李飞飞等提出新的迭代视觉推理框架,在ADE上实现8.4 %的绝对提升

译者 | 梁红丽 张蔚敏
编辑 | 明 明
来源 | AI科技大本营(公众号ID:rgznai100)
【AI科技大本营导读】近日,陈鑫磊、李佳、李飞飞、Abhinav Gupta等人提出了一种新的迭代视觉推理框架。
该框架超越了目前缺乏推理能力的识别系统。该框架包括两个核心模块:一个局部模块,用空间记忆来存储之前并行更新的认知;一个全局的图推理模块。相比普通的卷积网络( ConvNets ),新的模型性能表现更优越,各类的平均精度在 ADE 上有 8.4% 的绝对提升,在 COCO 上实现了 3.7 % 的绝对提升。分析还表明,该推理框架对当前区域分割方法造成的区域缺失具有很强的适应性。
以下内容来自 Iterative Visual Reasoning Beyond Convolutions 论文,AI 科技大本营翻译:

这篇文章中,我们提出了一个可以同时用于空间和语义推理的生成框架。与现在只依赖于卷积的方法不同,我们的框架可以从以知识库为形式的结构化信息中学习,进行视觉识别。我们的核心算法包含两个模块:局部模块,基于空间记忆,用 ConvNets 做像素级推理。通过并行记忆更新,我们的执行效率得到很大提高。
此外,我们引入了全局模块进行局域外的推理。在全局模块中,推理是基于图模型展开的。它有三个组成部分:
a)一个知识图谱,我们把类当做结点,建立边来对它们之间不同类型的语义关系进行编码;
b)一个当前图像的区域图,图中的区域是结点,区域间的空间关系是边;c)一个工作分配图,将区域分配给类别。利用这种结构的优势,我们开发了一个推理模型,专门用于在图中传递信息。局部模块和全局模块迭代工作,交叉互递预测结果来调整预期。
需要注意的是,局部模块和全局模块不是分离的,对图像的深刻理解通常是先验的背景知识和对图像的具体观察间的折中。因此,我们用注意力机制联合两个模块,使模型在做最终预测时使用相关性最大的特征。
我们的框架比普通的 ConvNets 表现更好。例如,框架在 ADE 测试得到的各类平均精度有 8.4% 的绝对提升,而加深网络却只能提高 1%。
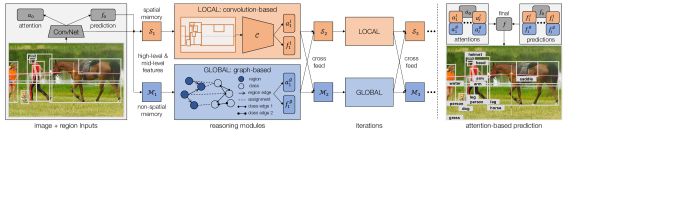
图2:推理框架概览。除做预测的普通ConvNets外,框架有两个模块进行推理:一个局部模块(Sec. 3.1),用空间记忆Si,并用另一个ConvNet C推理;一个全局模块(Sec. 3.2),将区域和类作为图中的结点,通过传递结点间信息进行推理。两个模块接收高层和中层的整合信息,交叉互递认知来迭代地工作。最后的预测通过注意力机制整合所有预测结果来生成。
▌Reasoning Framework(推理框架)
在这部分,我们建立推理框架。除 ConvNet 的普通预测 p0 外,它由两个模块通过推理做预测。第一个是局部模块,用空间记忆存储先前并行更新的认知,仍属于以卷积为基础的推理(Sec. 3.1)。
除卷积之外,我们的关键部分是作为图中结点直接在区域和类别间推理的全局模块(Sec. 3.2)。两个模块都通过迭代展开估计(Sec. 3.3),认知在模块间交叉互递。最后我们取两模块之长,用注意力机制从所有迭代中整合预测结果(Sec. 3.4),用聚焦于硬示例(图2)的样本重新加权来训练模型(Sec. 3.5)。
3.1 Reasoning with Convolutions(用卷积进行推理)
我们第一个建立的区块——局部模块,由文章启发。在较高层面来看,这一想法是用空间记忆S来存储检测到的目标物,存储地点就在目标物被检测到时所在的位置。S是三维张量,高度H和宽度W为图像缩减后的尺寸(1/16),深度D(=512)将记忆的每个单元c作为向量,存储当前位置可能有用的信息。
S通过高层和中层特征来更新,高层存储有关估计的类别标签信息。但是,只知道类别并不理想,更多关于形状、姿态等的细节信息在其他物体检测时大有用处。例如,预先知道一个“人”打网球的姿势,会对识别“网球拍”大有帮助。本文中,我们在softmax激活前用logits f,结合底部卷积层h的特征图来补给记忆。
给定一个待更新的图像区域r,我们要先从底层提取相应特征,用双线性插值将其调整为预定大小(7*7)的方阵h。因为高层特征f是覆盖整个区域的向量,所以我们将其附加在所有位置(49个)。用两个1*1的卷积核来提取特征并为r生成输入特征fr。记忆S中的相同区域也提取出来,调整为7*7,标注为sr。这一步后,我们用卷积门递归单元(GRU)来写出记忆:
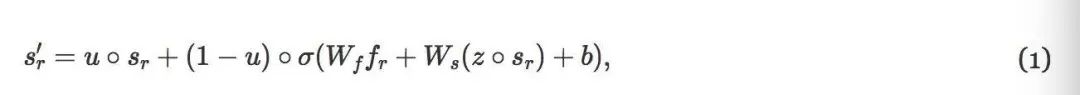
其中,s′r 是 r 更新后的记忆,u 是更新后的门,z 是重置门,Wf,Ws 和 b 分别是卷积的权重和偏置,○ 是 entry-wise 矩阵内积,σ(⋅) 为激活函数。更新后,s′r 通过再提取和尺寸调整放回到S。
前期的研究工作将序列更新到记忆。但是,序列推断低效且 GPU 密集,这限制其每张图像只能有 10 个输出。本文提出用并行更新区域作为近似。在交叠情况下,一个单元可以由不同区域覆盖多次。将区域放回至S时,我们也计算权值矩阵 Γ ,矩阵中,对于每一个入口 yr,c∈[0,1] 记录了区域 r 对记忆单元 c 的贡献率:1 表示单元被区域完全覆盖,0 表示没有覆盖。更新后的单元的终值是所以区域的加权平均。
实际的推理模块为一个ConvNet C,由三个 3*3 的卷积核和两个 4096D 的全连接层组成,以 S 为输入,在接受域的局地窗间建立连接关系来进行预测。因为图像的二维结构和位置信息保存在 S 中,所以,这样的结构对于空间推理关系非常有用。
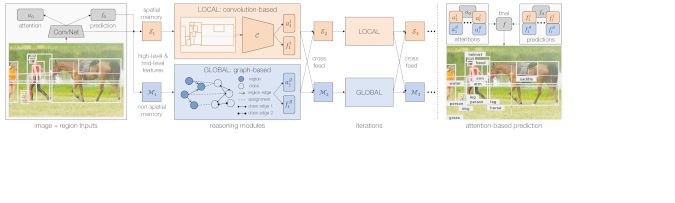
图3:用多种边在图中直接传递信息的图解。这里,四个结点连接两个类型的边,每个结点表示一个输入特征向量mi(集合为M)。权值矩阵Wj学习为边类型j来转换输入量。之后连接矩阵Aj用来向关联结点传递信息。最后,通过累计所有的边类型并使用激活函数生成输出G。
3.2 Beyond Convolutions(卷积之外)
我们的第二个模块采用的是对全局推理进行卷积操作而不是针对局部区域进行的。这里的“global”全局有两个含义。首先从空间角度来讲,我们希望让更远的区域也可以彼此直接进行信息交流,而不受推理模块C的接受域的限制。其次从语义层面来说,我们希望可以充分的利用视觉知识库,它可以提供跨图像的全局真实的类间关系( 比如常识类信息 )。为了实现以上两个层面的推理,我们构造了一个图G = ( N,E ),其中N和E分别为节点集和边集。在N中定义了两种类型的节点: R区域的区域节点N,和C类的类节点Nc。
对于E,在节点之间定义三组边。首先,对于Nr来说,我们使用空间图来编码区域( Er→r )之间的空间关系。设计多种类型的边来表征相对位置。我们从诸如“左/右”、“上/下”之类的基本关系开始,并且通过测量两者之间的像素级距离来定义边缘权重。需要说明的是,我们并不是直接使用原始距离x,而是使用核κ( x ) = exp ( - x /δ)(其中δ= 50代表带宽)将其归一化为[ 0,1 ],这样可以使得越接近的区域相关程度越高。然后直接在图的邻接矩阵中使用边缘权重。此外,为了能够有效的解决区域重叠时的分类问题,我们也把用于编码覆盖模式的边( 例如IoU intersection over union, )包含在了其中。
第二组边是位于区域和类之间的集合,即决定一个区域是否属于某一类。这些边缘的作用是,将信息从一个区域传播到另一个类别( er→c )或从一个类别反向传播到另一个区域( EC→r )。我们采用soft-max值p来定义连接到所有类别的边缘权重,而不是仅仅计算连接到可能性最高的那一类。这样做是希望它能提供更多的信息,并且提高对错误分类的鲁棒性。
第三组边是使用知识库中的语义关系构造类间( Ec→c )关系的集合。同样,这里可以包括多种类型的边。经典的例子有“is-kind-of”( 例如 “蛋糕”和“食物”)、“is-part-of”(例如“车轮”和“汽车”)、“相似性”( 例如“豹”和“猎豹”),其中许多都是普遍正确的,因此可以被认为是常识。这种常识可以是人工列出的或自动收集的。
有趣的是,即使是这些以外的关系(例如“行为”,“介词”)也可以帮助识别。以“人骑自行车”为例,这显然是一种更加具体形象的关系。然而,由于对“人”和“自行车”这两类的识别准确度不够高,那么从两者之间的“骑行”的关系以及他们的空间位置出发,则可以帮助我们对这一区域进行更好的推理。为了研究这两种情况,我们在本文中尝试了两种知识图谱:一种是内部创建的,大部分是常识边,另一种则是大规模积累的更多类型的关系。有关我们实验中所使用的图,请参阅4.1,那里会对这一部分工作进行更详情的介绍。
接下来,我们来看一下基于图的推理模块r。作为图的输入,我们使用Mr∈RR×D来表示来自所有区域节点Nr组合的特征,其中D ( = 512 )是特征信道的数目。为了方便表示,对于每个类节点NC,我们选择现成的字向量作为表示,记为Mc∈RC×d。然后我们对文献[ 42,35 ]的工作进行了扩展,并直接在G上传递消息(见图3 )。
需要注意的是,因为我们的最终目标是为了能够更好地识别区域,所以所有的类节点都只是中间表示,为的是能够更好地表示区域。基于此,我们设计了两种推理路径来学习输出特征Gr :仅包含区域节点的空间路径:

其中Ae∈Rr×r是边缘类型e的邻接矩阵,We∈rd×d是权重(为了简单起见,忽略了偏置)。第二个推理路径是通过类节点的语义路径:
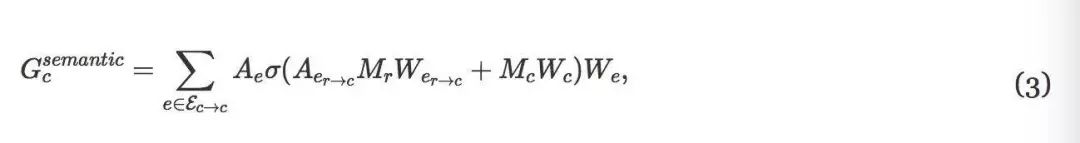
在这里,我们首先通过Aer→c和Wer→c将区域映射到类,将中间特征与类特征Mc相结合,然后在类之间聚集来自多种类型边缘的特征。最后,通过合并这两条路径来计算区域Gr的输出:
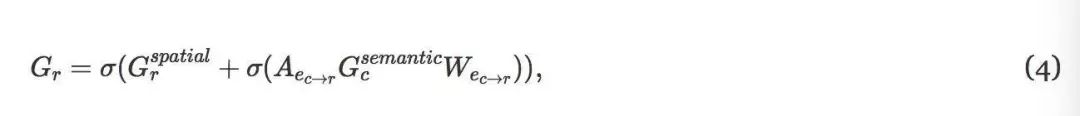
其首先将语义信息传播回区域,然后使用非线性激活(参见图4 )。
与卷积滤波器一样,上述路径也可以堆叠,其中可以经过另一组图形操作输出Gr,从而允许框架执行具有更深特征的联合空间语义推理。在输出被反馈用以进行预测之前,我们在R中使用了具有残差连接的三个操作栈。
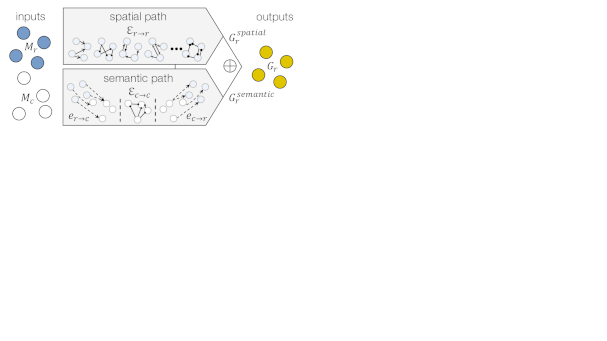
图4:在我们的全局推理模块r中使用的两个推理路径。以区域和类输入Mr和Mc为例,空间路径直接传递具有区域到区域边缘 Er→r 的区域图中的信息,而语义路径首先将区域分配给具有 Er→c 的类,然后将信息传递给具有类到类边缘Ec→c 的其他类,然后传播回来。组合最终输出以生成输出区域特征 Gr
3.3 Iterative Reasoning(迭代推理)
推理的一个关键要素是迭代地建立估计。但是信息是如何从一个迭代传递到另一个迭代的呢?我们的答案是显式内存,它存储之前迭代的所有历史记录。本地模块使用空间存储器S,全局模块使用另一无空间结构的存储器M。对于第i次迭代,Si之后是卷积推理模块C,以生成每个区域的新预测fli。类似地,全局模块还给出来自R的新预测fgi。这些作为高级特征的新的预测可以用于对存储器Si + 1和Mi + 1进行更新。新的记忆将带来fi + 1轮更新,以此类推。
虽然可以单独进行局部和全局推理,但这两个模块协同工作时的效果是最好。因此,我们希望在生成预测时加入两个模块的结果。为此,我们引入了cross-feed 连接。在完成推理后,将局部特征和全局特征连接在一起,利用GRU更新Si + 1和Mi + 1两个存储单元,这样,可是使空间存储单元能够从空间和语义关系的全局知识中受益,并且图能够更好地理解局部区域的布局。
3.4 Attention(注意力机制)
受到文献attention模型的启发,我们对模型输出进行了一次修改。具体来说,模型必须产生“attention”值来表示,当前预测与来自其它迭代或模块的预测的相对置信度,而不是仅仅是产生分数f。从而融合输出是使用“attention”的所有预测的加权版本。在数学上,如果模型展开I次,并且输出N = 2I + 1 (包括I个局部、I个全局和1个普通的ConvNet网络)预测fn,使用注意(attention)an,则最终输出f计算为:
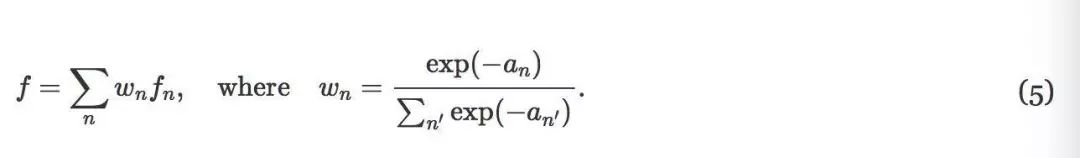
需要注意的是,这里fn是soft-max之前的logits,被激活以后产生pn。
“attention”的引入使模型能够智能地从不同的模块和迭代中选择最可行的预测。
3.5 Training(训练)
最后,对整个框架进行端到端的训练,总损失函数包括:
a )普通ConvNet损失L0;
b )本地模块损耗Lli;
c )全局模块损耗Lgi;
d ) 包含注意(attention)的最终预测损失Lf。
由于我们希望推理模块更多地关注较难的示例,因此我们建议根据以前迭代的预测,简单地对损失中的示例进行重新加权。具体的,对于迭代I≥1时的区域r,两个模块的交叉熵损失计算为:
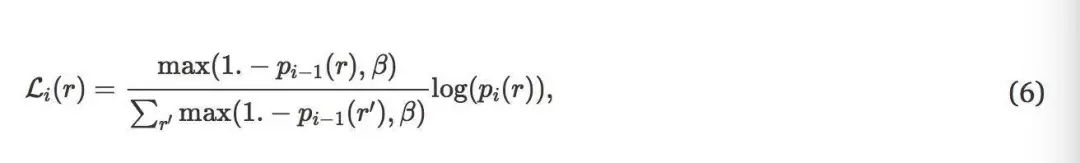
其中pi ( r )是ground-truth类的soft-max输出,β∈[ 0,1 ]控制权重分布的熵:当β= 1时,它是均匀分布;当β= 0时,熵最小。在我们的实验中,β设定为0.5。P1 ( r )用作没有反向传播的特征。对于本地和全局来讲,P0 ( r )是来自普通卷积神经网络(ConvNet)的输出。
▌总结
我们提出了一种新的迭代视觉推理框架。 除了卷积之外,它还使用图来编码区域和类之间的空间和语义关系,并在图上传递消息。与普通ConvNets相比,我们的性能表现更加优越,在ADE上实现了8.4 %的绝对提升,在COCO上实现了3.7 %的绝对提升。分析还表明,我们的推理框架对当前区域分割方法造成的区域缺失具有很强的适应性。
论文链接:https://arxiv.org/abs/1803.11189
扫描二维码,关注「人工智能头条」
回复“技术路线图”获取 AI 技术人才成长路线图

☟☟☟点击 | 阅读原文 | 查看更多精彩内容
