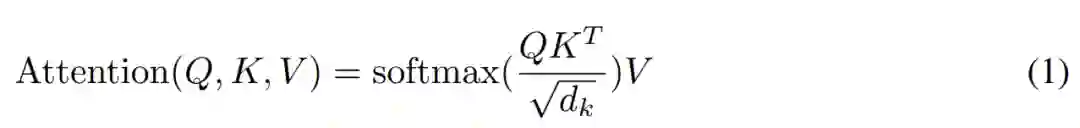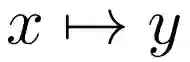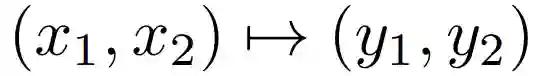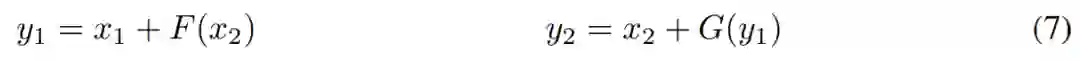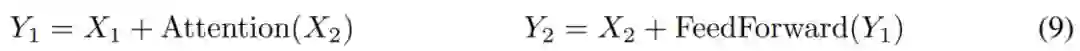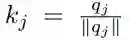Transformer 是近期 NLP 领域里最热门的模型之一,但因为算力消耗过大,对于个人研究者来说一直不太友好。近日一篇入选 ICLR 2020 的研究提出了「Reformer」,把跑 Transformer 模型的硬件要求压缩到了只需一块 GPU,同时效果不变。
大型的 Transformer 往往可以在许多任务上实现 sota,但训练这些模型的成本很高,尤其是在序列较长的时候。在 ICLR 的入选论文中,我们发现了一篇由谷歌和伯克利研究者发表的优质论文。文章介绍了两种提高 Transformer 效率的技术,最终的 Reformer 模型和 Transformer 模型在性能上表现相似,并且在长序列中拥有更高的存储效率和更快的速度。论文最终获得了「8,8,6」的高分。
![]()
在最开始,文章提出了将点乘注意力(dot-product attention)替换为一个使用局部敏感哈希(locality-sensitive hashing)的点乘注意力,将复杂度从 O(L2 ) 变为 O(L log L),此处 L 指序列的长度。
此外,研究者使用可逆残差(reversible residual layers)代替标准残差(standard residuals),这使得存储在训练过程中仅激活一次,而不是 n 次(此处 n 指层数)。最终的 Reformer 模型和 Transformer 模型在性能上表现相同,同时在长序列中拥有更高的存储效率和更快的速度。
这篇论文在评审过程中收获了「一致通过」,并被认为将产生重大影响,也经过了几位外部评审的详细审查,最终获得了「8,8,6」的高分。
-
论文地址:
https://openreview.net/forum?id=rkgNKkHtvB
-
代码:
https://github.com/google/trax/blob/master/trax/models/research/reformer.py
Transformer 架构被广泛用于自然语言处理中,并且在许多任务中实现了 sota。为了获得这些结果,研究者不得不开始训练更大的 Transformer 模型。在最大的配置中,参数数量已经超过了 0.5B/层,层数多达 64。
诸如此类的大型 Transformer 模型频频出现,到底是客观上必须要求如此多的资源,还是仅仅是因为处理效率不够高?
0.5B 的参数占据了 2GB 的内存,嵌入大小为 1024、批处理大小为 8 的 64K token 的激活要用 64K×1K×8 = 0.5B 浮点数,需要另外 2GB 的内存。
如果说每层的内存占用只有这么一些的话,部署 Transformer 会比实际中更容易,但是事情并不是这样的。以上的估计只包括了每层的内存占用情况和输入的激活损失,并没有考虑 Transformer 上的内存占用问题:
由于激活需要被存储并用于反向传播,有着 N 层的模型的大小比单层大了 N 倍;
由于中间的全连接层的深度 d_ff 通常远大于注意力激活层的深度 d_model,因此需要占用很大的内存;
在长度为 L 的序列上的 attention 的计算和时间复杂度是 O(L2),所以即使是一个有 64K 字符的序列就会耗尽 GPU 的内存。
研究者提出了一种 Reformer 模型来解决刚才说的那些问题:
可逆层(Reversible layer),这个东西最早是 Gomez 等人引入的,在整个模型中启用单个副本,所以 N factor 就消失了;
在前馈层(feed-forward layer)分开激活和分块处理,消除 d_ff factor,节省前馈层的内存;
基于局部敏感哈希(locality-sensitive hashing,LSH)的近似注意力计算,让注意力层的 O(L2) 因子替代 O(L) 因子,实现在长序列上的操作。
Transformer 中的多头注意力层是造成内存占用大的主要原因,因此研究者从这里入手解决问题。
![]()
在多头注意力中,多个注意力层平行计算并叠加。每个注意力层会线性地投影 queries、keys 和 values h 次。
在计算中可以发现,这种注意力机制带来的内存占用是很大的。回到公式 1,假设 Q、K、V 都有 [batch size, length, d_model] 这样的 shape。主要的问题就在于 QK^T,因为它的 shape 是 [batch size, length, length]。如果实验中序列的长度是 64k,在批大小为 1 的情况下,这就是一个 64K × 64K 的矩阵了,如果是 32 位浮点计算就需要 16GB 的内存。因此,序列越长,Transformer 性能就越受到影响。
如果要减少内存占用的话,在这里就需要让 Q 和 K 保持一致。这是很容易的,只要从同样的线性层 A 提取即可,并单独分离一个给 V。QK 共享不会对 Transformer 的性能造成影响,即使对 K 加入额外的正则长度。
对于局部敏感哈希注意力而言,需要 Q=K,以及 V,它们的 shape 都是 [batch size,length,d_model],而重点关注的是 QK^T,有着 [batch size,length,length] 的 shape。进一步来说,对于每个 q_i,实际需要关注的是它们在 key 的接近值。例如,如果 K 是 64K,对于每个 q_i,只需要考虑一小部分,如 32 个到 64 个最接近的 keys。
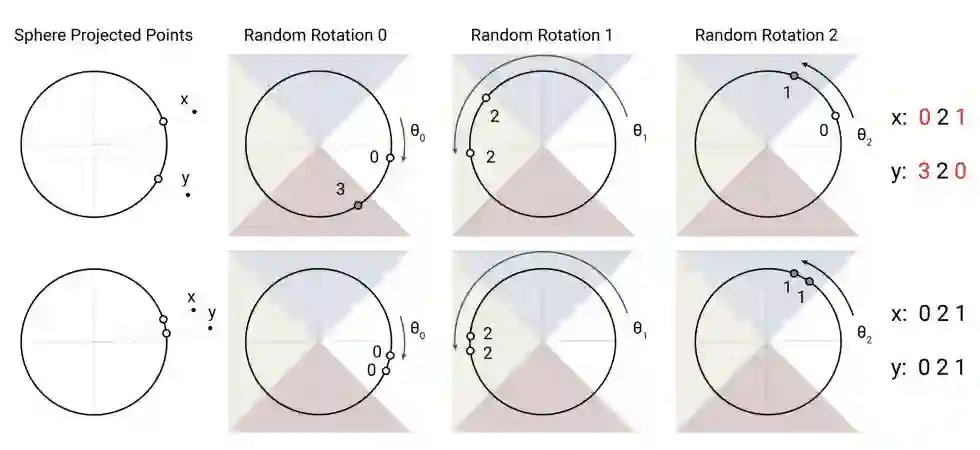
这样一来就需要找到最近邻的值,这就需要局部敏感哈希(LSH)了,它能够快速在高维空间中找到最近邻。一个局部敏感哈希算法可以将每个向量 x 转换为 hash h(x),和这个 x 靠近的哈希更有可能有着相同的哈希值,而距离远的则不会。在这里,研究者希望最近的向量最可能得到相同的哈希值,或者 hash-bucket 大小相似的更有可能相同。
![]()
图 1:研究中使用的局部敏感哈希算法。这种算法使用随机旋转的方法,对投影的点建立分块,建立的规则依据对给定轴的投影进行比较。在本图中,两个点 x、y 由于三次随机旋转投影中的两次都不靠近,所以不太可能有相同的哈希值。而另一个例子中他们投影后都在同一个。
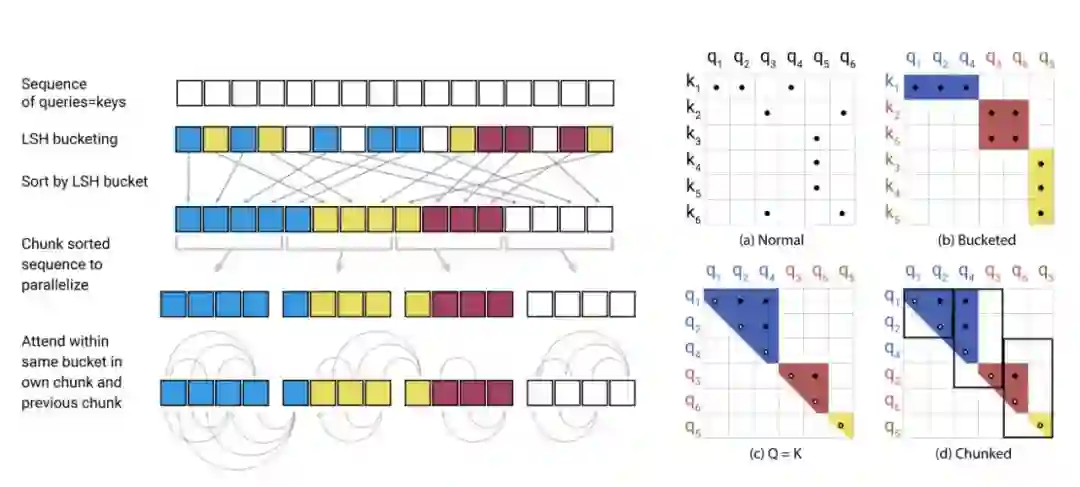
最终,对 attention 进行哈希处理的流程如下:
![]()
图 2:简化的局部敏感哈希注意力,展示了 hash-bucketing、排序和分块步骤,并最终实现注意力机制。
![]()
表 1:Scaled Dot-Product、Memory-Efficient 与 LSH 注意力的内存和复杂度对比。l 表示长度,b 表示批量大小,n_h 表示 head 数量,n_c 表示 LSH 块数量,n_r 表示哈希重复次数。
在一个大型 Transformer 中,通常设置 d_ff = 4K、n_l = 16,所以,如果 n_l = 16,那内存占用就会达到 16GB。在论文中,研究者首先通过可逆层来解决 n_l 问题,然后展示了如何利用分块来解决 d_ff 问题。
研究者在 Transformer 上应用了 RevNet 思想
,将注意力和前馈层结合在 RevNet 块内。
常规的残差层执行一个作用于单个输入并产生单个输出的
![]()
函数,其形式为 y = x + F (x),可逆层作用于成对的输入/输出:
![]()
![]()
在上面的公式中,F 成为注意力层,而 G 成为前馈层。
![]()
可逆 Transformer b 不需要在每一层中激活存储,于是无需使用 nl 项。
比较厚的层仍然会占用大量内存。前馈层的计算在序列中是完全独立的,所以可以分块:
![]()
一般这一层会通过执行所有位置的操作来进行批处理,但是每次进行一块的处理方法会减少内存占用,反向计算(reverse computation)和反向过程(backward pass)也会被分块。
在实验部分,研究者逐个分析上述每种技术,以确定哪种组合会对性能产生影响。首先,他们证明了可逆的层和共享的查询-键空间对性能没有影响。接下来,他们开始分析哈希注意力以及整个 Reformer 模型。
研究者在 imagenet64 和 enwik8-64K 任务上进行了实验,其中,后者是 enwik8 的一个变体,被分为 2 个 16 = 64K token 的子序列。研究者使用 3 层的模型进行控制变量实验,以便与常规 transformer 进行比较。所有的实验都有 d_model = 1024、d_ff = 4096、n_heads = 8。这些模型在每块 GPU 上进行批大小为一个序列的训练,总共有 8 块 GPU 并行。
研究者首先考虑了共享 QK 注意力对于常规 Transformer 模型的影响。共享 QK 注意力使得
![]()
,并且防止 token 注意到自身(除非没有其他可用的语境)。在下图 3 的左半部分,研究者绘制了常规和共享 QK 注意力的困惑度曲线。
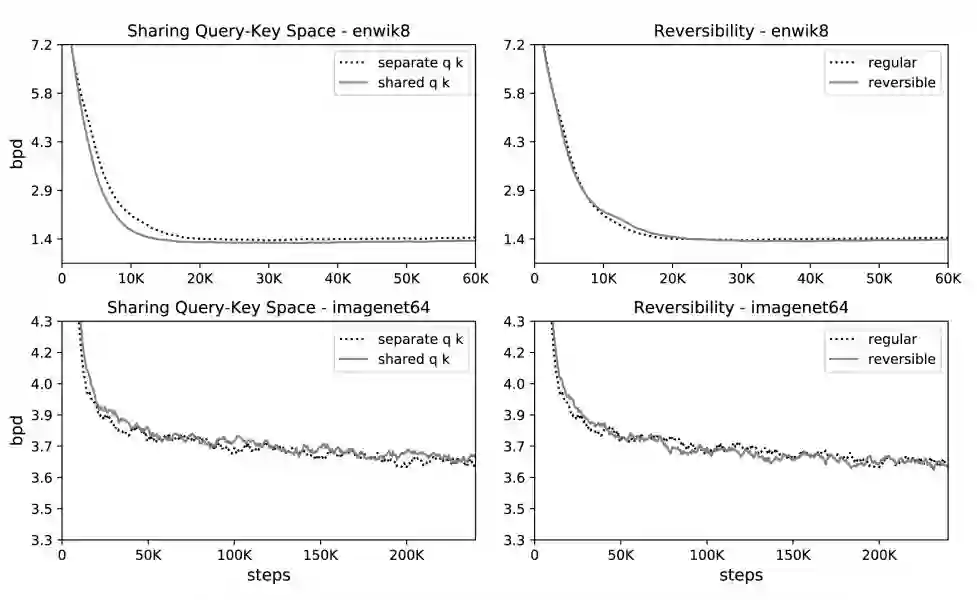
共享的查询-键空间并不比常规注意力表现差;实际上,对于 enwik8 来说,前者甚至训练得稍快一些。换句话说,采用共享 QK 注意力并不会造成准确率的损失。
![]()
图 3:在 enwik8 和 imagenet64 训练中,共享查询-键空间(左)和可逆性(右)对于性能的影响。
可逆层又会产生什么影响呢?如上图 3 右所示,研究者对比了常规 Transformer 和文中提到的可逆 Transformer。它们拥有相同的参数量,学习曲线也几乎一样。结果表明,
可逆 Transformer 节省内存的同时也不以牺牲准确率为代价。
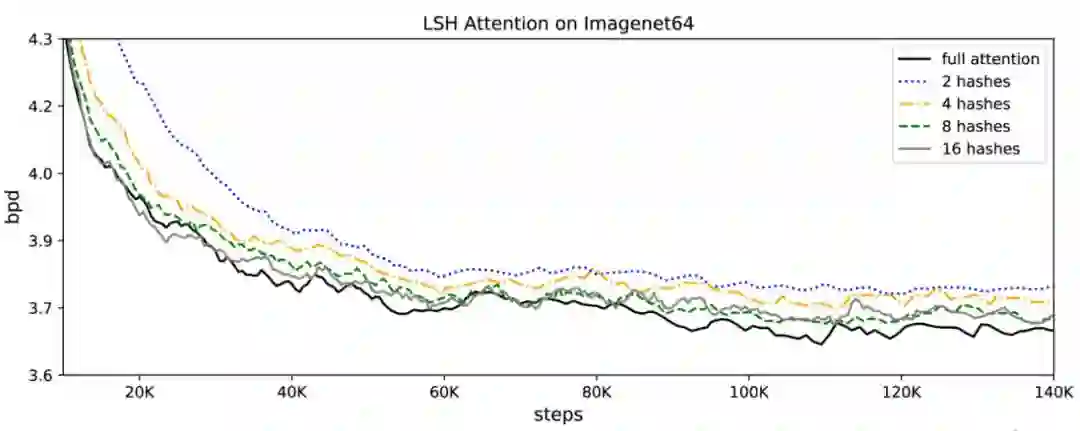
如下图 4 所证,LSH 注意力是全注意力的近似值,它的准确率随着哈希值的增加而提升。当哈希值为 8 时,LSH 注意力几乎等同于全注意力。一般而言,模型的计算开销随哈希值的增加而增大,所以研究者可以根据自身计算预算调整哈希值。
![]()
图 4:在 imagenet64 上 LSH 注意力性能基于哈希值的变化曲线图。
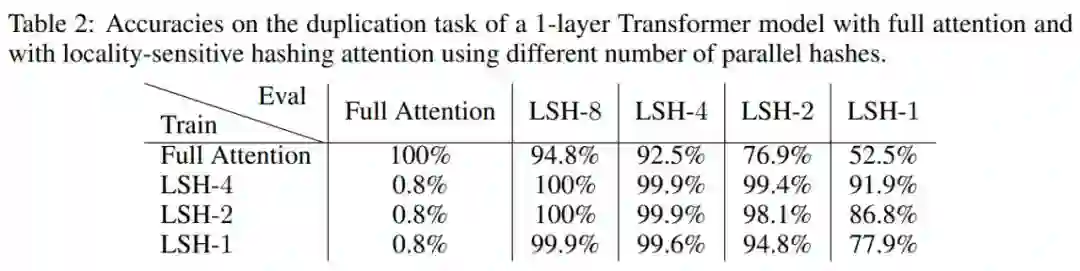
如下表 2 所示,研究者可以在评估的时候增加哈希值,从而使得结果更加准确。
![]()
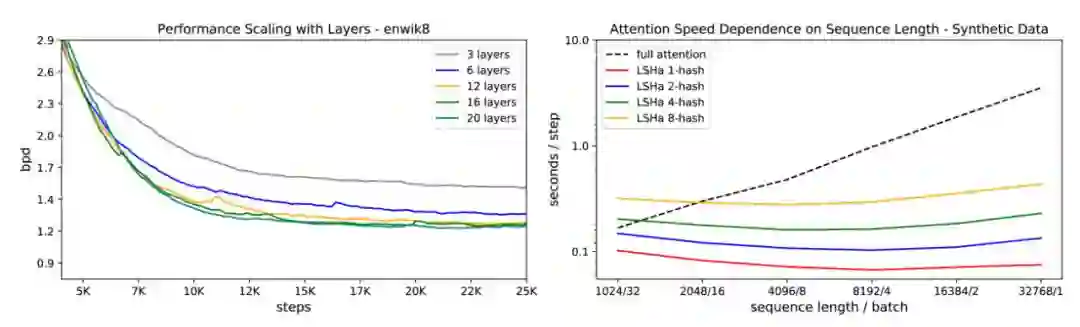
如下图 5 右所示,研究者描述出不同注意力类型的速度和序列长度的变化曲线图,同时保持 token 总数量不变。结果显示,常规注意力随着序列长度的增加而速度减缓,而 LSH 注意力速度保持平稳。
![]()
图 5 左:在 enwik8 上 LSH 注意力随层数增加的性能变化曲线;图 5 右:全注意力和 LSH 注意力的评估速度呈现出不同的曲线变化。
此外,为了验证 Reformer 的确可以在单核心上拟合大模型,并能够在长序列上快速训练,研究者在 enwik8 和 imagenet64 上训练了多达 20 层的大型 Reformer。如上图 5 所示,这些模型拟合内存和训练。
方便交流学习,备注:
昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:
机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。