变分自编码器VAE:这样做为什么能成?
作者丨苏剑林
单位丨广州火焰信息科技有限公司
研究方向丨NLP,神经网络
个人主页丨kexue.fm
话说我觉得我自己最近写文章都喜欢长篇大论了,而且扎堆地来。之前连续写了三篇关于 Capsule 的介绍,这次轮到 VAE 了。本文是 VAE 的第三篇探索,说不准还会有第四篇。不管怎么样,数量不重要,重要的是能把问题都想清楚。尤其是对于 VAE 这种新奇的建模思维来说,更加值得细细地抠。
这次我们要关心的一个问题是:VAE 为什么能成?
估计看 VAE 的读者都会经历这么几个阶段。第一个阶段是刚读了 VAE 的介绍,然后云里雾里的,感觉像自编码器又不像自编码器的,反复啃了几遍文字并看了源码之后才知道大概是怎么回事。
第二个阶段就是在第一个阶段的基础上,再去细读 VAE 的原理,诸如隐变量模型、KL 散度、变分推断等等,细细看下去,发现虽然折腾来折腾去,最终居然都能看明白了。
这时候读者可能就进入第三个阶段了。在这个阶段中,我们会有诸多疑问,尤其是可行性的疑问:“为什么它这样反复折腾,最终出来模型是可行的?我也有很多想法呀,为什么我的想法就不行?”
前文之要
让我们再不厌其烦地回顾一下前面关于 VAE 的一些原理。
VAE 希望通过隐变量分解来描述数据 X 的分布。
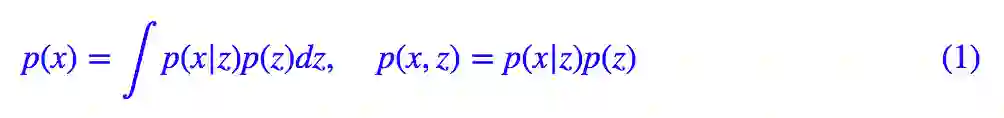
然后对 p(x,z) 用模型 q(x|z) 拟合,p(z) 用模型 q(z) 拟合,为了使得模型具有生成能力,q(z) 定义为标准正态分布。
理论上,我们可以使用边缘概率的最大似然来求解模型:
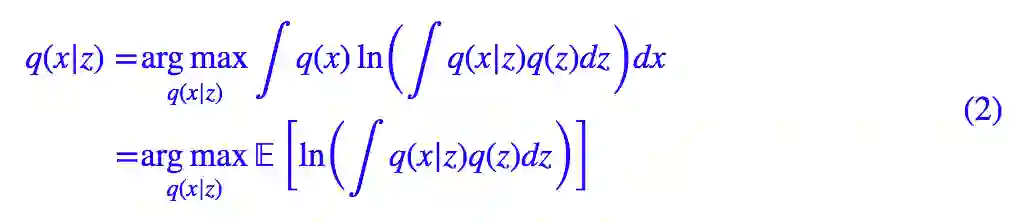
但是由于圆括号内的积分没法显式求出来,所以我们只好引入 KL 散度来观察联合分布的差距,最终目标函数变成了:
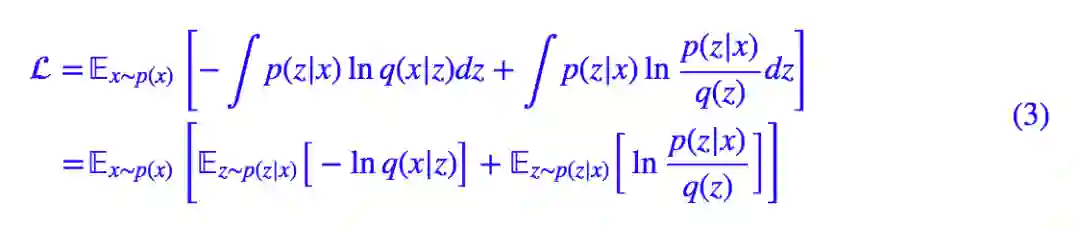
通过最小化 L 来分别找出 p(x|z) 和 q(x|z)。前一文再谈变分自编码器VAE:从贝叶斯观点出发也表明 L 有下界 −𝔼x∼p(x)[lnp(x)],所以比较 L 与 −𝔼x∼p(x)[lnp(x)] 的接近程度就可以比较生成器的相对质量。
采样之惑
在这部分内容中,我们试图对 VAE 的原理做细致的追问,以求能回答 VAE 为什么这样做,最关键的问题是,为什么这样做就可行。
采样一个点就够
对于 (3) 式,我们后面是这样处理的:
1. 留意到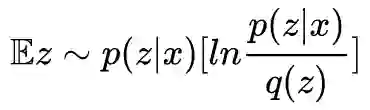
2. 𝔼z∼p(z|x)[−lnq(x|z)] 这一项我们认为只采样一个就够代表性了,所以这一项变成了 −lnq(x|z),z∼p(z|x)。
经过这样的处理,整个 loss 就可以明确写出来了:
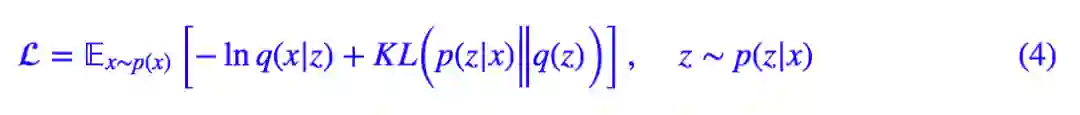
等等,可能有读者看不过眼了:KL(p(z|x)‖q(z)) 事先算出来,相当于是采样了无穷多个点来估算这一项;而 𝔼z∼p(z|x)[−lnq(x|z)] 却又只采样一个点,大家都是 loss 的一部分,这样不公平待遇真的好么?
事实上,
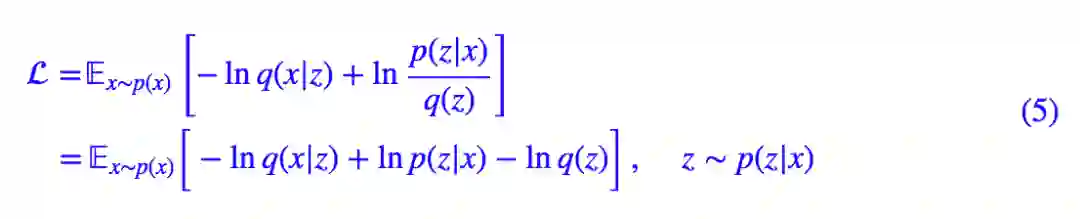
这个 loss 虽然跟标准的 VAE 有所不同,但事实上也能收敛到相似的结果。
为什么一个点就够?
那么,为什么采样一个点就够了呢?什么情况下才是采样一个点就够?
首先,我举一个“采样一个点不够”的例子,让我们回头看 (2) 式,它其实可以改写成:
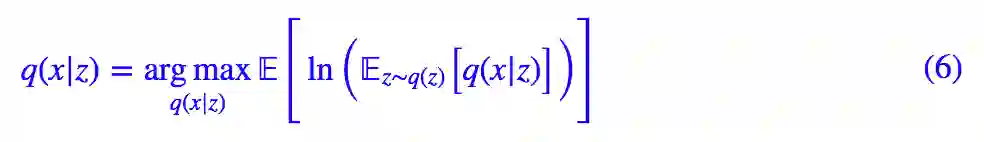
如果采样一个点就够了,不,这里还是谨慎一点,采样 k 个点吧,那么我们可以写出:
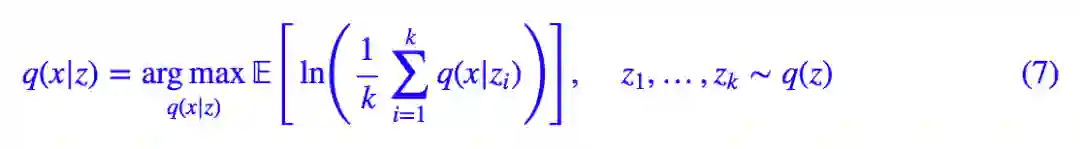
然后就可以梯度下降训练了。
然而,这样的策略是不成功的。实际中我们能采样的数目 k,一般要比每个 batch 的大小要小,这时候最大化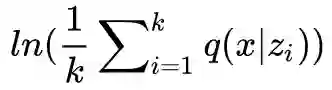
每次迭代时,一个 batch 中的各个 xi 都在争夺 z1,z2,…,zk,谁争夺成功了,q(x|z) 就大。说白了,哪个 xi 能找到专属于它的 zj,这意味着 zj 只能生成 xi,不能生成其它的,那么 z(xi|zj) 就大),但是每个样本都是平等的,采样又是随机的,我们无法预估每次“资源争夺战”的战况。这完全就是一片混战。
如果数据集仅仅是 mnist,那还好一点,因为 mnist 的样本具有比较明显的聚类倾向,所以采样数母 k 超过 10,那么就够各个 xi 分了。
但如果像人脸、imagenet 这些没有明显聚类倾向、类内方差比较大的数据集,各个 z 完全是不够分的,一会 xi 抢到了 zj,一会 xi+1 抢到了 zj,训练就直接失败了。
因此,正是这种“僧多粥少”的情况导致上述模型 (7) 训练不成功。可是,为什么 VAE 那里采样一个点就成功了呢?
一个点确实够了
这就得再分析一下我们对 q(x|z) 的想法了,我们称 q(x|z) 为生成模型部分,一般情况下我们假设它为伯努利分布或高斯分布,考虑到伯努利分布应用场景有限,这里只假设它是正态分布,那么:
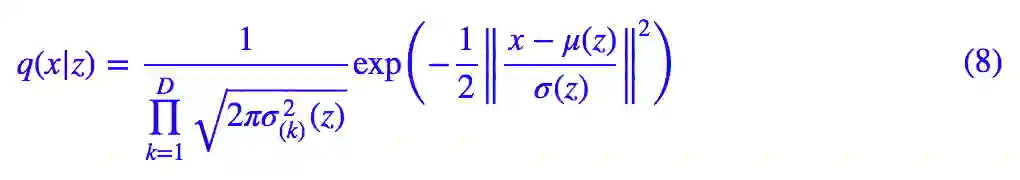
其中 μ(z) 是用来计算均值的网络,σ^2(z)是用来计算方差的网络,很多时候我们会固定方差,那就只剩一个计算均值的网络了。
注意,q(x|z) 只是一个概率分布,我们从q(z)中采样出 z 后,代入 q(x|z) 后得到 q(x|z) 的具体形式,理论上我们还要从 q(x|z) 中再采样一次才得到 x。但是,我们并没有这样做,我们直接把均值网络 μ(z) 的结果就当成 x。
而能这样做,表明 q(x|z) 是一个方差很小的正态分布(如果是固定方差的话,则训练前需要调低方差,如果不是正态分布而是伯努利分布的话,则不需要考虑这个问题,它只有一组参数),每次采样的结果几乎都是相同的(都是均值 μ(z)),此时 x 和 z 之间“几乎”具有一一对应关系,接近确定的函数 x=μ(z)。
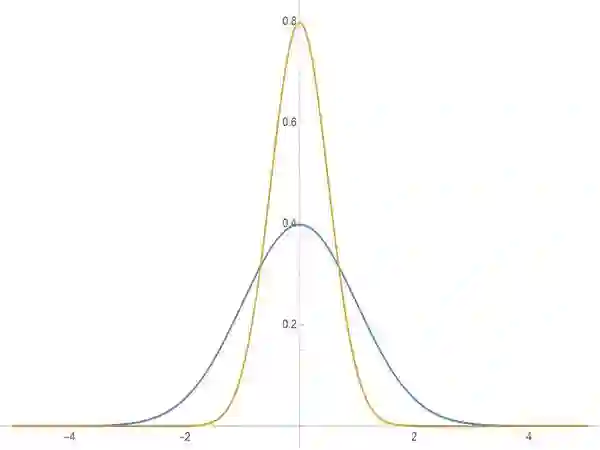
▲ 标准正态分布(蓝)和小方差正态分布(橙)
而对于后验分布 p(z|x) 中,我们假设了它也是一个正态分布。既然前面说 z 与 x 几乎是一一对应的,那么这个性质同样也适用验分布 p(z|x),这就表明后验分布也会是一个方差很小的正态分布(读者也可以自行从 mnist 的 encoder 结果来验证这一点),这也就意味着每次从 p(z|x) 中采样的结果几乎都是相同的。
既然如此,采样一次跟采样多次也就没有什么差别了,因为每次采样的结果都基本一样。所以我们就解释了为什么可以从 (3) 式出发,只采样一个点计算而变成 (4) 式或 (5) 式了。
后验之妙
前面我们初步解释了为什么直接在先验分布 q(z) 中采样训练不好,而在后验分布中 p(z|x) 中采样的话一个点就够了。
事实上,利用 KL 散度在隐变量模型中引入后验分布是一个非常神奇的招数。在这部分内容中,我们再整理一下相关内容,并且给出一个运用这个思想的新例子。
后验的先验
可能读者会有点逻辑混乱:你说 q(x|z) 和 p(z|x) 最终都是方差很小的正态分布,可那是最终的训练结果而已,在建模的时候,理论上我们不能事先知道 q(x|z) 和 p(z|x) 的方差有多大,那怎么就先去采样一个点了?
我觉得这也是我们对问题的先验认识。当我们决定用某个数据集 X 做 VAE 时,这个数据集本身就带了很强的约束。
比如 mnist 数据集具有 784 个像素,事实上它的独立维度远少于 784,最明显的,有些边缘像素一直都是 0,mnist 相对于所有 28*28 的图像来说,是一个非常小的子集.
再比如笔者前几天写的作诗机器人,“唐诗”这个语料集相对于一般的语句来说是一个非常小的子集;甚至我们拿上千个分类的 imagenet 数据集来看,它也是无穷尽的图像中的一个小子集而已。
这样一来,我们就想着这个数据集 X 是可以投影到一个低维空间(隐变量空间)中,然后让低维空间中的隐变量跟原来的 X 集一一对应。
读者或许看出来了:这不就是普通的自编码器吗?
是的,其实意思就是说,在普通的自编码器情况下,我们可以做到隐变量跟原数据集的一一对应(完全一一对应意味着 p(z|x) 和 q(x|z) 的方差为 0),那么再引入高斯形式的先验分布 q(z) 后,粗略地看,这只是对隐变量空间做了平移和缩放,所以方差也可以不大。
所以,我们应该是事先猜测出 p(z|x) 和 q(x|z) 的方差很小,并且让模型实现这个估计。说白了,“采样一个”这个操作,是我们对数据和模型的先验认识,是对后验分布的先验,并且我们通过这个先验认识来希望模型能靠近这个先验认识去。
整个思路应该是:
有了原始语料集
观察原始语料集,推测可以一一对应某个隐变量空间
通过采样一个的方式,让模型去学会这个对应
这部分内容说得有点凌乱,其实也有种多此一举的感觉,希望读者不要被我搞糊涂了。如果觉得混乱的话,忽视这部分吧。
耿直的IWAE
接下来的例子称为“重要性加权自编码器(Importance Weighted Autoencoders)”,简写为“IWAE”,它更加干脆、直接地体现出后验分布的妙用,它在某种程度上它还可以看成是 VAE 的升级版。
IWAE 的出发点是 (2) 式,它引入了后验分布对 (2) 式进行了改写:
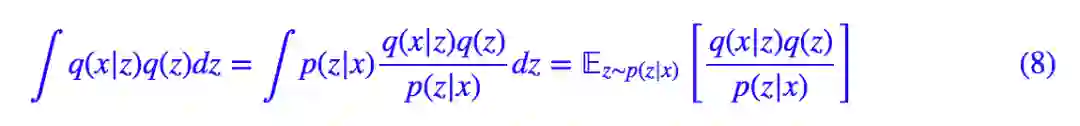
这样一来,问题由从 q(z) 采样变成了从 p(z|x) 中采样。我们前面已经论述了 p(z|x) 方差较小,因此采样几个点就够了:
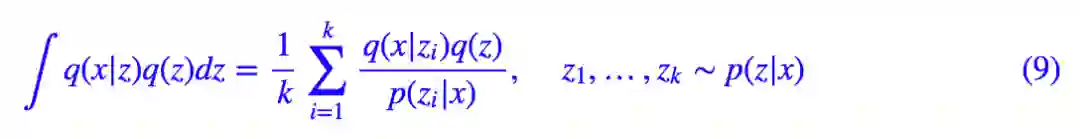
代入 (2) 式得到:
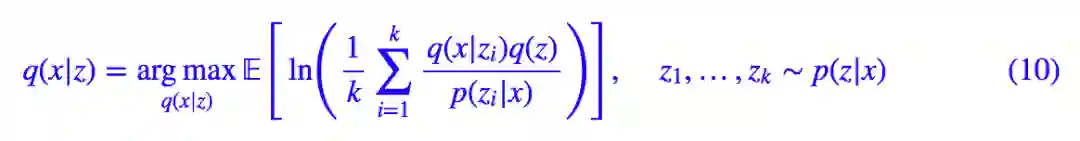
这就是 IWAE。为了对齐 (4),(5) 式,可以将它等价地写成:
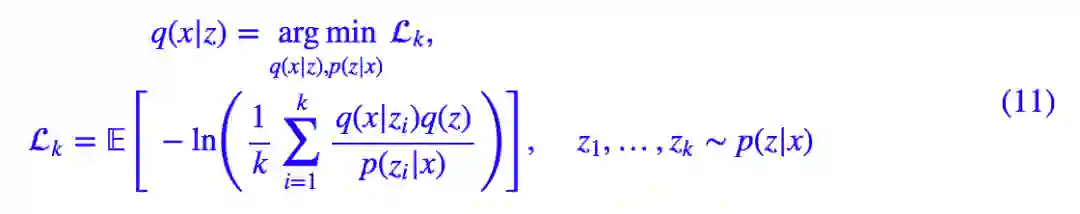
当 k=1 时,上式正好跟 (5) 式一样,所以从这个角度来看,IWAE 是 VAE 的升级版。
从构造过程来看,在 (8) 式中将 p(z|x) 替换为 z 的任意分布都是可以的,选择 p(z|x) 只是因为它有聚焦性,便于采样。而当 k 足够大时,事实上 p(z|x) 的具体形式已经不重要了。
这也就表明,在 IWAE 中削弱了 encoder 模型 p(z|x) 的作用,换来了生成模型 q(x|z) 的提升。
因为在 VAE 中,我们假设 p(z|x) 是正态分布,这只是一种容易算的近似,这个近似的合理性,同时也会影响生成模型 q(x|z) 的质量。可以证明,Lk能比 L 更接近下界 −𝔼x∼p(x)[lnp(x)],所以生成模型的质量会更优。
直觉来讲,就是在 IWAE 中,p(z|x) 的近似程度已经不是那么重要了,所以能得到更好的生成模型。
不过代价是生成模型的质量就降低了,这也是因为 p(z|x) 的重要性降低了,模型就不会太集中精力训练 p(z|x) 了。所以如果我们是希望获得好的 encoder 的话,IWAE 是不可取的。
还有一个工作 Tighter Variational Bounds are Not Necessarily Better,据说同时了提高了 encoder 和 decoder 的质量,不过我还没看懂。
重参之神
如果说后验分布的引入成功勾画了 VAE 的整个蓝图,那么重参数技巧就是那“画龙点睛”的“神来之笔”。
前面我们说,VAE 引入后验分布使得采样从宽松的标准正态分布 q(z) 转移到了紧凑的正态分布 p(z|x)。然而,尽管它们都是正态分布,但是含义却大不一样。我们先写出:
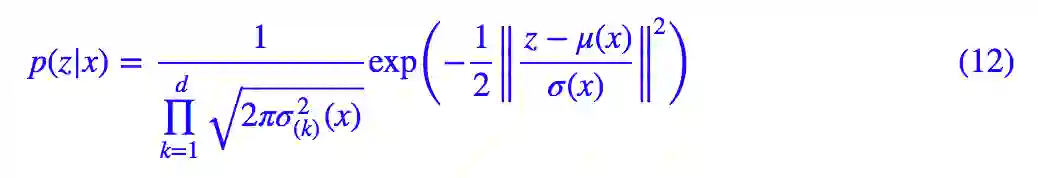
也就是说,p(z|x) 的均值和方差都是要训练的模型。
让我们想象一下,当模型跑到这一步,然后算出了 μ(x) 和 σ(x),接着呢,就可以构建正态分布然后采样了。
可采样出来的是什么东西?是一个向量,并且这个向量我们看不出它跟 μ(x) 和 σ(x) 的关系,所以相当于一个常向量,这个向量一求导就没了,从而在梯度下降中,我们无法得到任何反馈来更新 μ(x) 和 σ(x)。
这时候重参数技巧就闪亮登场了,它直截了当地告诉我们:
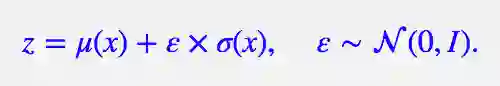
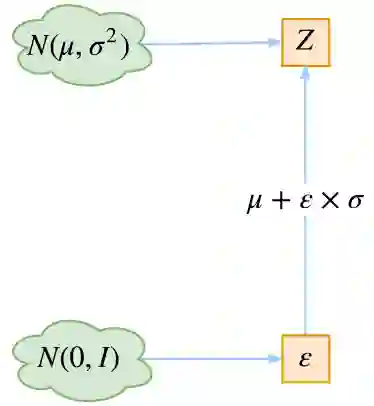
▲ 重参数技巧
没有比这更简洁了,看起来只是一个微小的变换,但它明确地告诉了我们 z 跟 μ(x) 和 σ(x) 的关系。于是 z 求导就不再是 0,μ(x), σ(x) 终于可以获得属于它们的反馈了。至此,模型一切就绪,接下来就是写代码的时间了。
可见,“重参数”简直堪称绝杀。
本文之水
本文大概是希望把 VAE 后续的一些小细节说清楚,特别是 VAE 如何通过巧妙地引入后验分布来解决采样难题(从而解决了训练难题),并且顺道介绍了一下 IWAE。
要求直观理解就难免会失去一点严谨性,这是二者不可兼得的事情。所以,对于文章中的毛病,望高手读者多多海涵,也欢迎批评建议。

点击以下标题查看相关内容:


我是彩蛋
解锁新功能:热门职位推荐!
PaperWeekly小程序升级啦
今日arXiv√猜你喜欢√热门职位√
找全职找实习都不是问题
解锁方式
1. 识别下方二维码打开小程序
2. 用PaperWeekly社区账号进行登陆
3. 登陆后即可解锁所有功能
职位发布
请添加小助手微信(pwbot02)进行咨询
长按识别二维码,使用小程序
*点击阅读原文即可注册

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 进入作者博客



