神经网络的简单偏好


https://www.bilibili.com/video/BV1eB4y1z7tL/






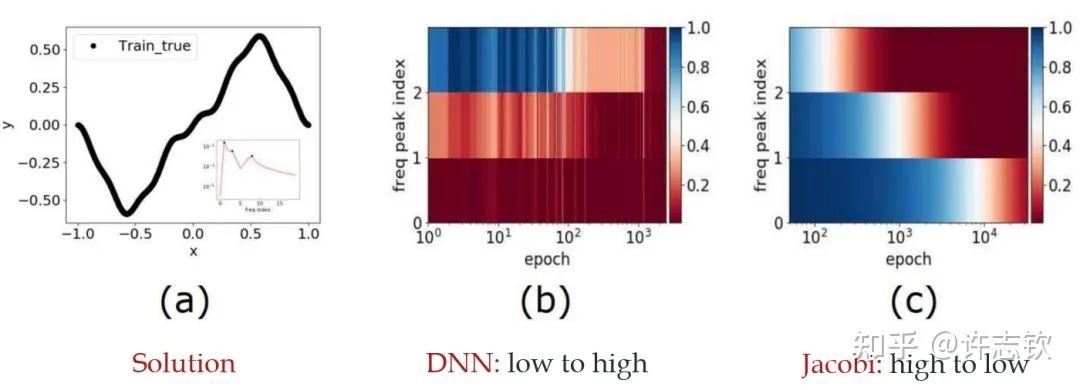
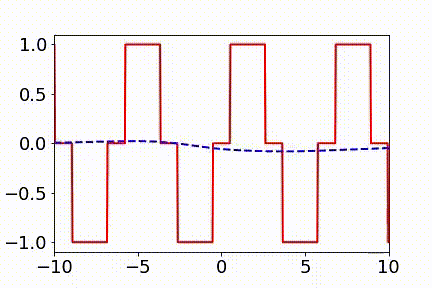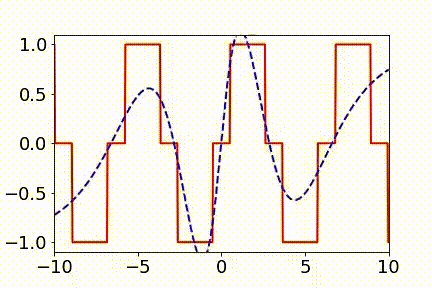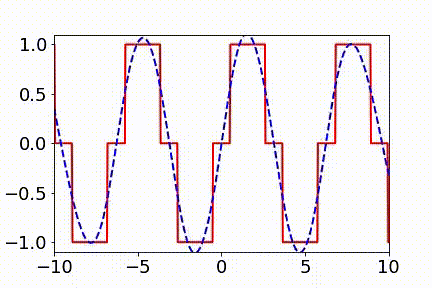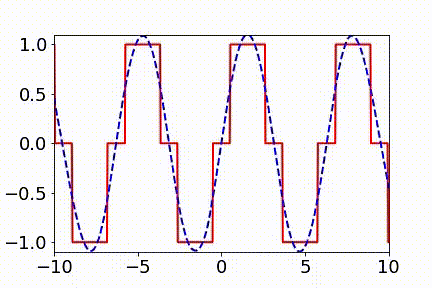
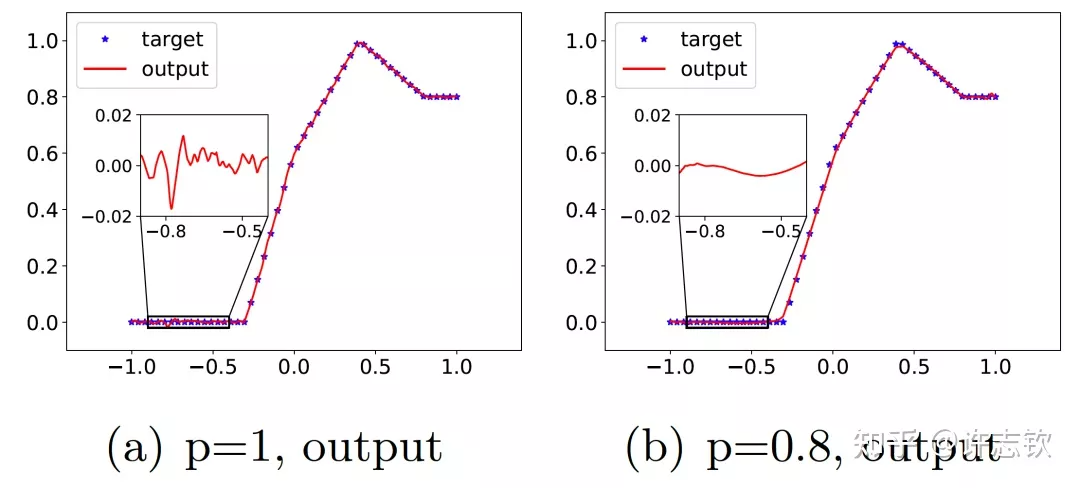
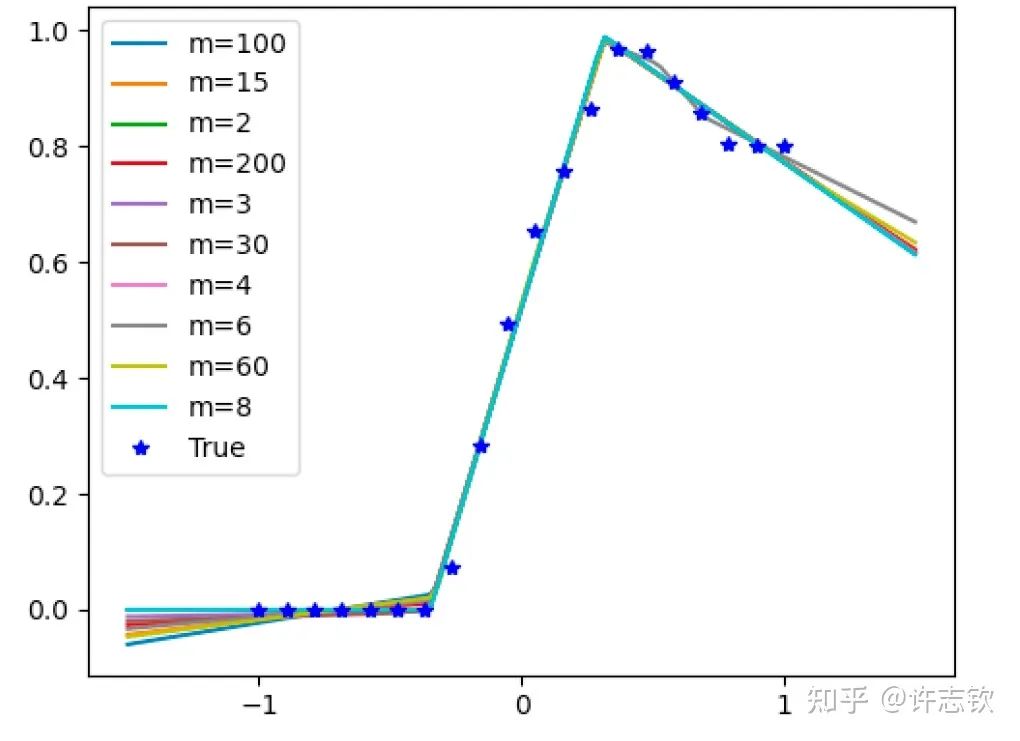
▲ 实域空间拟合(红色为目标函数,蓝色为DNN)
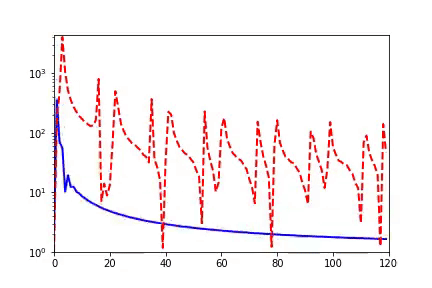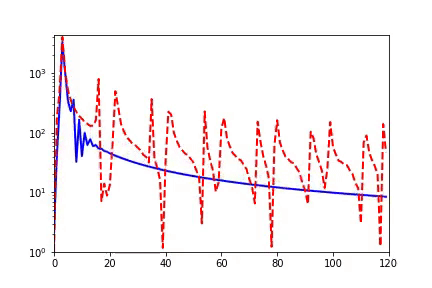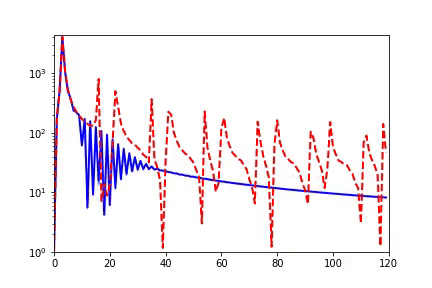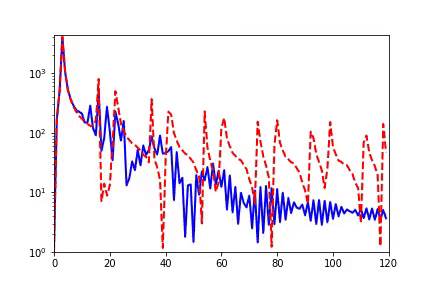

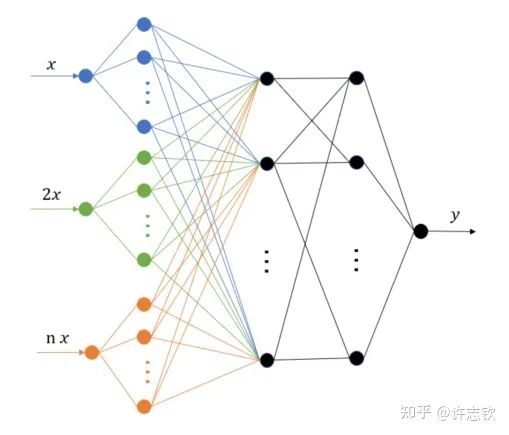

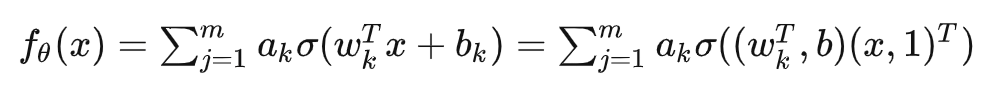
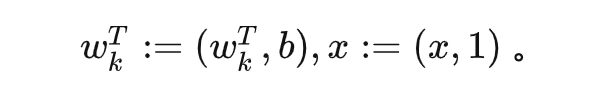
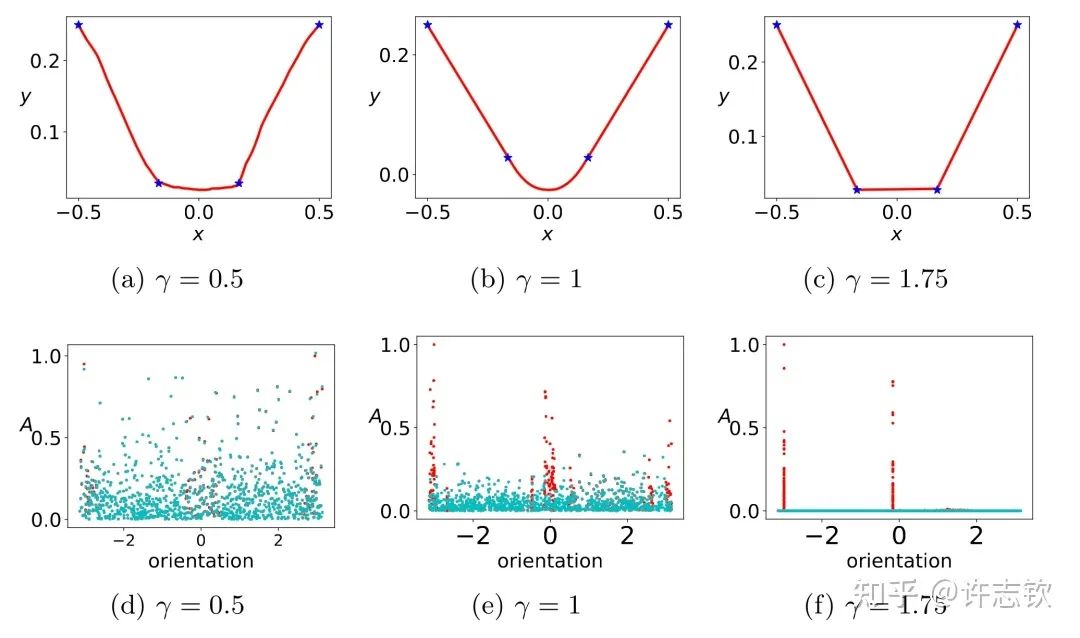

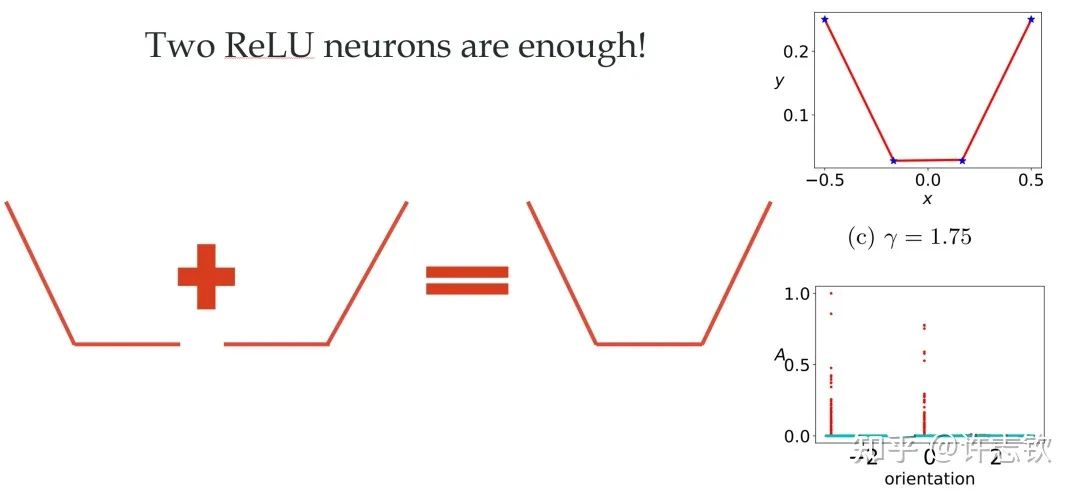
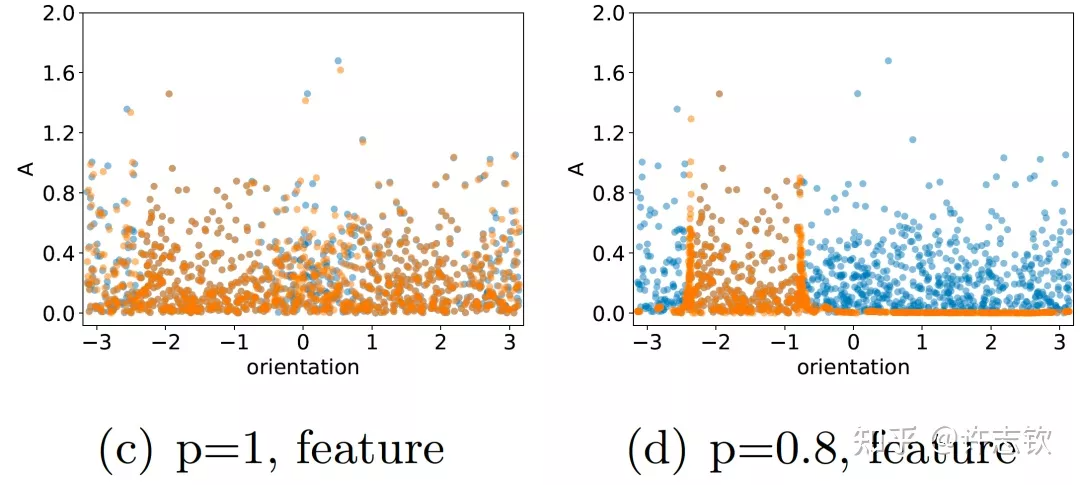
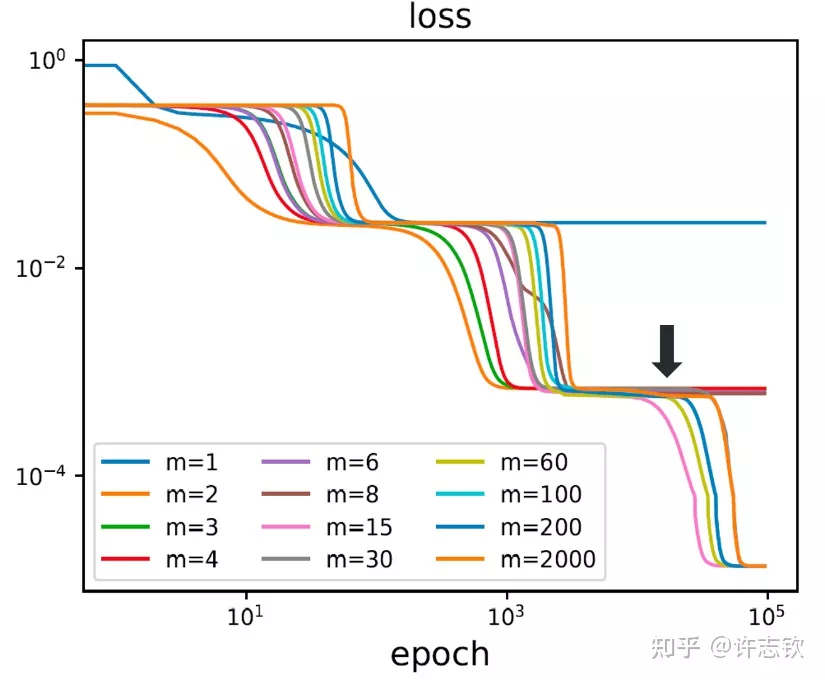
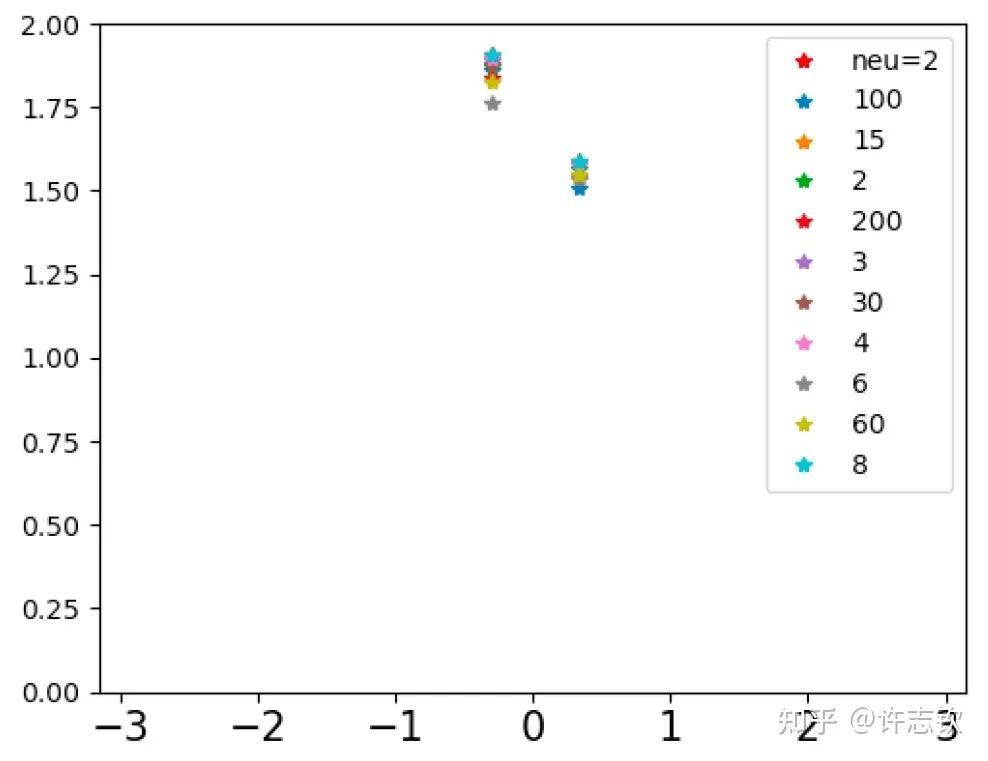
回顾在我们前面最开始提到的泛化迷团,以及我们最开始提出的问题“在实际训练中,神经网络真的很复杂吗?”,在参数凝聚的情况下,对于一个表面看起来很多参数的网络,我们自然要问:神经网络实际的有效参数有多少?比如我们前面看到的两层神经网络凝聚在两个方向的例子,实际上,这个网络的有效神经元只有两个。因此凝聚可以根据实际数据拟合的需求来有效地控制模型的复杂度。



参考文献
[1] Zhi-Qin John Xu*, Yaoyu Zhang, and Yanyang Xiao, Training behavior of deep neural network in frequency domain, arXiv preprint: 1807.01251, (2018), ICONIP 2019.
[2] Zhi-Qin John Xu* , Yaoyu Zhang, Tao Luo, Yanyang Xiao, Zheng Ma, Frequency Principle: Fourier Analysis Sheds Light on Deep Neural Networks, arXiv preprint: 1901.06523, Communications in Computational Physics (CiCP).
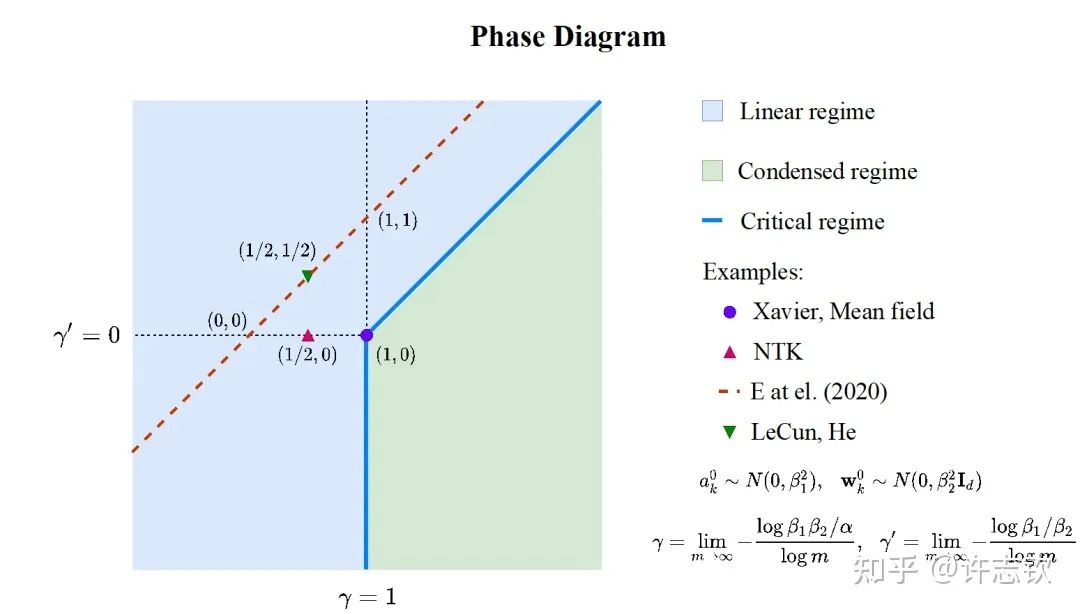
[3]Tao Luo#,Zhi-Qin John Xu #, Zheng Ma, Yaoyu Zhang*, Phase diagram for two-layer ReLU neural networks at infinite-width limit, arxiv 2007.07497 (2020), Journal of Machine Learning Research (2021)
[4]Hanxu Zhou, Qixuan Zhou, Tao Luo, Yaoyu Zhang*, Zhi-Qin John Xu*, Towards Understanding the Condensation of Neural Networks at Initial Training. arxiv 2105.11686 (2021), NeurIPS2022.
[5] Jihong Wang,Zhi-Qin John Xu*, Jiwei Zhang*, Yaoyu Zhang, Implicit bias in understanding deep learning for solving PDEs beyond Ritz-Galerkin method, CSIAM Trans. Appl. Math.
[6] Tao Luo, Zheng Ma,Zhi-Qin John Xu, Yaoyu Zhang, Theory of the frequency principle for general deep neural networks, CSIAM Trans. Appl. Math., arXiv preprint, 1906.09235 (2019).
[7] Yaoyu Zhang, Tao Luo, Zheng Ma,Zhi-Qin John Xu*, Linear Frequency Principle Model to Understand the Absence of Overfitting in Neural Networks. Chinese Physics Letters, 2021.
[8] Tao Luo*, Zheng Ma,Zhi-Qin John Xu, Yaoyu Zhang, On the exact computation of linear frequency principle dynamics and its generalization, SIAM Journal on Mathematics of Data Science (SIMODS) to appear, arxiv 2010.08153 (2020).
[9]Tao Luo*, Zheng Ma, Zhiwei Wang, Zhi-Qin John Xu, Yaoyu Zhang, An Upper Limit of Decaying Rate with Respect to Frequency in Deep Neural Network, To appear in Mathematical and Scientific Machine Learning 2022 (MSML22),
[10] Zhi-Qin John Xu* , Hanxu Zhou, Deep frequency principle towards understanding why deeper learning is faster, AAAI 2021, arxiv 2007.14313 (2020)
[11] Ziqi Liu, Wei Cai,Zhi-Qin John Xu* , Multi-scale Deep Neural Network (MscaleDNN) for Solving Poisson-Boltzmann Equation in Complex Domains, arxiv 2007.11207 (2020) Communications in Computational Physics (CiCP).
[12] Xi-An Li,Zhi-Qin John Xu* , Lei Zhang, A multi-scale DNN algorithm for nonlinear elliptic equations with multiple scales, arxiv 2009.14597, (2020) Communications in Computational Physics (CiCP).
[13] Xi-An Li,Zhi-Qin John Xu, Lei Zhang*, Subspace Decomposition based DNN algorithm for elliptic type multi-scale PDEs. arxiv 2112.06660 (2021)
[14]Yuheng Ma,Zhi-Qin John Xu*, Jiwei Zhang*, Frequency Principle in Deep Learning Beyond Gradient-descent-based Training, arxiv 2101.00747 (2021).
[15]Hanxu Zhou, Qixuan Zhou, Zhenyuan Jin, Tao Luo, Yaoyu Zhang,Zhi-Qin John Xu*, Empirical Phase Diagram for Three-layer Neural Networks with Infinite Width. arxiv 2205.12101 (2022), NeurIPS2022.
[16]Yaoyu Zhang*, Zhongwang Zhang, Tao Luo,Zhi-Qin John Xu*, Embedding Principle of Loss Landscape of Deep Neural Networks. NeurIPS 2021 spotlight, arxiv 2105.14573 (2021)
[17] Zhongwang Zhang,Zhi-Qin John Xu*, Implicit regularization of dropout. arxiv 2207.05952 (2022)
[18]Zhiwei Bai, Tao Luo,Zhi-Qin John Xu*, Yaoyu Zhang*, Embedding Principle in Depth for the Loss Landscape Analysis of Deep Neural Networks. arxiv 2205.13283 (2022)
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
点击「关注」订阅我们的专栏吧


