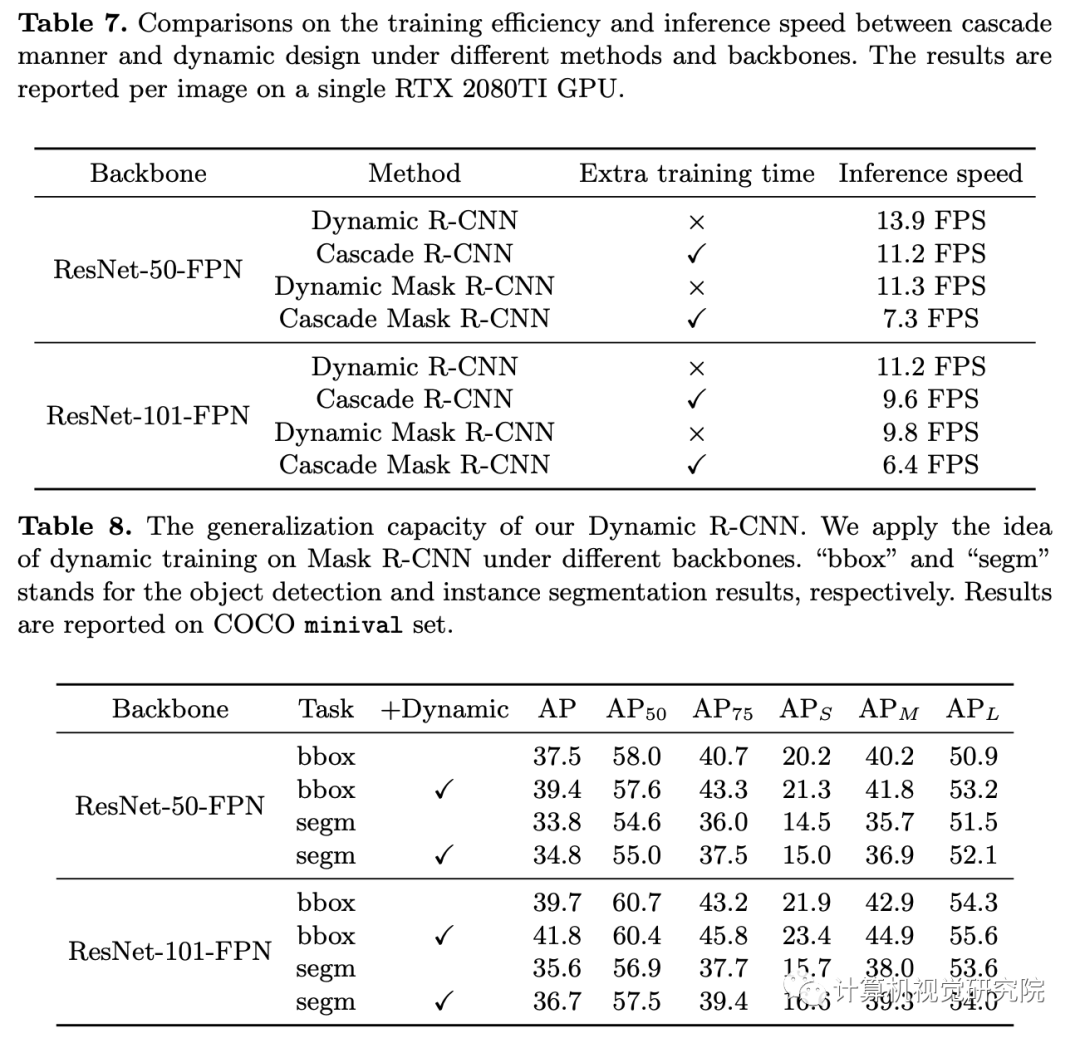
尽管两阶段目标检测算法的模型精度持续占据着金字塔顶,但这类模型的训练过程可以得到改善。首先,动态训练的方法与模型的固定设置之间存在着不一致。如在训练过程中正负样本的分配策略以及回归损失函数形式不能随着样本总体特征的变化而变化。针对以上两点,论文提出的Dynamic R-CNN用于缓解上述问题。
背景:
不同于图像分类里的分类概念,目标检测中的分类是基于标注框进行的。即与图像分类中每幅图像都有明确的类别标签不一样,在目标检测中不存在绝对的准则判断该候选框属于正类还是负类。而在目标检测中常用的用于确定正负样本的方法是设定交并比阈值,如果先验框框与标注框的交并比在某个范围内,则认定其为正样本,否则为负样本。但在训练过程中设定固定的阈值往往不能获得最佳的结果,Cascade R-CNN的解决办法是不断加大阈值,从而不断提高候选框的质量,但这其实是一个级联的检测过程,会引入大量的计算。同时,在边界框的回归过程也存在以上问题。
Dynamic Quality in the Training Procedure:
在目标检测中正负样本的区分策略一直是人们研究的热点,直观上我们认为如果预测框与任何标注框均不相交则视为负样本,如果与某个标注框完全重叠则视为正样本,但如果其和标注框的IoU为0.5时则没有绝对的界定方法。Faster R-CNN中区分正负样本的策略如下:
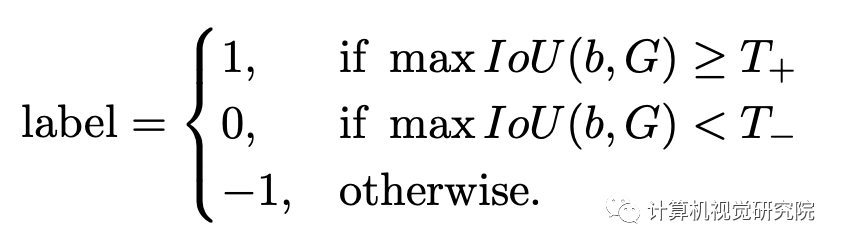
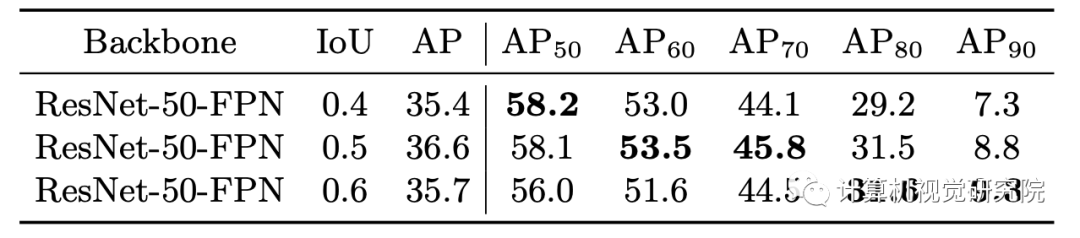
Faster R-CNN中主要通过人为设定的正负样本阈值来区分,这也是现在常用的分配方案。由于分类器的目的是产生正负样本,所以不同的交并比阈值也会产生不同的分类效果。
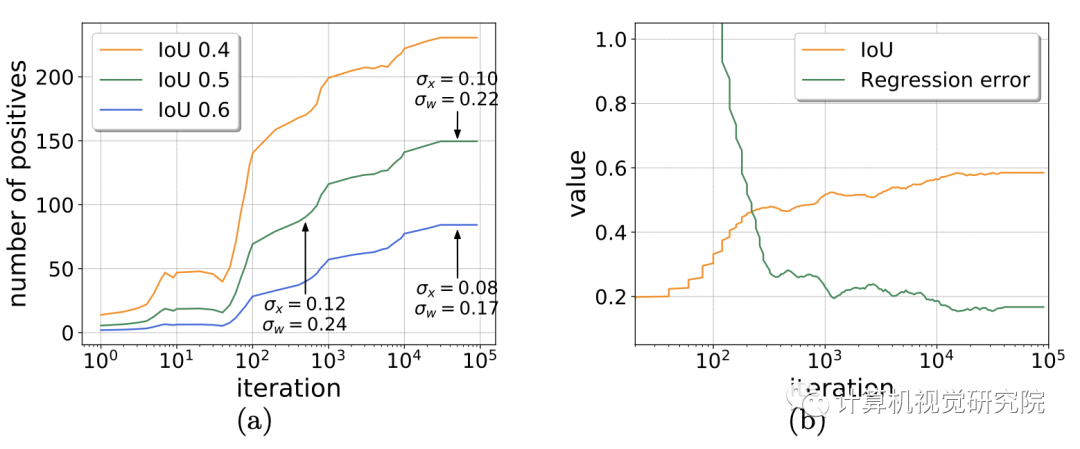
由上表可知,不同指标的最佳结果并没有在同一设定的IoU阈值处,我们理想的结果就是通过某种方法可以在不同检测标准下均得到最佳结果。Cascade R-CNN中通过级联的方式不断增大IoU阈值,从而得到了最佳的效果,但这种方法同时也引入大量额外的计算。直观上,在训练的初始阶段,模型并不能产生大量的高质量样本,这时应设置较低的IoU阈值以获得足够数量的正样本;随着训练过程的推移,这时应该适当增加IoU阈值以获得高质量的样本来训练模型。
Bounding Box Regression:
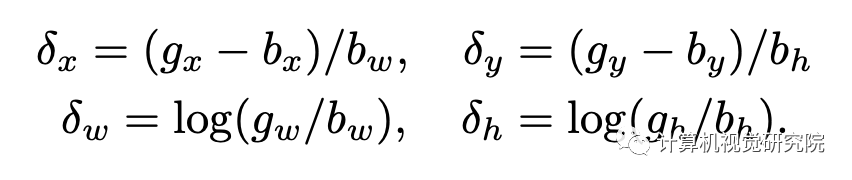
Dynamic R-CNN
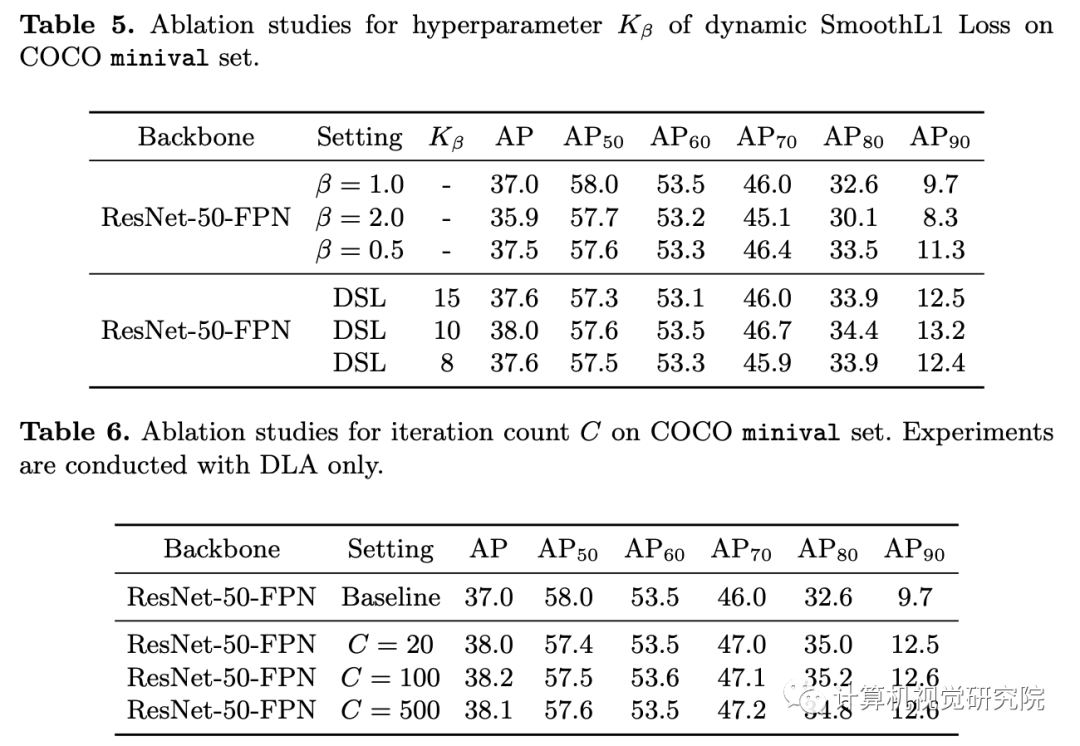
下图展示了Cascade R-CNN的整体流程,其核心思想是基于样本的分布动态地调整分类器和回归器。首先,输入图像经由RPN产生候选区域,由于随着训练过程的迭代而产生越来越多的高质量样本,这时增大IoU阈值。如下图(a)中右边的绿色框表示正样本,随着阈值的增加正样本的数量而不断增加。文中将这个过程称之为动态样本分配,DLA。下图(b)中展示了不同β的SmoothL1损失函数的变化情况,设置不同β的即为文中提到的DSL方法。
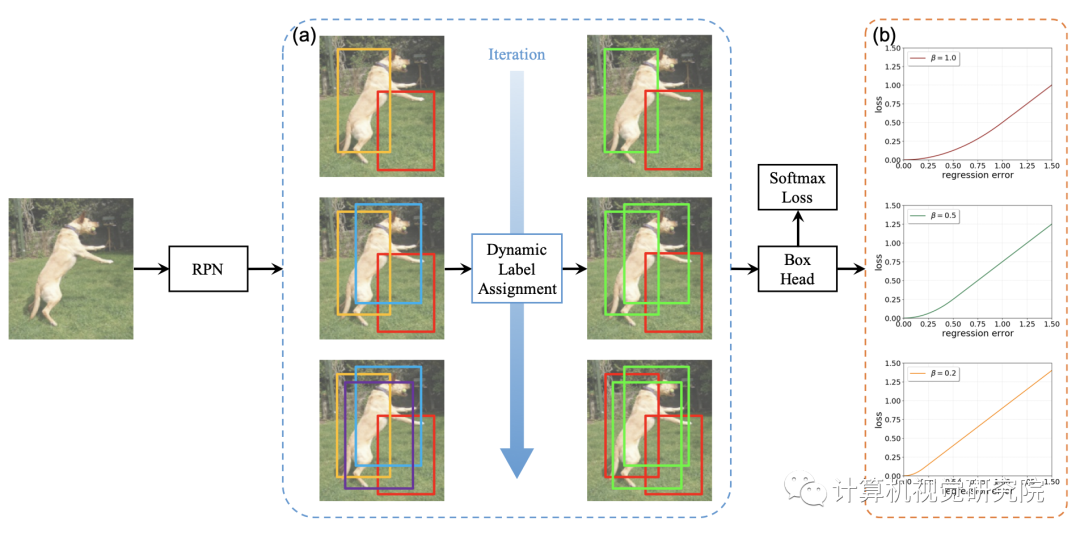
Dynamic Label Assignment:
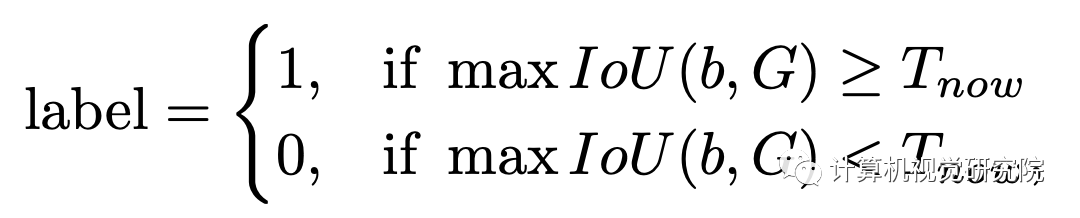
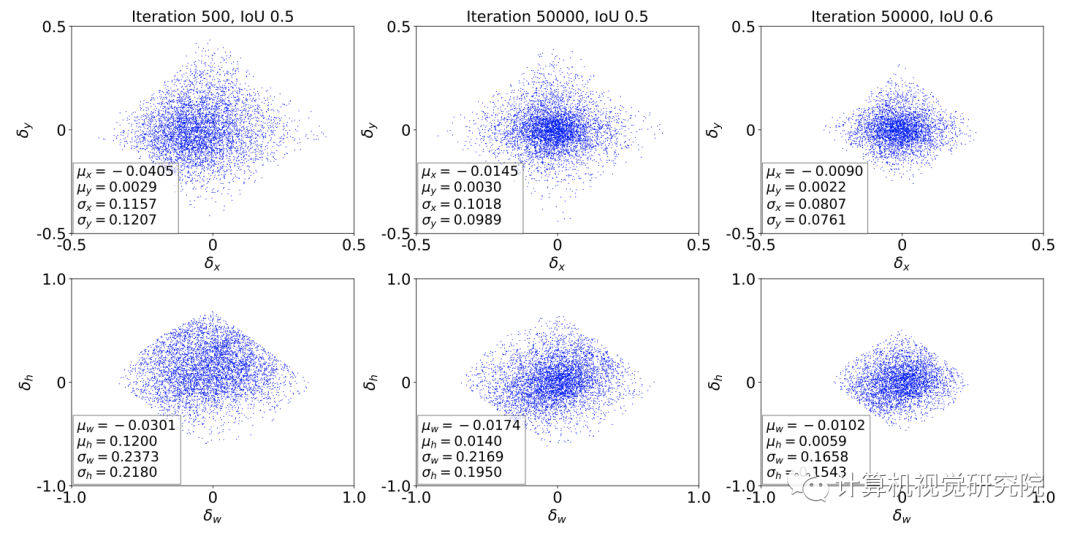
上面的公式就是DLA的形式,由经典Faster R-CNN中的形式得到,其中Tnow表示当前的IoU阈值。IoU的动态变化过程如下:首先计算候选框与其匹配的标注框的交并比I,然后选择第KI大的值作为当前的IoU阈值Tnow。随着训练的过程,Tnow会随着I的增大而增大。在具体实践中,首先计算批次样本中的第KI大的IoU值,然后每C个迭代使用前者的平均值更新Tnow(由于一次迭代会产生很多批次)。DLA的思路同Cascade R-CNN一致,只是选取阈值的方法有所不同。
Dynamic SmoothL1 Loss:
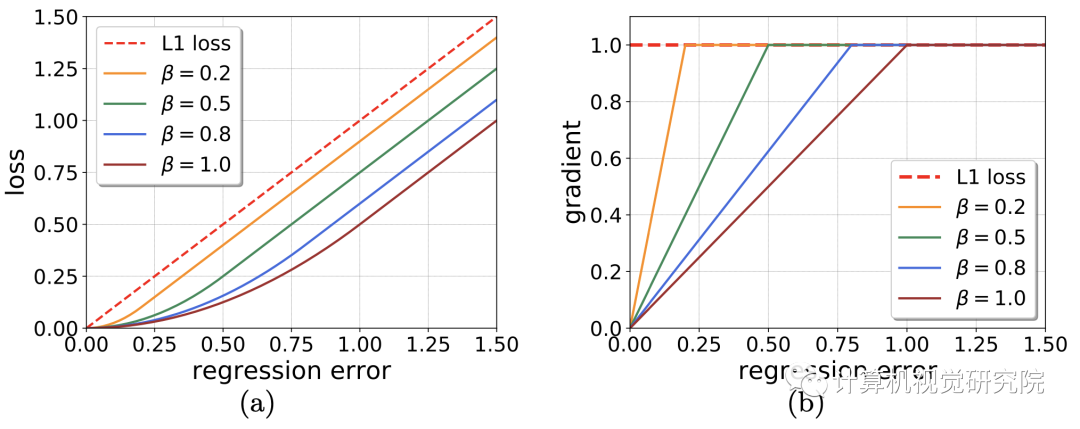
上图展示了SmoothL1损失函数的不同参数设置得到的损失和梯度变化情况。随着β值的减小,梯度更快趋于饱和,从而使较小的误差对模型的训练有更大的贡献。(这里没有理解具体为什么会采取如下措施,结合后面损失函数的形式,可以理解为随着迭代训练的进行,增大回归部分的损失而适当加快模型训练)则回归损失函数的形式如下:
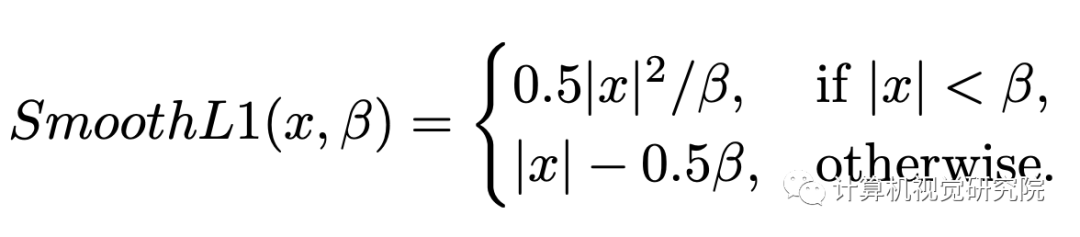
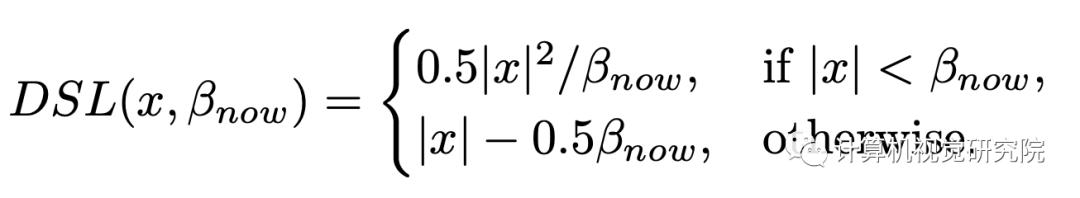
具体的做法是,首先候选框与其匹配的标注框的回归损失E,然后选择第Kβ小的值作为当前β值。在具体实践中,首先计算每批次样本中的第Kβ小的损失值,然后每C个迭代使用前者的中间值更新β。最后,给出Dynamic R-CNN的总体检测流程,其中第八行和第九行分别是DLA和DSA的关键步骤。

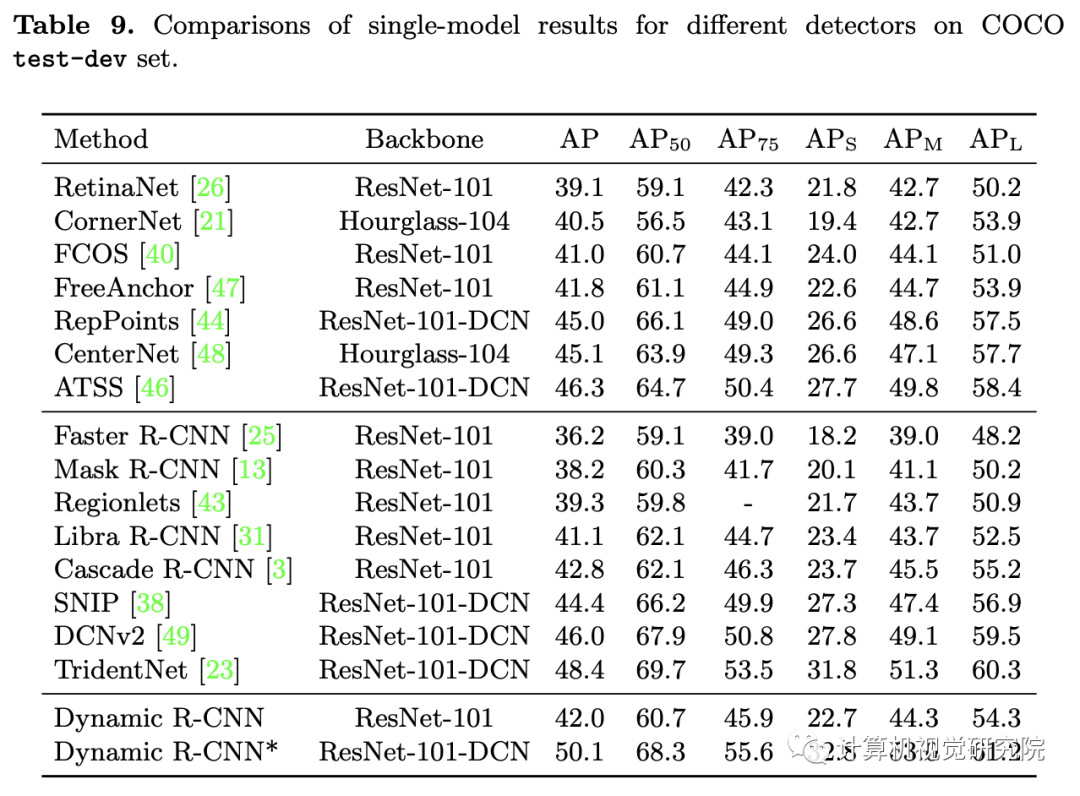
实验
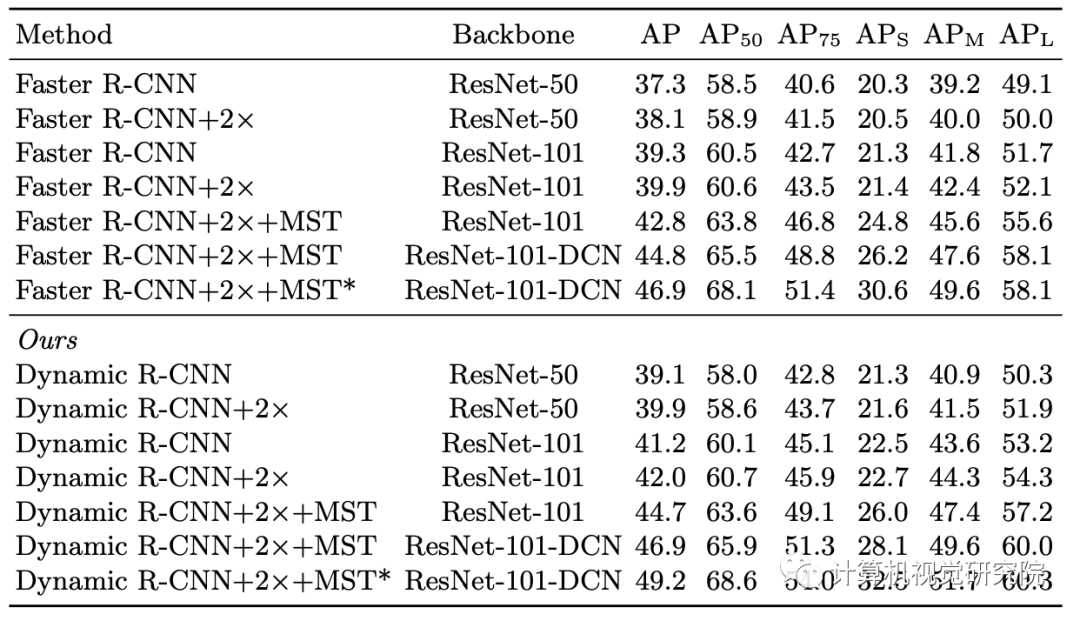
DLA和DSL的消融实验
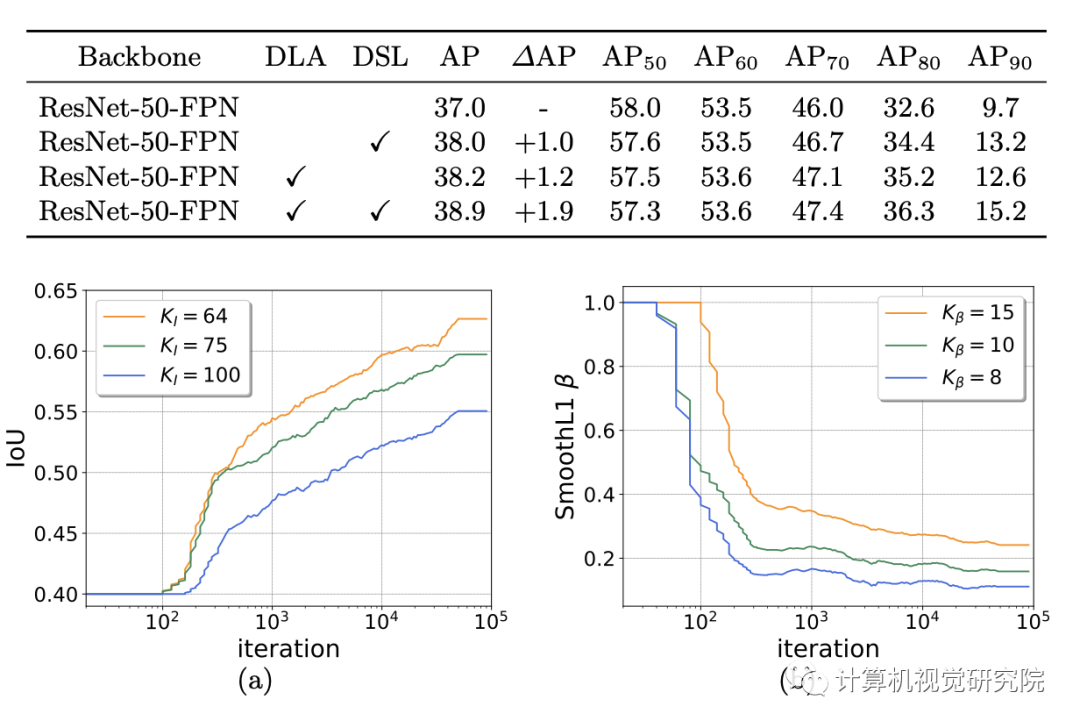
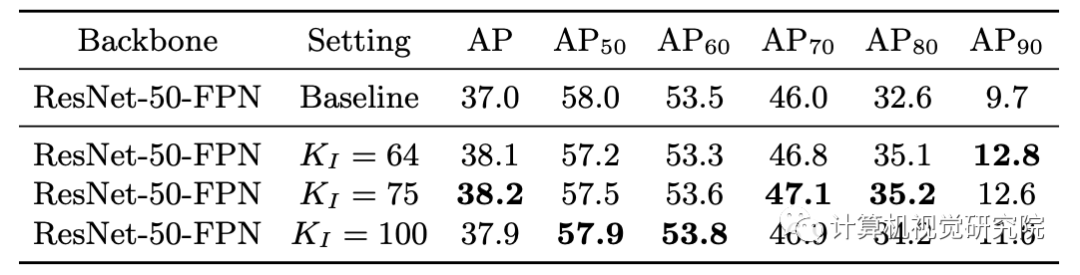
超参数KI的选择
论文以实验结果引入,得出在训练目标检测模型的过程中应随着样本的分布变化而动态设置分类器和回归器的结论。借鉴Cascade R-CNN中动态训练的设置,论文提出DLA在训练过程中动态改变交并比阈值以提高获取样本的质量。接着,借鉴DLA的思路,通过修改SmoothL1的参数动态调整回归器的形式,得到DSL。论文提出的方法在程序实现上并不困难,在定义分类器和回归器时分别引入一个变量即可。但是本文并没有理解文中的几个配图,是结合后续内容理解的。纵观全文,其创新性其实并不强,在ATSS中分析有框检测算法和无框就算法的异同后提出一种自适应的样本采样方法。本文可以借鉴的思路是,在训练目标检测器时应随着数据的变化而动态地改变训练的策略,文中给出了分类器和回归器两个方面。
✄-----------------------------------

扫码关注我们
公众号 : 计算机视觉研究院
关注回复“DRCNN”获取源码
