手把手教你从零起步构建自己的图像搜索模型

本文为 AI研习社 编译的技术博客,原标题 The unreasonable effectiveness of Deep Learning Representations,作者为 Emmanuel Ameisen 。
翻译 | 付腾 王飞 汪鹏 校对 | 余杭 整理 | MY

训练电脑以人类的方式去看图片
为什么从相似性搜索做起?
一张图片胜千言,甚至千行代码。
很多的产品是基于我们的感知来吸引我们的。比如在浏览服装网站上的服装,寻找 Airbnb 上的假期租房,或者领养宠物时,物品的颜值往往是我们做决定的重要因素。想要预测我们喜欢什么样的东西,看看我们对于事物的感知方法大概就能知道了,因此,这也是一个非常有价值的考量。
但是,如何让计算机以人类的视角来理解图片长久以来是计算机科学领域的一大挑战。直到 2012 年,深度学习在某些感知类任务(比如图像分类或者目标探测)中开始慢慢地超过了传统的机器学习方法(比如 方向梯度直方图,HOG)。关于学界的这次转变,一个主要的原因就要归功于深度学习对于在足够大训练数据集上面自动提取出有意义的表征的能力。
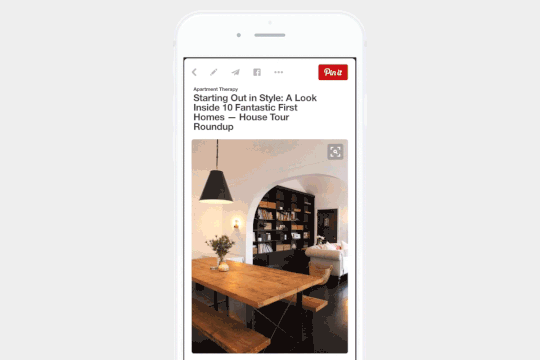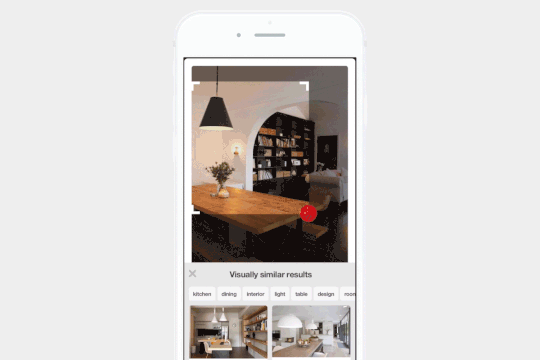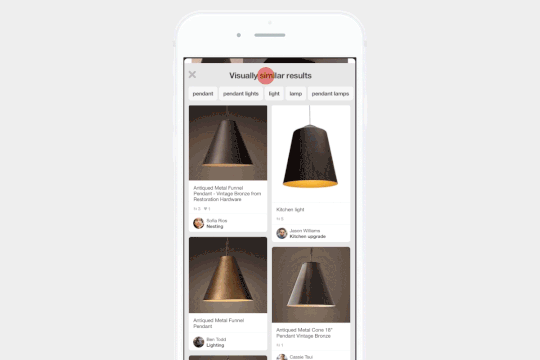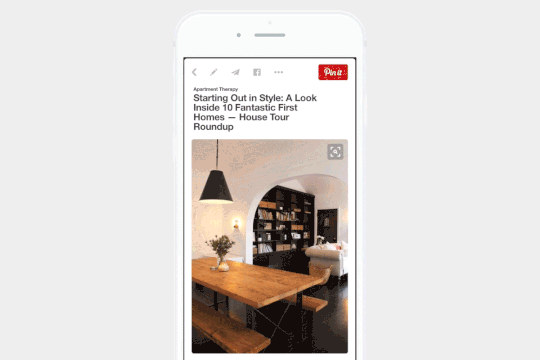
Pinterest 中的视觉搜索
这也是为什么很多开发团队,比如 Pinterest,StitchFix 以及 Flickr 等,开始使用深度学习来学习他们获得的图片当中的表征,基于这些提取的表征以及用户对于视觉内容是否欢迎的反馈来为用户提供内容推荐。类似的,insight 的研究员也使用深度学习来建立一系列的模型,比如帮助用户找到适合领养的猫咪,推荐适合购买的太阳镜,或者搜索具体的艺术风格。
许多推荐系统是基于协同过滤的:利用用户关联来提出建议(“喜欢这个物品的用户可能还喜欢···”)。但是,这类模型需要非常大量的数据才能比较准确,而且这类模型在应对新的还未被用户浏览过的新物品的时候会表现不佳。物品表征是另一个解决办法,那就是基于内容的推荐系统,这种推荐系统并不会受到上面提到的未被浏览的新物品问题的影响。
此外,这些表征允许消费者有效地搜索图像库,(通过图像查询)来获取与他们刚拍摄的自拍相似的图像,或者搜索某些特定物品的照片,比如汽车(通过文本查询)。这方面的常见示例包括 Google 反向图片搜索服务以及 Google 图片搜索服务。
根据我们为许多语义理解项目提供技术指导的经验,我们编写了一个教程,让读者了解如何构建自己的表征模型,包括图像和文本数据,以及如何有效地进行基于相似性的搜索。到本文结束时,读者自己应该能够从零起步构建自己的快速语义搜索模型,无论数据集的大小如何。
本文配有一个带有代码注释的 notebook,使用了 streamlit 和一个独立的代码库来演示和使用所有相关技术。代码可以自由使用,请读者自便。
我们的计划是什么?
来聊聊优化吧
在机器学习中,有时也和软件工程一样,方法总比问题多,每种方法都有不同的权衡。如果我们正在进行研究或本地的产品原型设计,我们可以暂时摆脱效率非常低的解决方案。但是如果我们的目标是要构建一个可维护和可扩展的相似图像搜索引擎,我们必须考虑到两点:1. 如何适应数据演变 2. 模型的运行速度。
让我们先想象几种解决方案:
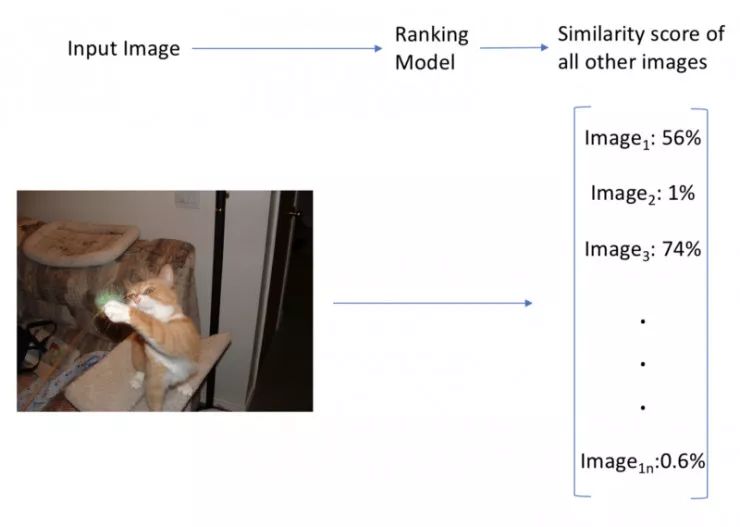
方案 1 的工作流程
方案 1:我们建立一个端对端的模型,这个模型使用了我们所有的模型进行训练。这个模型的输入是一个图片,输出一个数组,这个数组里的每个元素是输入图片和图片训练集中的每一个图片的相似性数值。模型的预测过程运行速度快(因为是单独的前向计算),但是我们每次添加了新的图片到图片训练集中就需要重新训练一个新的模型。我们同样会在模型迭代的过程中碰到一个大问题就是模型的输出包含太多的类,导致模型的正确优化极端困难。这的确是一个很快的方案,但是在可扩展性上有限制,不能扩展到比较大的数据集上。此外,我们还需要手动给我们的训练集进行图片相似性的标定,这将是极其耗时的一项工作。
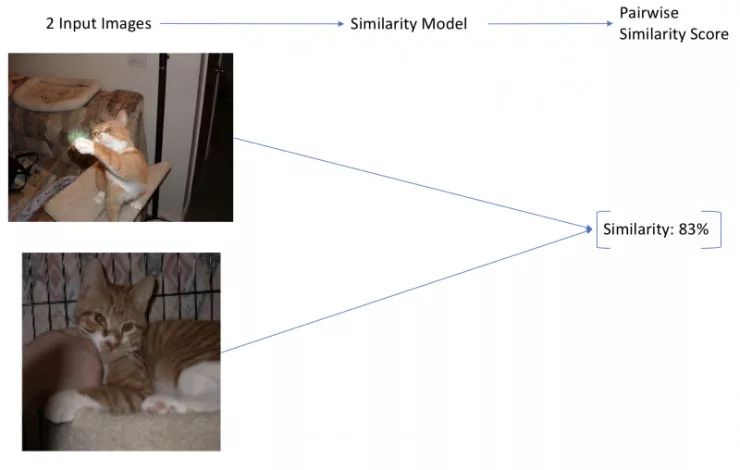
方案 2 的工作流程
方案 2:另外一种方案是建一个相似性预测模型,这个模型的输入是两张图片,输出是一个落在区间 0 到 1 范围内的相似性配对值。这些模型在大型数据集上也能比较准确,但是却受限于另一个可扩展问题。我们经常需要从一大堆的图片集中找到相似的图片,因此我们需要对我们的数据集中的所有可能图片配对集运行一次相似性模型。假设我们的模型是卷积神经网络(CNN),而且我们有不小的图片量,那么整个系统的处理速度就太慢了,简直无法忍受。此外,这种方案只能用于基于图片相似性搜索,不能扩展到基于文本的相似性搜索。这种方案可以扩展到大数据集,但是总体的运行时间太慢了。
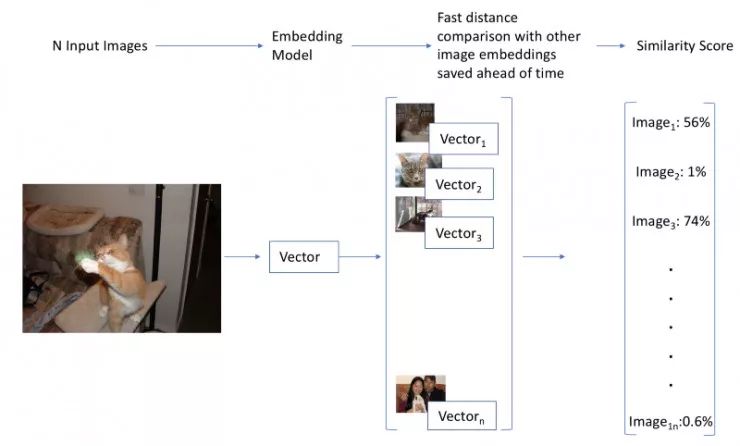
方案 3 的工作流程图
方案 3:有一种更简单的方法,类似于字嵌入。如果我们为图像找到一个很有代表性的表示或者嵌入,我们就可以通过观察它们的矢量彼此之间的距离来计算它们的相似性。这种类型,许多库都实现了快速解决方案(我们将在这里使用 Annoy)。此外,如果我们能提前计算出我们数据库中所有图像的这些向量,那么这种方法便可表现出既快速(一次正向传递,一种有效的相似性搜索),又可扩展的特点。最后,如果我们设法为我们的图像和单词找到常见的嵌入,我们可以使用它们来进行文本到图像的搜索!
由于其简单性和高效性,第三种方法将成为本文的重点。
我们该怎样实现这个过程?
那么,我们该如何在实际中使用深度学习表示来创建搜索引擎?
我们的最终目标是拥有一个搜索引擎,它可以接收图像并输出相似的图像或标签,可以接收文本并输出类似的单词或图像。为实现这一目标,我们将经历以下三个连续的步骤:
为输入图片寻找相似的图片 (图片 → 图片)
为输入的文字寻找相似的文字 (文本 → 文本)
为图像生成标签,并使用文本搜索图像 (图像 ↔ 文本)
为此,我们将使用嵌入 (embeddings),图像和文本的矢量表示。一旦我们有嵌入 (embeddings),搜索只是找到靠近我们的输入向量的向量。
寻找这个向量的方法是计算我们的图像的嵌入和其他图像之间的嵌入之间的余弦相似度。类似的图像将具有类似的嵌入,意味着嵌入之间的高余弦相似性。
让我们从一个数据集开始试验。
数据集
图片
我们的图像数据集由总共 1000 张图像组成,分为 20 个类别,每个类别下 50 张图像。此数据集可在此处找到。您可以随意使用链接代码中的脚本自动下载所有图像文件。另外感谢 Cyrus Rashtchian,Peter Young,Micah Hodosh 和 Julia Hockenmaier 的数据集。
此数据集包含每个图像的类别和一组标题。为了使问题的难度增加,并且为了验证我们的方法的泛化性能,我们将只使用类别,而忽略标题。数据集中总共有 20 个类,如下所示:


图像示例,我们能看到,标签很繁杂
我们可以看到我们的标签非常繁杂:许多照片包含多个类别,标签并不总是来自最突出的标签。例如,在右下角,图像被标记为 chair 而不是 person,虽然 3 人站在图像的中心,椅子几乎看不见。
文本
此外,我们加载已在 Wikipedia 上预训练的单词嵌入(本教程将使用 GloVe 模型中的单词嵌入)。我们将使用这些向量将文本合并到我们的语义搜索中。有关这些单词向量如何工作的更多信息,请参阅我们的 NLP 教程的第 7 步。
图像 -> 图像
从简单的开始。
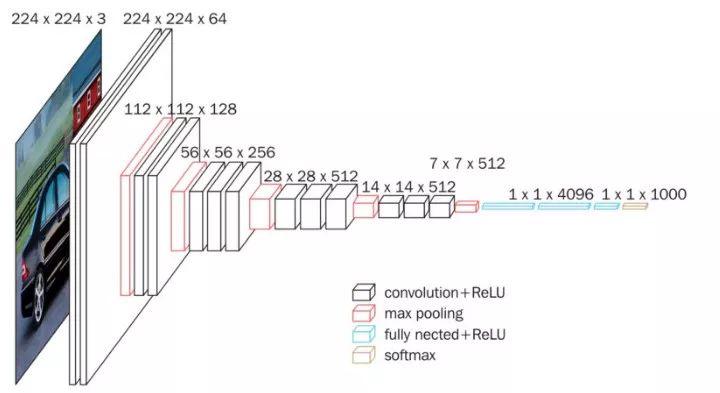
我们现在要加载一个在大型数据集(Imagenet)上预先训练过的模型,这个模型可以在线免费获取。我们在这里使用 VGG16,但这种方法适用于任何最近的 CNN 架构。我们使用此模型为我们的图像生成嵌入。
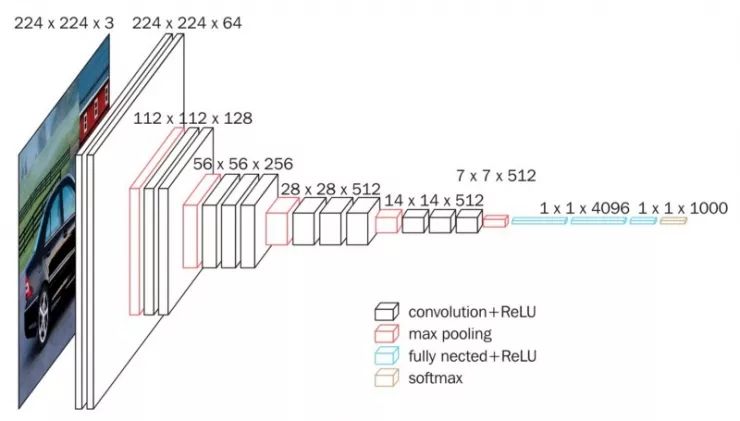
VGG16 (感谢 Data Wow 博客)
生成嵌入是什么意思?我们将使用我们预先训练的模型直到倒数第二层,并存储激活的值。在下图中,这过程由绿色突出显示的嵌入层表示,该嵌入层位于最终分类层之前。
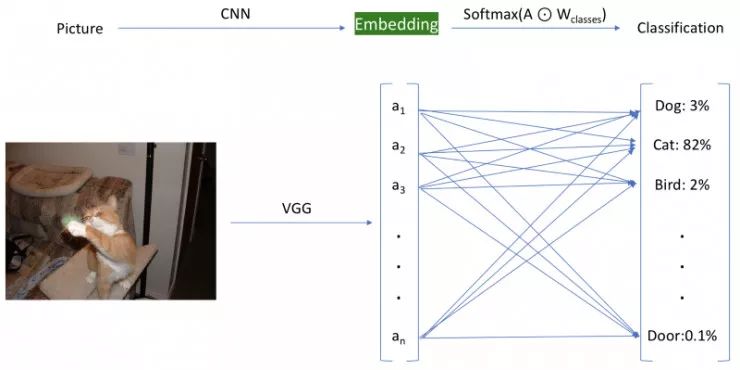
对于我们的嵌入,我们在最终分类层之前使用该层。
一旦我们使用该模型生成图像特征,我们就可以将它们存储到磁盘并重新使用它们而无需再次进行推理!这是嵌入在实际应用中如此受欢迎的原因之一,因为它们可以实现巨大的效率提升。除了将它们存储到磁盘之外,我们将使用 Annoy 构建嵌入的快速索引,这将允许我们非常快速地找到任何给定嵌入的最近嵌入。
以下是我们的嵌入。现在每个图像都由一个大小为 4096 的稀疏向量表示。注意:向量稀疏的原因是我们在激活函数之后取了值,这会将负数归零。
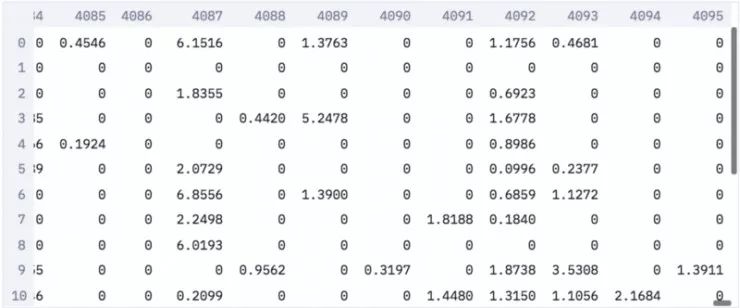
图像嵌入
使用我们的嵌入来搜索图像
我们现在可以简单地接收图像,获取其嵌入,并查看我们的快速索引以查找类似的嵌入,从而找到类似的图像。
这特别有用,因为图像标签通常很嘈杂,并且一般来说图像比标签的信息更多。
比如,在我们的数据集中,我们有 cat 和 bottle 这两个类你觉得这张图片该标记成哪一个类?

Cat 还是 Bottle? (图像被缩放到了神经网络下的 224*224 的大小)
正确答案是瓶子。这是实际数据集中经常遇到的问题。将图像标记为唯一类别的情况是很少的,这就是为什么我们希望使用更细微的表示。幸运的是,这正是深度学习所擅长的!
让我们看看使用嵌入的图像搜索是否比人类标签更好。
为 dataset/bottle/2008_000112.jpg…这张图片寻找相似的图片:

太棒了,我们大多得到更多猫的图像,这看起来很合理!我们的预训练网络已经过各种图像的训练,包括猫,因此它能够准确地找到相似的图像,即使它之前从未接受过这个特定数据集的训练。
但是,底行中间的一幅图像显示了瓶架。一般而言,这种方法能够很好地找到类似的图像,但有时我们仅对图像的一部分感兴趣。
例如,给一张猫和瓶子的图像,我们可能只对相似的猫感兴趣,而不是类似的瓶子。
半监督搜索
解决此问题的常用方法是首先使用对象检测模型,检测我们的猫,然后对原始图像的裁剪版本进行图像搜索。
这增加了巨大的计算开销,如果可能的话我们希望避免这种开销。
有一种更简单的「hacky」方法,包括重新赋予激活的权重。我们通过加载我们最初丢弃的最后一层权重来做到这一点,并且仅使用与我们正在寻找的类的索引相关联的权重来重新对嵌入进行加权。这个很棒的方法最初是从 Insight 研究员 Daweon Ryu 那里看到的。例如,在下图中,我们使用 Siamese cat 类的权重来重新赋予我们数据集上的激活(以绿色突出显示)的权重。请随意查看附录中的笔记,了解实现的细节。
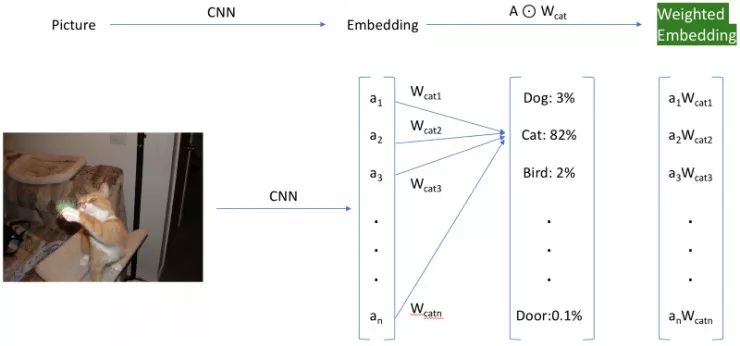
快速获得加权嵌入,分类层仅供参考。
让我们根据 Imagenet 中的第 284 类 Siamese cat 来给我们的激活赋予权值,以此来研究它是如何工作的。
使用加权后的特征来为 dataset/bottle/2008_000112.jpg 寻找相似的图片。

我们可以看到搜索一直偏向于寻找孪生类猫物体。我们不再显示任何瓶子,这个结果很棒。你可能会注意到我们的最后一张照片是一只羊!这非常有趣,原因更偏向于我们的模型导致了一种不同类型的错误,这更适合我们的当前域。
我们已经看到,我们可以通过广泛的方式搜索类似的图像,或者通过调整我们的模型所训练的特定类。
这是一个非常大的进步,但由于我们使用的是一个在 Imagenet 上预训练的模型,因此我们仅限于 1000 个 Imagenet 的类别。这些类远非包罗万象(例如他们缺少一个人的类别),所以我们希望找到更灵活的方式。另外,如果我们只是想在不提供输入图像的情况下搜索猫呢?
为了做到这一点,我们不仅仅使用了一些简单的技巧,还利用了一个能够理解单词语义能力的模型。
文本 -> 文本
毕竟没什么不同
嵌入文本
绕道自然语言处理(NLP)的领域,我们可以使用类似的方法来索引和搜索单词。
我们基于 GloVe 模型加载了一组预先训练的矢量,这些矢量是通过爬取维基百科的所有内容并学习该数据集中单词之间的语义关系而获得的。
就像之前一样,我们将创建一个索引,这次包含所有 GloVe 向量。然后,我们可以在嵌入层中搜索类似的单词。
举个例子,搜索 said , 将会返回一个形如【word, distance】的列表:
['said', 0.0]
['told', 0.688713550567627]
['spokesman', 0.7859575152397156]
['asked', 0.872875452041626]
['noting', 0.9151610732078552]
['warned', 0.915908694267273]
['referring', 0.9276227951049805]
['reporters', 0.9325974583625793]
['stressed', 0.9445104002952576]
['tuesday', 0.9446316957473755]
这似乎非常合理,大多数单词在含义上与我们的原始单词非常相似,或代表一个合适的概念。最后的结果(tuesday)也表明这个模型远非完美,但它会让我们有一个好的开始。现在,让我们尝试在我们的模型中包含单词和图像。
一个相当大的问题
使用嵌入层之间的距离作为搜索方法是一种非常通用的方法,但这让我们对单词和图像的表示看使用嵌入层之间的距离作为搜索方法是一种非常通用的方法,但这让我们对单词和图像的表示看起来似乎并不兼容。图像的嵌入层大小为 4096,而单词的嵌入大小为 300——我们如何使用一个来搜索另一个?此外,即使两个嵌入层都是相同的大小,它们也会以完全不同的方式进行训练,因此图像和与其相关的单词很可能不会随机情况下产生相同的嵌入层。我们需要训练一个联合模型。
图像 <-> 文本
两个世界的碰撞融合
现在让我们创建一个混合模型,可以实现从单词到图像,反之亦然。
在本教程的第一课中,我们将训练我们的模型,并从一篇名为 DeViSE. 的优秀论文中汲取了灵感。虽然我们高度借鉴的这篇论文的主要想法,但我们并不会完整的重新实现它。(对于另一篇略有不同的论文,请查看 fast.ai 在 lesson 11. 的实现)
我们的想法是综合通过重新训练我们的图像模型并改变其标签的类型这两种表现。
通常,图像分类器被训练为从许多类中选择一个类别(Imagenet 的 1000 个种类)。这可以转化为——使用 Imagenet 的示例——最后一层是一个大小为 1000 的向量,表示每个类的概率。这意味着我们的模型没有语义理解哪些类与其他类相似:将 cat 的图像识别为 dog 将会导致与将其识别为 airplane. 一样多的错误。
对于我们的混合模型,我们用我们已知类的词向量替换模型的最后一层。这允许我们的模型学习将图像的语义映射到单词的语义,并且意味着类似的类将彼此更接近 (因为 cat 的词向量比 airplane 更靠近 dog )。我们将预测一个大小为 300 的语义丰富的词向量,而不是大小为 1000 的目标除了一个全部为 0。
我们通过添加两个全连接层来实现此目的:
一个大小为 2000 的中间层
一个大小为 300 的输出层(GloVe 的词向量的大小)。
这是模型在 Imagenet 上训练时的样子:
这是模型现在的样子:
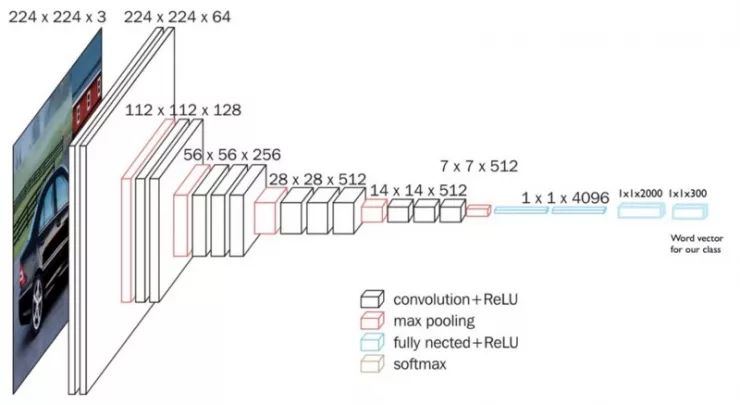
训练模型
接着,我们需要在数据集分割成的训练集上重新训练我们的模型,以学习预测与图像标签相关联的词向量。例如,对于一张属于类别 cat 的图像,我们尝试预测与 cat 相关联的 300 长度的词向量。
这种训练需要花费一些时间,但仍然比在 Imagenet 上快得多。作为参考,我的笔记本电脑上没有 GPU 的情况下需要大约 6-7 个小时。
重要的是要注意这种方法是多么浪费资源的。与通常的数据集相比,我们在这里使用的训练数据(我们数据集的 80%,因此共有 800 张图像)是微不足道的(Imagenet 有一百万张图像,大 3 个数量级)。如果我们使用传统的分类训练技术,我们不能指望我们的模型在测试集上表现得非常好,并且肯定不会期望它在全新的示例上表现出色。
一旦我们的模型训练完成,我们就可以从上面获得 GloVe 的单词索引,并通过运行数据集中的所有图像,将它保存到磁盘,构建新的关于我们的图像特征的快速索引。
标记
我们现在只需将我们的图像提供给我们训练有素的网络,就可以轻松地从任何图像中提取标签,并保存输出成大小为 300 的矢量,并从 GloVe 中找到我们的英语单词索引中最接近的单词。让我们试试这张图片——虽然它包含各种各样的物品,但它在 bottle 类中。

以下是生成的标签:
[6676, 'bottle', 0.3879561722278595]
[7494, 'bottles', 0.7513495683670044]
[12780, 'cans', 0.9817070364952087]
[16883, 'vodka', 0.9828150272369385]
[16720, 'jar', 1.0084964036941528]
[12714, 'soda', 1.0182772874832153]
[23279, 'jars', 1.0454961061477661]
[3754, 'plastic', 1.0530102252960205]
[19045, 'whiskey', 1.061428427696228]
[4769, 'bag', 1.0815287828445435]
这是一个非常优秀的结果,因为大多数标签都非常相关。这种方法虽然还有很大的成长空间,但它现在已经可以很好地掌握图像中的大多数内容。这个模型学习提取许多相关标签,甚至从那些未经过训练的类别中提取!
使用文本搜索图像
最重要的是,我们可以使用我们的联合嵌入层来使用任何单词搜索我们的图像数据库。我们只需要从 GloVe 获取我们预先训练好的单词嵌入层,并找到具有最相似嵌入层的图像(我们通过在模型中运行它们得到)。
使用最少数据进行广义图像搜索。
让我们首先从搜索在我们的训练集中的“dog”开始:

搜索 “dog"的结果
可以,相当不错的结果——但是我们可以从任何一个经由这些标签训练的分类器中得到这个!让我们来搜索更困难的关键字 “ocean”,这不在我们的数据集中。

搜索 "ocean"的结果
这太棒了——我们的模型理解到 ocean 与 water 类似,并从 boat 类中返回了许多物品。
那么搜索 "street"的结果又如何呢?
搜索 "street"的结果

在这里,我们返回的图像来自许多不同的类别(car, dog, bicycles, bus, person),但大多数都包含或靠近街道,尽管我们在训练模型时从未使用过这个概念。因为我们通过预先训练的词向量来利用外部知识库来学习从图像到比简单类别在语义上更丰富的向量的映射,所以我们的模型可以很好地理解外部知识。
可意会不可言传
英语已经发展了很久,但还不足以为任何东西都发明一个词。例如,在发表这篇文章时,没有英文单词用来形容「一只躺在沙发上的猫」,这是一个输入搜索引擎的完全有效的查询。如果我们想要同时搜索多个单词,我们可以使用一种非常简单的方法,利用词向量的算术属性。事实证明,总结两个词向量通常非常有效。因此,如果我们只是通过使用 cat 和 sofa 的平均词向量来搜索我们的图像,我们会希望获得一张非常像猫,非常像沙发一样的图像,或者在沙发上有猫的图像。
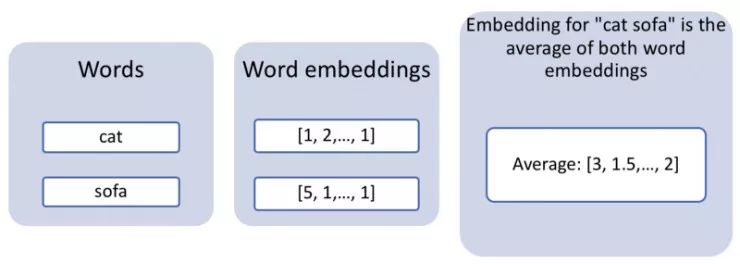
获得多个单词的混合嵌入层
让我们尝试使用这种混合嵌入层并进行搜索!

搜索"cat"+"sofa"的结果
这是一个很棒的结果,因为大多数这些图像都包含一些毛茸茸的动物和一个沙发(我特别喜欢第二排最左边的图像,这看起来像沙发旁边的一堆毛巾)!我们的模型只训练单个单词,但可以处理两个单词的组合。虽然我们没有构建像谷歌搜图这样的大工程,但对于相对简单的架构来说,这绝对令人印象深刻。
这种方法实际上可以很自然地扩展到各种领域(请参阅此示例以获取嵌入层代码),因此我们很乐意听到您最终将他实际应用的消息。
结论
我希望你发现这篇文章内容丰富,它揭开了一些基于内容的推荐和语义搜索世界的神秘面纱。如果你有任何问题或意见,或想要分享您使用本教程构建的内容,请在 Twitter 上与我联系!
想要从硅谷或纽约的顶级专业人士那里学习人工智能?了解有关人工智能领域的更多信息。
如果您是一家从事 AI 领域的公司,并希望参与进 Insight AI Fellows Program 吗? 请随时与我们联系。.
感谢 Stephanie Mari, Bastian Haase, Adrien Treuille, and Matthew Rubashkin。
原文链接:https://blog.insightdatascience.com/the-unreasonable-effectiveness-of-deep-learning-representations-4ce83fc663cf
想阅读更多计算机视觉文章?
欢迎点击“阅读原文”
或者移步 AI 研习社社区~





