ACL 2018论文解读 | 基于排序思想的弱监督关系抽取选种与降噪算法


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
作者丨卢靖宇
学校丨西安电子科技大学硕士
研究方向丨自然语言处理
本期推荐的论文笔记来自 PaperWeekly 社区用户 @hawksilent。本文创造性地将 Bootstrapping 关系提取中的自动选种任务,以及远程监督关系提取中的降噪任务看成是根据不同的排序标准进行排序的问题,提出了多种兼具自动选种和数据降噪功能的策略。
文章的贡献主要有以下几点:
1. 创造性的将关系提取中的自动选种和数据降噪任务转换成排序问题;
2. 提出多种既可用于 Bootstrapping 关系提取自动选种,又能用于远程监督关系提取降噪的策略;
3. 在收集自 Wikipedia 和 ClueWeb 的数据集上,通过实验证实提出的算法的实用性和先进性。


引言
最近阅读了 Ranking-Based Automatic Seed Selection and Noise Reduction for Weakly Supervised Relation Extraction 这篇文章,该工作来自于 Nara Institute of Science and Technology,发表在 ACL 2018。
这篇文章主要对弱监督关系提取中两个相关的任务展开研究:
Bootstrapping 关系提取(Bootstrapping RE)的自动选种任务;
远程监督关系提取(Distantly Supervise RE)的降噪任务。
文章受到 Web 结构挖掘中最具有权威性、使用最广泛的 Hypertext-induced topic search(HITS)算法,以及 K-means、潜在语义分析(LSA)、非负矩阵分解(NMF)等聚类中心选择算法的启发,提出一种能够从现有资源中选择初始化种子、并降低远程标注数据噪声的算法。
实验证明,该算法的性能要好于上述两个任务的基线系统。下面是我对这篇文章的阅读笔记。
问题引入
Bootstrapping RE 算法是机器学习中一种比较常用的弱监督学习方法。首先,利用一个称作“seeds”的小实例集合进行初始化,用以表示特定的语义关系;然后,通过在大规模语料库上迭代获取实例和模式,以发现与初始化种子相似的实例。该算法性能的主要制约因素在于语义漂移问题,而解决语义漂移问题的一种有效手段就是选择出高质量的“seeds”。
Distantly Supervise 技术是一种用于构建大规模关系提取语料库的有效方法。然而,由于错误标注问题的存在,远程监督获取的语料常常包含噪声数据,这些噪声会对监督学习算法性能造成不良影响。因此,如何降低错误标注带来的数据噪声,就成为了远程监督技术的一个研究热点。
问题转化
用表示目标关系的集合,每一种目标关系
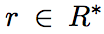
结合上述概念文章将所研究的两个关系提取任务分别定义如下:
Bootstrapping RE 的自动选种任务:以目标关系集合为输入,针对每一个
Distantly Supervised RE 的降噪任务:从由 DS 自动为每个关系
由以上两个任务的描述可以发现,无论是选种还是降噪都是从给定的集合中选出三元组。从排序的角度来看,这两个任务实质上拥有相似的目标。
因此,文章将这两个任务分别转换为:在给定三元组集合 Dr(可能包含噪声)的情况下,实例 (e1,e2 )的排序任务(选种)和三元组 (e1, p, e2 ) 的排序任务(降噪)。
在选种任务中,使用排名最高的 k 个实例作为 bootstrapping RE 的种子。同理,在降噪任务中,对于 DS 生成的三元组,使用其中排名最高的 k 个三元组来训练分类器(降噪任务中的 k 值可能远远小于选种任务中的 k 值)。
自动选种和降噪算法
文章提出的算法受到了 Hypertext-induced topic search(HITS)算法,以及 K-means、潜在语义分析(LSA)、非负矩阵分解(NMF)等聚类中心选择算法的启发。
该算法根据具体的任务来决定是选择实例还是选择三元组:实例用于自动选种任务,三元组用于降噪任务。由于实例即为实体对,而实体对又包含在三元组中,因而可以通过实例和三元组之间的转换,灵活的将提出的方法分别应用到两个任务中。
基于K-means的算法
文章提出的基于 K-means 的算法具体描述如下:
1. 确定需要选择的实例/三元组的数目 k;
2. 运行 K-means 聚类算法将输入的三元组中的所有实例划分为 k 个簇,每个数据点通过其对应实体间的嵌入向量差来表示。例如,实例 I=(Barack Obama,Honolulu) 对应于 vec(I)=vec("Barack Obama")-vec("Honolulu");
3. 从每个簇中选出最接近质心的实例。
基于HITS的算法
Hypertext-induced topic search(HITS)算法又称为 hubs-and-authorities 算法,它是一种广泛用于对 web 页面排序的链接分析方法。
该算法的基本思想是:利用 Hub 页面(包含了很多指向 Authority 页面的链接的网页)和 Authority 页面(指与某个主题相关的高质量网页)构成的二部图,计算每个节点的枢纽度(hubness)得分,然后据此对网页内容的质量和网页链接的质量做出评价。
对于第 2 节描述的两个任务,可通过实例 (e1,e2) 和模式 p 的共生矩阵 A 生成两者的二部图,进而即可利用 HITS 算法的思想计算两者的 hubness 得分。
文章提出的基于 HITS 思想的选种策略描述如下:
1. 确定要选择的三元组的数目 k;
2. 基于实例-模式的共生矩阵 A 构建实例和模式的二部图。下图所示为构建二部图的三种可能思路。思路一:将每一个实例/模式均作为图中的一个节点。思路二:将实例和模式分别作为边和节点。思路三:将实例和模式分别作为节点和边;
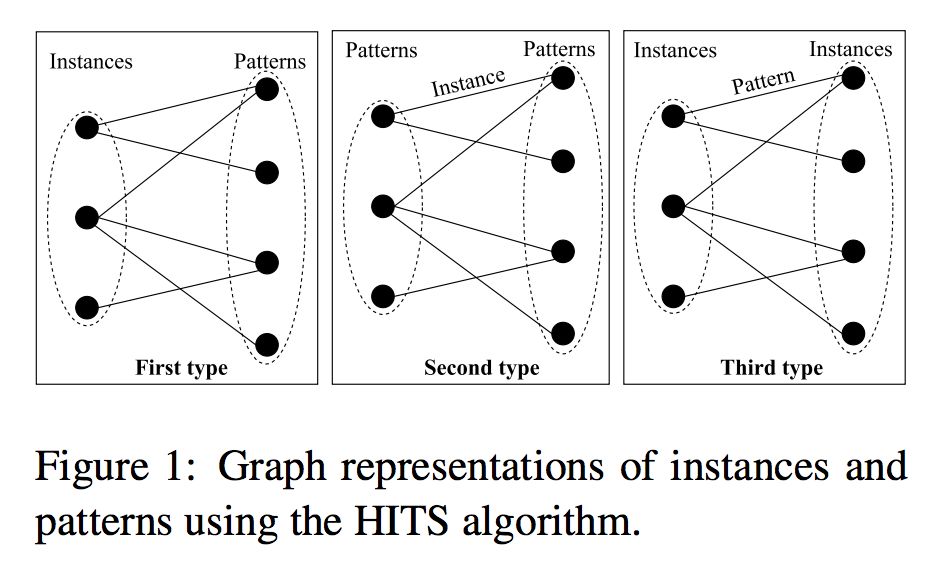
3. 对于思路一和思路三,仅保留 hubness 得分最高的 top k 个实例作为输出。对于思路二,选择与得分最高的模式相关联的 k 个实例作为输出。
基于HITS和K-means的方法
该方法将 HITS 算法和 K-means 算法组合使用。首先,基于实例和模式的二部图对这两者进行排序;然后,在标注数据集上运行 K-means 算法对实例进行聚类。之后,与常规思路不同,这里不选择距离质心最近的实例,而是选择每个簇中 HITS 算法 hubness 得分最高的实例。
基于LSA的算法
潜在语义分析(LSA)是一种被广泛应用的多维数据自动聚类方法,该方法利用奇异值分解(Singular value decomposition,SVD)算法构建实例-模式共生矩阵 A 的等价低秩矩阵。
所谓 SVD,是将矩阵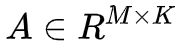
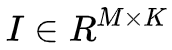
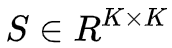
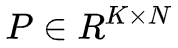
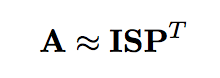
本文提出的基于 LSA 的选种策略具体描述如下:
1. 指定需要的三元组数目 k;
2. 利用 LSA 算法将实例-模式的共生矩阵 A 分解为矩阵 I、S、P。将 LSA 的维度设置为 K=k;
3. 将 LSA 看作软聚类的一种形式,其中 SVD 实例矩阵 I 的每一列对应一个簇。之后,从矩阵 I 的每一列选出绝对值最高的 k 个实例。
基于NMF的方法
非负矩阵分解(Non-negative matrix factorization,NMK)是另外一种用于近似非负矩阵分解的方法。非负矩阵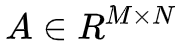
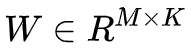
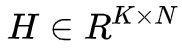
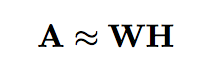
非负约束(non-negativity constraint)是 NMF 与 LSA 之间的主要区别。与基于 LSA 的方法类似,NMF 算法先将期望选择的实例数目设置为 K=k。之后,从矩阵 W 的每一列中选出值最大的 k 个实例。
实验
数据集与设置
文章使用了一个局整关系的标注数据集做为种子选择的来源。该数据集提取自 Wikipedia 和 ClueWeb。这里,所谓的局整关系并不是指某一种具体的关系,而是指一种类型的关系集合,如下表所示。
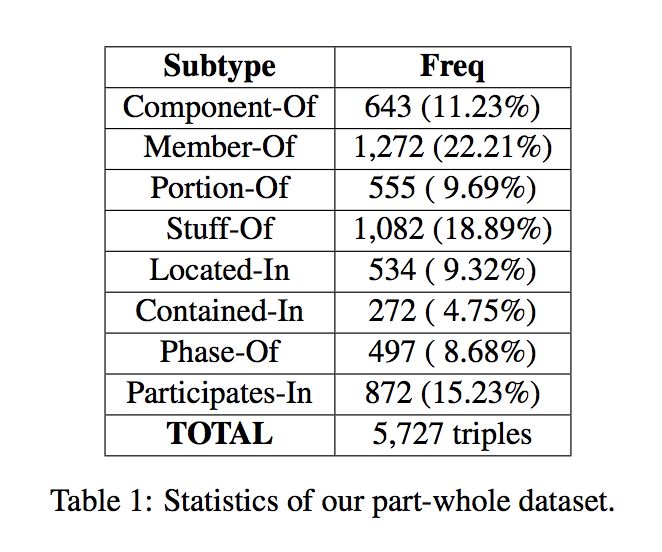
表中显示出了局整关系集中 8 种子关系出现的频率。数据集中 8 种子关系共有 5727 个标注实例。文章通过使用 Precision@N 来衡量提出的模型性能,其中取 N=50。实验中 k 的值在区间 [5,50] 内以 5 为步长逐步递增,对于每个选种方法给出其 P@50 的值。
在降噪任务中,文章使用由 (Riedel et al., 2010) 开发的训练集和测试集,该数据集是通过将 Freebase 关系与纽约时报语料库对齐而生成的,包含53 种关系类型。在使用提出的方法从数据集中滤除噪声三元组之后,文章使用过滤后的数据对两种卷积神经网络模型(CNN)进行了训练:一种是 (Zeng et al., 2014) 提出的 CNN 模型,一种是 (Zeng et al., 2015) 提出的 PCNN 模型。
表中显示出了局整关系集中 8 种子关系出现的频率。数据集中 8 种子关系共有 5727 个标注实例。文章通过使用 Precision@N 来衡量提出的模型性能,其中取 N=50。实验中 k 的值在区间 [5,50] 内以 5 为步长逐步递增,对于每个选种方法给出其 P@50 的值。
在降噪任务中,文章使用由 (Riedel et al., 2010) 开发的训练集和测试集,该数据集是通过将 Freebase 关系与纽约时报语料库对齐而生成的,包含 53 种关系类型。在使用提出的方法从数据集中滤除噪声三元组之后,文章使用过滤后的数据对两种卷积神经网络模型(CNN)进行了训练:一种是 (Zeng et al., 2014) 提出的 CNN 模型,一种是 (Zeng et al., 2015) 提出的 PCNN 模型。
自动选种算法性能
选种算法的实验结果如下表所示。对于基于 HITS 的算法和基于 HITS+K-means 的算法,文章给出了相应的 P@50(分别采用 3.2 节介绍的三种构图思路),实验中使用随机种子选择做为对比基线。
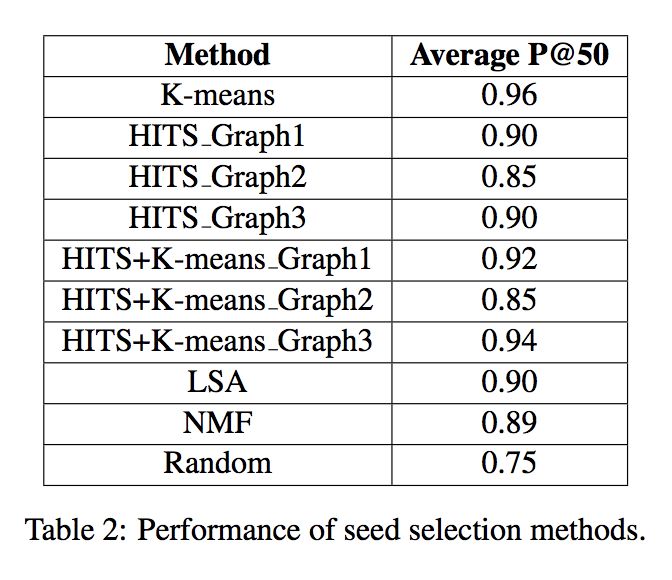
观察实验结果发现,随机选种性能最差,为 0.75;基于 HITS 的策略、基于 LSA 的策略和基于 NMF 的策略,三种算法性能相当,都超过了基线算法;对于基于 HITS 的策略,三种不同的构图思路中,思路一和思路三性能提升明显,思路二性能虽有提升但效果明显低于其他两种策略;将 HITS 策略(构图思路分别采用思路一和思路三)与 K-means 算法结合得到的性能在提出的算法中最佳。
HITS 策略中思路二效果不佳的原因在于:一个模式可能含有歧义,因而链接到该模式的实例可能并不与其匹配,这说明依靠实例选种要好于依靠模式选种。
降噪算法性能
在降噪实验中,文章分别采用基于 HITS、LSA 和 NMF 的算法,下表为各算法对于 CNN 和 PCNN 模型带来的性能提升。表中最右边一列为集成算法的性能,该方法结合基于 HITS 和基于 LSA 的策略,其中,一半的三元组来自基于 HITS 的算法,另一半三元组来自基于 LSA 的算法。
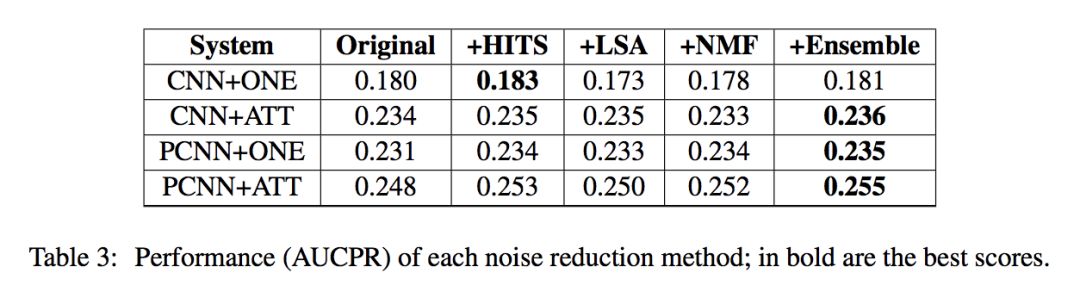
观察实验结果发现,基于 HITS 的策略表现最为稳定,对于四种模型都能提升其性能;基于 LSA 的策略,与注意力机制(无论模型是 CNN 还是 PCNN)结合使用时性能提升明显,但与多实例学习算法结合使用则效果变差,甚至还要低于原始模型;基于 NMF 的策略,对于 PCNN 模型(无论采用多实例学习还是注意力机制)能带来明显的性能提升,但对于 CNN 模型性能改善不明显;将基于 HITS 的策略和基于 LSA 的策略集成使用,则对于四种模型不但表现稳定,且性能提升效果也十分明显。
总结
文章创造性地将关系提取中的自动选种和数据降噪这两个重要任务转换为排序问题。然后,借鉴 HITS、K-means、LSA 和 NMF 等传统算法策略,按照对实例-模式三元组排序的思路,构建出了兼具自动选种和数据降噪功能的算法。实验结果显示,文章提出的算法能够有效完成自动选种和数据降噪任务,并且其性能同基线算法相比也有较大提升。
这篇文章的启发作用在于:对于关系提取中的不同子任务通过问题转换归结为本质相同的同一问题,而后借鉴已有的成熟算法设计出可以通用的解决策略。这种思路上的开拓创新能否应用于其他 NLP 任务,是一个值得思考和探索的方向。
参考文献
[1] Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions without labeled text. In Proceedings of the 2010 Joint European Conference on Machine Learning and Principles of Knowledge Discovery in Databases (ECML PKDD), pages 148–163. Springer.
[2] Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via convolutional deep neural network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pages 2335–2344. Dublin City University and Association for Computational Linguistics.
[3] Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao.2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1753–1762. Association for Computational Linguistics.
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文



