6月3日组会分享:基于物理和特定领域知识的神经网络无标签监督学习
原文:
《Label-Free Supervision of Neural Network with Physics and Domain Knowledge》
本文是AAAI2017的最佳论文,作者是斯坦福的Russell Stewart,Stefano Ermon
点击文章末尾原文链接即可获取原文。
—————————————————
动机:
1.许多机器学习应用中,label数据是很稀缺,想要获得更多label需要付出很大代价。因此本文致力于不用label来监督(训练)神经网络。
2.通过观察发现,人类的学习经常不是通过直接的样本,而是通过高级训练以达到更好的性能,或者说当完成学习的时候,看起来像什么。因此考虑是否可以用相同的原理来教会机器?是否可以不用直接的标签样本而是通过对希望输出的结构进行描述来代替标签样本?
因此本文介绍一种新的方法:把握输出空间的结构而不是直接的“输入-输出”对的样例。这种限制通过先验的特定领域知识导出,比如可以通过已知的物理学定律。
—————————————————
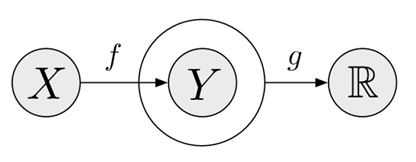
图1:限制学习目的在于不适用标签 y 来达到转换 f。而是寻找一个映射 f 来捕捉输出空间的结构,这个结构通过g得到。
问题步骤:
1. 传统的有监督学习中,给定一个n个训练样本的训练集D={(x1,y1),…,(xn,yn)},每个样本对由输入xi属于X和对应的标签yi属于Y组成,目标是学习一个函数:f:X->Y的一个映射。为了量化性能,提供一个损失函数,l:YxY->R:
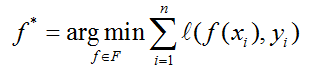
上式优化的是假设的类别。在这里,f是(卷积)神经网络的参数。
通过限制可以指定假设类别F的函数空间,我们正在利用想要解决的问题的先验知识。正是所谓的无免费午餐定理。
另一种先验知识参与模型的通用方法是为某函数在F中指定一个先验的优先权,结合正则化项: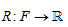
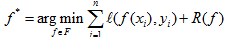
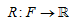
在许多机器学习问题中,输入空间X是复杂的(如图像),而输出空间Y是简单的(比如说二分类问题只有两个类Y={0,1})。我们关心结构预测问题,这样X和Y都是复杂的。如如说,在第一个实验中,X对应图像序列,Y对应物体在空中移动时的高度。目标时得到一个函数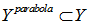
2. 本文中,我们对先验知识对输出进行结构建模,通过提供一个带权重的限制函数: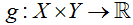
本文中我们探索的是是否这种微弱形式的监督可以充分学习到感兴趣的函数。
实验:
本文方法的目标时训练一个神经网络f,从输入到输出的映射是我们关心的,而不需要直接的输入输出对。前两个实验是从一张图像到目标位置的映射,学习关注的是通过探索整个过程中图像的结构。第三个实验中,映射一张图像到两个布尔变量描述图像中是否有两个不同的目标。学习过程探索这些目标之间的独特的因果语义。实验中,提供的label只用于评估中。
第一个实验:跟踪自由下落的物体
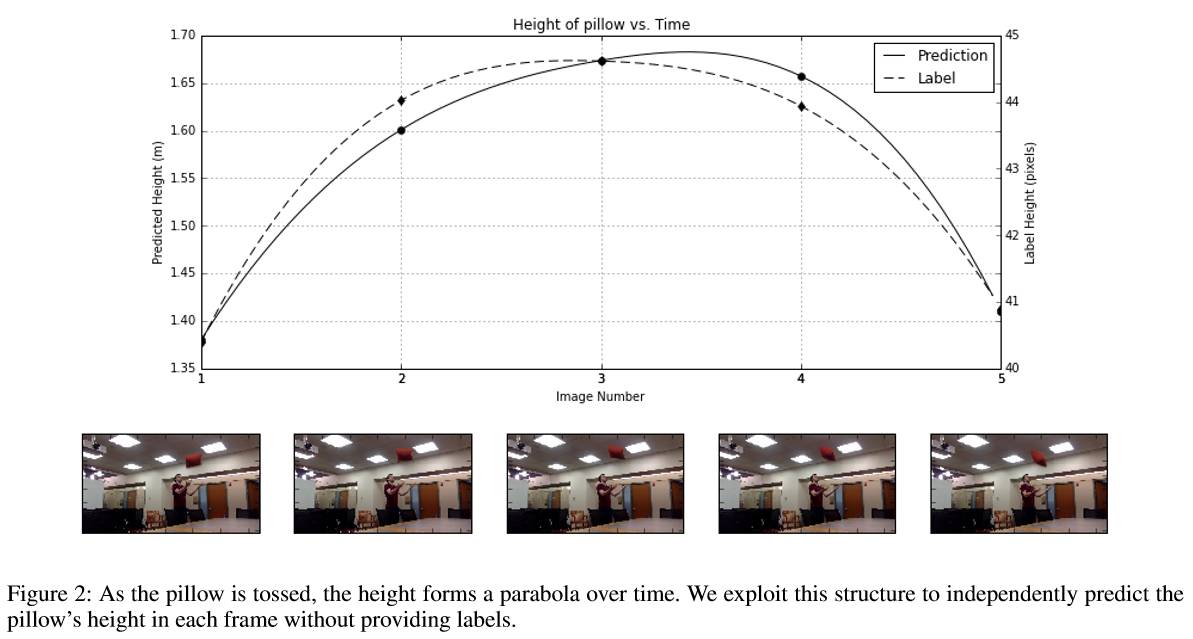
本实验中记录被抛掷的物体的视频,目的在于学习每帧物体的高度。目标时得到一个回归网络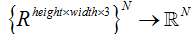
损失函数:
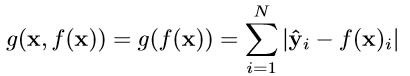
第二个实验:跟踪行人的位置
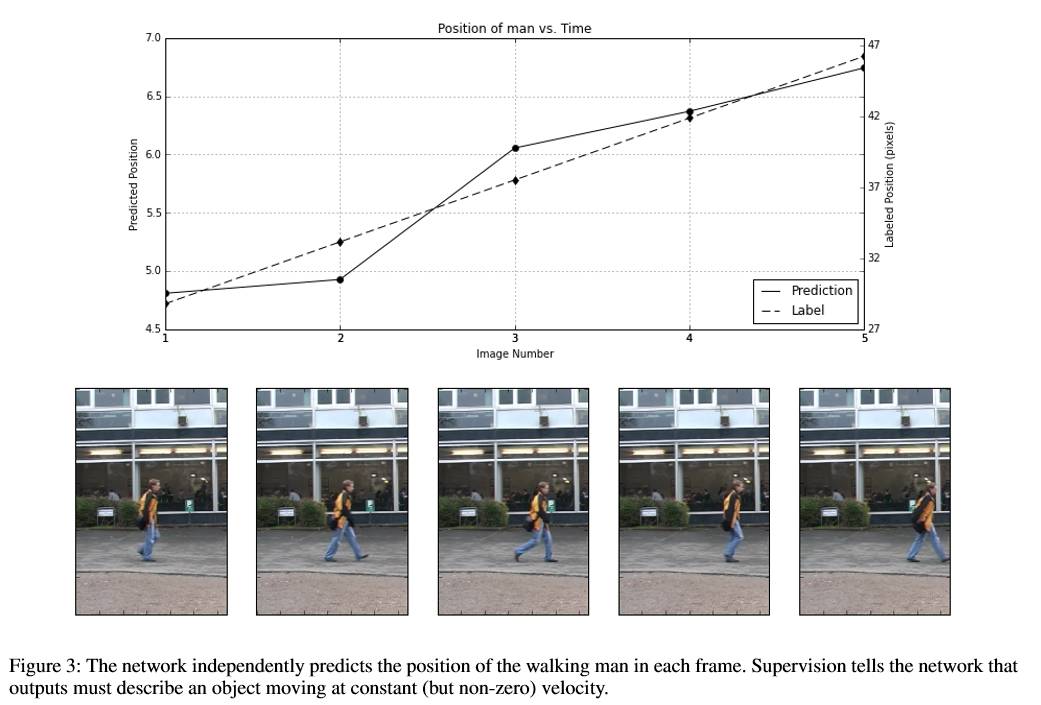
损失函数:
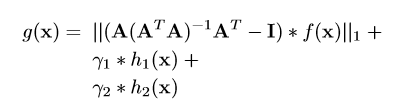
总结:
本文介绍了一种利用物理和其他领域的限制来监督神经网络的方法。未来的挑战包括扩展这种结果到大量的数据集,以及对新的问题简化选择优化项的过程。另外可以从已收集的label基础上,结合本文的方法,对神经网络进行弱监督训练。




