人机语音对话技术在58同城的应用实践

分享嘉宾:李忠 58同城 算法架构师
编辑整理:赵旺
内容来源:58技术沙龙
出品社区:DataFun
注:欢迎转载,转载请在留言区内留言。
导读:本文将介绍58同城人机语音对话机器人的完整解决方案,重点分享对话策略管理、自动电话拨打、意图识别、防骚扰控制等核心模块的设计实现,并阐述如何将语音机器人应用于58各业务场景,以助力销售、运营和客服提高人效。
——背景——
58同城是中国最大的生活信息服务平台,公司主营业务包括:招聘、汽车、金融、本地服务、二手等。其中,电话沟通是信息连接的重要渠道之一,如招聘业务模块,需要大量的业务人员进行求职信息确认、面试预约、面试回访等重复耗时的沟通工作。为了更好的服务 B 端商家和 C 端用户,实现“让生活简单美好”的公司使命,我们开发了语音机器人来进行电话语音沟通,减少业务人员的工作量并提升服务质量。
传统的沟通工作是完全依赖于人工拨打电话,而人工的方式相比于语音机器人存在很多问题。下图是语音机器人与人工的对比情况:
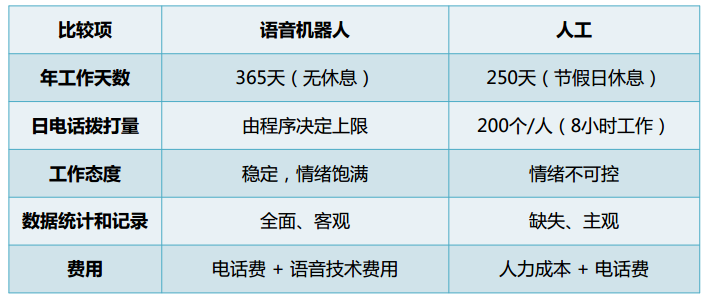
其中,关于工作态度,人工难以保持自身情绪的长久稳定,而机器人则可以始终如一的保持稳定、情绪饱满的工作态度;另外,在成本费用上,长期来看,语音机器人的成本远低于人力成本。对比了市面的语音机器人后,为了能快速的根据需求场景的变化与解决个性化的业务问题,公司采取了自研语音机器人的战略。
下面我们看一下58同城的人机语音对话示例:
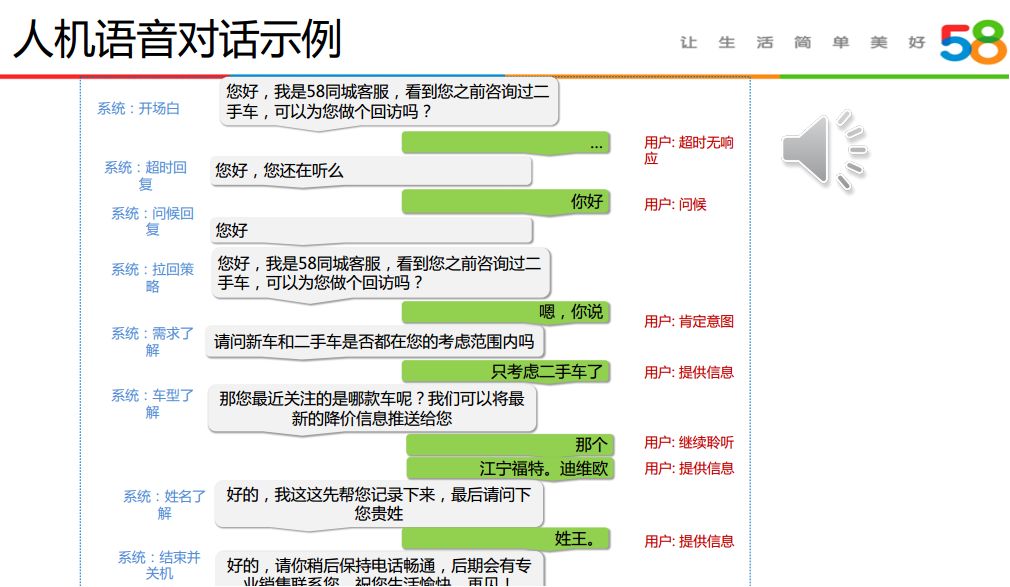
从图中可以看出,语音机器人还是保持了相对流畅的对话。机器人怎样实现根据用户的不同回应做出不同的响应的呢?后面给大家做进一步的详细的介绍。
——语音机器人的总体架构——
1. 总体架构
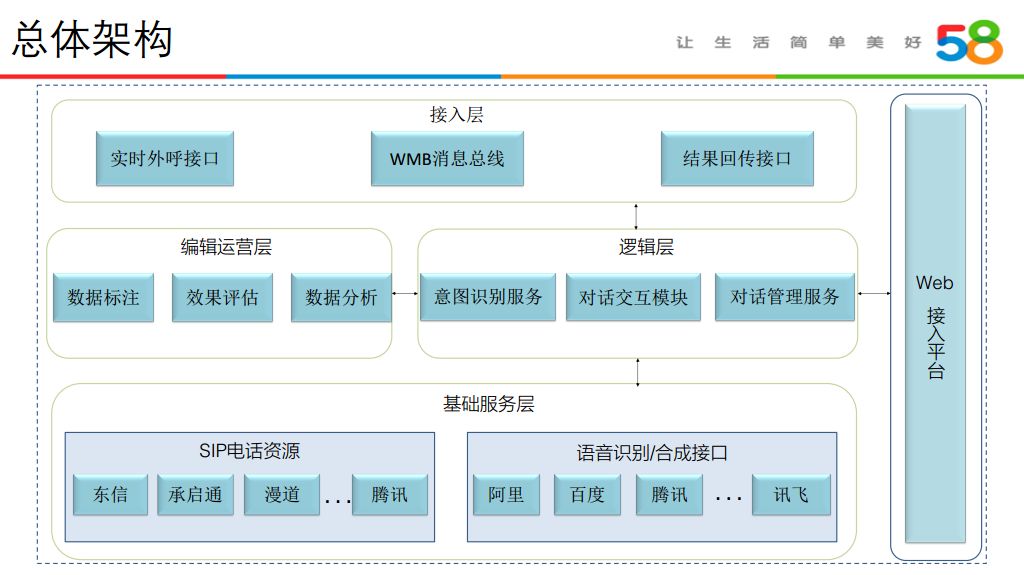
语音机器人的总体架构 :
① 接入层:主要以 API 接口的形式,方便业务方调用语音机器人。当一通电话结束时,机器人可以把消息以 WMB 方式传递给业务方,相当于异步调用。同时销售等业务方,可以通过结果回传接口将后期跟进、成单信息反馈给后台,进行进一步的算法优化。
② web 管理层:主要负责话术的配置、权限的控制、批量拨打、防骚扰策略设置、数据可视化查询等。
③ 逻辑层:整个机器人的核心控制层,相当于人的大脑,保证整个对话流程完整进行。
④ 编辑运营层:目前主要用于数据标注,标注数据用于模型迭代与线上效果评估。
⑤ 基础服务层:主要包括 SIP 电话资源和语音识别/合成接口两部分。SIP 电话资源即实现拨打电话的资源,像东信、漫道等。语音识别采用的是阿里、腾讯等第三方的接口。
2. 智能外呼流程
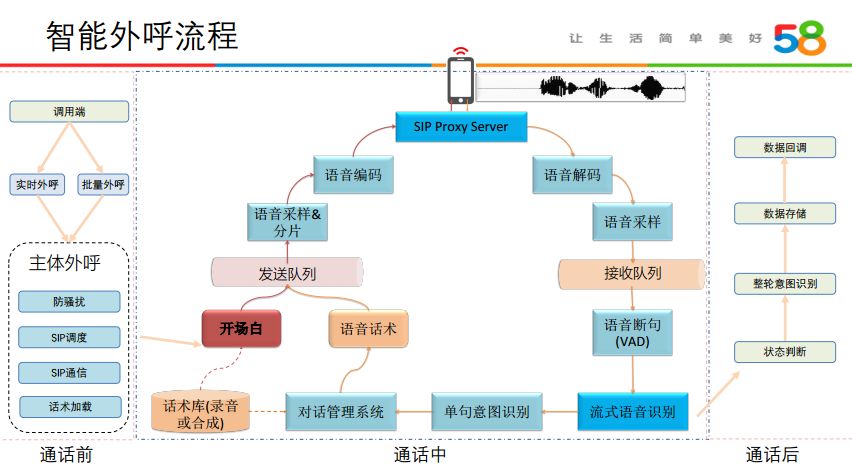
语音机器人智能外呼流程主要分为通话前、通话中、通话后三个部分。通话前主要是调用端,调用端会把被叫号码、业务场景等使用的信息传给主体外呼,主体外呼拿到信息后会进行一些策略的设置,如防骚扰逻辑的设置、选择合理的 SIP 方、建立 SIP 通信、根据业务场景加载话术等。当触发开场白后,进入“通话中”状态,通过发送语音和利用第三方语音合成接口编码语音,经 SIP Proxy Sever 端发送给用户,用户接听后,再对用户的反应进行判别与用户语音的解码,再利用第三方的流式语音识别接口得到文本。通过对文本的分析,结合话术跳转的逻辑,对用户的回复进行合理的响应。通话结束后,语音机器人会对整轮电话进行通话状态判断、整轮通话意图识别、数据存储与回调,并以 WMB 的方式回传给业务方。
——核心功能——
58同城语音机器人的核心功能包括四部分:电话拨打服务、通话状态识别、智能对话交互、整轮意图识别。
1. 电话拨打服务
实现电话的拨打服务功能,和客户建立连接。
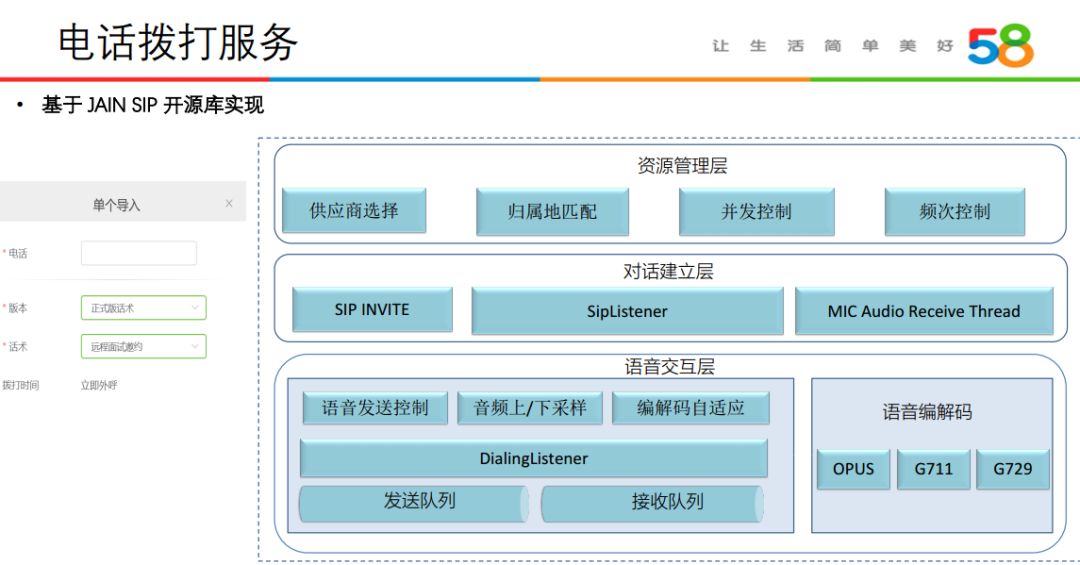
当前这一功能实现主要是基于 JAIN SIP 的开源库,主要包括四层。其中在资源管理层控制上,对于呼叫用户会考虑同样的归属地来提升拨打电话的接通率。对话建立层基于 SIP 协议来实现建立通话连接与释放连接的处理。
防骚扰策略:
为了避免过多打扰和消耗用户,设计了防骚扰策略。其策略主要考虑:
① 被呼名单限制:设置了呼叫白名单与黑名单,比如有些特定用户名单是不能呼叫的。
② 呼叫时间控制:哪些时间段是不能呼叫的。
③ 呼叫频次控制:对用户的呼叫频率要控制,防止过渡消耗用户。
④ 用户情绪识别:对呼叫中用户的情绪进行分析,当用户情绪很抵触时,添加到被禁的黑名单中。
2. 通话状态识别
判断拿到的客户电号码话是否真实存在和是否处于正常状态。比如做销售业务时,需要核对业务方拿过来的客户号码是否是空号、异常号码等,这个可用通过电话拨打服务来实现状态判断。
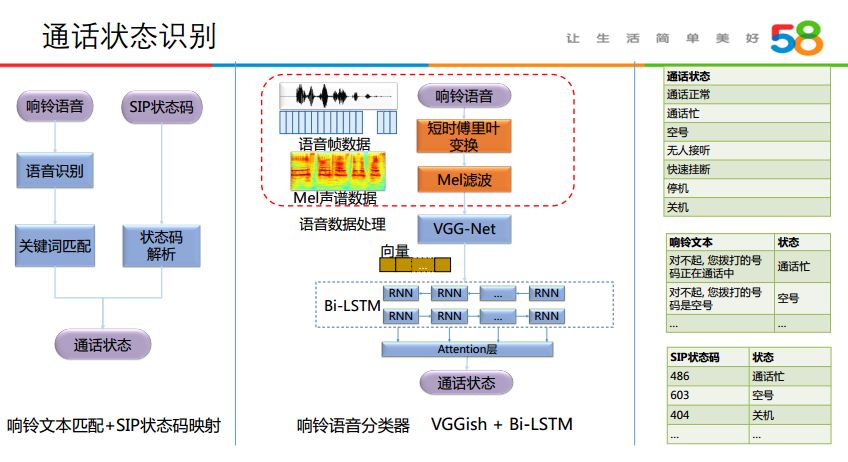
具体可以利用 SIP 协议和响铃语音来实现。SIP 协议:利用基于 SIP 协议返回的 SIP 状态码来进行判断,比如返回603则判断为空号;响铃语音:通过将语音信号转化为文本,进行文本关键词匹配和文本分类,对拨打号码进行判断,比如“您拨打的电话已关机”判断为关机状态,还可以利用语音信息特征设计响铃语音分类器,判断号码状态。
3. 智能对话交互
为了实现多轮对话流畅进行,智能对话交互主要包含以下模块:智能对话管理、电话按键捕获、单句意图识别、标准问题匹配、槽位提取。
① 智能对话管理:
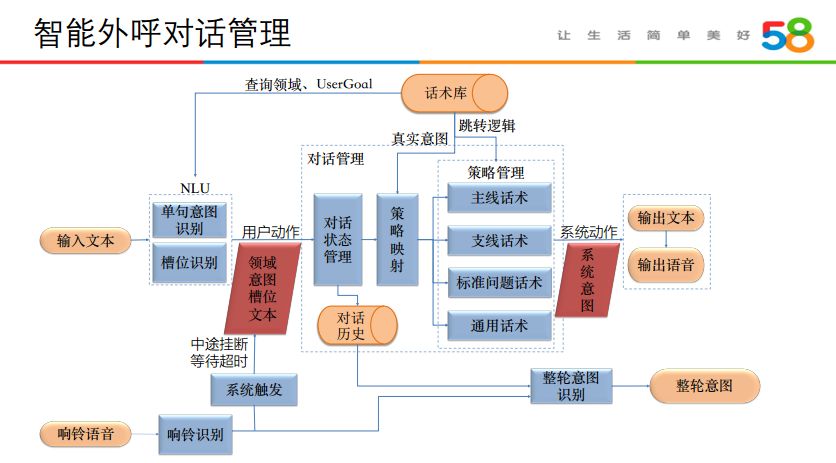
通常情况下:将用户语音转化后的文本作为模型的输入,首先对文本进行包括单句意图识别与槽位识别的 NLU 工作,然后将信息转化为用户动作并交给对话管理器。对话管理器需要判别用户的意图,根据预先设计好的话术库,结合映射策略进行话术选择跳转,生成系统动作。
具体的话术选择与策略,可以根据用户动作的语音响应与非语音响应,做进一步的处理,如下图所示。
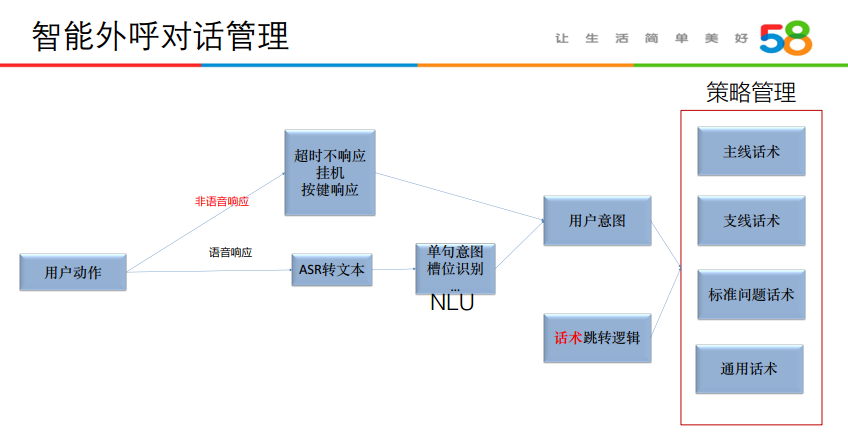
对于四类具体话术策略跳转的理解,可以结合下图话术实例来看:
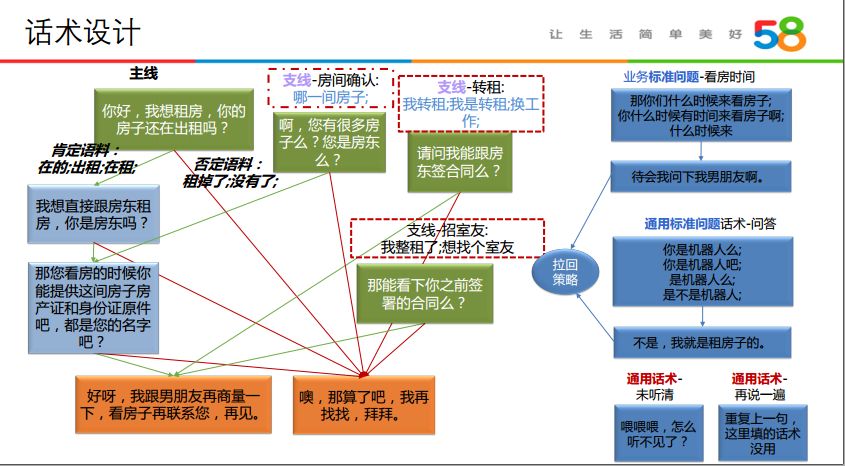
② 电话按键获取
捕获用户的按键信息。电话按键信息的捕获主要是基于 RTP、SIP、SDP 协议对按键的信号解析获得。
③ 单句意图识别:
用户的意图可能会有很多种,我们将意图整体划分为了十九类意图,并建立了标签、意图及说明的识别表。

单句意图识别的实现:当前公司上线主要用的是 TextCNN 进行多分类,将用户的单句话转换为文本后再进行分类。

我们也在尝试使用 Bert 模型,进行单句意图识别:
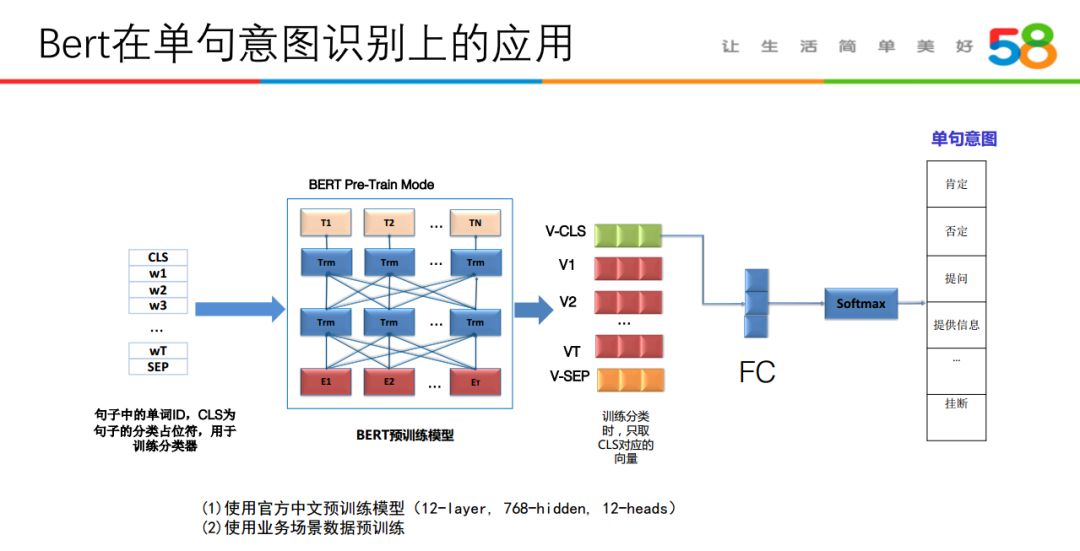
用公司自己的场景语料在谷歌官方中文预训练模型的基础上进行的 Pretrain,拿到 Bert 关于句子的编码向量 CLS 加全连接层后接 softmax 进行多分类。相对于原来 TextCNN 的方式,效果上准确率会有百分之二的提升。
④ 标准问题匹配:
当用户意图为提问时,对于问题类型为标准型问题,可以与标准问题库的问题进行问题匹配,选择对应的答案进行回复。

标准问题匹配当前使用的主要模型是 Bi-LSTM-DSSM:
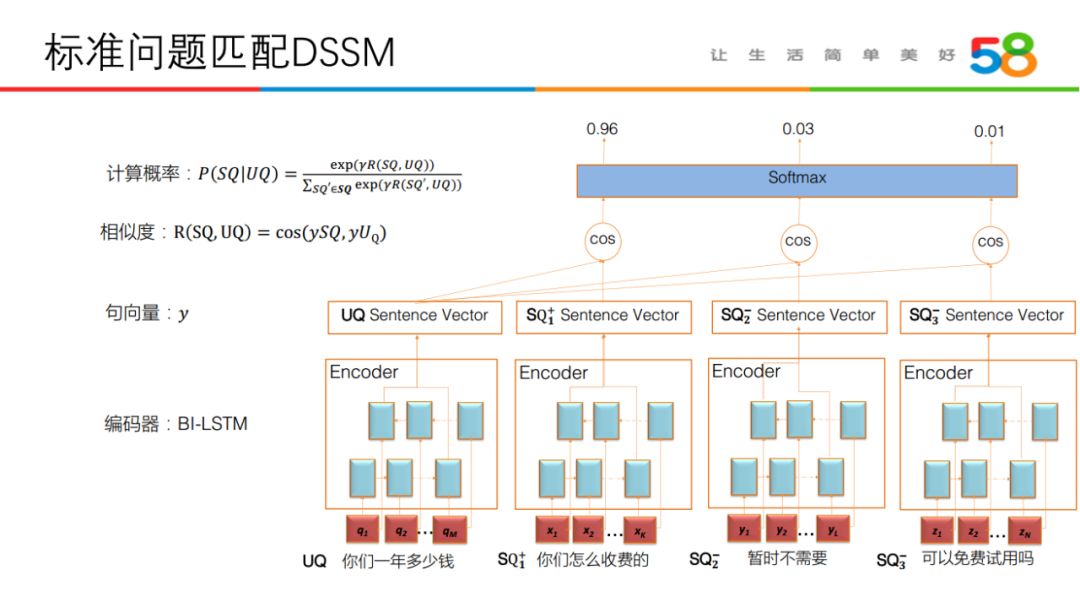
Bi-LSTM 进行句子的语义编码,DSSM 进行句子匹配。在正负例的选择上,当前主要需要依据具体场景与实验效果进行设定。计算损失时的目标是与正例的相似度越高以及与负例的相似度越低。
在标准问题匹配上,也有尝试用 Bert 的方式来做:
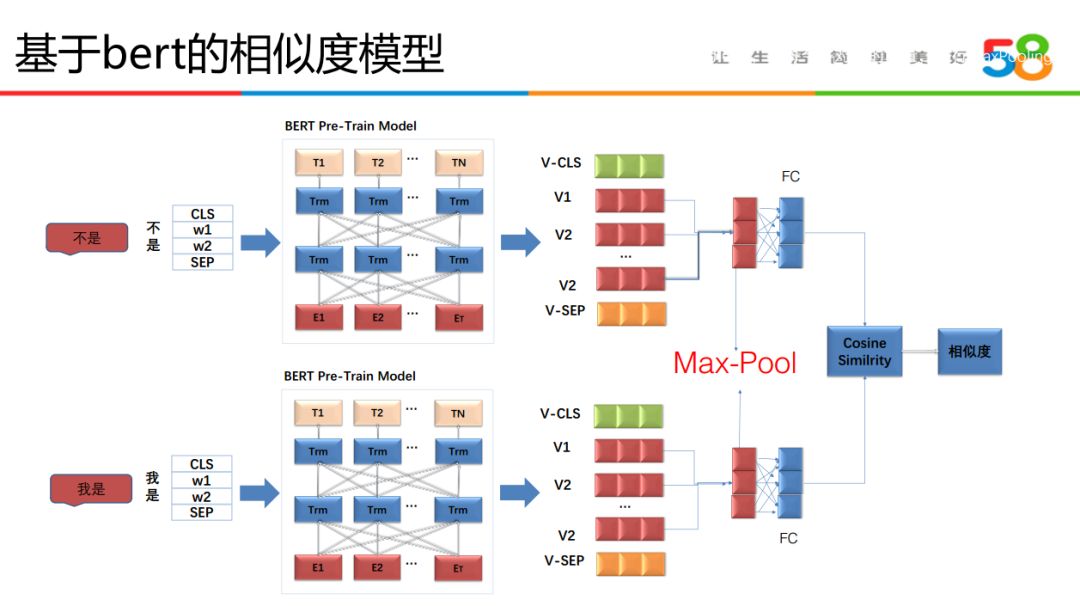
在标准问题的匹配上,Bert 主要是用于句子信息的抽取,在具体实现的时候,对比了 CLS、Mean-Pool、Max-Pool 等常见方式,发现用 Max-Pool 的方式去抽取作为句子的向量表示是最好的。
标准问题挖掘:
完善和更新标准问答数据集。
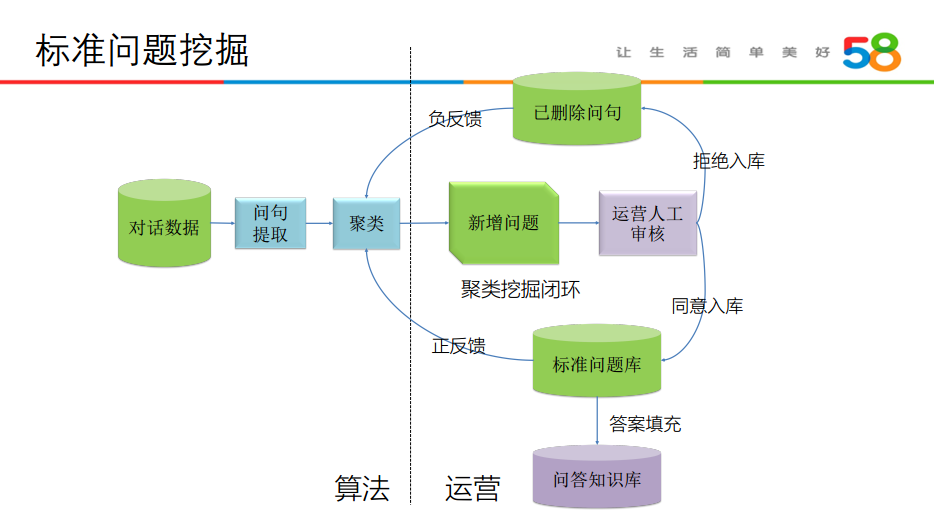
从对话数据中,提取问题与更新问答知识库。这里在新增问题时需要结合人工进行问题入库与否的审核,对于确定后的标准问题,需要对答案填充后才能添加到问答知识库中。
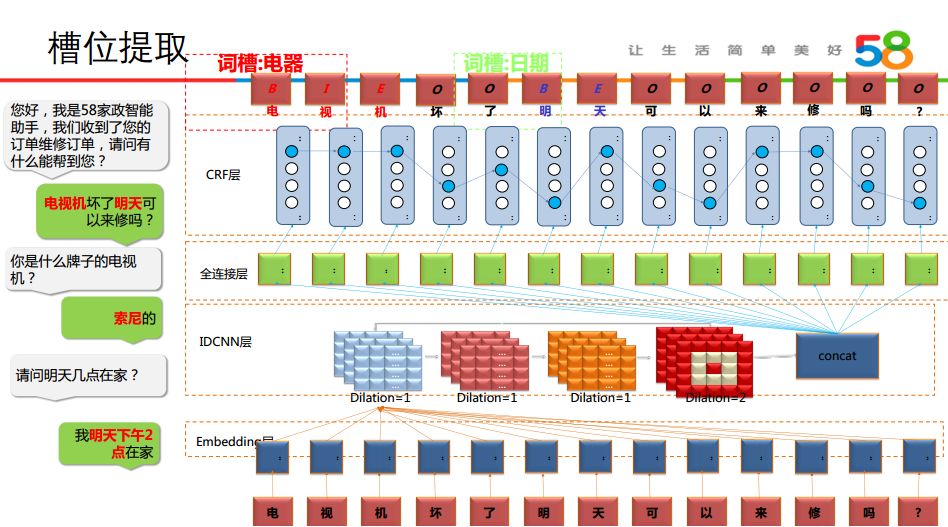
⑤ 槽位提取:
提取对话文本中的词槽,当前主要使用的是 IDCNN+CRF 的方式进行。
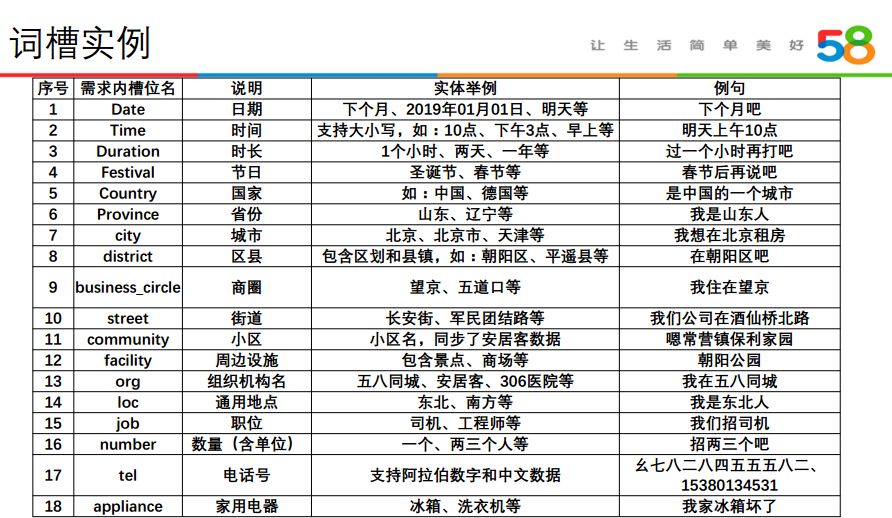
当前外呼中提取的词槽实例如下:
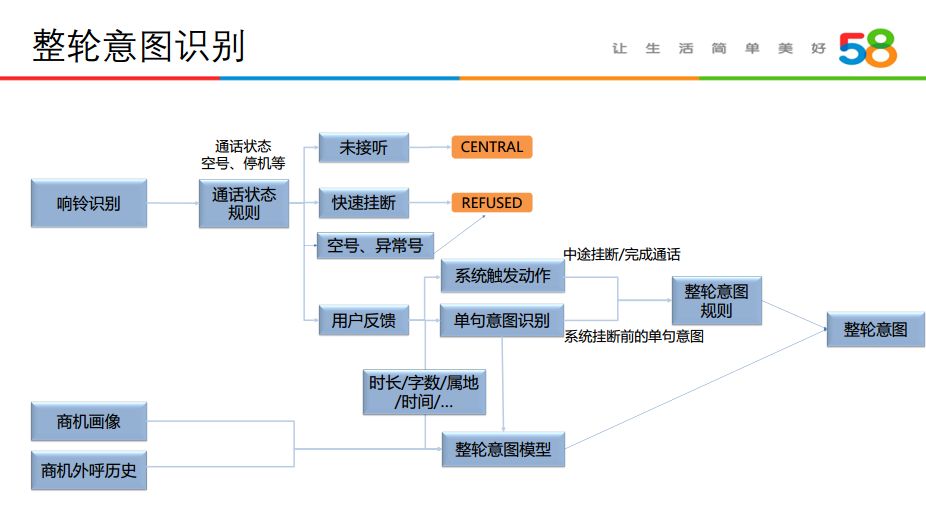
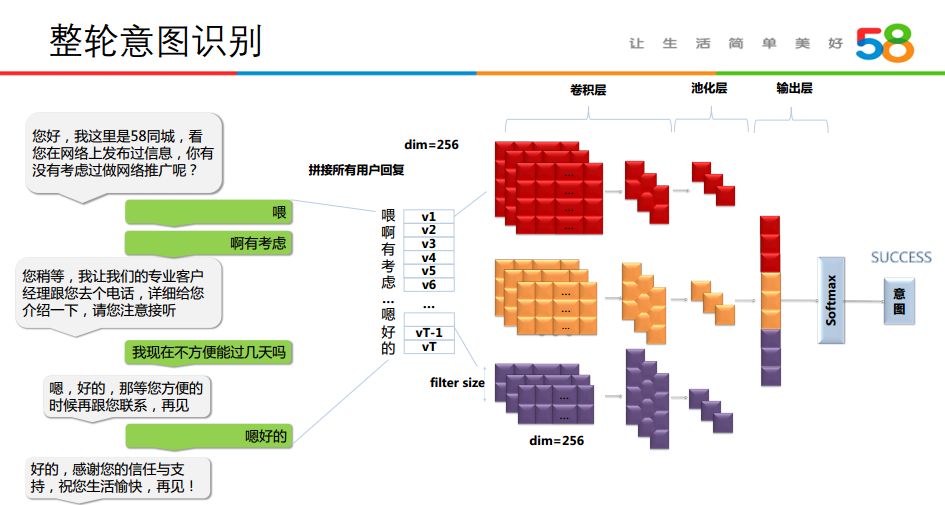
4. 整轮意图识别
在部分外呼业务场景下,当外呼电话结束时,需要对客户意图进行预测,目前采用整轮意图识别的方式对客户意图进行预测。比如在销售场景下,将客户的意图分成了三类分别为 SUCCESS、CENTRAL、REFUSED,具体意图说明如下表:

整轮意图识别会考虑整个对话从响铃识别到对话结束的相关信息来判定,具体可以见下图:
具体的意图识别算法,主要包括 TextCNN 等模型进行分类,输入为整个对话过程中用户的所有回复文本的拼接,当前实际上线的模型是采用多模型融合来做的。此处以 TextCNN 单模型为例,模型结构如下图:
意图识别的评测:
评测会包括离线人工评价与线上评价。
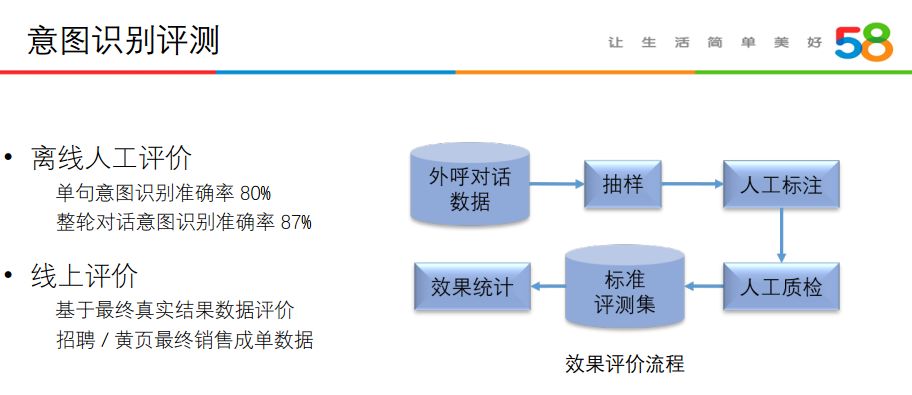
目前影响意图识别准确率的主要因素是语音识别错误。
——应用场景——
语音机器人的实用场景不仅在是在销售场景,在58同城的应用主要还可以概括六个方面,包括:
① 通知:最基本的场景,如当用户信息发生更改,机器人可以用语音的方式告知用户哪些信息发生了更改,需要注意哪些特别事情等。
② 满意度回访:如使用58同城的产品时,可以利用语音机器人对客户进行产品满意度的回访。
③ 信息验真:进行用户信息真实与否的确认。
④ 销售:判断与发现潜在客户。
⑤ 告警:比如内部运维场景下,服务器出现了异常情况,机器人语音电话将报警信息告诉相关负责人。
⑥ 销售客服培训:在人力客服上岗前,需要先进行上岗培训,原来主管对于新员工的基础培训与考核部分,可以改为利用机器人进行初步培训。
下面可以看看四个具体的实际应用案例:
① 校招提效:通知场景,语音机器人在校招面试中成功运用,提升校招工作人员的效率。

② 客服提效

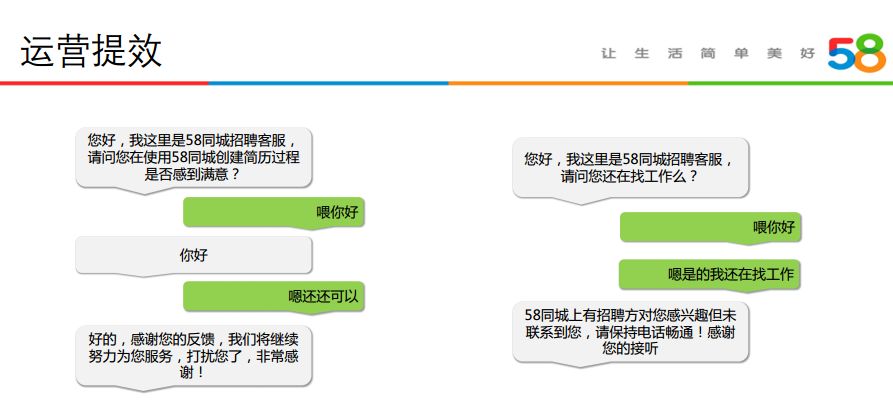
③ 运营提效
④ 销售提效
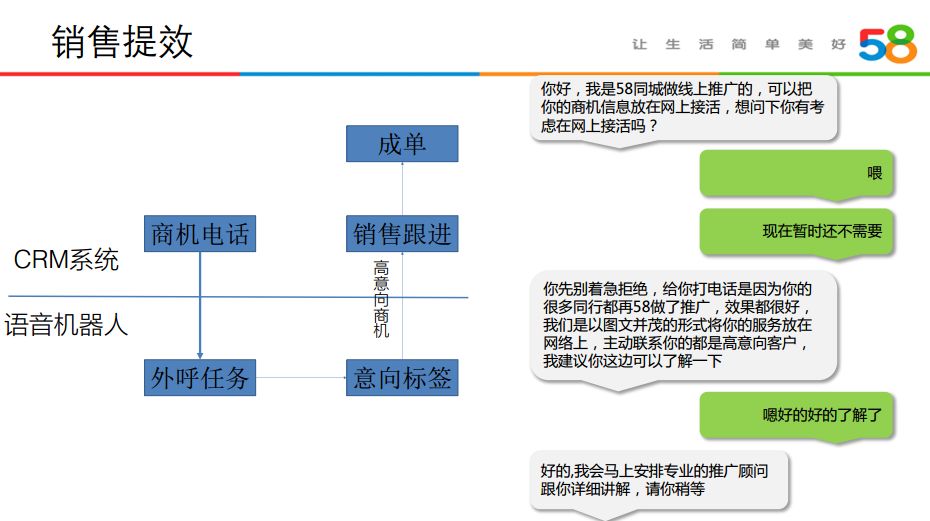
利用语音机器人识别意向程度高的潜在客户,提升销售人员的销售效率。
小结:语音对话技术不仅在销售业务领域落地,在信息通知、内部的业务告警等多个业务模块都得到了应用。本文围绕人机语音对话技术在58同城的落地场景,对语音机器人的总体架构、核心功能、具体实践场景进行了系统的介绍。


李忠
——END——
文章推荐:

DataFun:
专注于大数据、人工智能领域的知识分享平台。

一个「在看」,一段时光!👇


