让机器告诉你故事的结局应该是什么:利用GAN进行故事型常识阅读理解

论文作者 | 王炳宁,刘康,赵军(中科院自动化所)
特约记者 | 吴桐(东南大学)
深夜,父亲捧着故事书来到小儿子的床边,温柔的念到:“……王子看着躺在面前的睡美人,轻轻的俯身吻了下去……”“爸爸,睡美人是还没醒吗?”父亲轻声地说:“刚才爸爸讲了什么来着,王子出发之前吃了四碗韭菜大蒜馅的饺子,所以睡美人终于还是忍不住醒了。”
故事型常识阅读理解(Story Cloze Test (SCT))是近几年新提出的一个文本理解任务,在这个任务中,给定背景的四句话,我们需要从两个候选句子中选择出哪一个可以被前四句话推导出来。要完成这个任务,我们需要深入理解背景的四个句子,进行推理。

▲ 图1:训练数据集样本

▲ 图2:测试数据集样本
如上图所示,这个数据集的训练集和测试集存在偏差,而且在训练集中只有正样本,没有负样本。这使得常规的判别模型难以得到应用。
来自中国科学院自动化研究所模式识别国家重点实验室的王炳宁同学,刘康老师和赵军老师在 IJCAI 2017 会议论文“Conditional Generative Adversarial Networks for Commonsense Machine Comprehension”提出了一种新的模型,使用对抗式生成网络(GAN)产生负样本,从而使分类器能够得到充分训练并在该任务上表现不俗。
模型的整体思路如图 3 所示:
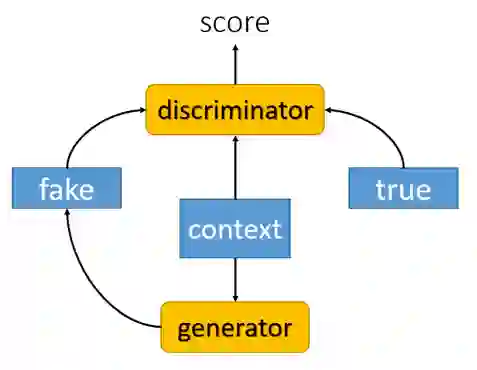
▲ 图3:系统结构图
在系统流程中,生成器(generator)读入长度为四句话的故事前情(context),然后生成一个伪样本(fake)。判别器有两个输入,其一是故事前情(context),其二是训练正例(true)或是生成器(generator)产生的伪样本(fake),判别器将输出概率值以表示样本能够从故事前情中推导得到的可能性。
具体地,判别器的模型图如图 4 所示:
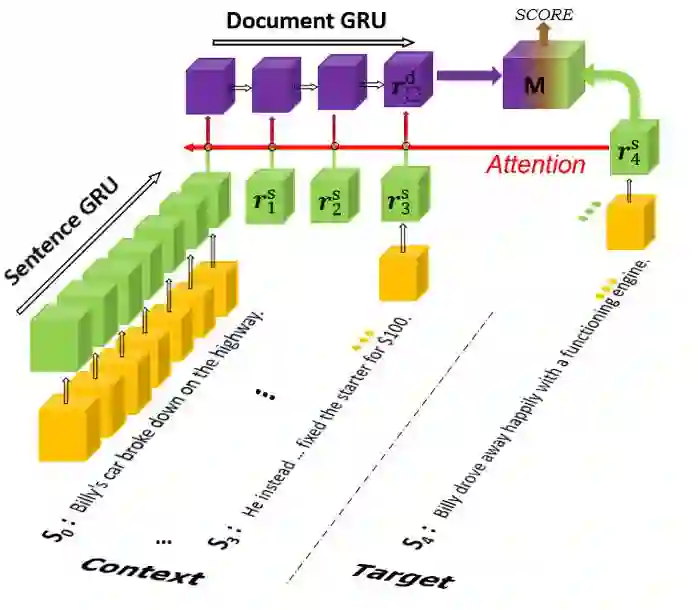
▲ 图4:判别器模型图
对于生成器,由于目标函数是判别器的分数值,而生成器的输出是根据 argmax 得到的一个个离散的词语,因此无法直接求导。本工作中使用了一种温度算法来近似 argmax 操作。具体来说,在预测每个词时,首先会经过 softmax 对词表中的每一个词求一个概率:
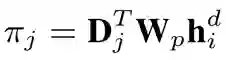
其中是第 πj 个词未经过 softmax 归一化的分数。然后对这个分数进行缩放,使大的更大,小的更小:
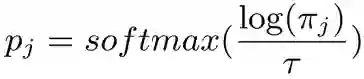
其中 τ 是缩放因子(温度系数),当它越大的时候,系统的输出越不确定,即每个词的概率都差不多,当这个因子很小的时候(特别的,趋近于 0 的时候),绝大部分都近似于 0,只有一个最大值近似 1。最后当前的输出为:
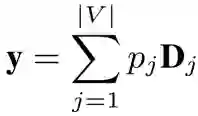
由于输出就由最大的那个值确定,因而可以看作是 argmax 的一种连续的近似。
随着判别器和生成器不断迭代的训练。最后得到的判别器可以判断当前输入的句子是不是可以被背景四句话推出。因此在测试阶段,本工作直接用判别器来输出一个概率来给出两个候选的可能性。这也是本工作的亮点之一,和以往 GAN 的应用不同,对抗过程中提升的主要目标是一个高性能的判别器,生成器在模型中仅起到一个辅助作用。
最后的实验结果(正确率)如下图所示:
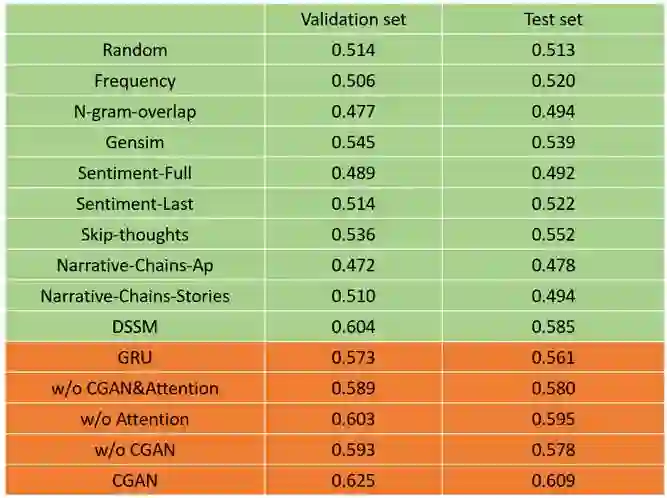
实验中,文中将该模型同几种传统的分类模型进行对比,该模型取得了显著的性能优势,并且可以看到,在加入了关注机制以及对抗样本之后,模型的效果更进一步的提高了。该工作对于处理正负样本不均衡的分类问题具有较高的借鉴意义。
欢迎点击「阅读原文」查看论文:
Conditional Generative Adversarial Networks for Commonsense Machine Comprehension
关于中国中文信息学会青工委
中国中文信息学会青年工作委员会是中国中文信息学会的下属学术组织,专门面向全国中文信息处理领域的青年学者和学生开展工作。

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。


点击 | 阅读原文 | 查看论文





