深度学习表示不可思议的威力:从头搭建图像语义搜索引擎
编者按:和Insight Data Science AI负责人Emmanuel Ameisen一起,基于深度学习技术,从头开始搭建图像语义搜索引擎。

教会电脑看照片
为何使用相似性搜索?
一图胜千言,更胜万行代码。
许多产品的基础在于展示图片。当我们浏览服饰网站上的套装时,当我们在Airbnb上寻找度假租屋时,当我们选择领养的宠物时,它看起来怎么样常常是我们决策的一个重要因素。我们感知事物的方式是预测我们将喜欢什么样的事物的强力预测者,因此它是值得测量的有价值的性质。
然而,让计算机以人类的方式理解图像在很长时间以来都是一项计算机科学挑战。2012年以来,在图像分类或目标检测之类的感知任务中,深度学习慢慢开始取代方向梯度直方图这样的经典方法。这一转变的重要原因之一是,在足够大的数据集上训练之后,深度学习能够自动提取有意义的表示。
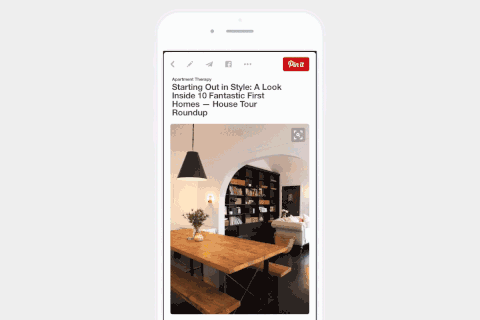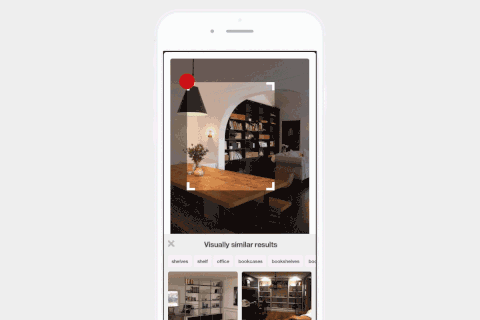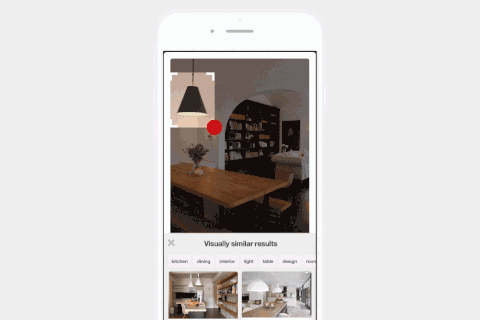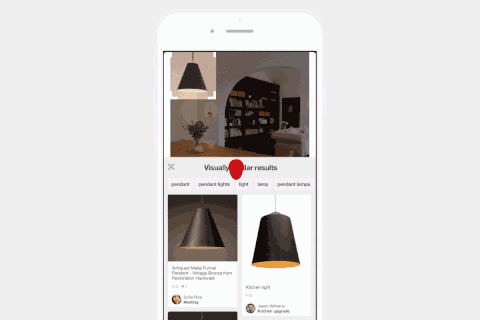
Pinterest的视觉搜索
这正是许多团队——比如Pinterest、StitchFix、Flickr——开始使用深度学习来学习他们的图像表示的原因,并基于用户觉得赏心悦目的内容提供推荐。类似地,Insight也使用深度学习创建用于帮助人们认养猫咪、推荐太阳镜、搜索艺术风格等应用的模型。
许多推荐系统基于协同过滤:利用用户的相关性做出推荐(“喜欢你喜欢的某物的用户也喜欢……”)。然而,这些模型需要大量数据才能足够精确,同时难以处理没有用户见过的新物品。而所谓基于内容的推荐系统,则可以使用物品表示,并不存在上面提到的问题。
此外,这些表示可以让消费者高效地搜索照片库,查找和刚看过的自拍照相似的图像(以图查询),或者查找包含特定物体(比如汽车)的照片(以文本查询)。常见的例子包括Google反向图像搜索(Google Reverse Image Search),以及Google图像搜索。
基于我们为许多语义理解项目提供技术咨询的经验,我们想要撰写一篇教程,关于如何为图像和文本数据创建你自己的表示,以及高效进行相似性搜索。读完本文之后,不管你的数据集有多大,你都应该能够从头搭建一个快速的语义搜索模型。
这篇教程有配套的使用streamlit制作的注释代码notebook,以及相应的GitHub代码仓库hundredblocks/semantic-search,供阅读时参考。
我们的计划是什么?
先谈谈优化
和软件工程一样,机器学习中,有很多处理问题的方法,各有各的折衷。如果你正在做一项研究或者一个本地原型,你可以使用非常低效的解决方案。但是如果我们创建的是可维护、可伸缩的相似图像搜索引擎,那么我们需要考虑我们如何适应数据演变,以及我们的模型可以运行得多快。
让我们想象一些方法:
我们创建了一个在我们所有图像上训练的端到端模型,接受一张图像作为输入,然后输出所有图像的相似度评分。预测很快(一次前向传播),但每次新增一张图像,我们就需要训练一个新模型。我们也会很快达到这样一个状态,分类是如此之多,以致于正确地优化它极为困难。这个方法很快速,但无法扩展至大数据集。此外,我们需要手工标注数据集的图像相似性,极耗时间。
另一个方法是创建一个接受两种图像作为输入的模型,并输出这对图像0到1之间的相似度评分(比如,使用孪生网络)。这些模型在大数据集上能够产生精确的结果,但导致了另一种伸缩性问题。我们通常想要查看大量图像找到相似图像,所以我们需要为数据集中的每对图像运行相似性模型。如果我们的模型是CNN,并且我们的图像数量超过两位数,那模型就太慢了,慢到我们不会考虑。此外,这个方法只能支持相似图像搜索,无法支持基于文本搜索图像。
有更简单的方法,一个类似词嵌入的方法。如果我们找到图像的一种富有表达力的向量表示,或者说嵌入,我们可以通过检查它们的向量的接近程度计算图像的相似度。这类搜索方法是一个充分研究过的常见问题,许多库实现了高速的解决方案(我们这里将使用Annoy)。此外,如果我们事先计算数据集中所有图像的向量,这个方法既快速(一次前向传播,和一次高效的相似度搜索),又可伸缩。最后,如果我们成功找到图像和文本的共同嵌入,我们可以使用它们基于文本搜索图像!
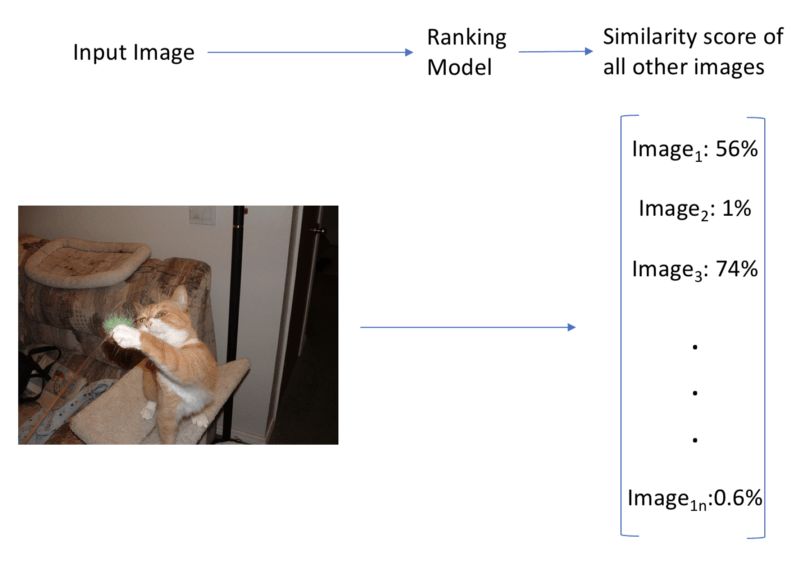
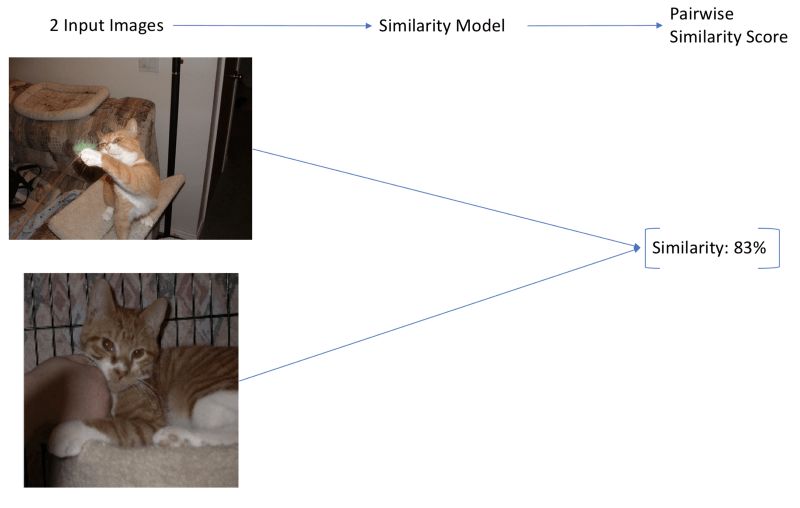
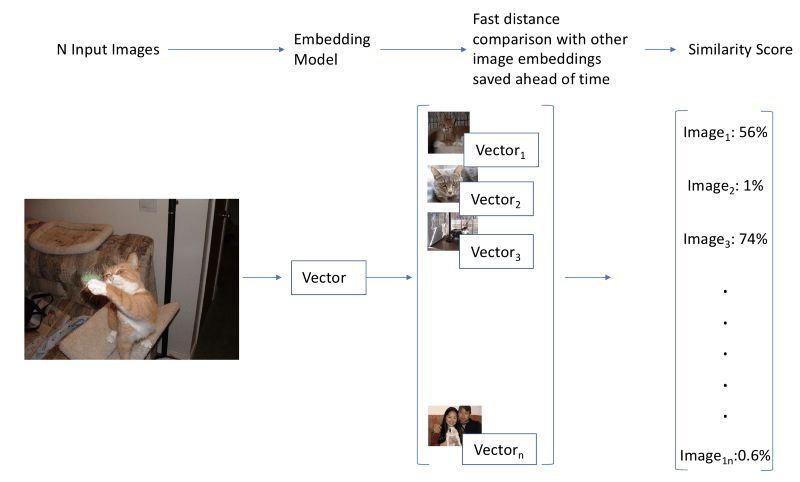
由于方法3的简单性和高效性,本文将使用方法3.
我们如何操作?
那么,我们到底如何使用深度学习表示来创建一个搜索引擎?
我们的最终目标是得到一个可以接受图像作为输入,输出相似图像或标签,或者接受文本作为输入,输出相似文本或图像的搜索引擎。为此,我们需要经过如下步骤:
根据输入图像搜索类似图像(图像 -> 图像)
根据文本搜索类似文本(文本 -> 文本)
生成图像标签,基于文本搜索图像 (图像 <-> 文本)
为了做到这些,我们将使用嵌入,图像和文本的向量表示。一旦我们有了嵌入,搜索就变成寻找输入向量的相近向量简单过程。
我们通过计算图像嵌入的余弦相似度找到相近向量。相似图像会有相似的嵌入,也就是说,嵌入之间会有高余弦相似度。
让我们从数据集开始。
数据集
图像
我们的图像数据集总共有1000张图像,分为20类,每类50张。这个数据集是由Cyrus Rashtchian、Peter Young、Micah Hodosh、Julia Hockenmaier制作的。之前提到过的本文的代码仓库中,有自动下载所有图像文件的脚本。
除了类别之外,数据集中还包括每张图像的说明。为了增加难度,也为了表明我们的方法的通用性,我们将只使用类别,丢弃所有说明。如前所述,数据集总共包括20个分类:
aeroplanebicyclebirdboatbottlebuscarcatchaircowdining_tabledoghorsemotorbikepersonpotted_plantsheepsofatraintv_monitor

上面是数据集中的一些样本。我们看到,标签的噪声不小:许多照片包含多个类别,而标签并不总是主要的类别。例如,右下角的图像的标签是chair(椅子)而不是person(人),尽管图像中间有3个人,而椅子毫不引人注意。
文本
我们将加载在维基百科数据上预训练的词嵌入(本文将使用Glove模型)。我们将使用这些向量在我们的语义搜索中纳入文本。如果你不熟悉词向量,可以参考我的NLP教程的第七步。
图像 -> 图像
从简单的开始
我们将使用在大型数据集(Imagenet)上预训练的模型。这里我们使用的是VGG16,不过你也可以使用任何其他最近的CNN架构。我们使用VGG16生成图像的嵌入。
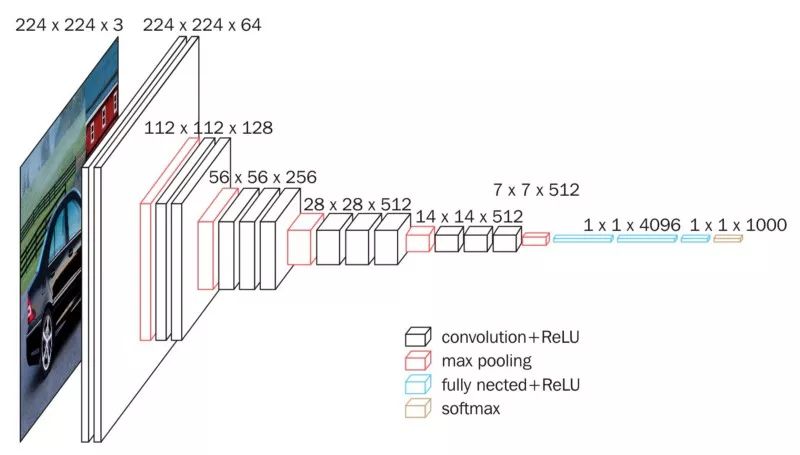
VGG16(图片来源:Data Wow博客)
我们说的生成嵌入是什么意思?我们将使用预训练模型,直到倒数第二层,然后储存激活的值。下图中,嵌入层加上了绿色高亮,这一层在最后的分类层之前。
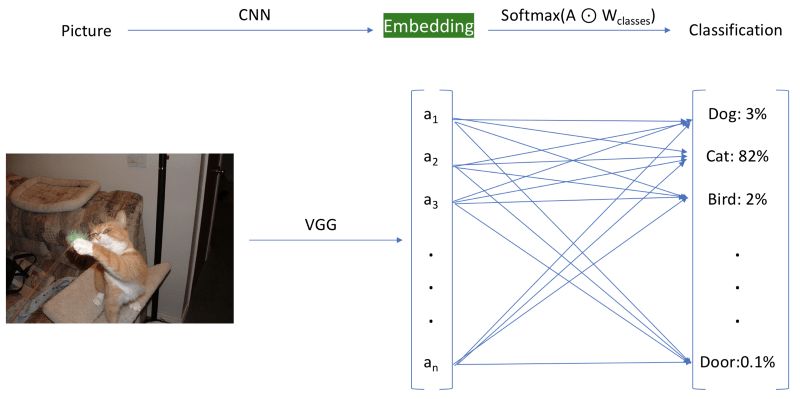
一旦我们使用模型生成图像特征后,我们就可以把它们储存在磁盘上,然后可以重复利用,无需再次推理!这正是嵌入在实际应用中如此流行的原因之一,因为它们带来了巨大的效率提升。将其储存在磁盘上之后,我们将使用Annoy为嵌入创建一个高速索引,这让我们可以为任意给定嵌入快速寻找最近的嵌入。
在我们的嵌入中,每张图像表示为一个4096维的稀疏向量。之所以向量是稀疏的,是因为我们取的是激活函数之后的值,而激活函数将负值转为零。
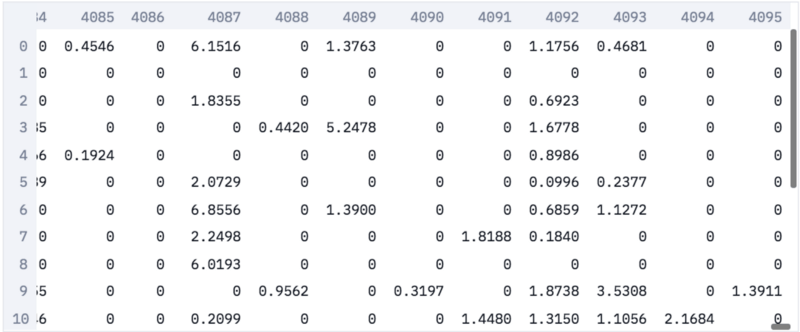
图像嵌入
基于嵌入通过图像搜索
现在我们可以直接接受一张图像作为输入,得到它的嵌入,然后查询我们的高速索引找到相似嵌入,也就是相似图像。
这一点特别有用,因为图像标签常常包含噪声,通过图像搜索通常优于通过标签搜索。
例如,在我们的数据集中,我们有cat类(猫),也有bottle类(瓶)。
你觉得下面这张图像的标签是什么?

图像缩放至224x224,这是神经网络看到的分辨率
很不幸,这张图像被打上了瓶标签。这是真实数据集中常常碰到的问题。给图像打上唯一的标签限制性很大,因此我们希望使用更细致的表示。好在这正是深度学习擅长的!
让我们看看基于嵌入的图像搜索表现如何?
搜索dataset/bottle/2008_000112.jpg的相似图像……

太棒了——基本上搜到的都是关于猫的图像,这看起来很合理!我们的预训练网络在多种多样的图像上训练过,包括猫图,所以能够精确地找到相似图像,即使它从未在这一特定数据集上训练过。
然而,下排中间的图像显示的是架子上的瓶子。总的来说,这一方法在寻找相似图像上表现不错,不过有时我们只对图像的局部感兴趣。
例如,在上面的搜索中,我们可能只想搜索相似的猫咪,而不是相似的瓶子。
半监督搜索
解决这一问题的一个常用方法是首先使用目标检测模型检测出猫,然后对原图进行裁切,通过裁切出的猫图进行搜索。
不过这会大大增加计算负担,所以有可能的话,我们想避免使用这种方法。
有一个更简单的“取巧”方法,重新加权激活。我们加载原本抛弃掉的最后一层的权重,然后使用和我们搜寻的分类相连的权重,重新加权嵌入。这个很酷的技巧最初是由我在Insight的同事Daweon Ryu告诉我的。例如,我们将使用Siamese cat(暹逻猫)分类的权重重新加权数据集的激活(下图中加上了绿色高亮)。你可以查看前面提到的配套notebook,了解实现细节。
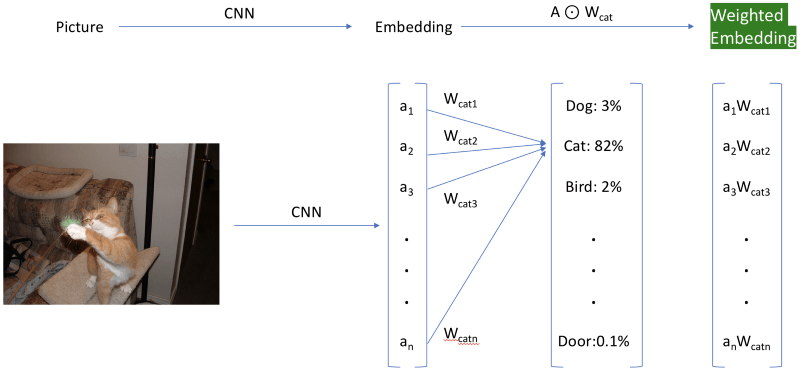
显示的分类层仅供参考,并不在嵌入中使用
让我们看看使用Imagenet的分类284(即Siamese cat)加权激活后效果如何?
基于加权特征搜索dataset/bottle/2008_000112.jpg的相似图像……

我们可以看到,搜索加上了偏置,寻找类似暹逻猫的东西。结果中不再有瓶子图像了,这很好。不过你可能注意到我们的最后一张图像是一只羊!有意思,给我们的模型加上偏置导致了不同种类的错误。就我们目前的应用范围来说,这种错误比之前的错误更加合理。
我们已经见到了相似图像搜索更宽泛的方式,通过以模型的特定分类为条件进行搜索。
这是一项很棒的进展,但由于我们使用的是在Imagenet上预训练的模型,我们因此受到1000个Imagenet分类的限制。这些分类远远说不上包罗万象(例如,它们缺乏关于人的类型),所以,我们想要找到更灵活的理想方案。此外,如果我们只是想在不提供输入图像的前提下搜索猫图呢?
为了达成这一点,我们将使用简单技巧之外的方法,利用可以理解单词语义的模型。
文本 -> 文本
说到底,没什么不同
用于文本的嵌入
绕行至自然语言处理(NLP)的世界,我们可以类似的方法索引和搜索单词。
我们将载入Glove预训练的向量,这些向量是通过爬取所有维基百科文章,然后学习数据集中单词之间的语言联系得到的。
和之前一样,我们创建一份索引,这次索引包括的是所有的Glove向量。接着,我们可以搜索我们的嵌入以查找相近单词。
例如,搜索said将返回如下的[单词, 距离]列表:
['said', 0.0]
['told', 0.688713550567627]
['spokesman', 0.7859575152397156]
['asked', 0.872875452041626]
['noting', 0.9151610732078552]
['warned', 0.915908694267273]
['referring', 0.9276227951049805]
['reporters', 0.9325974583625793]
['stressed', 0.9445104002952576]
['tuesday', 0.9446316957473755]
这看起来非常合理,绝大多数单词的含义都很相似,或者表示相宜的概念。最后一项结果(tuesday,周二)则表明,这模型远不完美。不过这个模型将给我们一个好的开始。现在,让我们尝试将单词和图像同时纳入我们的模型。
维度问题
使用嵌入的距离作为搜索方法相当通用,但我们的单词表示和图像表示看起来不兼容。图像嵌入的维度是4096,而单词嵌入的维度是300——我们怎么能用一种嵌入搜索另一种呢?此外,即使两种嵌入维度相等,它们也是通过完全不同的方法训练的,因此图像和相关单词碰巧具有相同嵌入的概率极低。我们需要训练联合模型。
图像 <-> 文本
世界的碰撞
现在,让我们创建一个混合模型,可以从单词到图像,也可以从图像到单词。
在这篇教程中,这是我们第一次实际训练自己的模型,该模型的灵感来自一篇杰出的论文DeViSE。我们不会精确地重新实现论文中的算法,不过我们的模型基本遵循论文的主要思路。(你也可以参考fast.ai第11课,其中包含了论文算法的一个略微不同的实现)。
主要思路是通过重新训练图像模型,改变标签的类别来组合两种表示。
我们通常训练图像分类器从许多类别(Imagenet有1000个类别)中选中一个。也就是说——以Imagenet为例——最后一层是一个表示每个分类概率的1000维向量。这意味着我们的模型没有分类相似性的语义理解,将“猫”图分类为“狗”,在模型看来,和将其分类为“飞机”错得一样离谱。
在我们的混合模型中,我们将模型的最后一层替换为类别的词向量。这让我们的模型得以学习图像语义和单词语义间的映射,同时,相似分类将彼此接近(因为,相比“飞机”,“猫”的词向量和“狗”的词向量更接近)。我们不预测1000维的稀疏向量(除了一个分量为1外,所有分量均为0),我们将预测300维的语义丰富的词向量。
我们通过添加两个密集层达成这一点:
大小为2000的中间层
大小为300的输出层(大小等于Glove的词向量)
下面是在Imagenet上训练的模型的架构:
这是改动之后的架构:
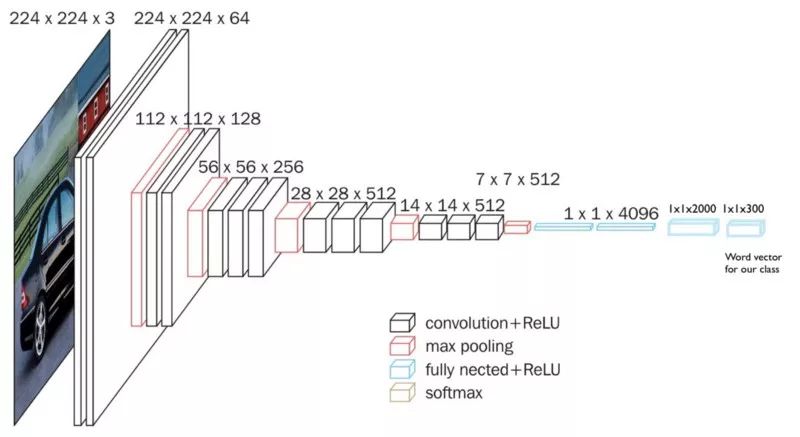
训练模型
我们接着从数据集中分出训练集,再训练我们的模型,以学习预测与图像相关的词向量。例如,对类别为猫的图像而言,我们尝试预测300维的“猫”词向量。
再训练需要一些时间,但仍然比在Imagenet上训练要快得多。作为参考,在我不带GPU的笔记本上,再训练耗时6到7小时。
值得注意的是这一方法的雄心壮志。相比通常的数据集(Imagenet有一百万张图像),我们这里使用的训练集(数据集的80%,也就是800张图像)根本不算什么(3个数量级的差异)。如果我们使用传统的基于类别训练的技术,我们不会指望我们的模型在测试集上表现良好,更别说在全新的样本上了。
一旦模型训练完成,我们将创建相应的Glove词向量索引和图像的高速索引(运行模型于数据集上的所有图像),并储存到磁盘上。
标记
现在,提取任意图像的标签非常简单。我们只需将图像传入训练好的网络,保存网络输出的300维向量,并在Glove英文单词索引中找到最接近的单词。让我们用一张图像来试一下——这张图像在数据集中被打上了bottle(瓶)标签,不过它包含多种物品。

下面是生成的标签:(注释为译者所加)
[6676, 'bottle', 0.3879561722278595] # 瓶
[7494, 'bottles', 0.7513495683670044] # 瓶(复数)
[12780, 'cans', 0.9817070364952087] # 罐头
[16883, 'vodka', 0.9828150272369385] # 伏特加
[16720, 'jar', 1.0084964036941528] # 广口瓶
[12714, 'soda', 1.0182772874832153] # 苏打水
[23279, 'jars', 1.0454961061477661] # 广口瓶(复数)
[3754, 'plastic', 1.0530102252960205] # 塑料
[19045, 'whiskey', 1.061428427696228] # 威士忌
[4769, 'bag', 1.0815287828445435] # 袋
这个结果相当惊人,大多数标签高度相关。这一方法仍然有提升的空间,但它对图像中的大多数物品的理解相当好。模型学习提取许多相关的标签,甚至包括没有训练过的类别!
通过文本搜索图像
最重要的是,我们可以基于联合嵌入,通过任何单词搜索我们的图像数据库。我们只需从Glove获取预训练的词嵌入,然后找到具有相似嵌入的图像。
让我们首先从训练数据集中的一个单词dog(狗)开始:

好,相当好的结果——但是任何基于标签训练的分类器也能给出这样的结果!让我们增加难度,搜索关键词ocean(海洋),这是我们的数据集中没有包含的类别。

太棒了——我们的模型理解ocean(海洋)和water(水)相似,并且返回了很多boat(船)分类的图像。
试试street(街道)?

这里,返回的图像来自多个分类(汽车、狗、自行车、巴士、人),不过大部分都包含街道或者靠近街道,尽管我们在训练模型的时候从未使用过这一概念。由于我们通过预训练的词向量,利用外部知识学习图像到向量的一种映射,该映射比简单的类别具有更丰富的语义,所以我们的模型能够很好地概括外部概念。
单词之外
英语词汇增加得很快,但还没有快到为所有东西发明一个单词。例如,在发布这篇文章的时候,还没有一个英语单词表示“躺在沙发上的猫”,这是一个再合理不过的可以在搜索引擎中输入的查询。如果我们希望同时搜索多个单词,我们可以使用一个非常简单的方法,利用词向量的算术性质。实际上,把两个词向量加起来一般来说效果非常好。所以如果我们直接使用“猫”、“沙发”的平均词向量进行搜索,我们可以希望得到和猫相似,同时和沙发相似的图像,或者说,猫在沙发上的图像。
让我们试着使用这一混合嵌入搜索!

结果非常棒,大多数图像都包含某种毛茸茸的动物和沙发(我特别喜欢第二排最左的图像,看起来像放在沙发边上的一袋皮毛)!我们基于单个单词训练的模型,可以处理两个单词的组合。我们现在并没有造出Google图像搜索,但就这一相对简单的架构而言,这毫无疑问是令人印象深刻的结果。
实际上,这一方法可以很自然地扩展到多个领域(比如这个联合嵌入代码和英语文本的例子),所以我们希望能了解你最后将这一方法应用到了哪里。
结语
我希望你觉得这篇文章有干货,并且驱散了基于内容的推荐和语义搜索的一些迷雾。如果你有任何问题或评论,或者想要分享你用这篇教程的方法创造的东西,可以在Twitter上联系我(EmmanuelAmeisen)!
原文地址:https://blog.insightdatascience.com/the-unreasonable-effectiveness-of-deep-learning-representations-4ce83fc663cf






