从BERT、XLNet到MPNet,细看NLP预训练模型发展变迁史

地址 | https://zhuanlan.zhihu.com/p/146325984
20世纪以来,自然语言处理(NLP)领域的发展涌现了许多创新和突破。NLP中许多之前机器不可能完成的任务,如阅读理解、人机对话、自动写新闻稿等,正逐渐成为现实,甚至超越了人类的表现。
如果总结过去20年里,无数先辈辛劳付出带来的璀璨成果,以下3个代表性工作列入NLP名人堂,应该实至名归:1)2003年Bengio提出神经网络语言模型NNLM,从此统一了NLP的特征形式——Embedding;2)2013年Mikolov提出词向量Word2vec,延续NNLM又引入了大规模预训练(Pretrain)的思路;3)2017年Vaswani提出Transformer模型,实现用一个模型处理多种NLP任务。
基于Transformer架构,2018年底开始出现一大批预训练语言模型,刷新众多NLP任务,形成新的里程碑事件。本文将跨越2018-2020,着眼于3个预训练代表性模型BERT、XLNet和MPNet,从以下4个章节介绍NLP预训练语言模型的发展变迁史:
1.BERT 原理及 MLM 简述
2.XLNet 原理及 PLM 简述
3.MPNet 原理及创新点简述
4.NLP预训练模型趋势跟踪
附录:快速上手BERT的4大工具包1.BERT 原理及 MLM 简述

自谷歌2018年底开源BERT,NLP界的游戏规则某种程度上被“颠覆”了;一时间,这个芝麻街的可爱小黄人形象,成为众多NLPer及其他DL、ML研究者们的拥趸。
“BERT一把梭“,“遇事不决就BERT”,“BERT在手,天下我有”,表达了使用者们对BERT的心声。也因为BERT,NLP的准入门槛大幅下降,一些较浅层的NLP任务如文本分类、相似匹配、聚类某种程度上可以被认为是完全解决。

BERT为什么会有如此引人注目的优良效果?下面我们再来回顾下BERT到底是什么。
1.1 Masked Language Model & Next Sentence Predict
BERT本质上是一个自编码(Auto Encoder)语言模型,为了能见多识广,BERT使用3亿多词语训练,采用12层双向Transformer架构。注意,BERT只使用了Transformer的编码器部分,可以理解为BERT旨在学习庞大文本的内部语义信息。
具体训练目标之一,是被称为掩码语言模型的MLM。即输入一句话,给其中15%的字打上“mask”标记,经过Embedding输入和12层Transformer深度理解,来预测“mask”标记的地方原本是哪个字。
input: 欲把西[mask]比西子,淡[mask]浓抹总相宜
output: 欲把西[湖]比西子,淡[妆]浓抹总相宜例如我们输入“欲把西[mask]比西子,淡[mask]浓抹总相宜”给BERT,它需要根据没有被“mask”的上下文,预测出掩盖的地方是“湖”和“妆”。
MLM任务的灵感来自于人类做完形填空。挖去文章中的某些片段,需要通过上下文理解来猜测这些被掩盖位置原先的内容。
训练目标之二,是预测输入的两句话之间是否为上下文(NSP)的二分类问题。继续输入“ 欲把西[湖]比西子,淡[妆]浓抹总相宜”,BERT将预测这两句话的组合是否合理(这个例子是“yes”)。(随后的研究者对预训练模型探索中证明,NSP任务过于简单,对语言模型的训练作用并不是很大)
通过这两个任务和大规模语料训练,BERT语言模型可以很好学习到文本之间的蕴含的关系。
1.2 Self-Attention
接下来简单介绍BERT以及XLNet、MPNet所使用Transformer的核心模块:自注意力机制。
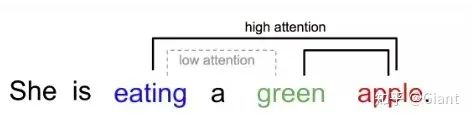
自注意力机制重点在于学习输入序列自身的内部信息。具体地,每个 

同时,这种双向性使得模型可以同时观测序列的所有位置,解决了RNN等递归模型无法高效并行的瓶颈。
1.3 Denoising Auto Encoder
由于架构采用12层双向Transformer且训练目标包含还原 
而在BERT之前,NLP领域的语言模型几乎是Auto Regression(自回归)类型,即当前位置的字符预测 

虽然ELMO采用了BiLSTM,但只是前向、后向两次输出的简单拼接,包含的全局语义信息依然较弱。
1.4 BERT缺点
虽然效果好,BERT的缺点也很明显。从建模本身来看,随机选取15%的字符mask忽视了被mask字符之间可能存在语义关联的现象,从而丢失了部分上下文信息。同时,微调阶段没有mask标记,导致预训练与微调的不一致。
2.XLNet 原理及 PLM 简述
和BERT不同,XLNet本质上是用自回归语言模型来同时编码双向语义信息的思路,可以克服BERT存在的依赖缺失和训练/微调不一致的问题。同时为了弥补自回归模型训练时无法同时看到上下文的缺陷,XLNet曲线救国地提出了PLM排列语言模型的训练方式。
2.1 排列语言模型 - Permutation Language Model
对于一个长度为N的序列,我们知道其存在 
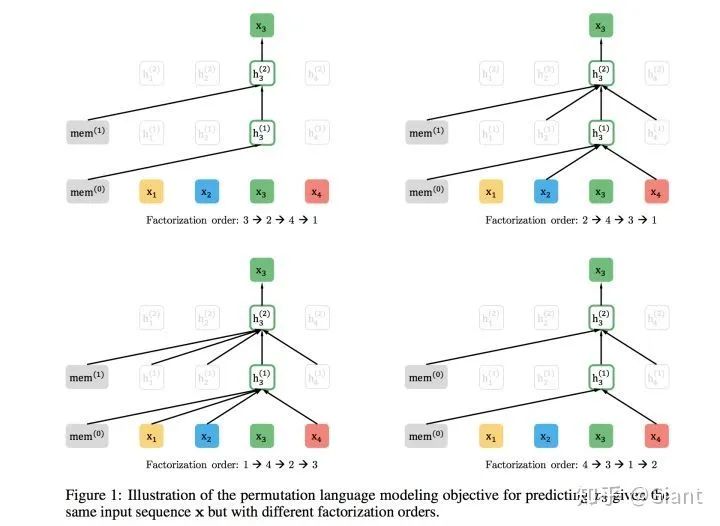
例如,初始序列为 




2.2 双流自注意力
那XLNet是如何在保持输入顺序不变的同时,对序列进行乱序编码的呢?
简单而言,通过Attention掩码机制,将当前token及其之后的token(不该看到的部分)嵌入信息用attention-mask掩盖。具体实现上,使用了一种双流自注意力机制。
例如某个序列的因式分解顺序为 





然而这又带来了新的矛盾。对于某个因式分解顺序
具体来看,XLNET将序列拆分为2部分,序列的后部分(约占句长的1/K,K为超参数)为需要预测的部分,前部分为已知上下文。已知的上下文不做预测,因此只计算content流注意力,每个token都编码之前token以及自身的完整信息。从预测部分开始,每个token同时计算Query流和Content流注意力:Query流的输出用于预训练做预测,Content流的输出提供给后续待预测token计算Query流,这就保证了当预测当前token时,它无法看到自身编码;当前token预测结束后,将其Content流作为上下文部分的编码提供给后续需要预测的token。预训练过程计算2种注意力,微调过程去除了Query流,只保留Content流,因为不需要对token进行词表空间的预测,而是需要编码整个上下文语义用于下游任务。
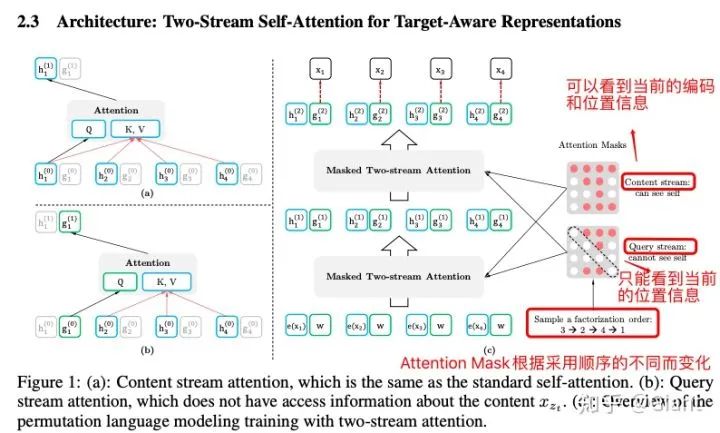
2.3 双向 AR Model
前面提到 Auto Regression 模型的缺点是只能单向编码,但它能够编码被预测的token之间的联系,即克服了BERT被mask字符间信息丢失的缺点。其次,通过上文的PLM模型弥补了自回归语言模型只能单向编码的缺点。AR模型在预训练和下游任务中都没有对输入序列进行损坏(遮盖部分token,引入噪声),消除了模型在预训练和微调过程中的差异。
虽然在期望上看,PLM几乎实现了双向编码功能的自回归模型,但是针对某一个因式分解序列来说,被预测的token依然只能关注到它前面的序列,导致模型依然无法看到完整序列信息和位置信息。
3.MPNet 原理及创新点简述
结合BERT、XLNet的思路,南京大学和微软在2020年共同提出了新的预训练语言模型MPNet:Masked and Permuted Pre-training for Language Understanding。
MPNet的创新点在于4个字:位置补偿(position compensation),大家先留个印象,下文会再详细介绍。
论文开篇,作者针对上文MLM、PLM各自特点,希望用一种统一的模型既保留二者的优点,又弥补它们的不足,这就是MPNet。
3.1 统一视角
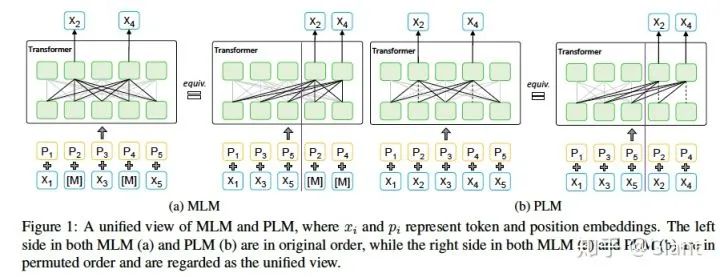
首先,作者通过重新排列和切分输入序列中的tokens,将MLM和PLM统一为非预测部分(non-predicted)和预测部分(predicted),如图(a),(b)右侧。如此一来,MLM和PLM就拥有了相似的数学表达公式,仅在条件部分有细小差异。

3.2 模型架构
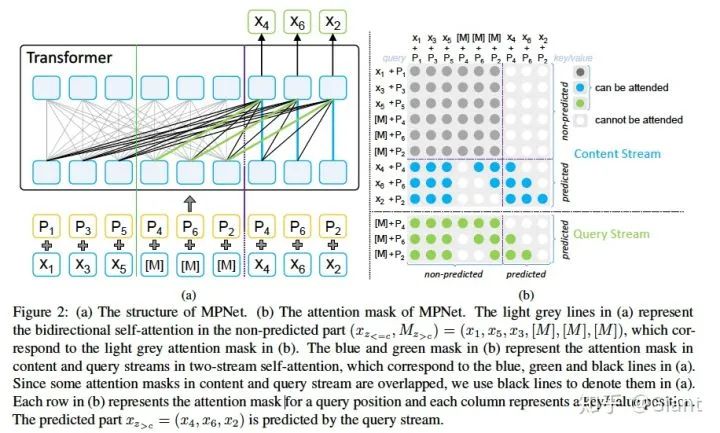
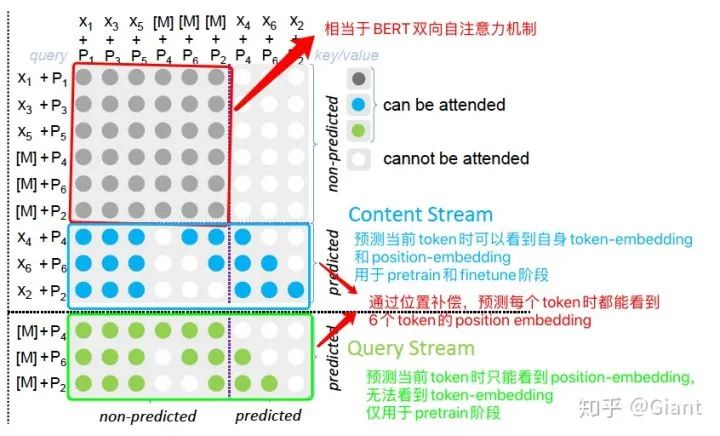
为缓解BERT-mask可能丢失依赖信息的问题,MPNet沿用了XLNet的自回归结构,同时为弥补XLNet无法捕捉全部序列位置信息的缺陷,添加了「位置补偿」:针对需要预测的token,额外添加了它们的位置信息。使得自回归过程中,在任意一个位置i,除了可以看到之前部分的token编码,还能看到序列所有token的位置编码(类似于BERT)。
例如,对于一个长度为6的token序列 







3个[M]和对应位置position-embedding的加入,就是位置补偿。例如在序列 




3.3 MPNet优势
MPNet使用自回归编码,避免了BERT做Mask时可能丢失被Mask的token的彼此关联信息和pretrain(有mask)、finetune(无mask)不一致的问题;通过位置补偿,又解决了XLNet无法看到全局位置信息的缺陷。取其精华,确实是挺巧妙的一种思路。

观察输入信息的占比,MPNet输入的信息量是最大的;从直观上理解,模型每次可以接受到更多的文本特征,从而容易训练出更优结果。
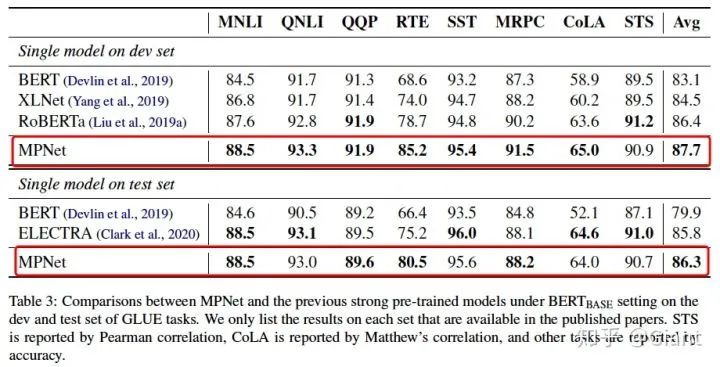
3.4 SOTA结果
作者在权威的语义理解评估数据集GLUE上的实验结果表面,MPNet确实比它的前辈BERT和XLNet略胜一筹。另外,作者表示MPNet在训练时加入了全词掩码whole word mask以及相对位置编码等已被证明有效的trick,加上和RoBERTa训练一样的160GB训练语料,取得这样的结果应该说是情理之中了。
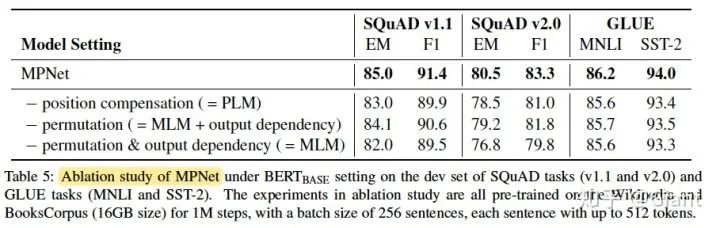
末尾的消融实验,可以看到位置补偿和PLM对实验结果的提升都很关键。
4.NLP预训练模型趋势跟踪
从目前来看,大规模语料预训练+finetune的方式,应该会是NLP接下去几年的主流。各种基于语言模型的改进也是层出不穷。虽然玩法种类各异,我们还是可以瞥见一些具有突破性的方向。
4.1 土豪系列 - T5、GPT3、MegatronLM

前期BERT到RoBERTa,GPT到GPT2效果的提升,已经证明更多数据可以跑出更强大更通用的预训练模型。去年底到今年,英伟达、谷歌、Open-AI相继放出巨无霸模型MegatronLM(83亿参数)、T5(110亿)、GPT3(1500亿),不断刷榜令人咋舌的同时也彰显了巨头们的实力。
相信未来,巨无霸模型依然会成为大公司的研究目标之一,却让普通科研人员可望不可及。
4.2 小而美系列 - DistillBERT、TinyBERT、FastBERT
没有前排巨头们的经济实力,普通公司和科研机构沿着相反赛道-模型轻量化下足了功夫。如何在尽可能少的参数量下,取得和大模型接近的效果,同时训练/预测速度翻倍,是很实际很有价值的课题。
这其中,有代表性的工作如华为诺亚方舟实验室发布的TinyBERT、北大的FastBERT都取得了瞩目的效果。例如FastBERT在BERT的每一层都接入一个分类器,通过样本自适应机制自动调整每个样本的计算量(容易的样本通过一两层就可以预测出来,较难的样本则需要走完全程)。
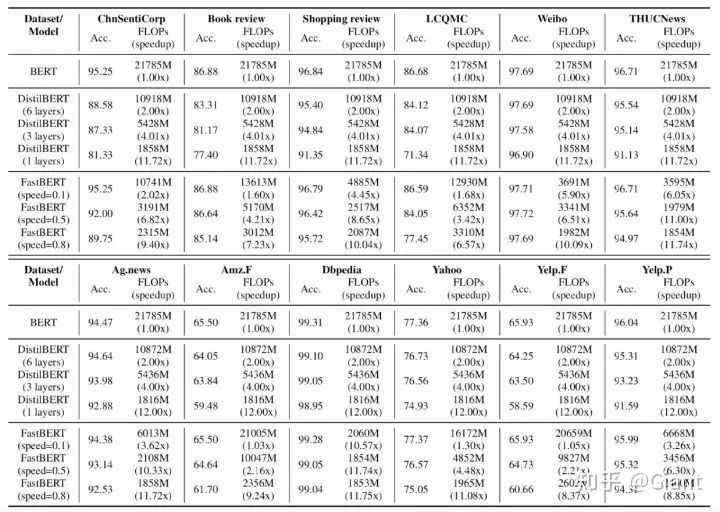
图中“Speed”代表不确定性的阈值,和推理速度成正比。在Speed=0.2时,FastBERT速度可以提升1-10倍,且精度下降全部在0.11个点之内。
除了知识蒸馏,常规的模型轻量化一般包含层数裁剪、精度量化等手段。
4.3 潜力股系列 - few shot learning
在实际业务场景中,对于中小AI企业往往容易出现数据量不足的问题。例如用户需要订制一个FAQ问答机器人,有100个标准问,但表示每个问句只有2-3条同义句...

战略上,“客户就是上帝“的精神激励我们不能虚,要迎难而上。战术上,除了花高成本找标注团队造数据外,迁移学习、小样本学习可能会非常有帮助。受到人类具有快速从少量(单)样本中学习能力的启发(例如生活在北方的人可能没有见过榴莲,一旦看过一次榴莲的照片,就认识了!),让模型在少量样本中学习获得有力的泛化能力,成为近年的研究热点之一。
感兴趣的同学可以参考阿里的这篇paper:Few-Shot Text Classification with Induction Network。
5.附录-快速上手BERT的4大工具包
预训练语言模型的代表BERT,已经成为NLP领域的重要工具,不同机构/个人也分别开发了轻松使用BERT的工具包。笔者结合自身经验,简单概括了一下:
5.1 肖涵 - bert-as-service
顾名思义,将BERT模型直接封装成一个服务,堪称上手最快的BERT工具。作者是xxx肖涵博士。
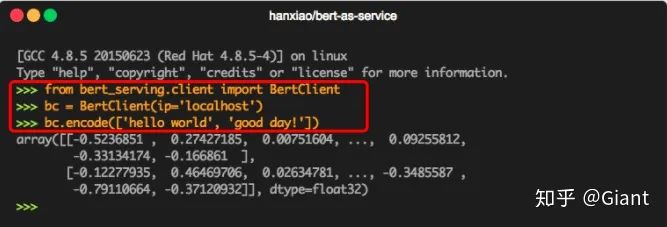
按照GIthub上的教程,下载BERT权重并安装工具包,三行代码即可轻松使用BERT获得文本的向量特征,完成下游NLP各项任务。bert-as-service是跨平台的服务,不受限于OS、深度学习框架,且作者对于并发做了大量优化与加速,可以满足日常实验甚至公司的实际业务需求。
5.2 Google - BERT源码
BERT源码官方仓库,可以学习BERT各模块的底层实现细节。Google开源了权重的同时,也开源了预训练、子任务微调的脚本,是学习BERT不可略过的学习教程。代码基于tensorflow,对TF熟练的同学会更快上手。
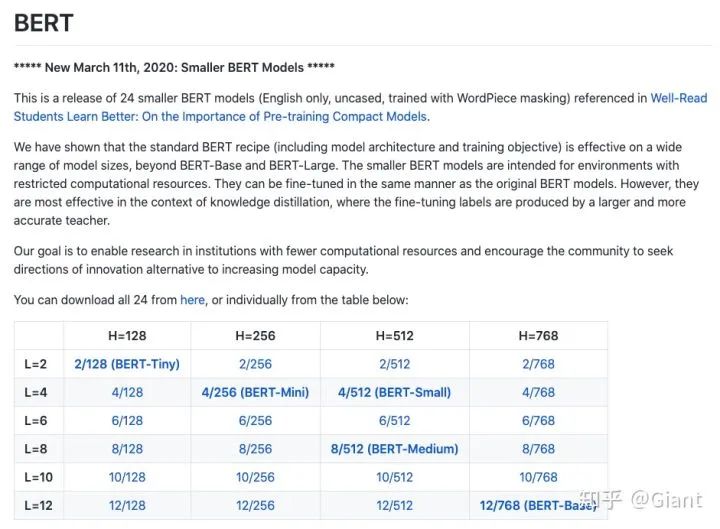
当前,仓库中还发布了2/4/6/8..层不同大小的BERT,以缓解BERT资源开销大、inference缓慢带来的问题。中文BERT可以参考哈工大崔一鸣、实在智能徐亮等开源的权重。
5.3 huggingface - transformers
有了TF版,pytorch怎甘落后。机构huggingface开发的transformers工具包,堪称预训练模型大礼包,囊括了10几种火热模型。

种类齐全且api接口实现统一、调用简单,是pytorch框架与BERT的最佳组合。transformers的src源码也是学习BERT等模型原理的绝佳资料。
5.4 苏剑林 - bert4keras
接下来自然而然该Keras出场了!作为tf2.0的官方高阶api,Keras的简洁特性始终拥有超高人气。

来自追一科技的苏神苏剑林,在业余时间自己实现了bert4keras框架,且提供了详细教程、众多下游任务微调脚本(分类、文本生成、QA、图片标题生成等)。始终走在BERT任务的前沿。
除以上工具包,github上还有众多用户开源的BERT相关工具,按需参考使用即可。
Reference
[1] Devlin J, Chang M W, Lee K, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[2] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need [C]//Advances in Neural Information Processing Systems. 2017: 5998-6008.
[3]Zhilin Yang, Zihang Dai, Yiming, et.al. XLNet: Generalized Autoregressive Pretraining for Language Understanding[C]. arXiv preprint arXiv:1906.08237, 2019.
[4]Kaitao Song, Xu Tan, Tao Qin, Tie-Yan Liu, et.al. MPNet: Masked and Permuted Pre-training for Language Understanding [C]. arXiv preprint arXiv:2004.09297, 2020.
[5]Weijie Liu, PengZhou, QiJu, et.al. FastBERT: a Self-distilling BERT with Adaptive Inference Time[C]. arXiv preprint arXiv:2004.02178, 2020.
[6]张俊林 - XLNet:运行机制及和Bert的异同比较
[7]李如 - FastBERT:又快又稳的推理提速方法
推荐阅读
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇


