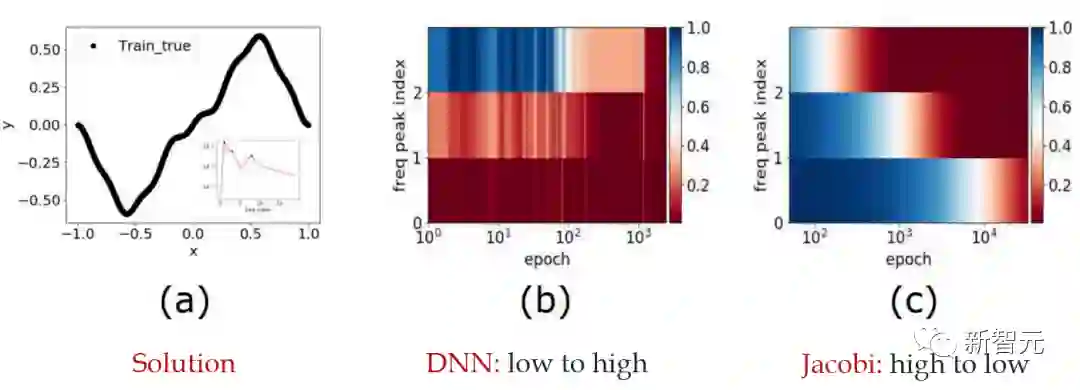
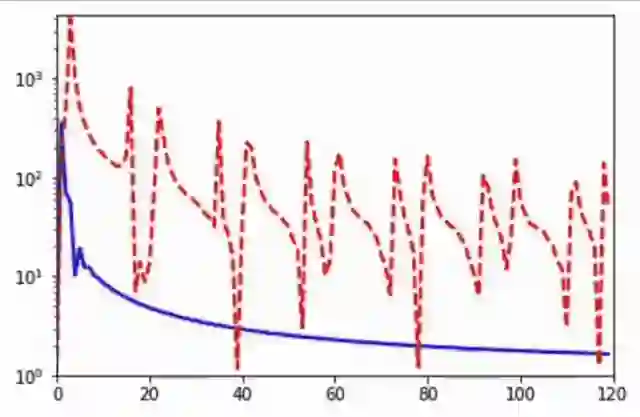
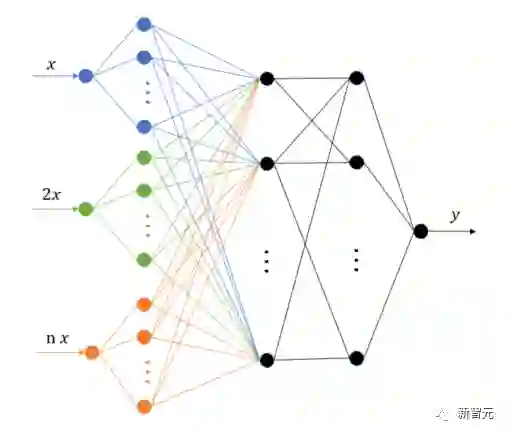
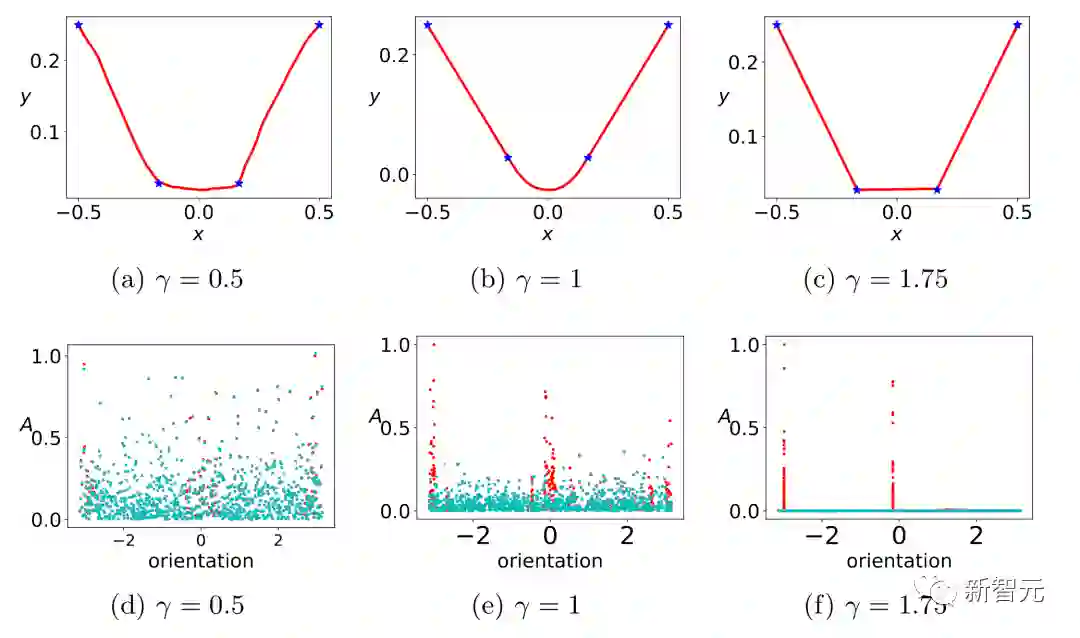
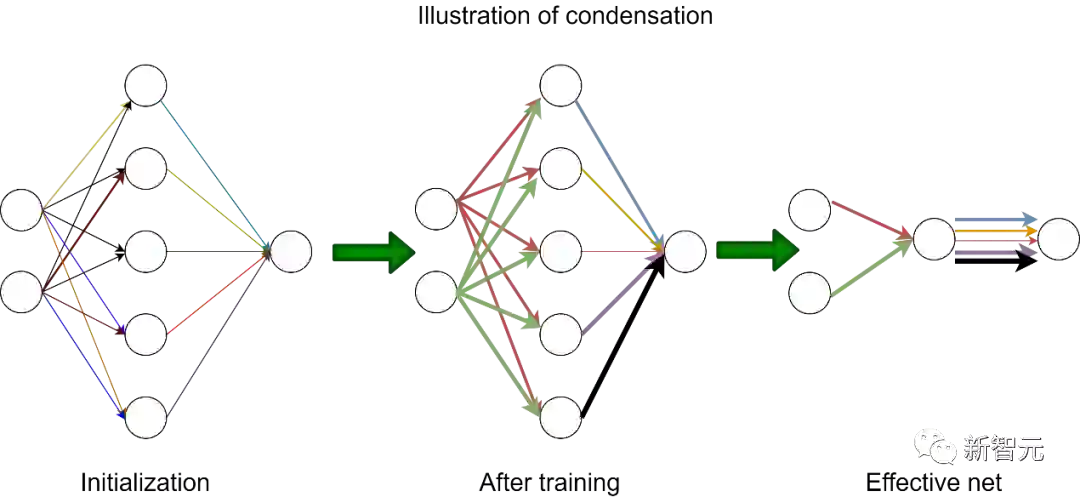
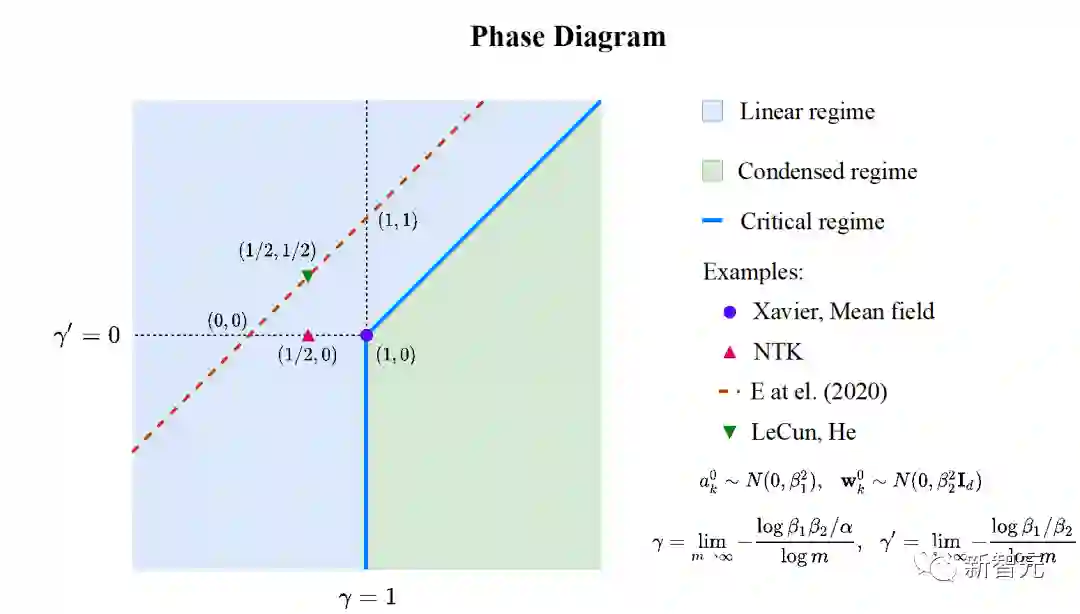
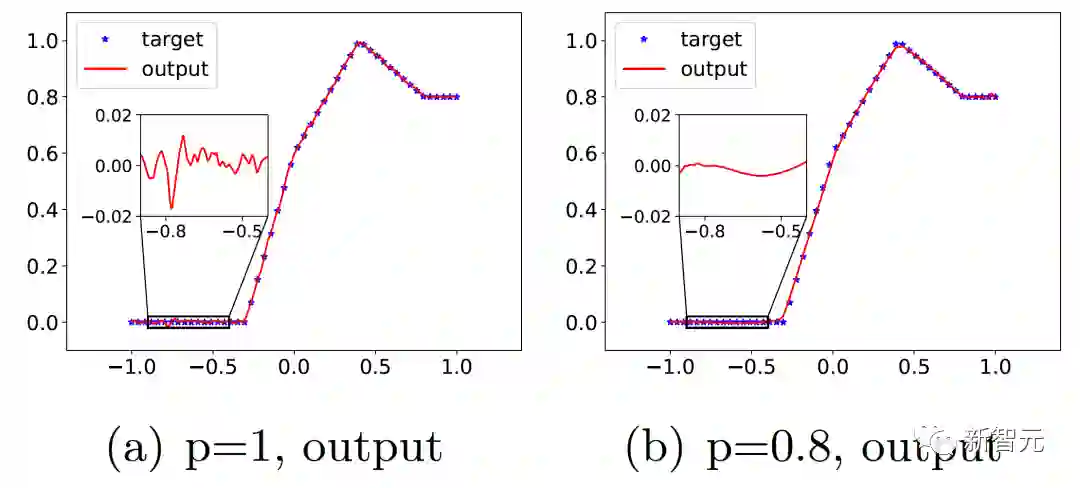
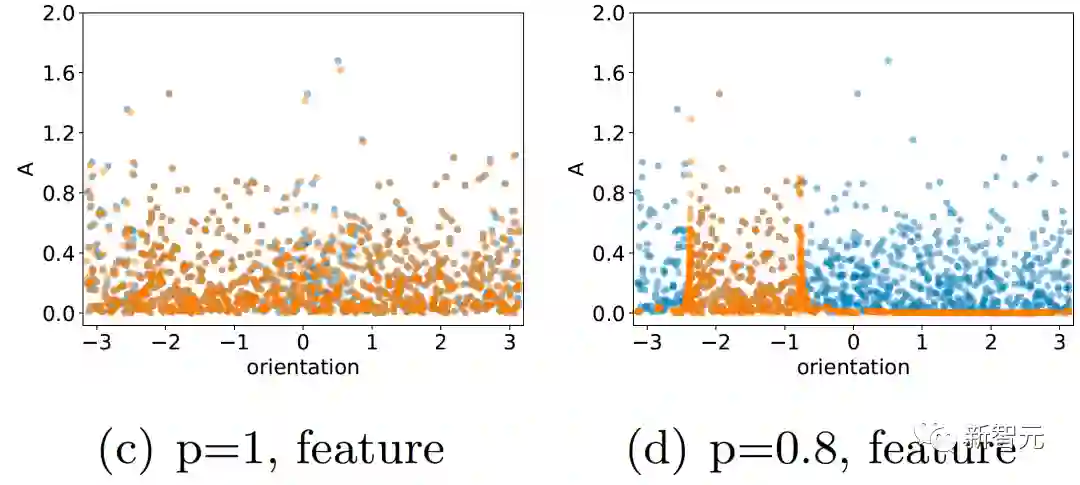
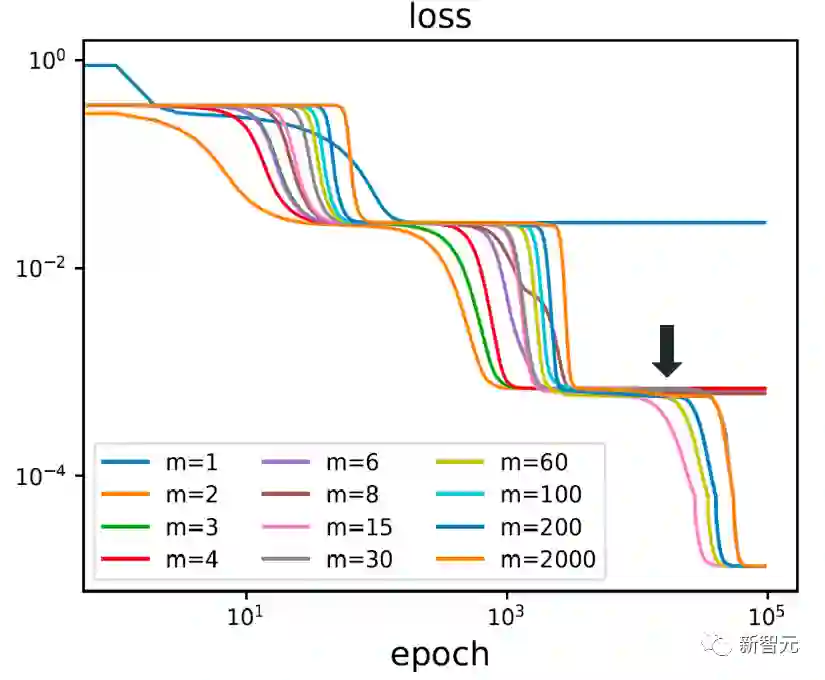
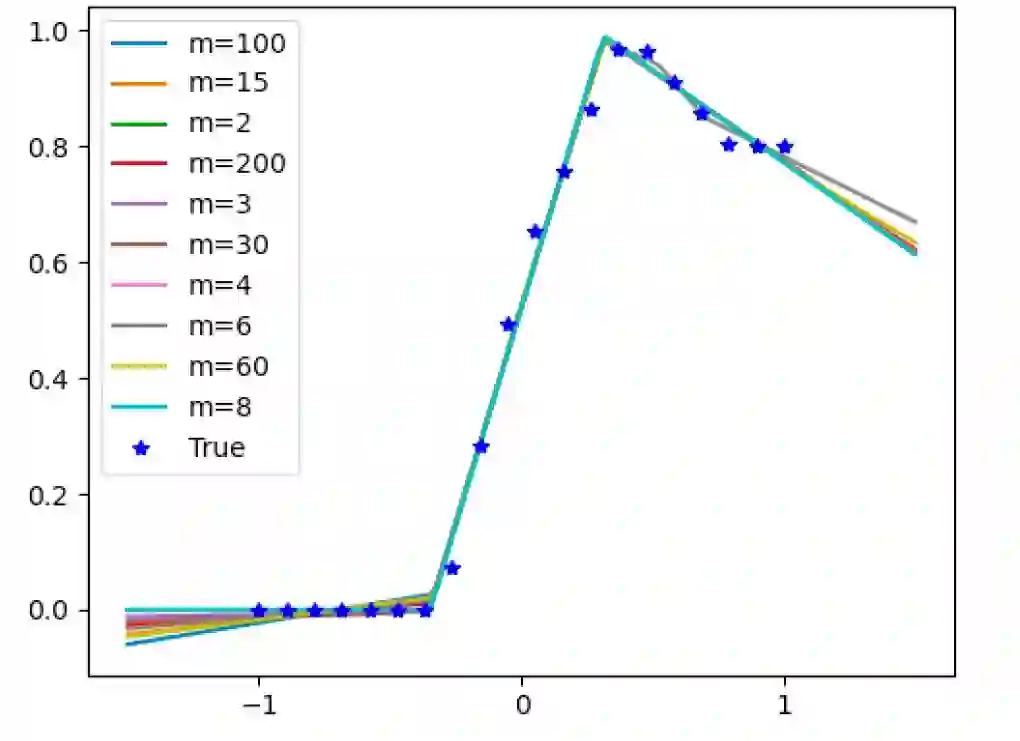
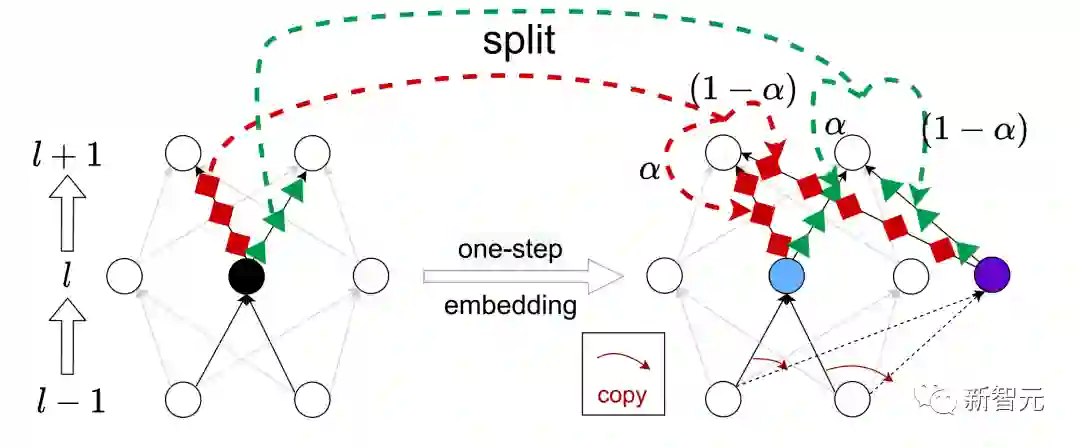
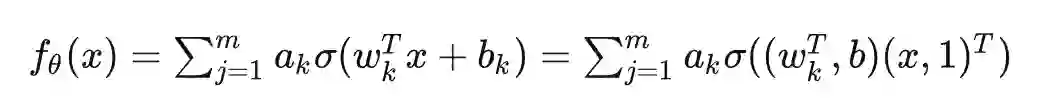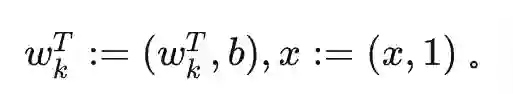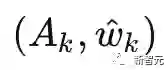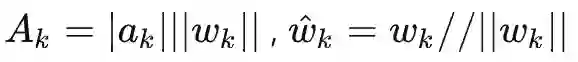过去五年,在深度学习的基础研究方面,我们主要围绕频率原则和参数凝聚两类现象展开工作。从发现它们,意识到他们很有趣,再到解释它们,并在一定程度上基于这些工作去理解深度学习的其它方面和设计更好的算法。未来五年,我们将在深度学习的基础研究和AI for Science方面深入钻研。参考资料:[1] Zhi-Qin John Xu*, Yaoyu Zhang, and Yanyang Xiao, Training behavior of deep neural network in frequency domain, arXiv preprint: 1807.01251, (2018), ICONIP 2019. [2] Zhi-Qin John Xu* , Yaoyu Zhang, Tao Luo, Yanyang Xiao, Zheng Ma, Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks, arXiv preprint: 1901.06523, Communications in Computational Physics (CiCP).[3]Tao Luo#,Zhi-Qin John Xu #, Zheng Ma, Yaoyu Zhang*, Phase diagram for two-layer ReLU neural networks at infinite-width limit, arxiv 2007.07497 (2020), Journal of Machine Learning Research (2021)[4]Hanxu Zhou, Qixuan Zhou, Tao Luo, Yaoyu Zhang*, Zhi-Qin John Xu*, Towards Understanding the Condensation of Neural Networks at Initial Training. arxiv 2105.11686 (2021), NeurIPS2022.[5] Jihong Wang,Zhi-Qin John Xu*, Jiwei Zhang*, Yaoyu Zhang, Implicit bias in understanding deep learning for solving PDEs beyond Ritz-Galerkin method, CSIAM Trans. Appl. Math.[6] Tao Luo, Zheng Ma,Zhi-Qin John Xu, Yaoyu Zhang, Theory of the frequency principle for general deep neural networks, CSIAM Trans. Appl. Math., arXiv preprint, 1906.09235 (2019).[7] Yaoyu Zhang, Tao Luo, Zheng Ma,Zhi-Qin John Xu*, Linear Frequency Principle Model to Understand the Absence of Overfitting in Neural Networks. Chinese Physics Letters, 2021.[8] Tao Luo*, Zheng Ma,Zhi-Qin John Xu, Yaoyu Zhang, On the exact computation of linear frequency principle dynamics and its generalization, SIAM Journal on Mathematics of Data Science (SIMODS) to appear, arxiv 2010.08153 (2020).[9]Tao Luo*, Zheng Ma, Zhiwei Wang, Zhi-Qin John Xu, Yaoyu Zhang, An Upper Limit of Decaying Rate with Respect to Frequency in Deep Neural Network, To appear in Mathematical and Scientific Machine Learning 2022 (MSML22),[10] Zhi-Qin John Xu* , Hanxu Zhou, Deep frequency principle towards understanding why deeper learning is faster, AAAI 2021, arxiv 2007.14313 (2020)[11] Ziqi Liu, Wei Cai,Zhi-Qin John Xu* , Multi-scale Deep Neural Network (MscaleDNN) for Solving Poisson-Boltzmann Equation in Complex Domains, arxiv 2007.11207 (2020) Communications in Computational Physics (CiCP).[12] Xi-An Li,Zhi-Qin John Xu* , Lei Zhang, A multi-scale DNN algorithm for nonlinear elliptic equations with multiple scales, arxiv 2009.14597, (2020) Communications in Computational Physics (CiCP).[13] Xi-An Li,Zhi-Qin John Xu, Lei Zhang*, Subspace Decomposition based DNN algorithm for elliptic type multi-scale PDEs. arxiv 2112.06660 (2021)[14]Yuheng Ma,Zhi-Qin John Xu*, Jiwei Zhang*, Frequency Principle in Deep Learning Beyond Gradient-descent-based Training, arxiv 2101.00747 (2021).[15]Hanxu Zhou, Qixuan Zhou, Zhenyuan Jin, Tao Luo, Yaoyu Zhang,Zhi-Qin John Xu*, Empirical Phase Diagram for Three-layer Neural Networks with Infinite Width. arxiv 2205.12101 (2022), NeurIPS2022.[16]Yaoyu Zhang*, Zhongwang Zhang, Tao Luo,Zhi-Qin John Xu*, Embedding Principle of Loss Landscape of Deep Neural Networks. NeurIPS 2021 spotlight, arxiv 2105.14573 (2021)[17] Zhongwang Zhang,Zhi-Qin John Xu*, Implicit regularization of dropout. arxiv 2207.05952 (2022)[18]Zhiwei Bai, Tao Luo,Zhi-Qin John Xu*, Yaoyu Zhang*, Embedding Principle in Depth for the Loss Landscape Analysis of Deep Neural Networks. arxiv 2205.13283 (2022)