“超参数”与“网络结构”自动化设置方法---DeepHyper
前言:
在深度学习和机器学习算法学习和训练的过程中,有两个非常让人头疼的问题
超参数的设置
神经网络结构的设计
可以说这两个问题一直困扰每一个学习者,为了解决这些问题,谷歌公司开源了AutoML(貌似收费)。此外还有Keras(后期详解),本篇文章介绍一个自动化学习包: DeepHyper
DeepHyper
可扩展的异步神经网络和超参数搜索深度神经网络
DeepHyper是一种用于深度神经网络的自动化机器学习(AutoML)软件包。 它包括两个组成部分:
(1)神经架构搜索是一种自动搜索高性能深度神经网络架构的方法。
(2)超参数搜索是一种自动搜索给定深度神经网络的高性能超参数的方法。
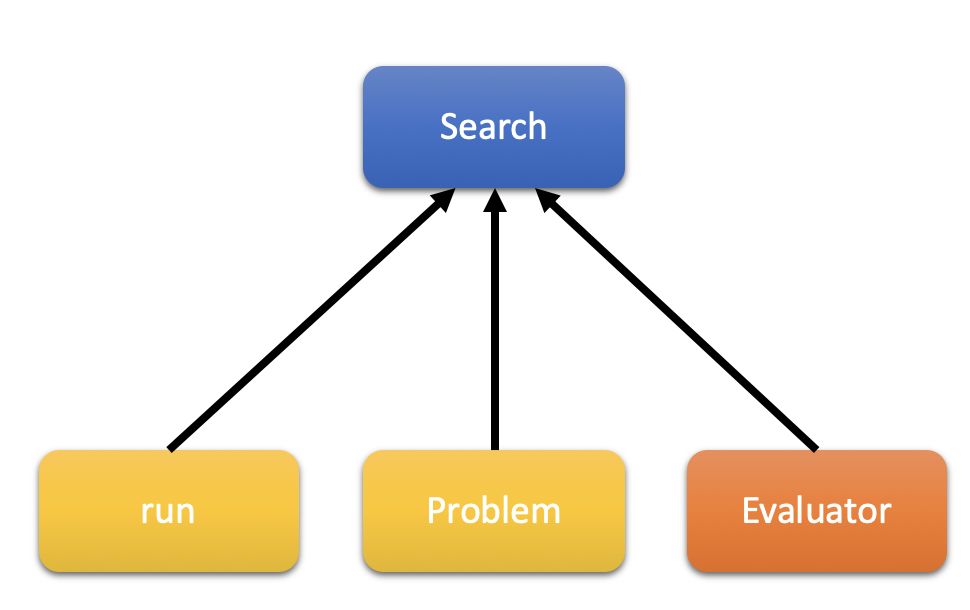
DeepHyper提供了一个基础架构,旨在针对HPC(Hyper Parameters Search)系统中的神经架构和超参数搜索方法,可扩展性和可移植性进行实验研究。 为可扩展的超参数和神经架构搜索方法的实现和研究提供了一个通用接口。 在这个包中,其为用户提供了不同的模块:
基准(benchmark):超参数或神经架构搜索的一组问题,用户可以使用它来比较我们的不同搜索算法或作为构建自己问题的示例。
评估者(evaluator):一组有助于在不同系统和不同情况下运行搜索的对象,例如快速和轻型实验或长时间和重度运行。
搜索(search):一组用于超参数和神经架构搜索的算法。 您还将找到一种模块化方法来定义新的搜索算法和用于超参数或神经架构搜索的特定子模块。
其结构如下:
一、Hyperparameter Search (HPS)搜索
(1)定义超参数问题
首先导入deephyper包,并设置问题和纬度
1from deephyper.benchmark import HpProblem
2Problem = HpProblem()
3Problem.add_dim('nunits', (10, 20), 10)
4print(Problem)
5Problem
6{'nunits': (10, 20)}
7
8Starting Point
9{'nunits': 10}
通过运行模型的函数,结果为类似{'nunits':10}的字典,但每个键的值将根据搜索的选择而改变。 下面看看如何为mnist数据上的多层Perceptron模型训练定义一个简单的运行函数。
1'''Trains a simple deep NN on the MNIST dataset.
2Gets to 98.40% test accuracy after 20 epochs
3(there is *a lot* of margin for parameter tuning).
42 seconds per epoch on a K520 GPU.
5'''
6
7from __future__ import print_function
8
9import keras
10from keras.datasets import mnist
11from keras.models import Sequential
12from keras.layers import Dense, Dropout
13from keras.optimizers import RMSprop
14
15def run(params):
16 nunits = params['nunits]
17
18 batch_size = 128
19 num_classes = 10
20 epochs = 20
21
22 # the data, split between train and test sets
23 (x_train, y_train), (x_test, y_test) = mnist.load_data()
24
25 x_train = x_train.reshape(60000, 784)
26 x_test = x_test.reshape(10000, 784)
27 x_train = x_train.astype('float32')
28 x_test = x_test.astype('float32')
29 x_train /= 255
30 x_test /= 255
31 print(x_train.shape[0], 'train samples')
32 print(x_test.shape[0], 'test samples')
33
34 # convert class vectors to binary class matrices
35 y_train = keras.utils.to_categorical(y_train, num_classes)
36 y_test = keras.utils.to_categorical(y_test, num_classes)
37
38 model = Sequential()
39 model.add(Dense(nunits, activation='relu', input_shape=(784,)))
40 model.add(Dropout(0.2))
41 model.add(Dense(512, activation='relu'))
42 model.add(Dropout(0.2))
43 model.add(Dense(num_classes, activation='softmax'))
44
45 model.summary()
46
47 model.compile(loss='categorical_crossentropy',
48 optimizer=RMSprop(),
49 metrics=['accuracy'])
50
51 history = model.fit(x_train, y_train,
52 batch_size=batch_size,
53 epochs=epochs,
54 verbose=1,
55 validation_data=(x_test, y_test))
56 score = model.evaluate(x_test, y_test, verbose=0)
57 print('Test loss:', score[0])
58 print('Test accuracy:', score[1])
59
60 return -score[1]
61
现在,如果您想要搜索上一个问题和模型。 假设问题是在“package_name/problem.py” 中定义,模型在package_name/mnist_mlp.py 中定义。 如果使用命令行运行AMBS之类的搜索:
1python ambs.py --problem package_name.problem.Problem --run package_name.mnist_mlp.run
(2)Asynchronous Model-Base Search (AMBS)
论文:点击阅读
1class deephyper.search.hps.ambs.AMBS(problem, run, evaluator, **kwargs)
2
(3) Genetic Algorithm (GA)
接口类
1class deephyper.search.hps.ga.GA(problem, run, evaluator, **kwargs)
2
完整代码
1import signal
2import random
3
4from deephyper.search.hps.optimizer import GAOptimizer
5from deephyper.search import Search
6from deephyper.search import util
7
8logger = util.conf_logger('deephyper.search.hps.ga')
9
10SERVICE_PERIOD = 2 # Delay (seconds) between main loop iterations
11CHECKPOINT_INTERVAL = 10 # How many jobs to complete between optimizer checkpoints
12EXIT_FLAG = False
13
14def on_exit(signum, stack):
15 global EXIT_FLAG
16 EXIT_FLAG = True
17
18[docs]class GA(Search):
19 def __init__(self, problem, run, evaluator, **kwargs):
20 super().__init__(problem, run, evaluator, **kwargs)
21 logger.info("Initializing GA")
22 self.optimizer = GAOptimizer(self.problem, self.num_workers, self.args)
23
24 @staticmethod
25 def _extend_parser(parser):
26 parser.add_argument('--ga_num_gen',
27 default=100,
28 type=int,
29 help='number of generation for genetic algorithm'
30 )
31 parser.add_argument('--individuals_per_worker',
32 default=5,
33 type=int,
34 help='number of individuals per worker')
35 return parser
36
37 def run(self):
38 # opt = GAOptimizer(cfg)
39 # evaluator = evaluate.create_evaluator(cfg)
40 logger.info(f"Starting new run")
41
42
43 timer = util.DelayTimer(max_minutes=None, period=SERVICE_PERIOD)
44 timer = iter(timer)
45 elapsed_str = next(timer)
46
47 logger.info("Hyperopt GA driver starting")
48 logger.info(f"Elapsed time: {elapsed_str}")
49
50
51 if self.optimizer.pop is None:
52 logger.info("Generating initial population")
53 logger.info(f"{self.optimizer.INIT_POP_SIZE} individuals")
54 self.optimizer.pop = self.optimizer.toolbox.population(n=self.optimizer.INIT_POP_SIZE)
55 individuals = self.optimizer.pop
56 self.evaluate_fitnesses(individuals, self.optimizer, self.evaluator, self.args.eval_timeout_minutes)
57 self.optimizer.record_generation(num_evals=len(self.optimizer.pop))
58
59 with open('ga_logbook.log', 'w') as fp:
60 fp.write(str(self.optimizer.logbook))
61 print("best:", self.optimizer.halloffame[0])
62
63 while self.optimizer.current_gen < self.optimizer.NGEN:
64 self.optimizer.current_gen += 1
65 logger.info(f"Generation {self.optimizer.current_gen} out of {self.optimizer.NGEN}")
66 logger.info(f"Elapsed time: {elapsed_str}")
67
68 # Select the next generation individuals
69 offspring = self.optimizer.toolbox.select(self.optimizer.pop, len(self.optimizer.pop))
70 # Clone the selected individuals
71 offspring = list(map(self.optimizer.toolbox.clone, offspring))
72
73 # Apply crossover and mutation on the offspring
74 for child1, child2 in zip(offspring[::2], offspring[1::2]):
75 if random.random() < self.optimizer.CXPB:
76 self.optimizer.toolbox.mate(child1, child2)
77 del child1.fitness.values
78 del child2.fitness.values
79
80 for mutant in offspring:
81 if random.random() < self.optimizer.MUTPB:
82 self.optimizer.toolbox.mutate(mutant)
83 del mutant.fitness.values
84
85 # Evaluate the individuals with an invalid fitness
86 invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
87 logger.info(f"Evaluating {len(invalid_ind)} invalid individuals")
88 self.evaluate_fitnesses(invalid_ind, self.optimizer, self.evaluator,
89 self.args.eval_timeout_minutes)
90
91 # The population is entirely replaced by the offspring
92 self.optimizer.pop[:] = offspring
93
94 self.optimizer.record_generation(num_evals=len(invalid_ind))
95
96 with open('ga_logbook.log', 'w') as fp:
97 fp.write(str(self.optimizer.logbook))
98 print("best:", self.optimizer.halloffame[0])
99
100 def evaluate_fitnesses(self, individuals, opt, evaluator, timeout_minutes):
101 points = map(opt.space_encoder.decode_point, individuals)
102 points = [{key:x for key,x in zip(self.problem.space.keys(), point)}
103 for point in points]
104 evaluator.add_eval_batch(points)
105 logger.info(f"Waiting on {len(points)} individual fitness evaluations")
106 results = evaluator.await_evals(points, timeout=timeout_minutes*60)
107
108 for ind, (x,fit) in zip(individuals, results):
109 ind.fitness.values = (fit,)
110
111
112
113if __name__ == "__main__":
114 args = GA.parse_args()
115 search = GA(**vars(args))
116 #signal.signal(signal.SIGINT, on_exit)
117 #signal.signal(signal.SIGTERM, on_exit)
118 search.run()
二、神经网络搜索
Neural Architecture Search (NAS)
(1)异步搜索 NAS A3C (PPO) Asynchronous
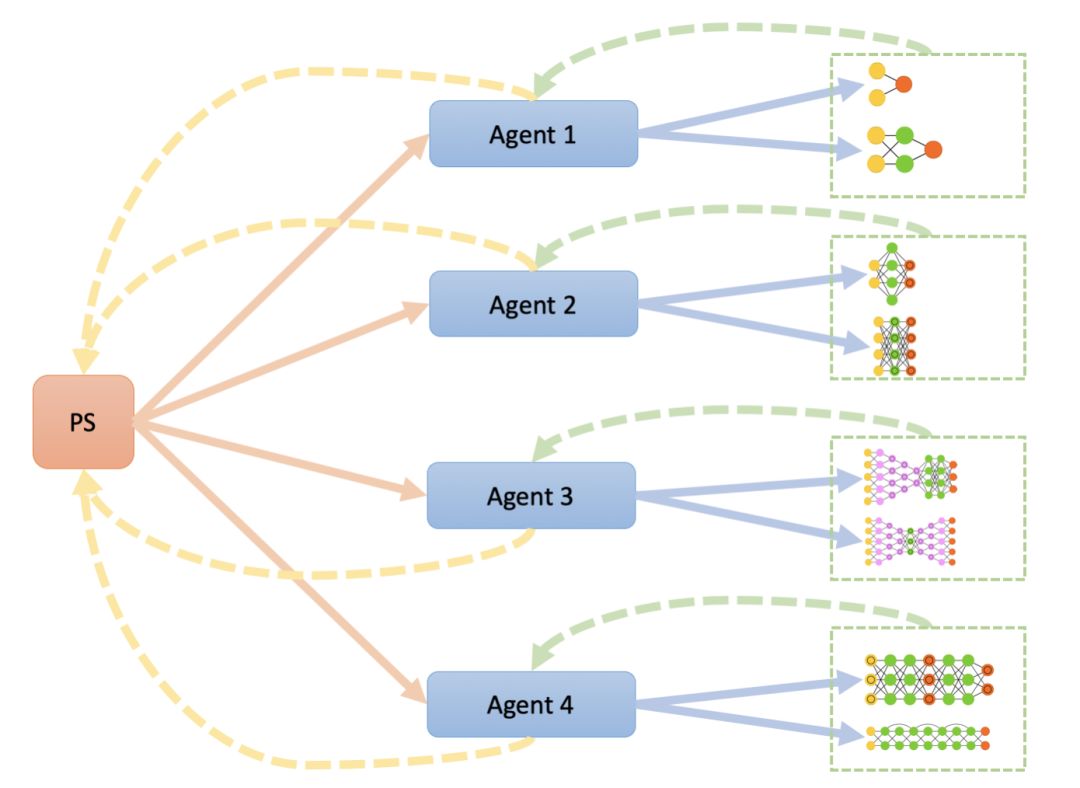
搜索接口类
1class deephyper.search.nas.ppo_a3c_async.NasPPOAsyncA3C(problem, run, evaluator, **kwargs)
2
具体搜索运行代码:
1mpirun -np 2 python ppo_a3c_async.py --problem deephyper.benchmark.nas.mnist1D.problem.Problem --run deephyper.search.nas.model.run.alpha.run --evaluator subprocess
完整代码:
1import os
2import json
3from math import ceil, log
4from pprint import pprint, pformat
5from mpi4py import MPI
6import math
7
8from deephyper.evaluator import Evaluator
9from deephyper.search import util, Search
10
11from deephyper.search.nas.agent import nas_ppo_async_a3c
12
13logger = util.conf_logger('deephyper.search.nas.ppo_a3c_async')
14
15def print_logs(runner):
16 logger.debug('num_episodes = {}'.format(runner.global_episode))
17 logger.debug(' workers = {}'.format(runner.workers))
18
19def key(d):
20 return json.dumps(dict(arch_seq=d['arch_seq']))
21
22LAUNCHER_NODES = int(os.environ.get('BALSAM_LAUNCHER_NODES', 1))
23WORKERS_PER_NODE = int(os.environ.get('DEEPHYPER_WORKERS_PER_NODE', 1))
24
25[docs]class NasPPOAsyncA3C(Search):
26 """Neural Architecture search using proximal policy gradient with asynchronous optimization.
27 """
28
29 def __init__(self, problem, run, evaluator, **kwargs):
30 super().__init__(problem, run, evaluator, **kwargs)
31 # set in super : self.problem
32 # set in super : self.run_func
33 # set in super : self.evaluator
34 self.evaluator = Evaluator.create(self.run_func,
35 cache_key=key,
36 method=evaluator)
37
38 self.num_episodes = kwargs.get('num_episodes')
39 if self.num_episodes is None:
40 self.num_episodes = math.inf
41
42 self.reward_rule = util.load_attr_from('deephyper.search.nas.agent.utils.'+kwargs['reward_rule'])
43
44 self.space = self.problem.space
45
46 logger.debug(f'evaluator: {type(self.evaluator)}')
47
48 self.num_agents = MPI.COMM_WORLD.Get_size() - 1 # one is the parameter server
49 self.rank = MPI.COMM_WORLD.Get_rank()
50
51 logger.debug(f'num_agents: {self.num_agents}')
52 logger.debug(f'rank: {self.rank}')
53
54 @staticmethod
55 def _extend_parser(parser):
56 parser.add_argument('--num-episodes', type=int, default=None,
57 help='maximum number of episodes')
58 parser.add_argument('--reward-rule', type=str,
59 default='final_reward_for_all_timesteps',
60 choices=[
61 'final_reward_for_all_timesteps',
62 'episode_reward_for_final_timestep'
63 ],
64 help='A function which describe how to spread the episodic reward on all timesteps of the corresponding episode.')
65 return parser
66
67 def main(self):
68 # Settings
69 #num_parallel = self.evaluator.num_workers - 4 #balsam launcher & controller of search for cooley
70 # num_nodes = self.evaluator.num_workers - 1 #balsam launcher & controller of search for theta
71 num_nodes = LAUNCHER_NODES * WORKERS_PER_NODE - 1 # balsam launcher
72 num_nodes -= 1 # parameter server is neither an agent nor a worker
73 if num_nodes > self.num_agents:
74 num_episodes_per_batch = (num_nodes-self.num_agents)//self.num_agents
75 else:
76 num_episodes_per_batch = 1
77
78 if self.rank == 0:
79 logger.debug(f'<Rank={self.rank}> num_nodes: {num_nodes}')
80 logger.debug(f'<Rank={self.rank}> num_episodes_per_batch: {num_episodes_per_batch}')
81
82 logger.debug(f'<Rank={self.rank}> starting training...')
83 nas_ppo_async_a3c.train(
84 num_episodes=self.num_episodes,
85 seed=2018,
86 space=self.problem.space,
87 evaluator=self.evaluator,
88 num_episodes_per_batch=num_episodes_per_batch,
89 reward_rule=self.reward_rule
90 )
91
92
93if __name__ == "__main__":
94 args = NasPPOAsyncA3C.parse_args()
95 search = NasPPOAsyncA3C(**vars(args))
96 search.main()
(2)同步更新 NAS A3C (PPO) Synchronous
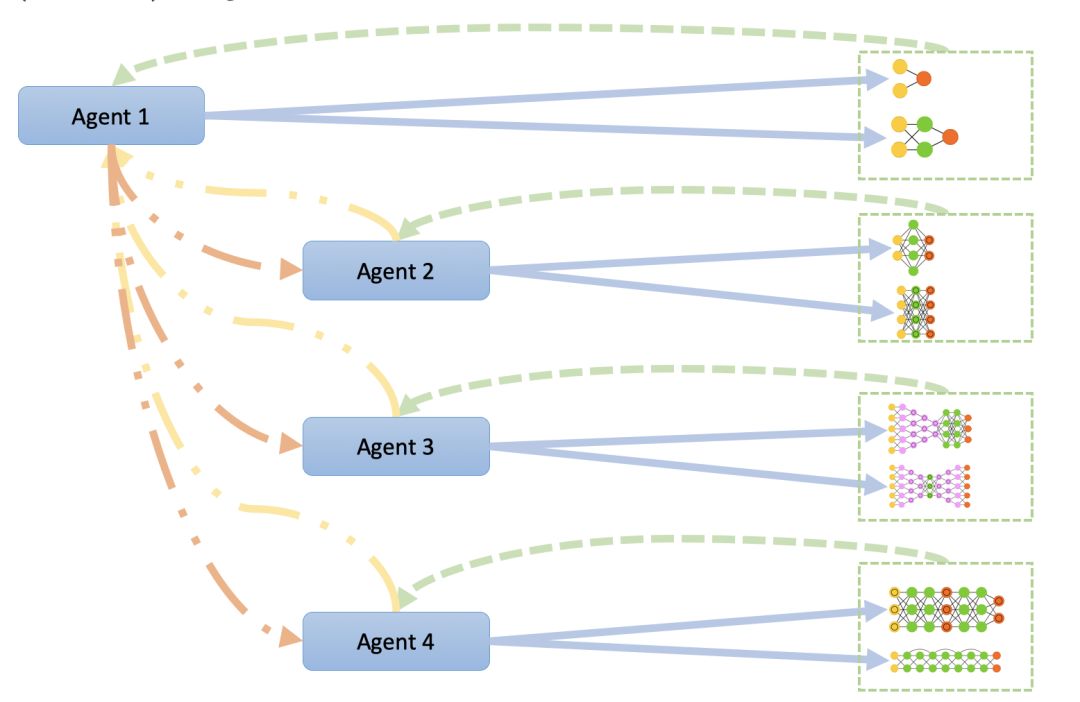
1class deephyper.search.nas.ppo_a3c_sync.NasPPOSyncA3C(problem, run, evaluator, **kwargs)
2
使用近端策略梯度进行神经结构搜索和同步优化
1python -m deephyper.search.nas.ppo_a3c_sync --evaluator subprocess --problem 'deephyper.benchmark.nas.linearReg.problem.Problem' --run 'deephyper.search.nas.model.run.alpha.run'
或者使用MPI来启动n个代理,其中n = np,因为所有代理都是将与第一个代理同步:
1mpirun -np 2 python ppo_a3c_async.py --problem deephyper.benchmark.nas.mnist1D.problem.Problem --run deephyper.search.nas.model.run.alpha.run --evaluator subprocess
完整代码实现
1import os
2import json
3from pprint import pprint, pformat
4from mpi4py import MPI
5import math
6
7from deephyper.evaluator import Evaluator
8from deephyper.search import util, Search
9
10from deephyper.search.nas.agent import nas_ppo_sync_a3c
11
12logger = util.conf_logger('deephyper.search.nas.ppo_a3c_sync')
13
14def print_logs(runner):
15 logger.debug('num_episodes = {}'.format(runner.global_episode))
16 logger.debug(' workers = {}'.format(runner.workers))
17
18def key(d):
19 return json.dumps(dict(arch_seq=d['arch_seq']))
20
21LAUNCHER_NODES = int(os.environ.get('BALSAM_LAUNCHER_NODES', 1))
22WORKERS_PER_NODE = int(os.environ.get('DEEPHYPER_WORKERS_PER_NODE', 1))
23
24[docs]class NasPPOSyncA3C(Search):
25 """Neural Architecture search using proximal policy gradient with synchronous optimization.
26 """
27
28 def __init__(self, problem, run, evaluator, **kwargs):
29 super().__init__(problem, run, evaluator, **kwargs)
30 # set in super : self.problem
31 # set in super : self.run_func
32 # set in super : self.evaluator
33 self.evaluator = Evaluator.create(self.run_func,
34 cache_key=key,
35 method=evaluator)
36
37 self.num_episodes = kwargs.get('num_episodes')
38 if self.num_episodes is None:
39 self.num_episodes = math.inf
40
41 self.reward_rule = util.load_attr_from('deephyper.search.nas.agent.utils.'+kwargs['reward_rule'])
42
43 self.space = self.problem.space
44
45 logger.debug(f'evaluator: {type(self.evaluator)}')
46
47 self.num_agents = MPI.COMM_WORLD.Get_size() - 1 # one is the parameter server
48 self.rank = MPI.COMM_WORLD.Get_rank()
49
50 logger.debug(f'num_agents: {self.num_agents}')
51 logger.debug(f'rank: {self.rank}')
52
53 @staticmethod
54 def _extend_parser(parser):
55 parser.add_argument('--num-episodes', type=int, default=None,
56 help='maximum number of episodes')
57 parser.add_argument('--reward-rule', type=str,
58 default='reward_for_final_timestep',
59 choices=[
60 'reward_for_all_timesteps',
61 'reward_for_final_timestep'
62 ],
63 help='A function which describe how to spread the episodic reward on all timesteps of the corresponding episode.')
64 return parser
65
66 def main(self):
67 # Settings
68 #num_parallel = self.evaluator.num_workers - 4 #balsam launcher & controller of search for cooley
69 # num_nodes = self.evaluator.num_workers - 1 #balsam launcher & controller of search for theta
70 num_nodes = LAUNCHER_NODES * WORKERS_PER_NODE - 1 # balsam launcher
71 if num_nodes > self.num_agents:
72 num_episodes_per_batch = (num_nodes-self.num_agents)//self.num_agents
73 else:
74 num_episodes_per_batch = 1
75
76 if self.rank == 0:
77 logger.debug(f'<Rank={self.rank}> num_nodes: {num_nodes}')
78 logger.debug(f'<Rank={self.rank}> num_episodes_per_batch: {num_episodes_per_batch}')
79
80 logger.debug(f'<Rank={self.rank}> starting training...')
81 nas_ppo_sync_a3c.train(
82 num_episodes=self.num_episodes,
83 seed=2018,
84 space=self.problem.space,
85 evaluator=self.evaluator,
86 num_episodes_per_batch=num_episodes_per_batch,
87 reward_rule=self.reward_rule
88 )
89
90
91if __name__ == "__main__":
92 args = NasPPOSyncA3C.parse_args()
93 search = NasPPOSyncA3C(**vars(args))
94 search.main()
(3)随机搜索 NAS Random
1class deephyper.search.nas.random.NasRandom(problem, run, evaluator, **kwargs)
2
好了,下面先安装
1From pip:
2
3pip install deephyper
4From github:
5
6git clone https://github.com/deephyper/deephyper.git
7cd deephyper/
8pip install -e .
9#if you want to install deephyper with test and documentation packages:
10
11# From Pypi
12pip install 'deephyper[tests,docs]'
13
14# From github
15git clone https://github.com/deephyper/deephyper.git
16cd deephyper/
17pip install -e '.[tests,docs]'
以上为本文内容,详细内容请学习文档内容
参考文献:https://deephyper.readthedocs.io/en/latest/?badge=latest
具体的详细使用文档请查看下面博客中的链接,或者关注本公众号,回复:“DeepHyper使用文档”,获取链接!
如果有想交流学习深度强化学习的伙伴,请添加微信小助手:NeuronDance 小助手将邀请您进微信群聊。

CSDN-blog
https://blog.csdn.net/gsww404/column/info/20885
知乎专栏
https://zhuanlan.zhihu.com/drl-paper


