干货 | 百度视觉团队斩获 ECCV Google AI 目标检测竞赛冠军,获奖方案全解读 | ECCV 2018

AI 科技评论消息,近日,百度视觉团队在 Google AI Open Images-Object Detection Track 目标检测任务中斩获第一,并受邀在计算机视觉顶级学术会议 ECCV 2018 上进行分享。比赛获奖在雷锋网旗下学术频道 AI 科技评论数据库产品「AI 影响因子」有相应加分。

Google AI Open Images-Object Detection Track 由 Google AI Research 举办,今年共吸引全球 450 多支队伍参赛。
大赛采用 Google 今年 5 月份发布的 Open Images V4 数据集作为训练数据集,包含超过 170 万的图片数据,500 个类别以及超过 1200 万物体框,数据没有完全精细标注,属于弱监督任务,框选类别数目不均衡且有非常广泛的类别分布,这更符合实际情况,也意味着参加竞赛的团队需要考虑到类别的分布,而不能统一对所有类别做处理,因此更具挑战性。
这项赛事有助于复杂模型的研究,同时对评估不同检测模型的性能有积极的促进作用。下图为 Open Image V4 与 MS COCO 和 ImageNet 检测任务数据对比情况,可以看到 Open Image V4 数据规模远远大于 MS COCO 和 ImageNet。
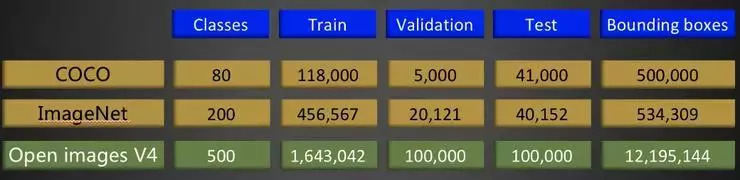
Open Image V4 与 MS COCO及ImageNet 检测数据对比情况
以下为百度视觉团队技术方案解读:
存在挑战
与传统的检测数据集合相比,该赛事除了数据规模大、更真实之外,还存在一系列的挑战。具体来说,主要集中在以下三个方面:
数据分布不均衡:最少的类别框选只有 14 个,而最多的类别框选超过了 140w,数据分布严重不均衡。

类别框数量分布
漏标框:很多图片存在只标注主体类别,其他小物体或者非目标物体没有标注出来。

漏标注图片举例
尺度变化大:大部分物体框只占整个图片的 0.1 以下,而有些框选却占了整个图片区域。如图所示,Open Image V4 集合存在更多的小物体,参赛者也会在检测数据中遇到更大的挑战。
框尺度大小分布对比
解决方案
在比赛过程中,百度视觉团队采用了不同复杂度、不同框架网络进行模型的训练,并对这些模型进行融合。从整体方案框架来看,可分为 Fast R-CNN 和 Faster R-CNN 两种不同的训练模式。Fast R-CNN 版本是百度视觉团队研发的一套 PaddlePaddle 版本,在此基础上 Faster R-CNN 加入了 FPN、Deformable、Cascade 等最新的检测算法,模型性能实现了大幅度的提升。
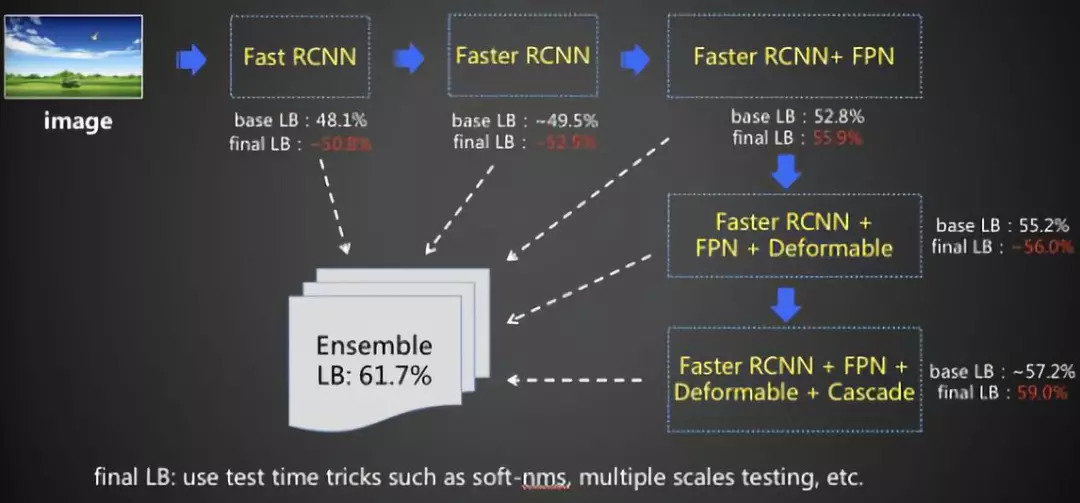
整体方案框架流程图
网络为 ResNet-101 的 Fast R-CNN,模型收敛后可以达到 0.481,在测试阶段加入 Soft NMS 以及 Multi-Scale Testing 策略,可以达到 0.508。百度也尝试了其他网络(dpn98,Inception-v4,Se-ResNext101),并把不同网络的检测算法融合到一起,最终 mAP 可以达到 0.546。在 Proposal 采样阶段,百度在不同位置进行不同尺度的候选框生成,然后对这些框选进行分类以及调整他们的位置。
Faster R-CNN: 采用这种框架可以达到略高于 Fast R-CNN 的效果,mAP 为 0.495。在测试阶段使用 Soft NMS 以及 Multi-Scale Testing 策略后,性能达到 0.525。
Deformable Convolutional Networks:使用 Soft NMS 以及 Multi-Scale Testing 策略前后,性能分别达到 0.528 及 0.559。
Deformable Cascade R-CNN : 使用 Soft NMS 以及 Multi-Scale Testing 策略前后,性能分别可以达到 0.581 和 0.590.
在 Fast R-CNN 框架下,百度视觉团队采用了不同的网络进行训练,而在 Faster R-CNN 框架下只使用了 ResNet101 这种网络进行训练。在训练过程中,百度视觉团队还通过不同的策略有效解决了各种技术问题。详情如下:
动态采样
Google Open Images V4 数据集大概有 170w 图片,1220w 框选,500 个类别信息。最大的类别框选超过了 140w,最小的类别只有 14 个框选,如果简单使用所有的图片及框选,需要几十天才能进行模型训练,而且很难训练出来一个无偏的模型。因此,需要在训练过程中进行动态采样,如果样本数量多则减少采样概率,而样本数量少则增加采样概率。百度视觉团队分别进行全集数据训练、固定框选子集训练、动态采样模型训练三种策略进行。
全集数据训练:按照主办方提供数据进行训练,mAP 达到 0.50。
固定框选子集训练:线下固定对每个类别最多选择 1000 个框,mAP 达到 0.53。
动态采样模型训练:对每个 GPU、每个 Epoch 采用线上动态采样,每次采集的数据都不同,轮数达到一定数目后,整个全集的数据都能参与整体训练。最后 mAp 达到 0.56。

动态采样策略
FPN
基于训练数据集的分析,百度视觉团队发现其中 500 个类别的尺度有很大的差异。因此他们将 FPN 引入到检测模型中,即利用多尺度多层次金字塔结构构建特征金字塔网络。在实验中,百度视觉团队以 ResNet101 作为骨干网络,在不同阶段的最后一层添加了自顶向下的侧连接。自顶向下的过程是向上采样进行的,水平连接是将上采样的结果与自底向上生成的相同大小的 feature map 合并。融合后,对每个融合结果进行 3*3 卷积以消除上采样的混叠效应。值得注意的是,FPN 应该嵌入到 RPN 网络中,以生成不同的尺度特征并整合为 RPN 网络的输入。最终,引入 FPN 后的 mAP 可达到 0.528。
Deformable Convolution Networks
百度视觉团队采用可变形卷积神经网络增强了 CNNs 的建模能力。可变形卷积网络的思想是在不需要额外监督的情况下,通过对目标任务的学习,在空间采样点上增加额外的偏移量模块。同时将可变形卷积网络应用于以 ResNet101 作为骨架网络的 Faster R-CNN 架构,并在 ResNet101 的 res5a、5b、5c 层之后应用可变形卷积层,并将 ROI Pooling 层改进为可变形位置敏感 ROI Pooling 层。可变形卷积网络的 mAP 性能为 0.552。
Cascade R-CNN
比赛中,百度视觉团队使用级联的 R-CNN 来训练检测模型。除训练基本模型外,还使用包含五个尺度特征金字塔网络(FPN)和 3 个尺度 anchors 的 RPN 网络。此外,他们还训练了一个针对全类模型中表现最差的150类的小类模型,并对这 150 类的模型分别进行评估。得出的结论是,500 类模型的 mAP 为 0.477,而用 150 类单模型训练结果替换 500 类的后 150 类的结果,模型的 mAP 提升为 0.498。使用以上方法进行训练的单尺度模型的性能为 0.573。
Testing Tricks
在后处理阶段,百度视觉团队使用了 Soft NMS 和多尺度测试的方法。用 Soft NMS 的方法代替 NMS 后,在不同模型上有 0.5-1.3 点的改进,而 Multi-Scale Testing 在不同模型上则有 0.6-2 个点的提升。
模型融合
对于每个模型,百度视觉团队在 NMS 后预测边界框。来自不同模型的预测框则使用一个改进版的 NMS 进行合并,具体如下:
给每个模型一个 0~1 之间的标量权重。所有的权重总和为 1;
从每个模型得到边界框的置信分数乘以它对应的权重;
合并从所有模型得到的预测框并使用 NMS,除此之外百度采用不同模型的分数叠加的方式代替只保留最高分模型,在这个步骤中 IOU 阈值为 0.5。

(完)






