周博磊:深度生成模型中的隐藏语义

来源:AI科技评论

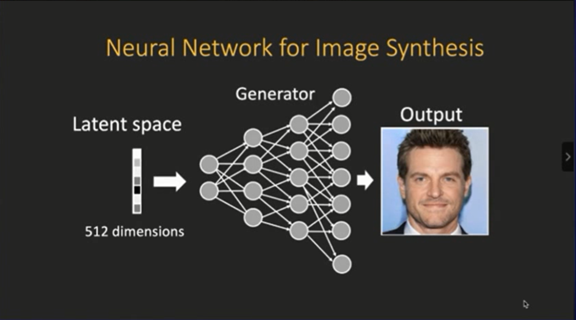

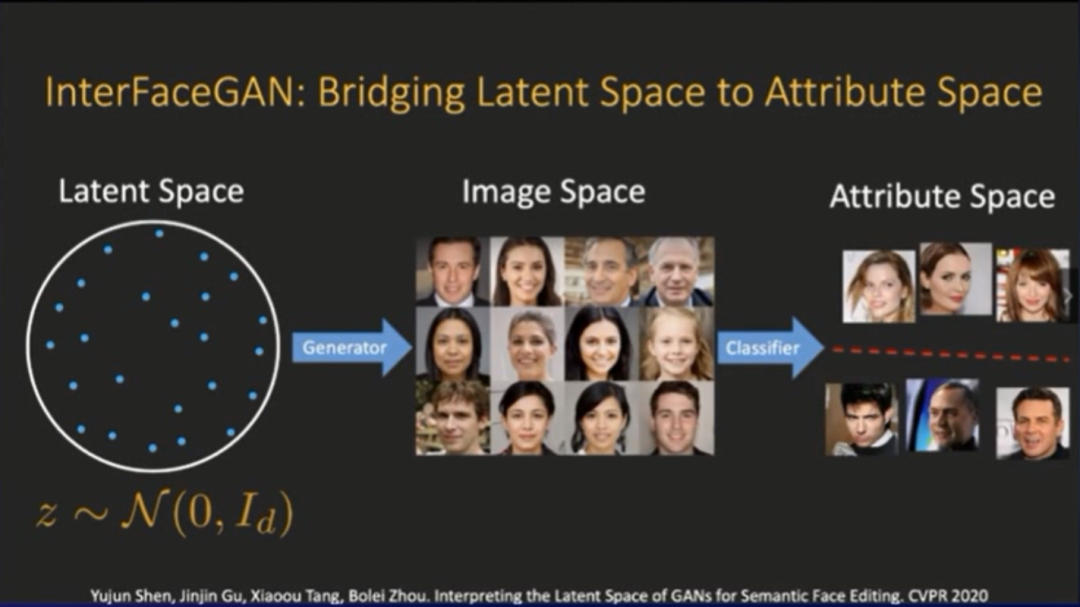
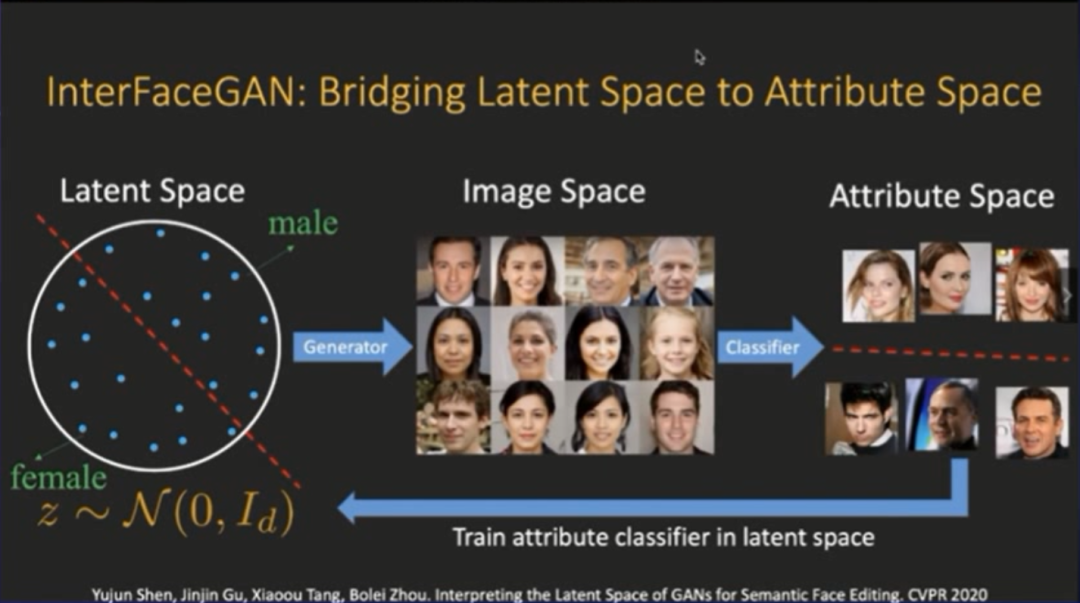
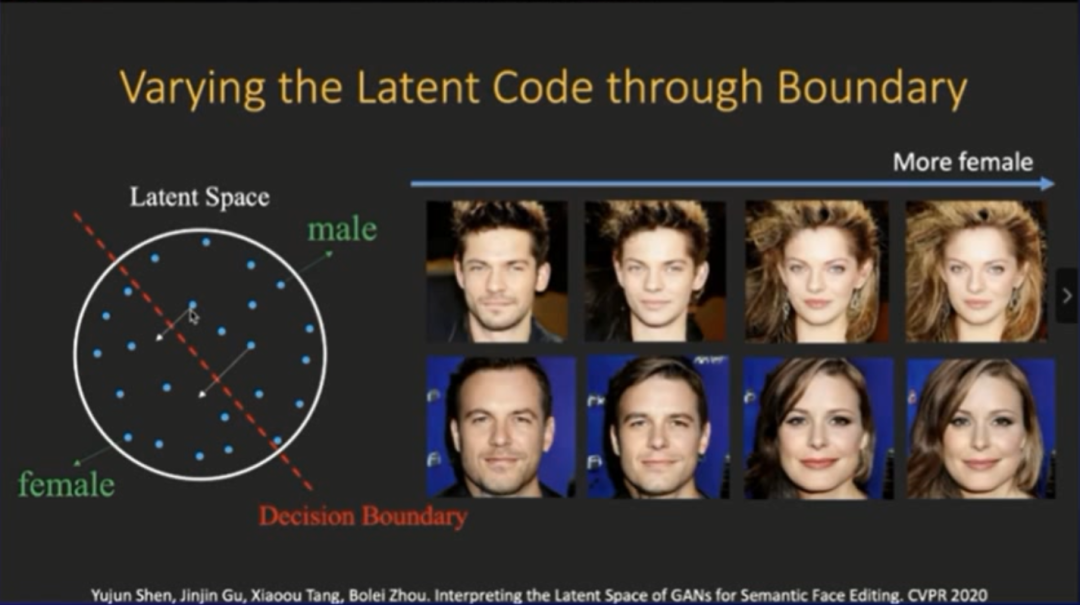


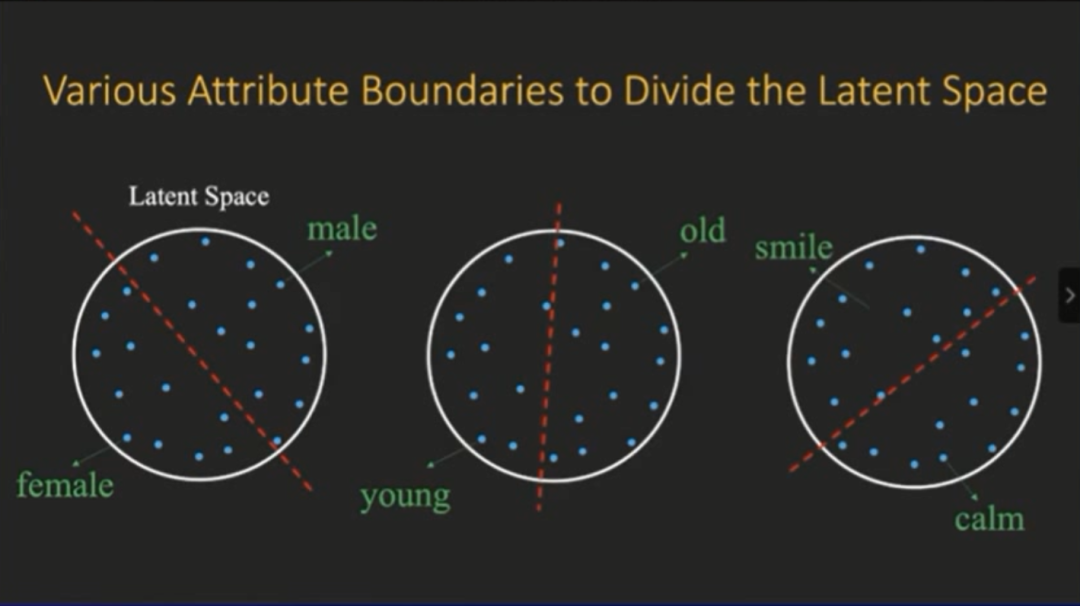





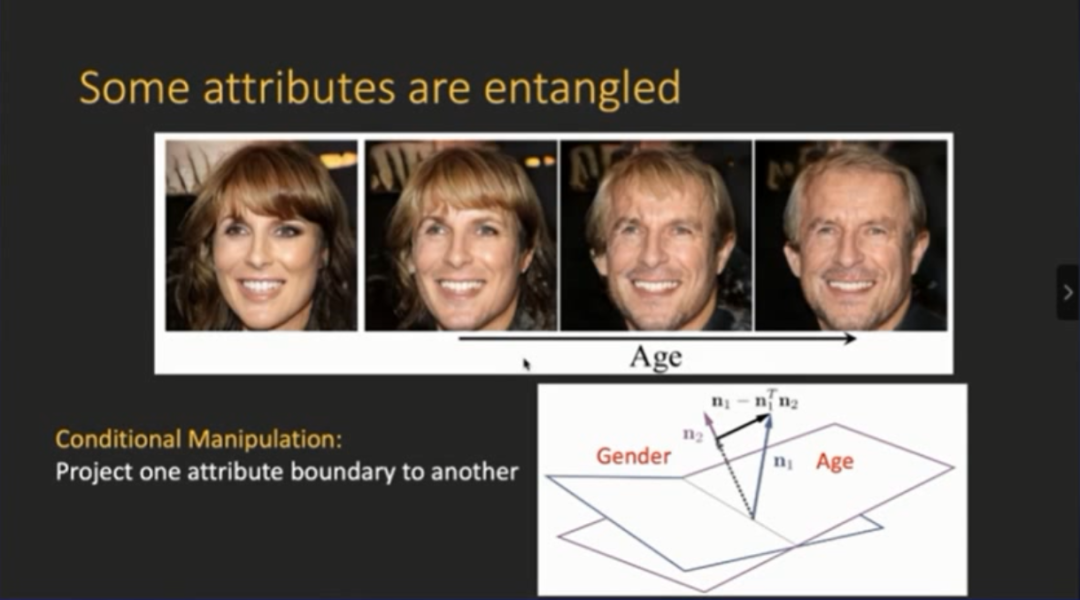



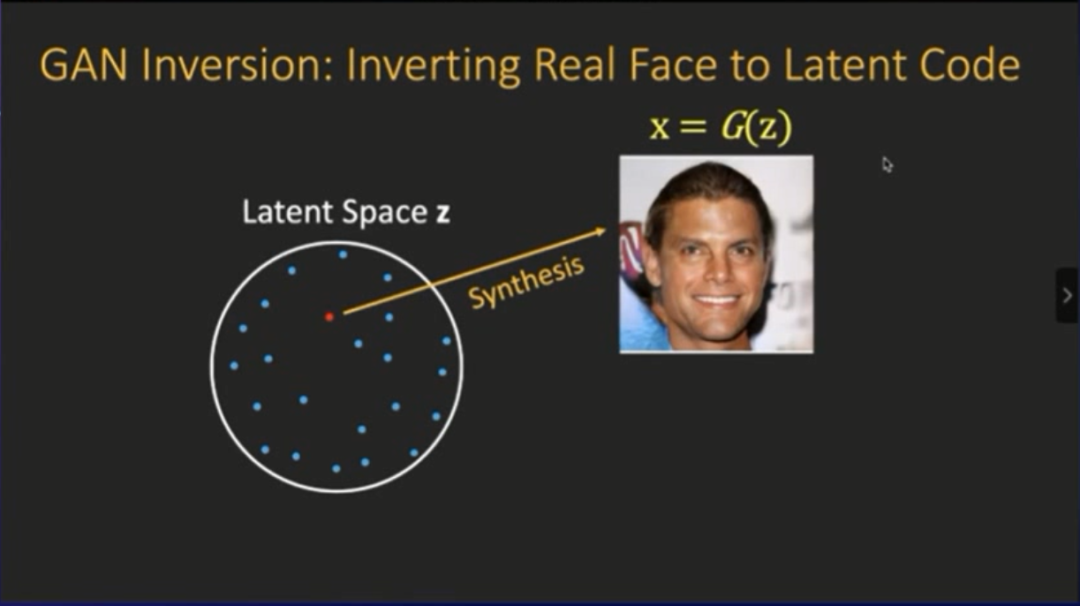
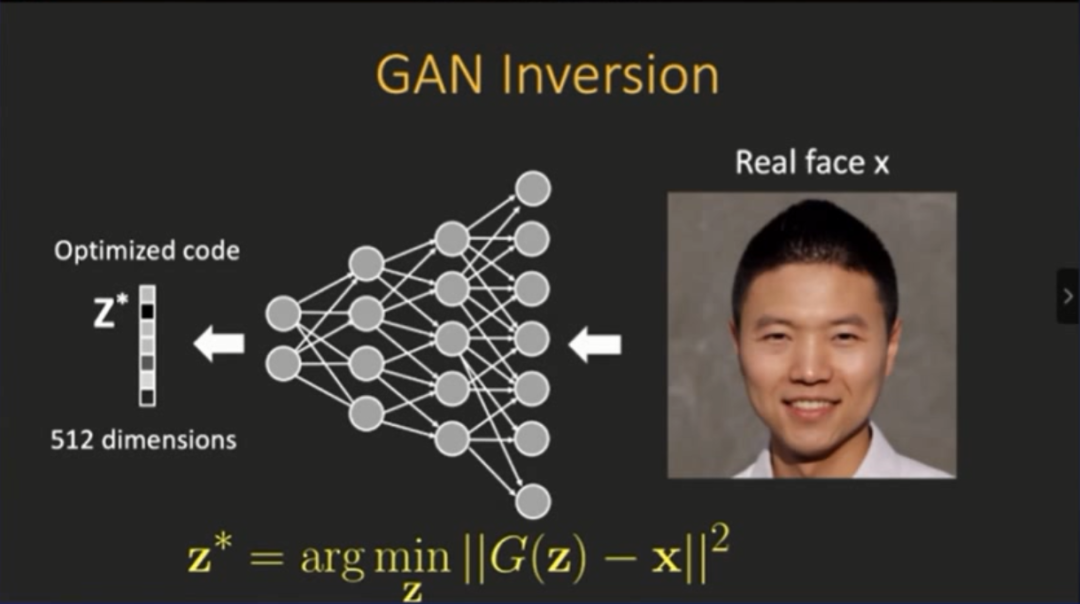
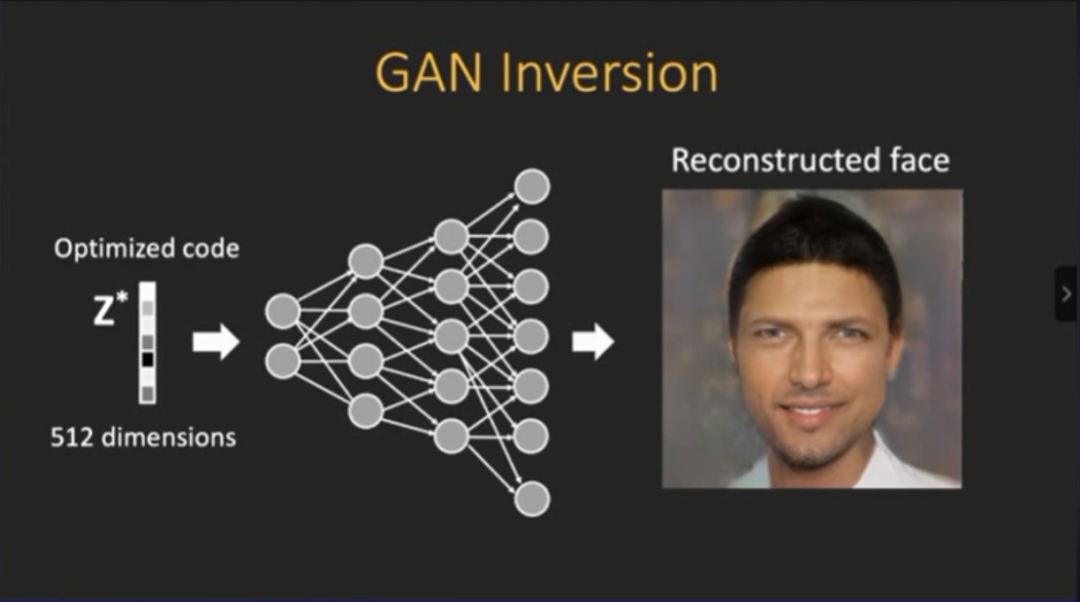


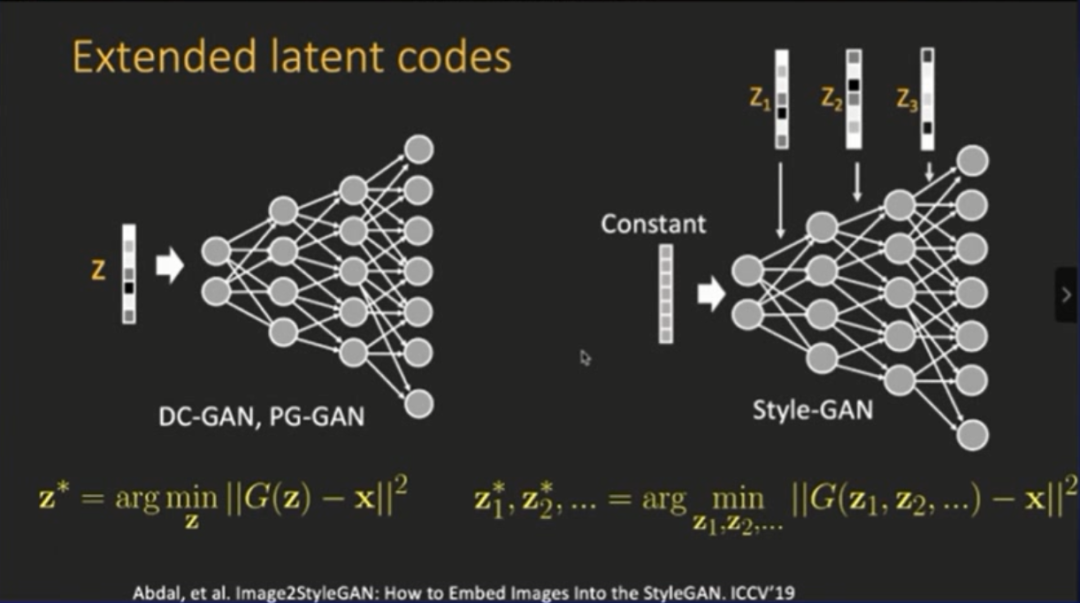



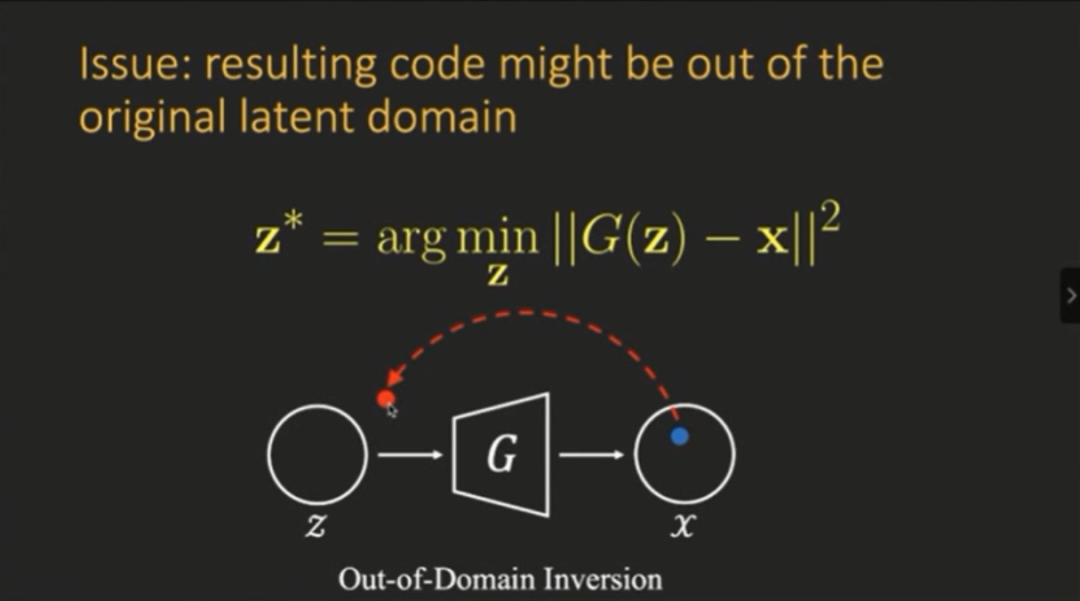
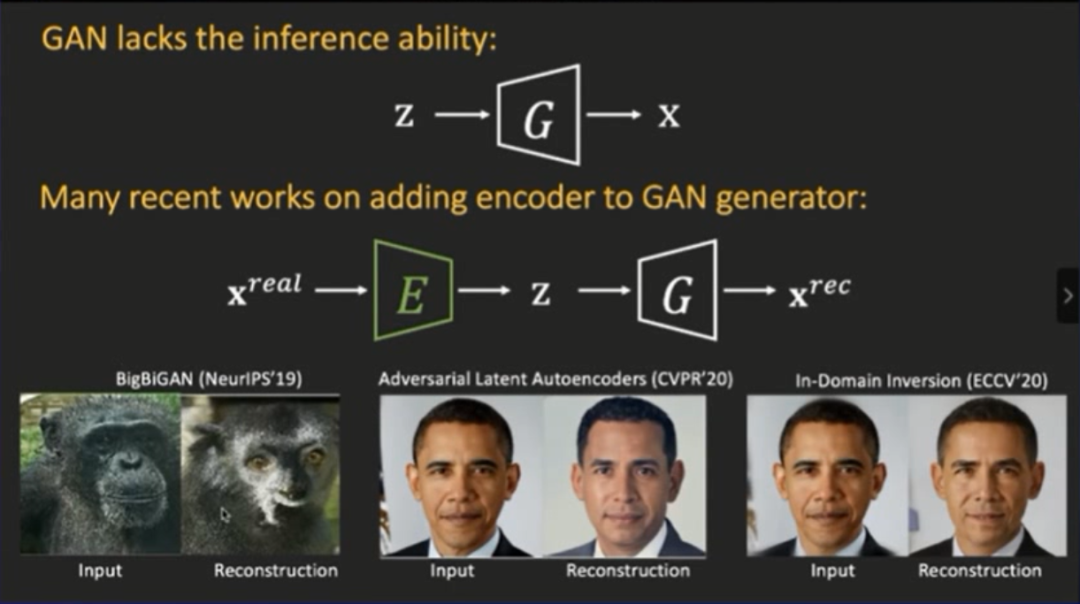






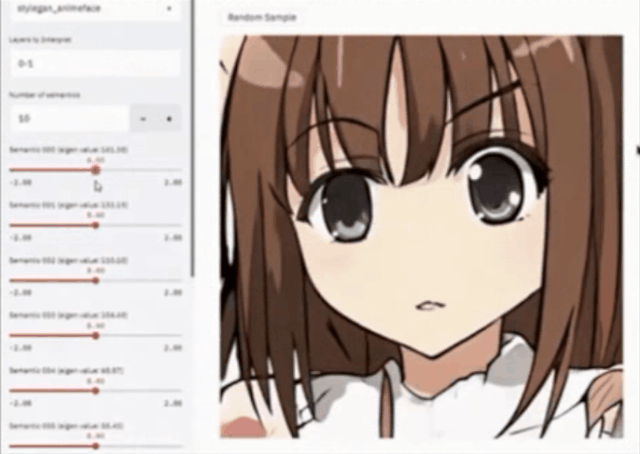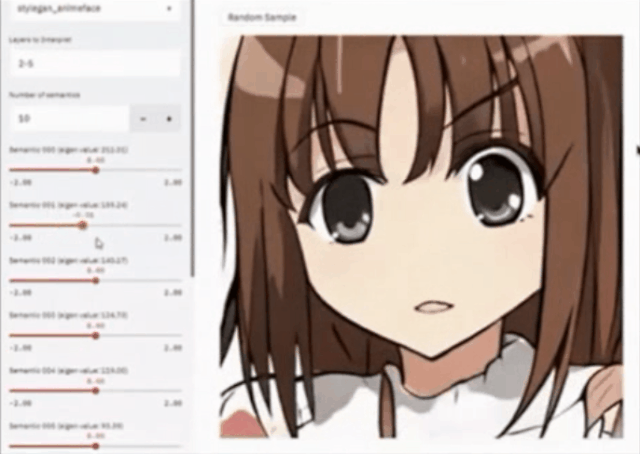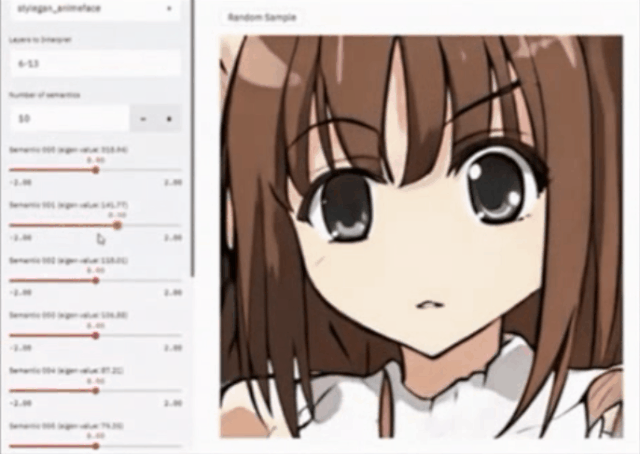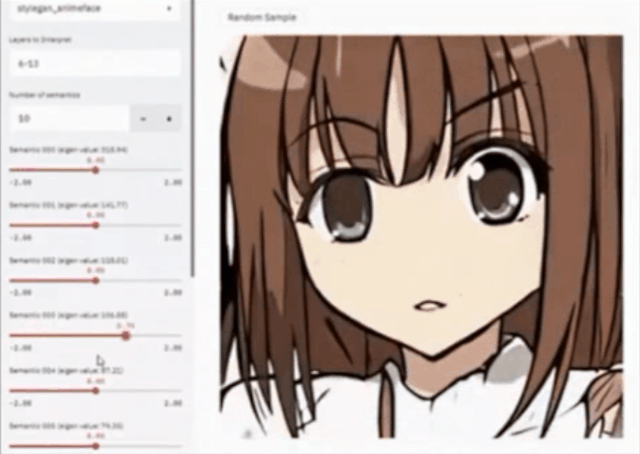



登录查看更多
相关内容

专知会员服务
32+阅读 · 2020年6月11日
Arxiv
3+阅读 · 2018年8月20日



相关VIP内容
专知会员服务
32+阅读 · 2020年6月11日
相关资讯
相关论文
Arxiv
3+阅读 · 2018年8月20日