AutoML-Zero: 从头开始的机器学习算法进化

兴趣所致,关注了一些AutoML的知识,主要是AutoML中的网络结构搜索的部分,特记录下来希望能形成体系。以下是要写的文章列表。
-
强化学习与网络结构搜索(一) -
强化学习与网络结构搜索(二) -
强化学习与网络结构搜索(三) -
遗传算法与网络结构搜索 -
Darts可微结构搜索 -
ENAS:基于参数共享的网络结构搜索 -
AutoML-Zero: 从头开始的机器学习进化(本篇) -
更多待续
Overall
在前面,我们介绍了很多种AutoML方法,它们都有一个共性,那就是它们的搜索空间是基于已有的经验去设计的,里面的模块都是经过验证的行之有效的方法。因而,这样做虽然能达到较好的效果,但是却有如下缺点:
-
过度依赖人为设计的组件使得搜索的结果有偏差,降低了AutoML的创造能力。 -
受限的搜索空间需要精心调制,增大了研究者的负担,没有真正达到AutoML的效果。
为了解决这个问题,AutoML-Zero应运而生,其目的在于用尽可能少的人为参与来进行更加完全的AutoML。换句话说,相对于其他已经介绍的算法来说,AutoML-zero可以在更少人工参与条件下,可以去搜索整个算法(模型结构,初始化,优化方法等),甚至允许发现非神经网络的算法。
为了达成上述目标,在搜索空间上,只能采用一些比较基础的数学操作,搜索空间也将会比原来的方法要大得多。因而,使用Random Search已经无法在这个搜索问题上找到合理的答案。而使用遗传算法与网络结构搜索中的进化方法能达到不错的效果。
这点跟之前的几篇文章不同,在之前的文章中,由于Search Space是精心调制的,使用RS往往也能达到不错的效果,使用更高级的方法只是更快更好。
实验表明,AutoML-Zero能够发现梯度下降、multiplicative interactions,梯度归一化,权重平均,dropout, 学习率衰减等神经网络中的基础操作,是行之有效的方法。
当然,AutoML-zero这篇论文所解决的问题比较简单,也没有在什么流行的数据集上获得SOTA的效果,但我感觉,这是一种趋势,在之前读AutoML相关论文的时候,觉得这些方法根本无法替代炼丹师,而这篇,让我看到了完全替代的希望。
需要解决的任务
给定一个任务集合T,AutoML-zero算法将会在它的一个子集TSearch上进行模型的搜索,在搜索完成之后,在另一个子集TSelect上进行模型的评估。
更具体的,任务集合T是由在Cifar10的十类数据中随机抽取两类做二分类的子任务组成的,一共十类,所有有45种两类的组合。cifar10的图像都是32x32x3=3072维的,比较大,为了进一步简化任务,使用随机矩阵对这个维度降维,降维到8<=F<=256。对每个两类组合,生成100个随机转换的任务,这样,一共就是4500个任务。
当然,在找到最佳算法后,还会在未转换的数据上进行验证。为了证明算法不是只针对cifar10的,除了cifar10外,还有在其他数据集例如SVNH、ImageNet、Fashion MNIST上进行进一步的验证。
搜索空间
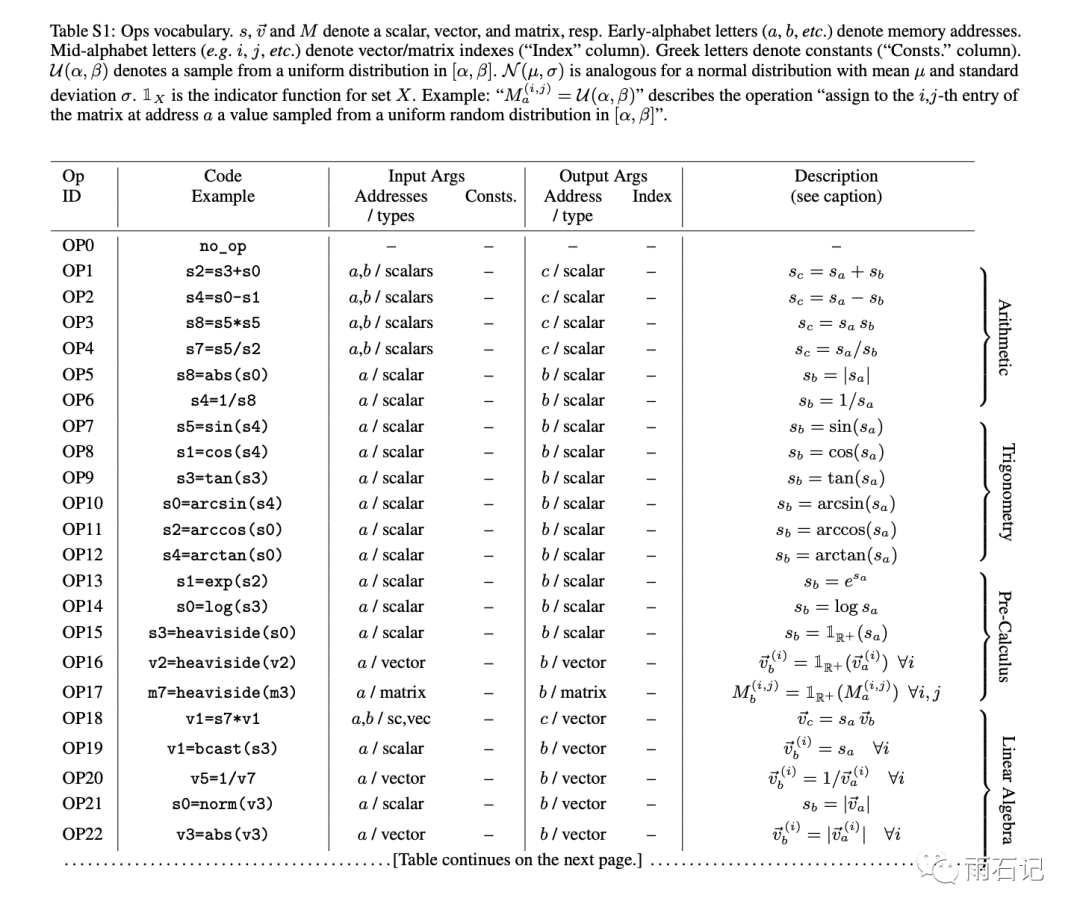
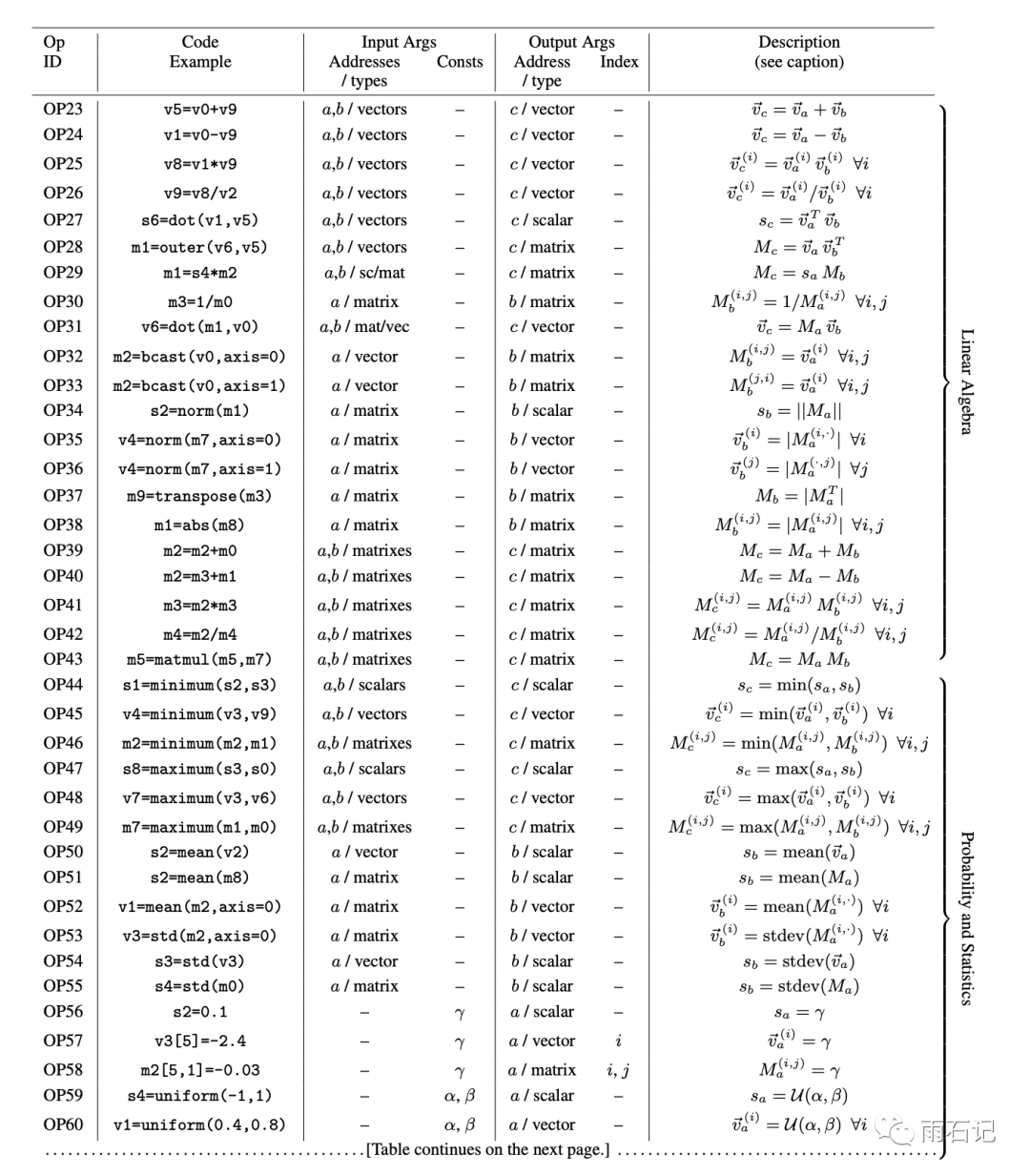
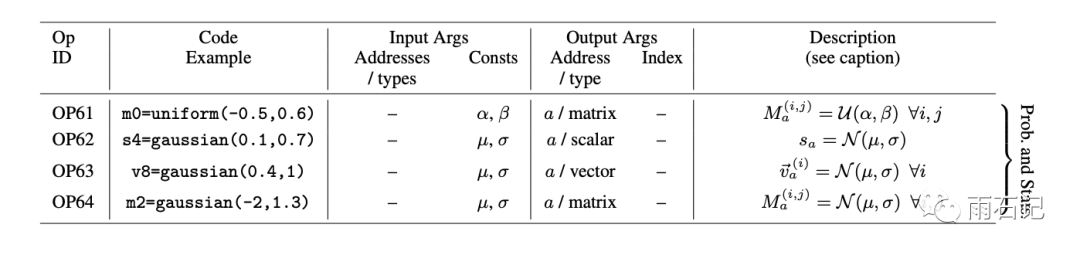
在AutoML-zero中,把算法表达成了计算机程序,在一块存储着多个变量(例如,s1, v1, m1分别代表1个scalar,1个vector,1个矩阵)的虚拟内存上进行各种操作。
这里为了简化,操作只用高中学过的op。
一些操作的例子如下:
-
读取s1处的常量和v1处的向量 -
将它们相乘 -
得到的结果写入v2
允许的操作有65个,如下图(就是个列表,大概看下不用细看)
受监督学习的启发,将算法表达为三个部分,称之为component function: Setup, Predict, Learn, 一个例子如下图所示:

其中Learn阶段可以看到Label,Predict阶段看不到,搜索开始时,会将数据放在v0,label放在s0内存上。这三个阶段都需要搜索。
整个算法流程如下,看起来很直接,就是监督学习的流程,先训练,在验证。在验证的时候,得到predict的结果后,会执行一个Normalize操作来获得概率,这里是一个预先定义好的操作: sigmoid或者softmax。内存会在三个阶段上共享和持续化。在D个任务上的结果的均值会被当做搜索到的算法的能力。

搜索算法
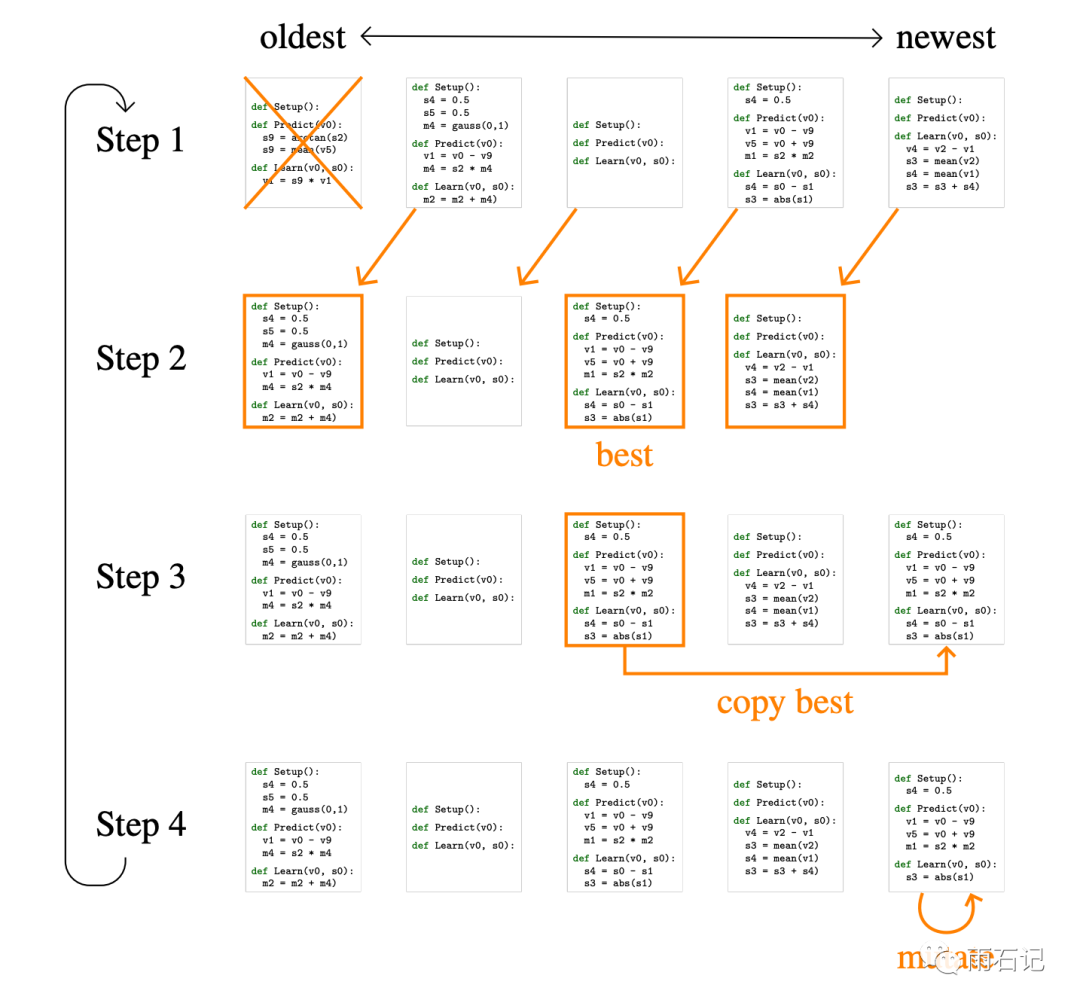
使用age正则化的遗传算法进行搜索。如下图,维护一个population的方法:
-
最老的结果被删除,得到T个结果 -
从T个结果中随机选择P个,在P个结果中找到最好的 -
进行变异 -
得到新的集合。以此类推。
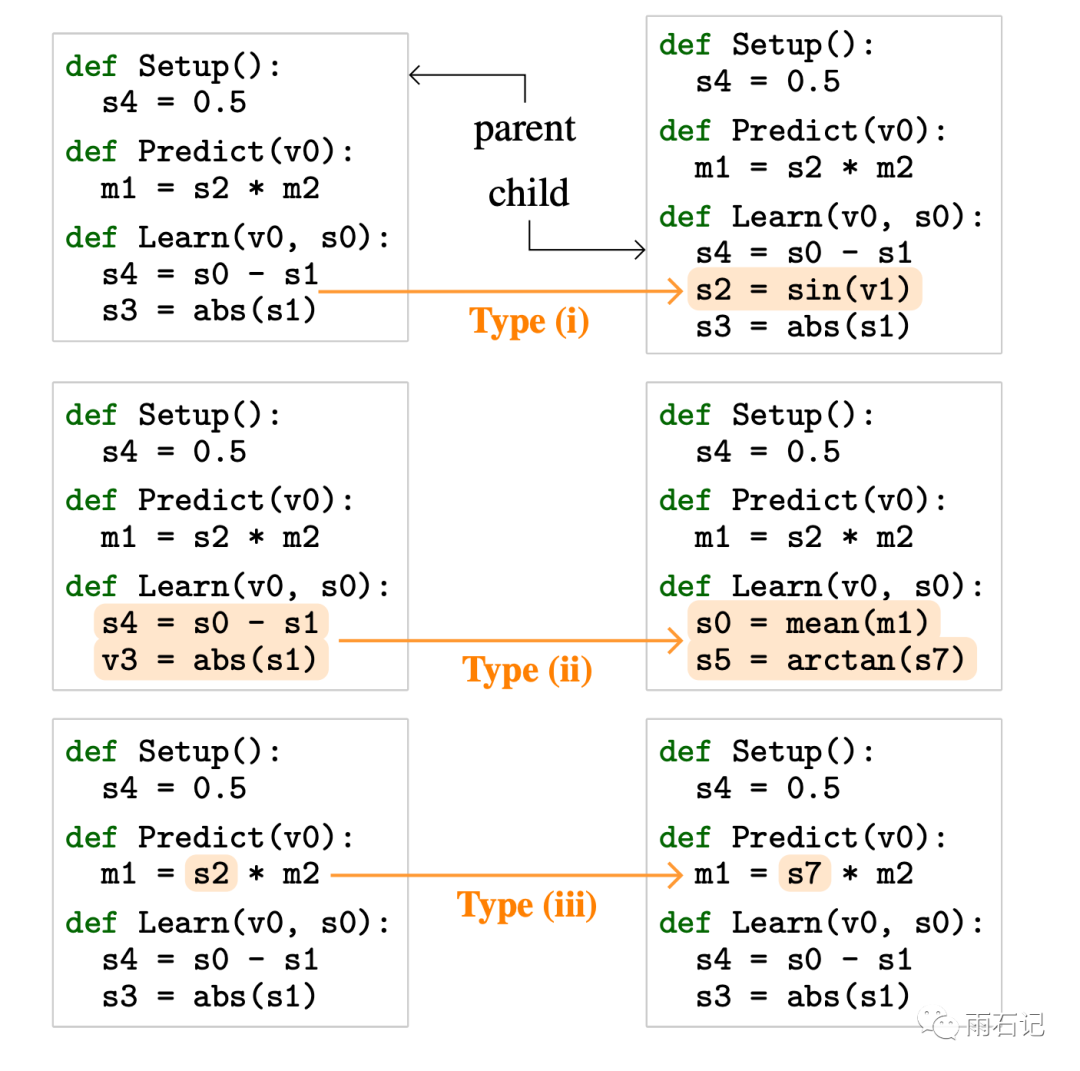
其中变异的方法有如下几种,如下图:
-
i. 在一个component function里的一个随机位置上,插入一个或者删除一个操作。 -
ii. 随机化一个component里的所有指令 -
iii. 改变一个指令的参数。
为了进行搜索算法的加速,采用了如下几种手段:
-
引入了一种效能等价检查的机制,即functional equivalence checking,这种方法可以检测出等价的算法,从而不用做多余的训练和验证。检测的方法则如下:
-
将一个算法训练10次,然后在一个固定的验证集上运行10步,得到的预测值去做哈希,然后存储下来,后面的算法如果哈希值相同,则认为是相同的算法,那么则使用内存中的评估结果。 -
注意,尽管两个算法可能结果相同,但并不丢弃某个,因为它们的变异结果可能不同。 -
这个方法加速4倍
-
跟之前的遗传算法类似,添加Hurdles,带来5倍加速 -
分布式,每个节点单独搜索,在一定步数后,将结果聚合,然后再选择最好的一些分发下去,各个节点再单独开始搜索。 -
为了提高结果,除了cifar10外,还引入了MNIST任务,这样可以提高在最后的模型在cifar10上的效果。
实验结果
先从简单的任务开始,来证明遗传算法比随机搜索算法的优势。
第一个任务:回归任务,固定一个向量u和实数a,随机生成8维向量x,然后用函数L(x) = ux + a得到向量x对应的值。当a=0的时候,就是线性问题,a不等于0的时候,就是仿射问题。评估则使用平方差函数。
为了进一步简化问题,减少了指令的数目;并且控制指令代码的长度。比如,因为线性回归的梯度下降只需要四个指令,所以把指令集控制在四个。又比如,插入、删除指令是不允许的,因为这样会改变长度。
为了衡量不同的搜索算法,采用了一个指标: 那就是经过多少次搜索能找到高于一个阈值的算法。比如,对线性回归这个case,用基于梯度下降的回归算法来做baseline,超过这个算法的模型可以认为是一个成功的算法。那么用Random Search需要搜索10^7个算法才可以。而使用遗传算法则是RS算法的5倍。
从下图可以看出,问题越难,遗传算法相对于RS的优势越大。下图中的纵坐标是遗传算法成功率和随机算法成功率的比值。
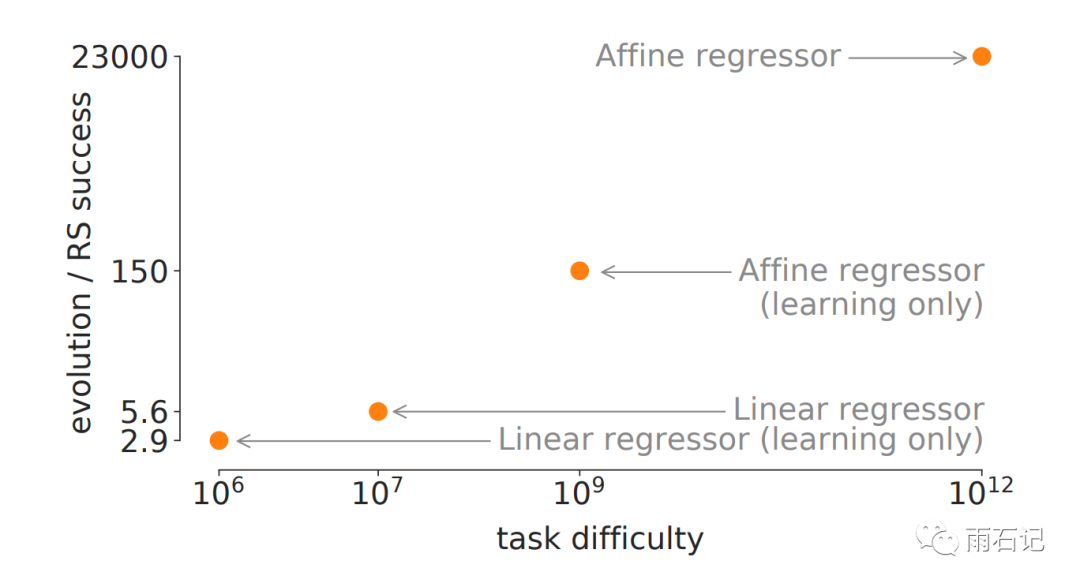
当我们把问题扩展到非线性时,使用RS已经无法发现成功的算法了。比如下面这个任务。
对上一个任务进行修改:
将L函数由线性变换变成非线性变化L(x)=u x Relu(Mx), M是一个随机的8x8矩阵,u是一个随机向量。Search space的改动则是将2层全连接网络所需要的操作也加入进来。
在这个任务上,RS已经不能找到好算法了。但是遗传算法还可以。当TSearch中只有一个任务时,遗传算法会找到M矩阵和u向量的具体的值。而当TSearch有多个任务时,比如100个任务,每个任务有不同的M和u的值,此时,遗传搜索就不能只找具体值了,此时,令人颇感震惊的事情发生了,遗传搜索得到了梯度下降算法。如下:
接下来正主任务上场,就是我们在上面的需要解决的任务一节中描述的任务。搜索空间也变大到我们在搜索空间一节中描述的那样。
下图反应了整个搜索过程,从左下角的空算法开始,一步一步找到各种技术。最终的算法代码经过整理后也列在了图中。
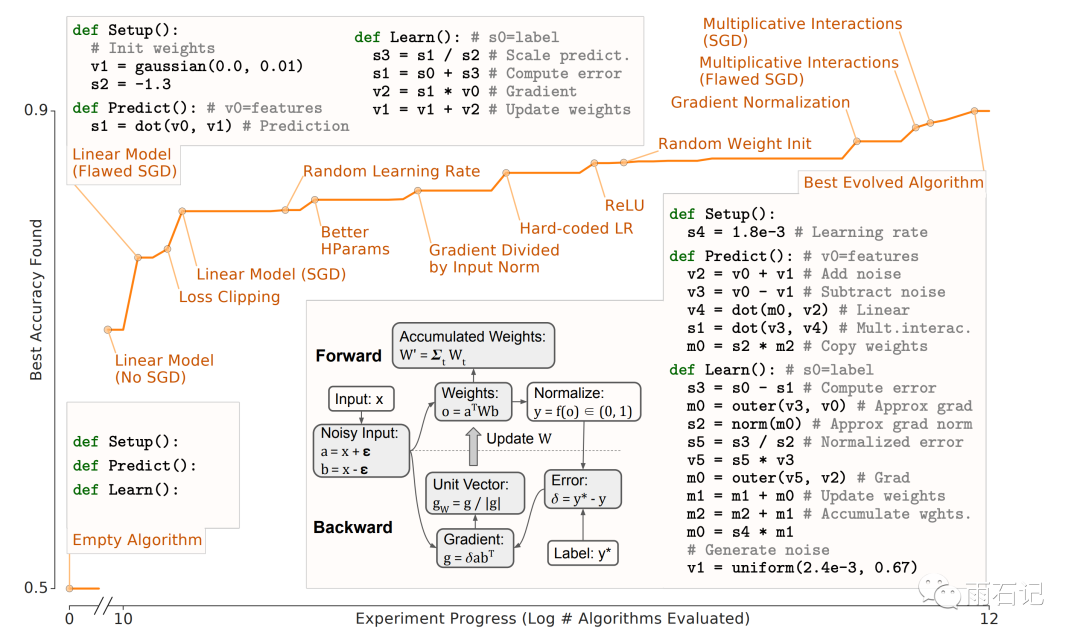
最终的算法中有一些对最后效果很重要的特性:
-
噪音被加入到了输入上。 -
Multiplicative interactions: o = a TWb -
梯度归一化技术。 -
在inference上的权重W '是训练中每一步权重的总和。
接下来,尝试一下搜索算法能不能解决一些特殊情况:
-
较少的训练样本数。训练样本只要80个,训练步数100epoch。 -
较少的训练迭代次数,算法只允许训练10个epoch,每个epoch 800样本。 -
10类而不是两类。
而发现的方法则如下,也如下图
-
对于较少的样本数目,学习到了通过noisy Relu进行数据增强,而且重复30次试验这个操作都会出现。 -
对于较少的迭代次数,搜索算法会发现学习率衰减这一操作。 -
对于多类问题,搜索到的算法会使用变换后的参数矩阵的平均来作为学习率。

总结
本文的主题是要介绍一种基于遗传的搜索算法,在这个只有基础操作的搜索空间里,提出了四种方法来加速:
-
并行 -
FEC来避免重复结果的多余计算 -
增加其他任务来增大多样性 -
hurdles
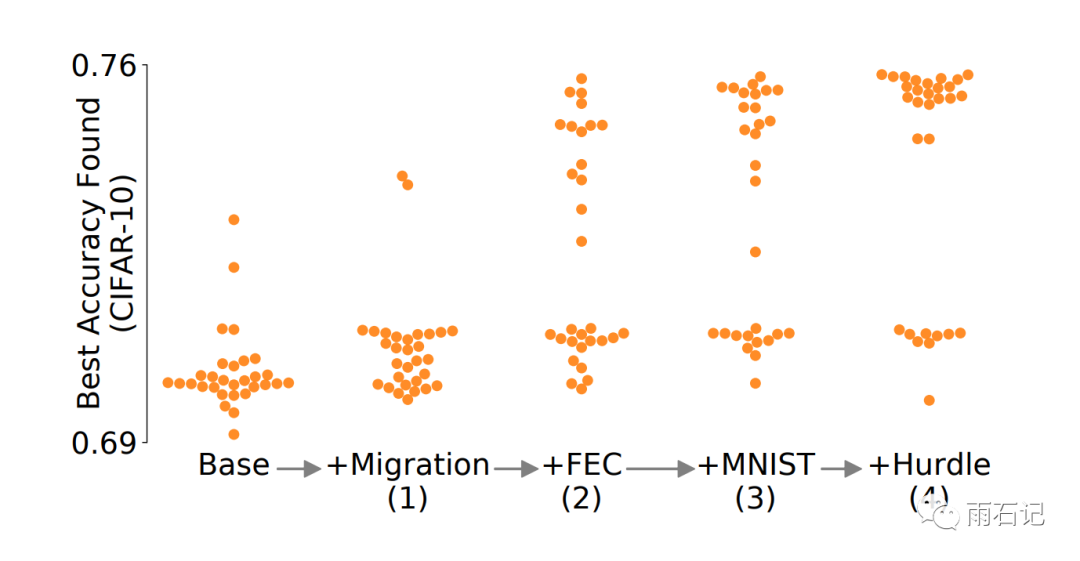
不同技术加进来得到的模型的效果如下:
在未来努力的方向:
-
可以继续增大搜索空间 -
同时还需要在生成的算法的解释上花费很多努力。比如,很多操作互相影响,需要解耦来找到真正有用的。
读到这个论文之后,感觉眼前一亮,让我看到一丝丝AutoML终能成大事的感觉,如果真的能成,就是在AI界的降维打击。
参考文献
-
[1]. Real, Esteban, et al. "Automl-zero: Evolving machine learning algorithms from scratch." arXiv preprint arXiv:2003.03384 (2020).
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏